企業自動化の向上:LLMを駆動とするインフラによるシームレスなCAPTCHA認識と運用効率

Sora Fujimoto
AI Solutions Architect

デジタル変革の急速な進展の中で、CAPTCHAは単なるセキュリティチェックから高度なビジネスプロセスフィルターへと進化しました。セキュリティにおいて不可欠ですが、自動化ワークフローに大きな摩擦をもたらし、「効率のギャップ」という課題を生み出しています。世界中で企業は毎日推定50万時間以上を手動でCAPTCHAを解決するために費やしており、重要なビジネス操作の円滑な実行を妨げています。
この手動介入はいくつかの課題を引き起こします:
- 高い運用コスト: CAPTCHAの解決に人間のオペレーターに依存すると、ビジネスの増加に伴いスケーラビリティが低下します。
- プロセスの中断: 自動スクリプトはCAPTCHAに遭遇すると頻繁に停止し、ビジネスプロセスの連続性を破ります。
- プライバシーと技術的なプレッシャー: 進化するプライバシー基準により、従来の行動ベースの検証方法は課題となり、より透明性があり効率的な解決策が求められます。
私たちのビジョン: CAPTCHAがビジネス成長を妨げるのではなく、支えるものであると考えています。AI自動化インフラを提供し、自動CAPTCHA認識を実現することで、企業が手動介入を大幅に削減し、運用コストを最適化し、コアビジネスプロセスのエコシステム効率を向上させることを支援しています。
📈 I. 検証の進化: 静的ルールから知的協調へ
過去25年間で検証技術の進化は、セキュリティとユーザー体験のバランスを追求する継続的なプロセスです。大規模言語モデル(LLM)の登場は、知的で協調的な処理の新しい時代をもたらす重要な転換点です。
| 段階 | コア技術 | 処理ロジック | ビジネスインパクト |
|---|---|---|---|
| V1 (2000年代) | ねじれた文字 | 単純なOCR認識 | 基本的な自動化に対して脆弱、初期効率が高い |
| V2 (2014年代) | イメージ選択 | オブジェクト検出と分類 | 大量の手動ラベリングを必要とし、運用コストが増加 |
| V3 (2024年代) | 行動分析 | リスクスコアリングとファINGERプリント | プライバシーの懸念に直面し、効率的な自動化に課題 |
| V4 (2026+) | LLM協調 | 意味理解と生成 | 高信頼性、効率向上、完全な自動化 |
重要な洞察: CAPTCHAが意味的・マルチモーダルな方向へ進化する中、従来のルールベースまたはハードコードされた解決策は不十分であることが明らかになっています。企業は、高度な意味理解能力を持つ知的インフラストラクチャを必要としています。これがCAPTCHA用LLMが不可欠になる理由です。
🧠 II. LLMの強化: 自動化インフラのコア機能
大規模モデルを検証処理エコシステムに統合することで、ビジネスプロセス効率を駆動する知的エンジンとなります。
このトレンドにおいて、一部の企業向け自動化インフラプラットフォームはLLM機能の開発を開始しています。例えば、CapSolverは、マルチモーダル認識と大規模モデルの推論機能を統合し、企業が手動介入を増やさずにビジネスプロセスの連続性と実行効率を向上させることを可能にしています。
このような解決策のコア価値は、単一の機能にとどまらず、進化する検証環境において企業が安定した自動化能力と制御可能なコストを維持するための下部インフラとして機能することにあります。
2.1 コア機能1: 知的リスク意思決定エンジン
従来の自動化は、CAPTCHA処理に柔軟なif-elseルールに依存しており、断片的でメンテナンスが困難で簡単に回避可能なシステムを生み出しています。LLM駆動のインフラは、統一的で適応的で説明可能な処理を行う知的リスク意思決定エンジンとして機能します。
従来のアプローチ(ルールベース):
python
# 従来の方法
if ip_risk > 0.8 and device_new == True:
captcha_type = "hard"
elif behavior_score < 0.5:
captcha_type = "medium"
else:
captcha_type = "none"LLM駆動のアプローチ(文脈に基づく意思決定):
python
# LLMの方法
context = {
"ip_reputation": "medium",
"device_fingerprint": "new_device",
"behavior_score": 0.65,
"request_frequency": "high",
"geo_location": "anomalous",
"historical_pattern": "deviation_detected"
}
# LLM出力: {"risk_level": "high", "captcha_type": "semantic_image",
# "difficulty": 0.8, "reason": "デバイスファイngerプリントが新しいIPの地理的場所と衝突"}価値提案:
- ✅ 偽陽性の削減(20%以上): 正規ユーザーへの中断を最小限に抑え、ユーザー体験を向上させます。
- ✅ 説明可能な意思決定: セキュリティ運用と継続的な最適化のための監査可能なインサイトを提供します。
- ダイナミックな適応性: 進化する検証課題とビジネスニーズに自動的に調整します。
2.2 コア機能2: 生成検証エンジン
従来のCAPTCHAは限られた問題バンクに依存しており、高度な自動化によってオフラインでトレーニングされたり、ハッキングされたりしやすいです。生成AI、特にDiffusionモデルを活用することで、独自で動的な検証課題を作成できます。各インスタンスは独自の創造であり、不正な自動化の試みのコストと複雑さを大幅に増加させます。
mermaid
graph TD
A[従来のCAPTCHA] --> B{限られた問題バンク}
B --> C[オフライントレーニング/ハッキングに脆弱]
D[生成検証エンジン] --> E{LLM + Diffusionモデル}
E --> F[無限でユニークなCAPTCHAインスタンス]
F --> G[不正な自動化に prohibitively 高いコスト]コア原則: 不正な自動化の一般化コストが、検証を回避する潜在的な利益を上回ることを確保します。
2.3 コア機能3: 深層行動シーケンス分析
従来の行動分析は単純なパターン(例: 直線的なマウス移動がロボット的とフラグ付け)を検出するにとどまりますが、LLMは深層行動シーケンス分析を行うことができます。ユーザー操作シーケンスをベクトル化し、Transformerモデルで処理することで、過度に完璧な自動スクリプトではなく、微細な人間らしいニュアンスを識別できます。
行動シーケンス分析フロー:
mermaid
graph LR
A[ユーザー操作シーケンス] --> B[埋め込みベクトル化]
B --> C[Transformerエンコード]
C --> D[リスクスコアリング]
subgraph ユーザー行動
E[マウス移動]
F[クリック位置]
G[滞在時間]
H[ページスクロール]
I[キーボードリズム]
end
E --> A
F --> A
G --> A
H --> A
I --> A
D --> J{LLM判断: "戸惑う本物のユーザー" vs. "完璧な自動スクリプト"}これにより、本物のインタラクションにある「人間の不完全さ」に基づいて、「戸惑う本物のユーザー」と「完璧な自動スクリプト」を区別できます。
🗺️ III. 戦略的優位性: LLMで自動化コストを最適化
効果的な自動化の本質は、不正な回避を完全に防止することではなく、不正な回避の経済的非効率性を確保することです。LLMはこのコストの非対称性を強化し、正当な自動化をより効率的で、不正な自動化を非常に高価にします。
不正な自動化 vs. 知的インフラストラクチャのコスト比較
| コスト要素 | 不正な自動化 | 知的インフラストラクチャ |
|---|---|---|
| データ収集 | 高い(トレーニング用) | 低い(行動データ取得) |
| モデルトレーニング | 高い(反復トレーニング) | 中程度(生成モデルの展開) |
| 敵対的サンプル生成 | 高い | 無し |
| 効果の有効期間 | 低い(CAPTCHAが陳腐化) | 高い(動的な戦略の更新) |
| 検出リスク | 高い | 低い |
| 偽陽性の処理 | 無し | 中程度(上訴処理) |
結論: 不正な自動化の運用コストは、LLM駆動インフラの持続可能なコストよりもはるかに高いです。これにより、長期的な強固な自動化が保証されます。
LLMがコスト最適化をどのように強化するか:
- 一般化コストの増加: 生成CAPTCHAは無限の視覚空間を作成し、事前トレーニングされたモデルを防ぎます。
- 推論コストの増加: 意味的なCAPTCHAは複数ステップの推論を必要とし、不正な試みに多くの計算リソースを消費します。
- タイム・トゥ・ライブの短縮: 短いCAPTCHA有効期間により、ハッキングされたソリューションが広く展開される前に陳腐化します。
- データ汚染: ハニーポットデータで本物のトラフィックを動的にオブフスケートすることで、不正な自動化のトレーニングデータセットを汚染します。
🚀 IV. 未来の展望: スムーズで信頼に基づく自動化エコシステムの構築
検証がユーザー体験に溶け込み、連続的なプロセスとなる未来を想像しています。
4.1 フェーズ1: LLMを「効率のコ・ピロット」として(現在 - 近未来)
この初期段階では、LLMは重要な決定を直接行うのではなく、セキュリティ運用の効率を向上させる知的アシスタントとして機能します。複雑な検証ロジックを処理し、手動介入の頻度を大幅に削減し、人間の専門家に行動可能なインサイトを提供します。
mermaid
graph TD
A[ユーザー要求] --> B{従来の検証システム}
B --> C{CAPTCHAに遭遇}
C --> D[LLMコ・ピロット: CAPTCHAと文脈を分析]
D --> E{人間のセキュリティ専門家: レビューと判断}
E --> F[検証結果]
D -- "解決策を提案" --> E
E -- "フィードバックを提供" --> D重要な原則: LLMはコ・ピロットとして機能し、人間の専門知識を補完して運用効率を向上させます。
4.2 フェーズ2: ダイナミック生成検証(近未来 - 中期)
この段階では、LLMと生成モデル(Diffusionモデルなど)を組み合わせて、事前にトレーニングできないCAPTCHAを作成します。各検証インスタンスはユニークであり、1つのインスタンスの成功した回避が後の試みに何の利点も与えません。検証は「問題バンク抽出」モデルから「リアルタイム作成」モデルへと移行します。
mermaid
graph TD
A[ユーザーアクセス] --> B[LLM: ページコンテキストを理解]
B --> C["生成AI(Diffusion): 意味的なCAPTCHAを作成"]
C --> D[ユーザー: ユニークなCAPTCHAを解決]
D --> E[検証成功/失敗]
subgraph 例のCAPTCHA
F["この記事には3つの都市が言及されています。地図上にその場所をマークしてください。"]
end
C --> F未来のCAPTCHAの例:
ユーザーがページにアクセス → LLMがページの内容を理解 → 意味的に関連する検証質問を生成。
- "この記事には3つの都市が言及されています。地図上にその場所をマークしてください。"
これは記事の内容、地理的知識、画像との相互作用を必要とし、自動回避は非常に高コストになりますが、人間ユーザーには管理可能です。
4.3 フェーズ3: 継続的信頼エンジン(中期 - 遠未来)
最終的な目標は、明示的なCAPTCHAの「消失」であり、ユーザーが検証ステップを意識することなく、継続的でバックグラウンドの信頼評価に置き換えられます。システムはリアルタイムの行動シグナルに基づいて信頼を常に評価します。
mermaid
graph TD
A[ユーザーがアプリを開く] --> B[バックグラウンド: 行動シグナルを収集]
B --> C[LLM: リアルタイム信頼スコア計算]
C --> D{信頼スコア > 閾値?}
D -- Yes --> E[スムーズな操作]
D -- No (サイレントダウングレード) --> F[制限された機能]
D -- No (明示的な検証) --> G[CAPTCHA/介入をトリガー]2030年の仮定された検証体験:
ユーザーがアプリを開く → バックグラウンドで継続的に行動シグナルを収集 → LLMがリアルタイム信頼スコアを計算。
- 信頼スコア > 閾値: すべての操作がスムーズに進行します。
- 信頼スコア < 閾値: 一部の機能がサイレントダウングレードされます。
- 信頼スコア << 閾値: 明示的な検証または介入をトリガーします。
ユーザーは「私はロボットではありません」とクリックする必要がなく、本当にスムーズで効率的な体験を実現します。
4.4 さらに進化: AIネイティブ検証の先駆け
また、我々は「AI特化型CAPTCHA」などの先進的なコンセプトを探索しています。これは、人間アシスタントを使用するユーザー(例: AIアシスタントを活用するユーザー)と完全な自動スクリプトを区別するように設計されています。AIアシスタントが一般的になると、この区別は公正で安全なデジタル相互作用を維持するために重要になります。
⚠️ V. ベンチマークと責任あるAIの実装
LLMは効率に関する画期的な機会を提供しますが、我々はAIの実装において責任あるアプローチを強調し、透明性と倫理的考慮を最優先にしています:
mermaid
graph TD
A[LLM駆動の自動化] --> B{透明性を最優先}
A --> C{コスト制御}
A --> D["セーフティネット: 人間がループ内"]
B --> B1["データプライバシー保護"]
B --> B2[バイアス低減]
B --> B3[説明可能な分析]
C --> C1[最適化されたモデル推論]
C --> C2[高ROI vs. 手動処理]
D --> D1[人間の監視]
D --> D2[複雑なシナリオの手動レビュー]重要な考慮事項:
- データプライバシー: すべてのデータ収集と処理がグローバルなプライバシー保護基準に準拠していることを確保します。
- バイアス低減: LLM駆動の意思決定における潜在的なバイアスを継続的に監視し、公平性を確保します。
- 透明性と説明可能性: ユーザーの摩擦がある場合でも、LLMが検証決定をどのように行うかを明確に説明します。
- 人間がループ内: 複雑または曖昧なシナリオでの人間の監視と介入のメカニズムを維持します。
コア原則: AI駆動の決定が主であり、ルールベースのフォールバックと人間-AI協働により、強固で倫理的な運用が保証されます。
💡 VI. 企業向けアクション戦略: 知的自動化を活用する
LLM駆動の自動化の力を活用するため、企業は以下の戦略を採用できます:
- 📊 現在の状態を評価する: オープンソースOCR/検出モデルに対する既存の検証システムの脆弱性を評価し、偽陽性率、ユーザー苦情率、自動化成功率などの主要指標を分析します。
- 🧪 パイロットと反復: 低リスクのビジネスラインから「スムーズな検証」または「動的難易度」ソリューションのパイロットを開始します。新しい戦略の影響を測定するためのA/Bテストフレームワークを構築します。
- 📚 トレンドを先取りする: 生成AI(例: Diffusionモデル)やマルチモーダルLLMの進展を監視し、検証と自動化への応用を確認します。業界セキュリティカンファレンス(例: BlackHat、DEF CON、RSA)に参加し、最新情報を得ます。
- 🗄️ データ中心のアプローチ: 「人間と機械の行動の違い」を捉えた高品質なデータセットを構築し始めましょう。プライバシーを保護しながら協働型データインテリジェンスを探索してください。
- 👥 クロスファンクショナルコラボレーション: AIエンジニア、セキュリティ研究者、製品マネージャー、専門家からなるチームを育成してください。定期的な内部赤チーム演習を実施し、知識共有メカニズムを確立してください。
🎯 結論: 検証の未来はシームレスな効率性
CAPTCHAの25年の歴史は、以下のサイクルを明らかにしています: AIの作成 → AI防御のためのCAPTCHA → AIがCAPTCHAを回避 → CAPTCHAのアップグレードが人間を困惑させる → 人間がAIを無料で訓練 → AIがより強力になる... しかし、大規模言語モデル(LLM)の登場により、パラダイムシフトが起こっています。
知能型AIオートメーションインフラによって、検証は単なる障害ではなくなります。**「信頼膜」**としてビジネス運営をシームレスに包み込み、静かにリスクを感知し、動的に強度を調整し、セキュリティとユーザー体験の最適なバランスを取るようになります。
検証の究極の形態は**「シームレスな効率性」**です。セキュリティの必要性が消えるわけではないですが、検証が目に見えない形で統合されるのです。我々の目標は、90%の正当なユーザーが検証ステップを一度も感じることなく、100%の不正な自動化が経済的に持続不可能なコストを負うことを保証することです。
自動化されたCAPTCHA認識ソリューションの世界的リーディングプロバイダーとして、我々はビジネスプロセスの摩擦を排除するイノベーションにコミットしています。よりスマートで効率的なオートメーションエコシステムを構築し、企業が検証の課題に悩まされることなく、コア成長に注力できるようにすることを目指しています。
より効率的なオートメーションシステムの構築を開始する
複雑な検証環境でより安定した効率的なオートメーションプロセスを達成しようとしている場合、信頼性の高いAIオートメーションインフラが鍵となります。
👉 CapSolver で以下が可能です:
- 主流のCAPTCHAタイプの自動認識と処理を実現
- 手動介入コストを削減し、プロセスの連続性を向上
- ダイナミックな検証環境で安定した成功確率を維持
- 既存のビジネスシステムと迅速に統合
データ収集、成長自動化、複雑なビジネスプロセスの最適化に関わらず、CapSolverはより効率的なオートメーションシステムを構築するための基盤となる能力となります。
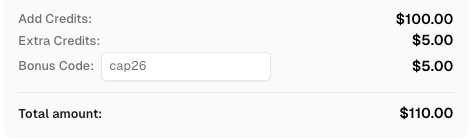
🎁 エクスクルーシブな特典
CapSolverに登録する際、コード
CAP26を使用してボーナスクレジットを獲得してください!
もっと見る
AIMar 27, 2026
LLMトレーニングのためのデータ収集のスケーリング: CAPTCHAをスケールで解く
大規模言語モデルのトレーニングのためのデータ収集をスケールする方法を学びましょう。大規模にCAPTCHAを解くことで、AIモデル用の高品質なデータセットを構築するための自動化された戦略を発見しましょう。

AIMar 24, 2026
CAPTCHAを解決する方法 OpenBrowserで CapSolverを使用して (AIエージェントオートメーションガイド)
OpenBrowserでCAPTCHAを解くためにCapSolverを使用してください。AIエージェント用にreCAPTCHA、Turnstileなど簡単に自動化します。