PuppeteerとNodeJSを使用したWebスクレイピングの方法 | Puppeteerチュートリアル

Sora Fujimoto
AI Solutions Architect

ウェブスクラッピングは、ウェブサイトからデータを抽出するための強力な技術です。このチュートリアルでは、ウェブ開発エコシステムで人気のあるPuppeteerとNode.jsを使用してウェブスクラッピングを実行する方法について説明します。Puppeteerは、ヘッドレスChromeまたはChromiumブラウザを制御するためのNode.jsライブラリです。ブラウザの操作を自動化し、ウェブページをナビゲートし、必要なデータを抽出できます。Node.jsの柔軟性とPuppeteerを組み合わせることで、信頼性の高い効率的なウェブスクラッピングソリューションを構築できます。Puppeteerを使用してウェブサイトをスクラップする手順について見ていきましょう。
Puppeteerとは何ですか?
Puppeteerは、Google Chromeでヘッドレスブラウザテストを行うための先進的なフレームワークです。Puppeteerテストでは、リンクをクリックしたり、フォームに入力したり、ボタンを送信したりするなどのJavaScriptコマンドを実行して、ウェブページと対話できます。
Googleによって開発されたPuppeteerは、DevToolsプロトコルを通じてヘッドレスChromeをシームレスに制御するためのNode.jsライブラリです。自動テスト、ウェブ機能の開発、デバッグ、要素の検査、パフォーマンスのプロファイリングなど、さまざまな高レベルAPIを提供します。
Puppeteerを使用すると、(ヘッドレス)ChromiumまたはChromeでウェブサイトを開き、フォームを埋め、ボタンをクリックし、データを抽出し、コンピュータを使用する人間が行うことができる一般的な操作を行うことができます。これは、ウェブスクラッピングだけでなく、ウェブ上の複雑なワークフローを自動化するための非常に強力なツールになります。現代のウェブ開発の文脈において、テスト担当者や開発者にとってPuppeteerとその機能を明確に理解することは非常に価値があります。
ウェブスクラッピングにPuppeteerを使用する利点は何ですか?
AxiosとCheerioはJavaScriptでスクラッピングするための優れたオプションです。しかし、これには2つの問題があります:動的コンテンツのクロールとアンチスクラッピングソフトウェア。Puppeteerはヘッドレスブラウザなので、動的コンテンツのスクラッピングに問題ありません。
また、Puppeteerはウェブスクラッピングにおいて一連の重要な利点を提供しています:
-
ヘッドレスブラウザの自動化:Puppeteerを使用すると、表示されるブラウザウィンドウなしで、クリック、スクロール、フォームの入力、データ抽出などのブラウザ操作をプログラムで制御できます。
-
完全なChrome機能とDOM操作:PuppeteerはChromeの完全な機能へのアクセスを提供し、JavaScriptを多く使用する現代的なウェブサイトのスクラッピングに適しています。ページの要素と対話したり、属性を変更したり、ボタンのクリックやフォームの送信などの操作を簡単に実行できます。
-
ユーザーの操作をシミュレートし、ネットワークリクエストとレスポンスをキャプチャ:Puppeteerはユーザーの操作をシミュレートし、ネットワークリクエストとレスポンスをキャプチャできます。これにより、ユーザー入力が必要なページやAJAXやWebSocketリクエストで動的にコンテンツを読み込むページのスクラッピングが可能になります。
-
パフォーマンスとデバッグ機能:Puppeteerの最適化されたChromeエンジンにより、効率的なスクラッピングが可能です。DevToolsとの統合により、強力なデバッグとテスト機能が利用できます。ウェブページのデバッグ、コンソールメッセージのログ、ネットワークアクティビティのトレース、パフォーマンスメトリクスの分析が可能です。
以降のガイドでは、ウェブスクラッピング中に遭遇する主要な課題の1つであるCAPTCHAを克服するため、CapSolverを統合したPuppeteerとNode.jsを使用したウェブスクラッピングのプロセスについて探っていきます。
ボーナスコード
最高のCAPTCHAソリューションのボーナスコード; CapSolver : WEBS。コードを有効にすると、各再充電後に5%のボーナスが追加され、無制限になります。

CapSolverを使用してPuppeteerでCAPTCHAを解く方法
この目標は、recaptcha-demo.appspot.comに配置されているCAPTCHAをCapSolverを使用して解くことです。
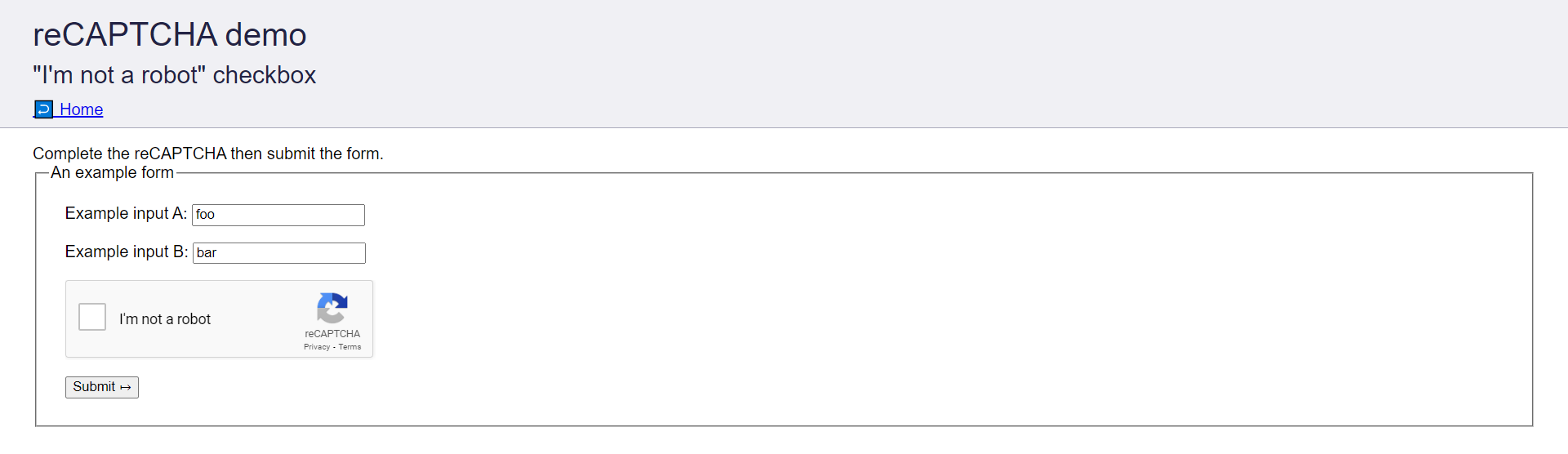
チュートリアル中に、上記のCAPTCHAを解くために以下の手順を実施します:
- 必要な依存関係をインストールします。
- CAPTCHAフォームのサイトキーを取得します。
- CapSolverを設定します。
- CAPTCHAを解きます。
必要な依存関係のインストール
まず、このチュートリアルに必要な依存関係をインストールする必要があります。
- capsolver-python: CapSolver APIとの簡単な統合に使用する公式のPython SDKです。
- pyppeteer: PuppeteerのPython版です。
以下のコマンドを実行して、これらの依存関係をインストールします:
python -m pip install pyppeteer capsolver-python次に、CAPTCHAの解決用のPythonコードを記述するためのファイルmain.pyを作成します。
bash
touch main.pyCAPTCHAフォームのサイトキーの取得
サイトキーは、Googleが提供する各CAPTCHAを一意に識別する識別子です。
CAPTCHAを解くには、サイトキーをCapSolverに送信する必要があります。
CAPTCHAフォームのサイトキーを取得するには、以下の手順に従います:
- CAPTCHAフォームにアクセスします。
Ctrl/Cmd+Shift+Iを押してChromeのDevToolsを開きます。Elementsタブに移動し、data-sitekeyを検索します。属性の値をコピーします。
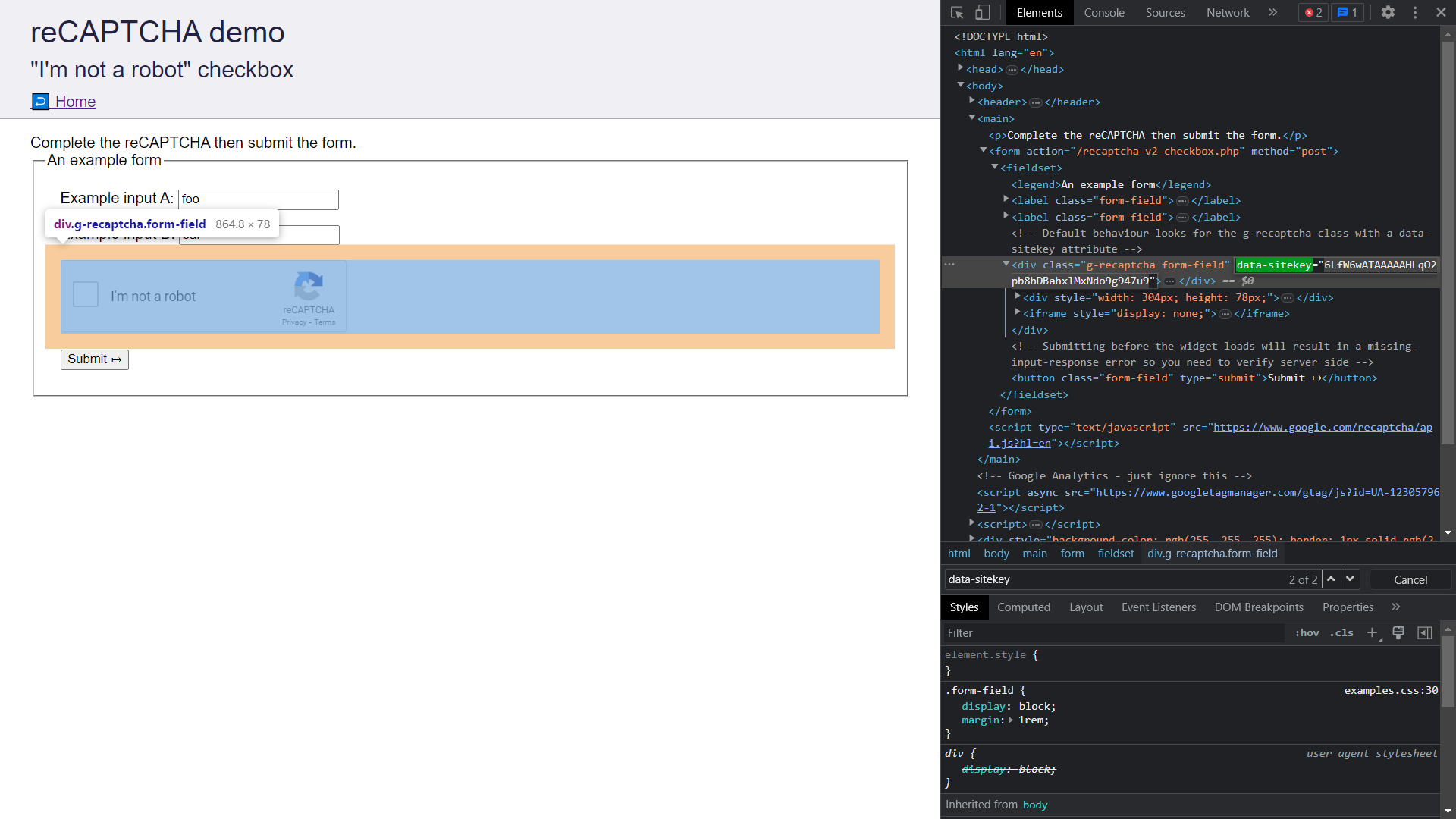
- 以降のセクションでCAPTCHAをCapSolverに送信する際に使用するため、サイトキーを安全な場所に保存します。
CapSolverの設定
CapSolverを使用してCAPTCHAを解くには、CapSolverアカウントを作成し、アカウントに資金を追加し、APIキーを取得する必要があります。CapSolverアカウントの設定には以下の手順を実施してください:
-
CapSolverにアクセスしてアカウントを登録します。
-
PayPal、暗号通貨、または他の掲載された支払い方法を使用してCapSolverアカウントに資金を追加します。最低入金額は6ドルであり、追加の税金が適用される点に注意してください。
-
CapSolverが提供するAPIキーをコピーし、後で使用するために安全な場所に保存します。
CAPTCHAの解き方
ここでは、CapSolverを使用してCAPTCHAを解く方法について説明します。全体的なプロセスは以下の3つのステップで構成されます:
- pyppeteerを使用してブラウザを起動し、CAPTCHAページにアクセスします。
- CapSolverを使用してCAPTCHAを解きます。
- CAPTCHAの応答を送信します。
これらのステップを理解するには、以下のコードスニペットを参照してください。
ブラウザの起動とCAPTCHAページへのアクセス:
python
# ブラウザを起動します。
browser = await launch({'headless': False})
# ターゲットページを読み込みます。
captcha_page_url = "https://recaptcha-demo.appspot.com/recaptcha-v2-checkbox.php"
page = await browser.newPage()
await page.goto(captcha_page_url)CapSolverを使用したCAPTCHAの解き方:
python
# CapSolverを使用してreCAPTCHAを解きます。
capsolver = RecaptchaV2Task("YOUR_API_KEY")
site_key = "6LfW6wATAAAAAHLqO2pb8bDBahxlMxNdo9g947u9"
task_id = capsolver.create_task(captcha_page_url, site_key)
result = capsolver.join_task_result(task_id)
# 解決されたreCAPTCHAコードを取得します。
code = result.get("gRecaptchaResponse")解決されたCAPTCHAをフォームに設定し、送信します:
python
# 解決されたreCAPTCHAコードをフォームに設定します。
recaptcha_response_element = await page.querySelector('#g-recaptcha-response')
await page.evaluate(f'(element) => element.value = "{code}"', recaptcha_response_element)
# フォームを送信します。
submit_btn = await page.querySelector('button[type="submit"]')
await submit_btn.click()すべてをまとめたコード
以下は、このチュートリアルの完全なコードです。このコードはCapSolverを使用してCAPTCHAを解きます。
python
import asyncio
from pyppeteer import launch
from capsolver_python import RecaptchaV2Task
# 以下は、CapSolverを使用してreCAPTCHA v2チャレンジを解決するコードです。
async def main():
# ブラウザを起動します。
browser = await launch({'headless': False})
# ターゲットページを読み込みます。
captcha_page_url = "https://recaptcha-demo.appspot.com/recaptcha-v2-checkbox.php"
page = await browser.newPage()
await page.goto(captcha_page_url)
# CapSolverを使用してreCAPTCHAを解きます。
print("CAPTCHAを解決中")
capsolver = RecaptchaV2Task("YOUR_API_KEY")
site_key = "6LfW6wATAAAAAHLqO2pb8bDBahxlMxNdo9g947u9"
task_id = capsolver.create_task(captcha_page_url, site_key)
result = capsolver.join_task_result(task_id)
# 解決されたreCAPTCHAコードを取得します。
code = result.get("gRecaptchaResponse")
print(f"reCAPTCHAを成功裏に解決しました。解決コードは{code}です")
# 解決されたreCAPTCHAコードをフォームに設定します。
recaptcha_response_element = await page.querySelector('#g-recaptcha-response')
await page.evaluate(f'(element) => element.value = "{code}"', recaptcha_response_element)
# フォームを送信します。
submit_btn = await page.querySelector('button[type="submit"]')
await submit_btn.click()
# 送信後に画面を確認できるように実行を一時停止します
input("CAPTCHA送信成功。Enterキーを押して続行してください")
# ブラウザを閉じます。
await browser.close()
if __name__ == "__main__":
asyncio.get_event_loop().run_until_complete(main())上記のコードをmain.pyファイルに貼り付け、YOUR_API_KEYをAPIキーに置き換えてコードを実行してください。
CAPTCHAが解決され、成功ページが表示されることに気付くでしょう。
NodeJSでCapSolverを使用してCAPTCHAを解く方法
必要条件
- プロキシ (オプション)
- Node.JSがインストールされていること
- Capsolver APIキー
ステップ1: 必要なパッケージをインストール
以下のコマンドを実行して必要なパッケージをインストールしてください:
python
npm install axiosプロキシなしでreCaptcha v2を解くNode.JSコード
このタスクを実行するためのNode.JSのサンプルスクリプトは以下の通りです:
js
const axios = require('axios');
const PAGE_URL = ""; // ご自身のウェブサイトに置き換えてください
const SITE_KEY = ""; // ご自身のウェブサイトのサイトキーに置き換えてください
const CLIENT_KEY = ""; // ご自身のCAPSOLVER APIキーに置き換えてください
async function createTask(payload) {
try {
const res = await axios.post('https://api.capsolver.com/createTask', {
clientKey: CLIENT_KEY,
task: payload
});
return res.data;
} catch (error) {
console.error(error);
}
}
async function getTaskResult(taskId) {
try {
success = false;
while(success == false){
await sleep(1000);
console.log("タスクID: " + taskIdのタスク結果を取得中");
const res = await axios.post('https://api.capsolver.com/getTaskResult', {
clientKey: CLIENT_KEY,
taskId: taskId
});
if( res.data.status == "ready") {
success = true;
console.log(res.data)
return res.data;
}
}
} catch (error) {
console.error(error);
return null;
}
}
async function solveReCaptcha(pageURL, sitekey) {
const taskPayload = {
type: "ReCaptchaV2TaskProxyless",
websiteURL: pageURL,
websiteKey: sitekey,
};
const taskData = await createTask(taskPayload);
return await getTaskResult(taskData.taskId);
}
function sleep(ms) {
return new Promise(resolve => setTimeout(resolve, ms));
}
async function main() {
try {
const response = await solveReCaptcha(PAGE_URL, SITE_KEY );
console.log(`受け取ったトークン: ${response.solution.gReCaptcharesponse}`);
}
catch (error) {
console.error(`エラー: ${error}`);
}
}
main();👀 詳細情報
結論:
このチュートリアルでは、CapSolverを使用して、PuppeteerとNode.jsでウェブスクラッピングを行う際にCAPTCHAを解決する方法について学びました。CapSolverのAPIを活用することで、CAPTCHA解決プロセスを自動化し、ウェブスクラッピングタスクをより効率的で信頼性の高いものにできます。スクラップするウェブサイトの利用規約に従い、ウェブスクラッピングを責任を持って行うことを忘れないでください。
もっと見る
Web ScrapingApr 22, 2026
Rust Web Scraping Architecture for Scalable Data Extraction
スケーラブルなRustウェブスクレイピングアーキテクチャを学びましょう。リクエスト、スクレイパー、非同期スクレイピング、ヘッドレスブラウザスクレイピング、プロキシローテーション、およびコンプライアンス対応のCAPTCHA処理で。
Web ScrapingFeb 10, 2026
データ・アズ・ア・サービス(DaaS):それは何か、そしてなぜ2026年において重要なのか
2026年のデータ・アズ・ア・サービス(DaaS)を理解する。その利点、ユースケース、およびリアルタイムの洞察と拡張性を通じて企業を変革する方法について探る。
