Python Requestsを用いたCAPTCHAチャレンジの解決方法

Emma Foster
Machine Learning Engineer

イライラするCAPTCHA…
1. CAPTCHA解決の重要性

永遠の闘争 - CAPTCHAは人間とボットを区別しようとします
CAPTCHAはウェブサイトをスパムから保護しますが、以下のような正当な自動化をブロックする可能性があります。
- 研究プロジェクト: 学術研究や市場調査では、ウェブサイトから大規模なデータ収集が必要になることがよくあります。
- アクセシビリティツール: 障害のあるユーザーを支援するために設計されたツールは、コンテンツを提供するためにCAPTCHAを操作する必要がある場合があります。
- データ移行スクリプト: システム間でデータ転送を行う場合、自動化されたスクリプトがCAPTCHAに遭遇する可能性があります。
- 学術研究: インターネットのトレンド、ユーザーの行動、またはテクノロジーの採用に関する研究でデータ収集を行う研究者。
- 価格比較と市場分析: 市場トレンドを分析するために、eコマースサイトから製品価格をスクレイピングします。
- eコマース製品スクレイピング: 競合他社のウェブサイトを監視して、製品の可用性と価格を追跡します。
- 広告検証: オンライン広告が正しく表示され、ボットによって操作されていないことを確認します。
- SEOとウェブサイト監視: ウェブサイトのパフォーマンス、稼働時間、コンテンツの変更を自動的にチェックします。
- ソーシャルメディアデータ収集: 感情分析のために、ソーシャルプラットフォームから公開投稿やトレンドを集約します。
- サイバーセキュリティ研究: 潜在的な脆弱性を分析したり、セキュリティ対策の堅牢性をテストしたりします。
- コンテンツ集約: ニュース集約サービスのために、記事やブログ投稿を自動的に収集します。
2. ツールキットの設定
あなたのCapsolverダッシュボード - APIキーが存在する場所
必要なものをインストールします。
bash
pip install requestsAPIキーを取得します。
- capsolver.comでアカウントを作成します。
- APIの概要に移動します。
clientKeyをコピーします。
3. 手順による実装
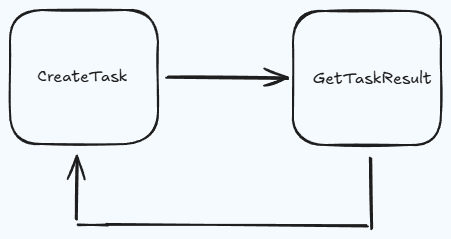
CAPTCHA解決プロセスがどのように機能するか
完全なコードの概要:
python
# pip install requests
import requests
import time
# TODO: 構成を設定します
api_key = "YOUR_API_KEY" # capsolverのAPIキー
site_key = "6Le-wvkSAAAAAPBMRTvw0Q4Muexq9bi0DJwx_kl-" # ターゲットサイトのサイトキー
site_url = "" # ターゲットサイトのページURL
def capsolver():
payload = {
"clientKey": api_key,
"task": {
"type": 'ReCaptchaV3TaskProxyLess',
"websiteKey": site_key,
"websiteURL": site_url,
"pageAction": "login",
}
}
res = requests.post("https://api.capsolver.com/createTask", json=payload)
resp = res.json()
task_id = resp.get("taskId")
if not task_id:
print("タスクの作成に失敗しました:", res.text)
return
print(f"taskIdを取得しました: {task_id} / 結果を取得しています...")
while True:
time.sleep(1) # 遅延
payload = {"clientKey": api_key, "taskId": task_id}
res = requests.post("https://api.capsolver.com/getTaskResult", json=payload)
resp = res.json()
status = resp.get("status")
if status == "ready":
return resp.get("solution", {}).get('gRecaptchaResponse')
if status == "failed" or resp.get("errorId"):
print("解決に失敗しました!レスポンス:", res.text)
return
token = capsolver()
print(token)4. タスクの種類について
遭遇する一般的なCAPTCHAの種類
| タスクの種類 |
|---|
| ReCaptchaV2Task / ReCaptchaV2TaskProxyless |
| ReCaptchaV3Task / ReCaptchaV3TaskProxyless |
| GeeTestTask / GeeTestTaskProxyless |
| AntiTurnstileTaskProxyless |
| ImageToTextTask |
5. 一般的な問題のトラブルシューティング

CAPTCHAソリューションが失敗した場合…
一般的な修正:
- APIキーの権限を再確認します。
- ウェブサイトのURL、websiteKey、pageAction、またはその他の必須/オプションのパラメーターが完全に一致していることを確認します。
- さまざまなCAPTCHAの種類でテストします。
- capsolverサポートにお問い合わせください。
