CAPTCHA AI 大規模モデルを用いた: なぜ企業向けシナリオに適しているのか

Sora Fujimoto
AI Solutions Architect

CAPTCHA技術は、AI視覚認識能力によって再定義されています。多くの人々はCAPTCHAを単なる「コンポーネント」と見なしていますが、現実の自動処理環境において、それはAI視覚技術と検証メカニズムの継続的な進化となっています。
I. CAPTCHAの進化:OCRからAI視覚認識へ
1. 第1世代:OCR時代(2000-2010)
技術的背景
インターネットの初期に直面した主要な問題は、スパムと自動プログラムの悪用でした。reCAPTCHAは画期的なシステムとして登場し、単純な設計哲学を採用しました:人間の視覚認識の優位性を活かして、機械が克服しにくいバリアを作り出しました。
典型的な実装
- ひずんだ英語の文字列(4〜6桁)
- 干渉線、ノイズ、背景テクスチャの追加
- 色のコントラスト干渉
自動認識技術の進化
| フェーズ | 技術方法 | 認識効率 |
|---|---|---|
| 2003-2005 | 伝統的なOCR(Tesseract)+ ルール修正 | 30〜50% |
| 2005-2008 | 画像前処理(ノイズ除去、二値化、セグメンテーション)+ SVM | 60〜80% |
| 2008-2010 | 畳み込みニューラルネットワーク(LeNet-5の改良版) | 90%+ |
画期的な出来事
2008年にScienceに掲載された研究は、テキストベースのCAPTCHAの機械認識率が急速に向上していることを示しました。これは第2世代のCAPTCHAの登場を直接促しました。
核心的な洞察: 固定された文字セット + 限られた歪みルール = 累積可能なデータセット = 自動システムによって簡単に認識される。
2. 第2世代:行動 + 画像の課題(2010-2020)
パラダイムシフト
CAPTCHAの設計者は、単に認識の難易度を上げても、実際のユーザー体験に悪影響を与えることを認識しました。これにより、「人間だけが持つ能力」—意味理解と行動パターンの導入が求められました。
3つの主要な商用システムの分析
reCAPTCHA(Google)
- v2(2014): 「私はロボットではありません」のチェックボックス + 隠しリスク分析
- コア技術: リスク分析エンジン、100以上のシグナル(Cookie、デバイス履歴、微細なマウス動作、ページインタラクションタイミング)を基盤としています
- 画像課題: ストリートビューから抽出された現実のシーン(信号機、歩道橋、バス)、クラウドソーシングラベリングを通じて自動運転モデルを同時に訓練
GCaptcha(Intuition Machines)
- 差別化された位置付け: プライバシー第一、ユーザーの個人データを追跡しないと主張
- 技術的特徴: 分散検証アーキテクチャ、クライアントの独自データセットからのチャレンジ画像、検証をラベリングとしてのビジネスモデルを形成
- 検証設計: ダイナミックな難易度調整、自動処理の圧力に応じてチャレンジタイプをリアルタイムで切り替え
GeeTest
- コアイノベーション: スライダー検証 + パズルの復元、認識を「操作」に変換
- 行動データの収集: 軌跡座標シーケンス(通常50〜200ポイント)、速度曲線、加速度の変化、タッチイベント(モバイル)
- リスクコントロールの次元: 通過/失敗の判定だけでなく、ビジネスレベルの意思決定に使用する「人間の信頼スコア」を出力
自動処理技術の発展
| 自動化タイプ | 技術方法 | 検証者の対応 |
|---|---|---|
| 自動画像認識 | オブジェクト検出(YOLO/Faster R-CNN)+ セマンティックセグメンテーション | ダイナミック画像生成、敵対的サンプル |
| スライダー軌跡シミュレーション | フィジックスエンジンシミュレーション(ベジエ曲線、ノイズ注入) | 時系列分析、バイオメトリック認識 |
| クラウドソーシングプラットフォーム処理 | クラウドソーシングプラットフォーム(1000件あたり$0.5〜2) | レート制限、相関分析、評判システム |
| ブラウザ自動化 | Selenium, Puppeteer, Playwright | ブラウザファンタム検出、自動特徴認識 |
核心的な課題
第2世代システムの核心的な仮定は、自動プログラムがスケールして人間の行動をシミュレートできないことでした。しかし、ディープラーニングの発展により、この仮定は挑戦されています:
- 軌跡生成: GANは実際のユーザーのマウス動作の動的特性を学ぶことができます
- 画像理解: Vision Transformers (ViT)のImageNetでのブレイクスルーにより、機械視覚は人間に近づいています。
- ブラウザファンタム: 自動化フレームワークのファントムをランダム化する技術はますます洗練されています
核心的な洞察: いかに巧妙に設計された固定チャレンジでも、結局は「標準的な答えのある試験」です。標準的な答えがあれば、それらは収集、学習、最終的に自動プログラムによって処理されます。
II. AI視覚認識技術の開発と課題
1. 自動認識の産業化システム
現代のCAPTCHA自動認識は、非常に専門的な技術スタックを持つ完全な産業化システムを形成しています:
データ層
- 収集システム: 分散型クローラークラスタ、24/7でターゲットサイトからのチャレンジを取得
- ラベリング工場: 低コストなデータラベリングチーム、または半自動ラベリングツール(SAM支援)
- データ拡張: 回転、クロッピング、色変換、敵対的ノイズを用いてトレーニングセットの多様性を拡大
モデル層
| タスクタイプ | モデルアーキテクチャ | オープンソース実装の参考 |
|---|---|---|
| 文字認識 | CRNN + CTC | PaddleOCR、EasyOCR |
| オブジェクト検出 | YOLOv8、RT-DETR | Ultralytics |
| 画像分類 | ViT、ConvNeXt | Hugging Face Transformers |
| スライダー軌跡 | Seq2Seq、Diffusion Model | コミュニティオープンソースソリューション |
| 多モーダル理解 | CLIP、LLaVA | OpenAI CLIP、アリババQwen-VL |
エンジニアリング層
- 推論最適化: ミリ秒単位の応答を実現するTensorRT、ONNX Runtime、OpenVINO
- サービスアーキテクチャ: Kubernetesオーケストレーション、オートスケーリング、高同時接続要求をサポート
- 自動回避: ブラウザファントムのランダム化、IPプロキシプール、行動リズムシミュレーション
OpenClaw現象の分析
最近人気の高いOpenClawプロジェクトは、「AI視覚認識ツールの民主化」の傾向を示しています:
- 低障壁: 事前学習モデル + 設定ファイルで特定の目的をターゲットに
- モジュラリティ: データ収集、モデルトレーニング、推論サービス、結果提出の分離
- コミュニティ駆動: 認識サンプル、モデル重み、反復的な技術ソリューションの共有
企業への影響: 以前は専門のセキュリティチームが必要だった自動認識の実装が、今では普通の開発者でも迅速に採用できるようになりました。これはCAPTCHA検証メカニズムの技術要件を大幅に引き上げています。
2. 検証メカニズム: 「静的チャレンジ」から「動的リスク管理」へ
パラダイムシフト: 行動モデリングの台頭
企業向けCAPTCHAシステムの核心的な変化は、「回答の正しさを検証する」から「行動の真実性を評価する」へと移行しています。これは金融リスク管理の進化、つまり「ルールエンジン」から「機械学習スコアカード」への変化に似ています。
多次元行動ファイントプリントシステム
| データ収集次元 | 技術指標 | AI分析方法 |
|---|---|---|
| マウスダイナミクス | 軌跡点密度、速度曲線、加速度分布、角度変化 | LSTM/Transformer時系列モデリング、実際のユーザーのベースライン分布との比較 |
| キーボードインタラクション | キー押下インターバル(Keydown-Keyup)、キーコンビネーションパターン、修正行動(バックスペース頻度) | リズム分析、自動化ツールの均一インターバル特性の検出 |
| タッチイベント(モバイル) | 圧力値、接触面積、スライディングインパクト、マルチタッチパターン | バイオメトリック認識、人間の指とロボットアーム/シミュレーターの区別 |
| 視覚的注意 | オプション許可の場合の目線追跡、ページスクロールパターン、要素フォーカスタイミング | 注意熱マップ分析、非人間のブラウジングパターンの検出 |
| 認知反応時間 | チャレンジ提示から最初のインタラクションまでの遅延、意思決定時間分布 | 統計的テスト、自動化ツールは通常速すぎるか遅すぎる |
| 環境的文脈 | デバイス姿勢(ジャイロスコープ)、バッテリー状態、ネットワーク遅延の変動 | 異常検出、仮想マシン/シミュレーター/クラウド電話の識別 |
大規模モデルの重要な役割
従来のルールエンジンは、高次元で非線形な行動シーケンスを処理することが困難です。大規模モデル(特にトランスフォーマー構造)が突破をもたらします:
- 表現学習: ラフな行動シーケンスを低次元埋め込みに符号化して、深いパターンを捉える
- 転移学習: 大量の非教師あり行動データで事前学習し、小さなサンプルで微調整して新しいシナリオに適応
- マルチモーダル統合: 画像、時系列、カテゴリカル特徴の統一処理でエンドツーエンド最適化
III. なぜ大規模モデルのCAPTCHA視覚認識が企業シナリオに適しているのか
データフライホイール: データ支配の時代、企業の独自の競争優位
自動認識者と検証者のデータ比較
| データタイプ | 自動認識者に利用可能 | 企業検証者によって実際に所有 | 戦略的価値 |
|---|---|---|---|
| 成功認識ケース | ✅ 限られたサンプル(高コストで収集が必要) | ✅ 大量の失敗ケース(自動認識ログ) | 自動パターン認識モデルのトレーニング |
| 実際のユーザー行動 | ❌ スケールで取得困難 | ✅ 全ビジネストラフィック | 人間行動ベースラインの構築 |
| 自動ツールファントム | ❌ 被動的に発見 | ✅ 主動的な検出 + ハニーポット収集 | 自動化フレームワークの特徴の特定 |
| 時系列相関データ | ❌ 単一点の視点 | ✅ ビジネスライン全体のグローバルビュー | 相関分析、組織的な自動化行動の特定 |
継続的な学習ループ
[生産トラフィック] → [行動データ収集] → [特徴工学] → [モデル推論] → [リスクスコア]
↑ ↓
[モデル更新] ← [パフォーマンス評価] ← [ラベリングフィードバック] ← [ビジネス決定]
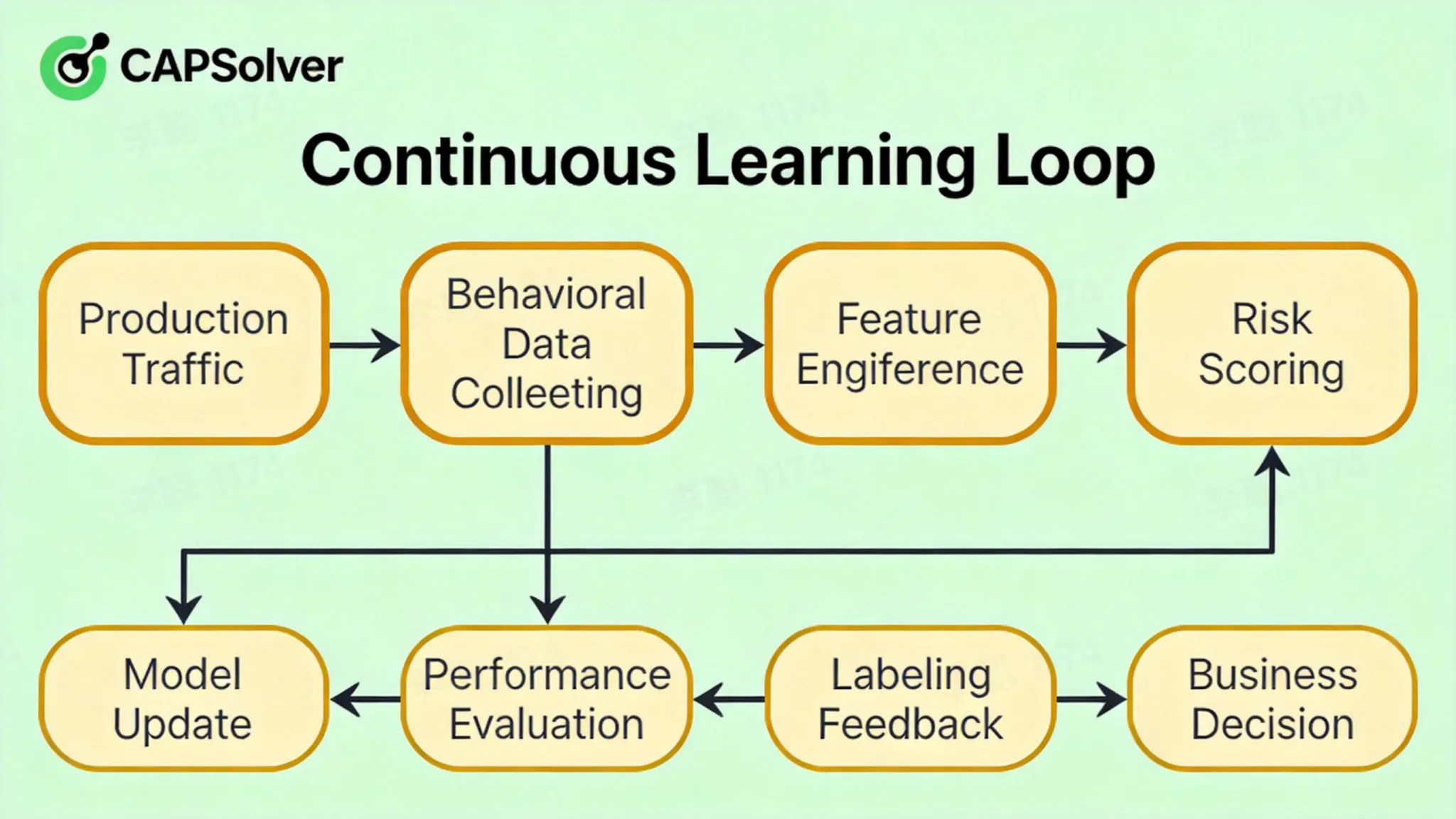
- オンライン学習: 新しいデータでモデルパラメータをリアルタイムで微調整、完全な再トレーニングは不要
- アクティブ学習: 高価値サンプルを知的に選択して手動ラベリング、ラベリングROIを最適化
- 敵対的トレーニング: 自動認識サンプルをネガティブ例として使用して、ロバスト性を向上
ビジネスリスク管理との深い統合
| 統合シナリオ | 技術実装 | ビジネス価値 |
|---|---|---|
| ログイン保護 | CAPTCHAスコア + デバイスファントム + IP評判 → 統一リスクスコア | 自動ログインを正確にブロック、誤検出を減らす |
| 登録詐欺防止 | 異常な検証行動 → 電話/メールの2次確認をトリガー | バッチ登録を特定、ユーザーープールの品質を保護 |
| マーケティング活動 | フラッシュセールのシナリオ、リアルタイム人間機械認識 → ダイナミックレート制限 | 自動スナッチングを防ぎ、実際のユーザー権利を保護 |
| 支払いセキュリティ | 高リスク操作前の必須検証 + 行動レビュー → 自動詐欺取引をブロック、資産損失を減らす |
現代の自動化に関するさらに深い洞察については、CAPTCHAでWeb自動化がなぜ失敗するのかをご覧ください。
IV. プライベート展開の進化経路
実験から本番への典型的な旅
第1段階: 概念実証(PoC、1〜2か月)
- シナリオ: セキュリティチームが既存CAPTCHAの脆弱性を評価する、またはビジネス側が検証体験の悪さを不満に述べる
- アクション: OpenClawなどのツールを使用して自動認識をシミュレートし、認識コストと成功確率を定量化する
- 出力: 自動認識の実現可能性報告書、初期ROI推定
第2段階: パイロット展開(Pilot、3〜6か月)
- 技術スタック: オープンソースモデル(YOLO + ResNet) + 自社ラベリングチーム
- 主要な課題:
- モデルの汎化が悪い、新しい自動化タイプが出現すると急速に失敗
- 推論遅延が高く、ユーザー体験に悪影響
- 行動分析の次元が不足、画像認識に依存
- 重要な決定: MLOpsプラットフォームの構築にリソースを投資するか、商用ソリューションを購入するか
第3段階: 大規模な本番(Production、6〜12か月)
- アーキテクチャのアップグレード:
- 推論レイヤー: Triton Inference Server + TensorRT、GPU利用効率最適化
- データレイヤー: 実時間特徴ストア(Redis/Flink) + オフラインデータレイク(Iceberg/Delta Lake)
- トレーニングレイヤー: Kubeflow/MLflowで実験とモデルバージョンを管理
- 組織の発展: 専門のAIセキュリティチームを設立(アルゴリズムエンジニア + バックエンドエンジニア + セキュリティアナリスト)
第4段階: プラットフォーム運用(Platform、1〜2年)
- 能力の出力: CAPTCHAサービスを内部セキュリティミドルウェアとして提供、複数のビジネスラインをサポート
- エコシステムの統合: ベクターインテリジェンス、SOC(セキュリティオペレーションセンター)、SIEMシステムとの連携
- 継続的な検証: レッドチーム/ブルーチーム検証メカニズムを確立し、定期的にAPTレベルの自動認識トレーニングをシミュレート
V. 企業向け vs. 非企業向け: 総合比較
| 比較次元 | 非企業ソリューション(OpenClaw / 伝統的OCR) | 企業向けCAPTCHA AI視覚認識 |
|---|---|---|
| 展開の複雑さ | ✅ 簡単、Dockerワンクリック起動 | ❌ 複雑、MLOpsプラットフォームのサポートが必要 |
| 初期コスト | ✅ 低く、単一GPUで十分 | ❌ 高く、クラスタ + ラベリングチームが必要 |
| モデルの更新 | ❌ 固定重み、自動認識に簡単に狙われます | ✅ オンライン学習、継続的な進化 |
| 行動分析 | ❌ 純粋な画像認識、行動次元なし | ✅ マルチモーダル統合、正確な人間機械区別 |
| リスクコントロール連携 | ❌ イソレートシステム、文脈意識なし | ✅ WAF、デバイスファントムと深い統合 |
| 高可用性 | ❌ デプロイの単一ポイント、SLA保証なし | ✅ マルチアクティブアーキテクチャ、エラスティックスケーリング |
| コンプライアンス対応 | ❌ 適切な監査ログ、プライバシーコンプライアンス | ✅ GDPR/CCPA対応、完全な監査 |
| 適用シナリオ | 小規模・中規模企業、内部テスト、短期プロジェクト | 大規模生産、金融、EC、政府関係 |
VI. 今後の形: AIリスク制御インフラ
技術進化トレンド
| 進化方向 | 現状 | 今後3〜5年 |
|---|---|---|
| 検証方法 | パッシブなチャレンジ(ユーザーが行動を実施する必要あり) | 背景の行動分析に基づく非表示CAPTCHA |
| モデルアーキテクチャ | 特化型の小さなモデル(CNN/LSTM) | 多モーダルな大規模モデル(GPT-4Vのようなアーキテクチャのファインチューニング) |
| チャレンジ生成 | 固定問題集+限られたバリエーション | 生成AIによるリアルタイム合成(1人1問、すべて異なる問題) |
| 決定論理 | 2値分類(人間/機械) | 連続的なリスクスコアリング+動的な戦略オーケストレーション |
| 検証モード | 単一ポイント検証 | フェデレーテッド学習協業、業界レベルの自動認識知的共有 |
生成CAPTCHAの想像空間
リアルタイムで拡散モデルまたはGANを用いて検証コンテンツを生成:
- 利点: 事前に保存された問題集が不要、自動認識システムが事前に学習データを収集できない
- 課題: 生成品質の制御(人間が認識困難なサンプルを避ける)、推論コストの最適化
- 先端研究: 業界の噂では、reCAPTCHA v4が生成技術を組み込む可能性がある。
VII. 技術意思決定者への推奨
| 時間軸 | 行動項目 | キーマイルストーン | 目標 |
|---|---|---|---|
| 短期(1〜3か月) | 自動認識表面評価 | OpenClawによる自動認識のシミュレーション完了、現在のCAPTCHA MTBFを数値化 | リスクへの認識を確立し、リソース投資を確保 |
| モニタリングシステム構築 | 自動認識検出ルールの導入、自動トラフィックの特徴を特定 | 「受動的対応」から「可視認識」へ | |
| 中期(3〜12か月) | データインフラ | 行動データ収集パイプラインの構築、1000万件以上のラベル付きサンプルの蓄積 | 本格的なモデルの訓練に必要なデータ基盤を構築 |
| モデルのイテレーションとリリース | 最初のディープラーニングモデルのA/Bテスト、認識防御の効果を検証 | 技術の実現可能性を証明し、チームの信頼を構築 | |
| 長期(1〜2年) | プラットフォーム化 | CAPTCHAサービスのSLAが99.99%に達し、100,000 QPSをサポート | 会社のコアセキュリティインフラとしての地位を確立 |
| AIセキュリティ戦略 | 統一されたリスク制御プラットフォームに統合し、詐欺防止と連携 | 多次元のAI検証システムの構築 |
VIII. CapSolverのAIビジュアル認識能力
CapSolverは、効率的で安定したAIビジュアル認識サービスを提供する技術プロバイダーとして、画像CAPTCHA認識およびカスタムソルバーのトレーニングにおいて大きな優位性を持っています:
- さまざまな画像ベースのCAPTCHAをサポート: CapSolverは、主流および複雑な画像ベースのCAPTCHAに対して認識アルゴリズムを深く最適化しており、画像分類やオブジェクト検出を含むタイプをサポートしています。
- 新しいCAPTCHAへの迅速な適応: 先進的な大規模ビジュアルモデル技術に基づき、CapSolverはファーストショット学習と迅速なファインチューニングが可能で、企業が市場に出現する新しいCAPTCHA課題に迅速に対応できるようにします。
- エンタープライズグレードのAPIと高同時接続処理能力: CapSolverは安定した高可用性のエンタープライズグレードAPIインターフェースを提供し、高同時接続要求に対応し、ミリ秒単位の応答を確保して企業の大量自動データ収集ニーズを満たします。
- カスタムソルバーのトレーニング: 企業の特定のビジュアル認識ニーズに対し、CapSolverはカスタムモデルトレーニングサービスを提供し、企業が独自の高精度CAPTCHA認識ソリューションを構築できるようにします。
IX. さらに読むための資料と業界参照
| リソースタイプ | 推奨コンテンツ | 価値 |
|---|---|---|
| オープンソースプロジェクト | OpenClaw & CapSolver | 自動認識技術スタックの理解 |
| 業界レポート | Gartner Market Guide for Fraud Detection | 商業ソリューション選定の参考 |
X. 結論
AI技術の急速な進歩により、CAPTCHA認識は単なる技術的課題ではなく、デジタル時代における企業が公開データを取得し、ビジネスの継続性を確保するための重要な能力となっています。AIビジュアル大規模モデルは、複雑なシーンの理解力、強力な一般化能力、効率的なモデルスケーラビリティを備え、企業向けの自動認識に画期的な解決策を提供しています。CapSolverは、AIビジュアル認識における深い蓄積とエンタープライズグレードのサービス能力を備え、企業がさまざまなCAPTCHA課題を効率的かつコンプライアンスに沿って対応し、コアビジネス価値の創造に注力できる信頼できるパートナーとなることを目指しています。
XI. 質問と回答(FAQ)
Q1: 大規模ビジュアルモデル(LVM)は従来のCNNとどのように異なるのでしょうか?
A1: 従来のCNNがローカルな特徴抽出に依存するのに対し、LVMはVision Transformers(ViT)などのアーキテクチャを利用してグローバルな文脈と意味を捉えます。これにより、複雑なシーンを理解し、新しい見慣れないCAPTCHAスタイルに非常に高い精度で一般化でき、追加のトレーニングが最小限で可能です。
Q2: AIベースのCAPTCHAソルバーにおいて「ファーストショット学習」とはどのようなものですか?
A2: ファーストショット学習とは、事前にトレーニングされたAIモデルが、非常に少ないラベル付き例を用いて新しいタスク(例えば新しいタイプのCAPTCHA)に適応できる能力を指します。これは大規模モデルのコアメリットであり、進化する検証メカニズムに対して迅速な展開を可能にします。
Q3: CapSolverはどの種類の画像CAPTCHAをサポートしていますか?
A3: CapSolverは、主流および複雑な画像CAPTCHAに対して認識アルゴリズムを深く最適化しており、画像分類やオブジェクト検出を含むタイプをサポートしています。
画像ソリューションを確認する: Imagetotext & VisionEngine
Q4: CapSolverは認識の正確性と安定性をどのように確保していますか?
A4: CapSolverは先進的な大規模ビジュアルモデル技術に基づき、継続的な学習ループとオンライン学習メカニズムを通じてモデル性能を継続的に最適化しています。さらに、エンタープライズグレードのAPIと高同時接続アーキテクチャを提供し、ミリ秒単位の応答と99.9%の可用性を確保しています。
Q5: CapSolverのサービスはプライベート配備をサポートしていますか?
A5: CapSolverは、クラウドサービスとプライベート配備の柔軟な展開オプションを提供し、さまざまな企業のセキュリティおよびコンプライアンス要件に対応しています。プライベート配備ソリューションは、企業の特定のアーキテクチャとリソースに基づいてカスタマイズ可能です。
もっと見る
AIMar 27, 2026
企業自動化の向上:LLMを駆動とするインフラによるシームレスなCAPTCHA認識と運用効率
LLMを駆動するAIオートメーションインフラがCAPTCHA認識をどのように変革するかを発見してください。ビジネスプロセスの効率を向上させ、手動の介入を削減します。高度な検証ソリューションで自動化されたオペレーションを最適化してください。
AIMar 27, 2026
LLMトレーニングのためのデータ収集のスケーリング: CAPTCHAをスケールで解く
大規模言語モデルのトレーニングのためのデータ収集をスケールする方法を学びましょう。大規模にCAPTCHAを解くことで、AIモデル用の高品質なデータセットを構築するための自動化された戦略を発見しましょう。
