AIエージェントによるWebスクレイピングと競争情報ガイド

Sora Fujimoto
AI Solutions Architect

TL;DR
- AIエージェントは、継続的な人間の入力なしに、マルチステップのデータ収集タスクを計画、実行、適応する自律型ソフトウェアシステムです。
- AIエージェント業界において、ウェブスクレイピングと競争分析は、ほぼ他のあらゆる用途よりも早く本格的な運用に移行した分野です。
- AIエージェントは、競合の価格をモニタリングし、製品の変更を追跡し、人間のチームでは到底追いつけない規模で構造化されたデータを抽出できます。
- 現代のウェブサイトはCAPTCHA、レート制限、ボット検出レイヤーを導入しており、これらは自動化パイプラインを妨げる要因になります。CAPTCHA解決サービスであるCapSolverは、エージェントが継続性を維持するのを支援します。
- データ収集におけるAIエージェントの責任ある、コンプライアンスに配慮した使用には、robots.txt、利用規約、および適用可能なデータ規制を尊重することが必要です。
はじめに
AIエージェントは、企業が外部データを収集し、行動する方法を変革しています。AIエージェント業界において、実験から本格的な運用に移行したケースは、ほぼ他のあらゆる用途よりも迅速です。ウェブスクレイピングと競争分析はその代表例です。企業は、人間がボタンをクリックすることなく、ウェブを自律的にブラウズし、構造化された情報を抽出し、それらを価格エンジン、市場ダッシュボード、戦略レポートに直接送信するエージェントを導入しています。この記事では、これらのエージェントが何であるか、どのように動作するか、どこで最も価値を発揮するか、そして自動化パイプラインを構築する際、チームが考慮すべき技術的障壁(CAPTCHAを含む)について説明します。
AIエージェントとは何か、データ収集においてなぜ重要なのか?
AIエージェントは、環境を認識し、目標について推論し、その目標を達成するために一連の行動を取るソフトウェアプログラムです。その後、観測した内容に基づいて調整を行います。単純なスクリプトが固定された経路をたどるのとは異なり、エージェントは「どのページに次に訪れるか」「予期せぬレイアウト変更をどう処理するか」「失敗したリクエストをいつリトライするか」を決定できます。
IBMはAIエージェントを、継続的なループで知覚、推論、行動を組み合わせたシステムとして定義しています。このループがデータ収集において強力な理由は、ウェブは複雑で、動的で、一貫性がないため、変化に対応するには柔軟な推論層が必要だからです。
AIエージェント業界は驚くほど急速に成長しています。MarketsandMarketsによると、グローバルなAIエージェント市場は2025年の78億4000万ドルから2030年の526億2000万ドルに成長し、CAGRは46.3%になると予測されています。研究とデータ収集はすでに運用されている上位3つの生産的利用ケースの一つです。LangChain AIエージェントの状況レポートでは、2024年時点で調査対象企業の51%が本格的な運用でエージェントを稼働させていることが判明しており、研究とデータ収集が主要な応用として、カスタマーサービスや個人の生産性よりも上位に位置しています。
コアアーキテクチャ:AIエージェントがスクレイピングパイプラインでどのように動作するか
アーキテクチャを理解することで、チームはより信頼性の高いシステムを構築できます。一般的なAIエージェント業界のスクレイピングパイプラインには4つのレイヤーがあります:
1. 計画レイヤー
エージェントは高レベルの目標を受け取ります。たとえば、「3つの競合サイトで上位50のSKUの価格を毎日収集する」などです。これをサブタスクに分割します。URLの特定、リクエストのスケジュール化、抽出スキーマの定義。より高度な設定では、計画レイヤーがLLMを使用して、条件が変化した場合に修正可能なステップバイステップの実行計画を生成します。
2. 実行レイヤー
エージェントはHTTPリクエストを送信するか、ヘッドレスブラウザ(Playwright、Puppeteer、Selenium)を制御します。HTML、JSON API、またはレンダリングされたJavaScriptコンテンツを解析し、構造化された出力形式にマッピングします。実行レイヤーは、ページネーション、無限スクロール、ログインフロー、クライアントサイドでレンダリングされる動的コンテンツを処理する必要があります。これらは、静的なスクレイパーでは失敗するシナリオです。
3. 観察と適応レイヤー
各アクションの後、エージェントは結果を確認します。ページは正しく読み込まれましたか?期待されるデータは存在しましたか?CAPTCHAが表示されましたか?観察に基づき、次のステップを決定します。リトライ、優先順位の上昇、または次のステップに進む。このレイヤーがエージェントをスクリプトから真正に異なるものにしている理由は、単に実行するだけでなく、評価を行うからです。
4. 記憶とストレージレイヤー
抽出されたデータはデータベース、データウェアハウス、または下流のパイプラインに保存されます。一部のエージェントは短期記憶(セッションコンテキスト)と長期記憶(歴史的な価格トレンド、既知のURLパターン)を維持します。長期記憶により、エージェントは異常を検出できます。たとえば、1日で価格が80%下がった場合は、データエラーではなく、実際の割引である可能性が低いと判断できます。
この4レイヤーのモデルが、現代的なデータ収集パイプラインと伝統的なcron-jobスクレイパーを区別しています。エージェントは単にページを取得するだけでなく、タスクについて推論を行うのです。この違いは、プロダクション規模において非常に重要です。
競争分析における主要な利用ケース
競争分析は、AIエージェント業界のツールで最も価値のある応用の一つです。現在、チームがエージェントを導入する最も一般的なシナリオは次のとおりです:
価格モニタリング
eコマースチームは、数千ものSKUの競合価格をほぼリアルタイムで追跡するためにエージェントを使用します。エージェントは製品ページにアクセスし、価格と在庫データを抽出して、自動調整をトリガーする価格エンジンに送信します。この規模での手動モニタリングは不可能です。1人のアナリストが1日で50製品を追跡するのに対し、エージェントは50,000製品を追跡できます。
このエージェントの観察レイヤーは非常に重要です。製品ページが429(Too Many Requests)ステータスを返すと、エージェントはバックオフし、指数関数的な遅延でリトライします。ページレイアウトが変更される(サイトリニューアル中に頻繁に起こる)場合、エージェントはLLMを使用して価格要素を再識別することができ、静かに失敗するのではなくなります。
製品と機能の追跡
SaaS企業は、競合の変更履歴ページ、リリースノート、機能発表ブログをモニタリングするためにエージェントを導入します。競合が新しい統合をリリースしたり、価格階層を変更したりした場合、エージェントは数時間以内にその変更を表示します。製品マネージャーは、エージェントの抽出レイヤーがコンテンツを事前に定義されたスキーマにマッピングするため、生のHTMLダンプではなく構造化された要約を受け取ります。つまり、機能名、リリース日、影響を受ける階層、要約などが含まれます。
このような継続的なモニタリングは、以前は専門のアナリストに依存していました。現在では、AIエージェント業界において、これはスケジュールされたバックグラウンドプロセスとして動作しています。
レビューと感情集約
エージェントは、G2、Trustpilot、アプリストアなどのプラットフォームからカスタマーレビューを収集します。自然言語処理レイヤーは感情を分類し、繰り返しテーマを抽出し、製品ギャップを浮き彫りにします。これにより、製品チームは市場からの継続的なシグナルを得ることができます。たとえば、競合のユーザーが一貫してオンボーディングの遅さを文句にしていることが分かった場合、その洞察をもとに自社のポジショニングを強化できます。
SERPとコンテンツモニタリング
SEOやコンテンツチームは、キーワード順位、バックリンクプロファイルのモニタリング、競合の新規コンテンツの検出にエージェントを使用します。これは編集カレンダーとリンク構築戦略に直接フィードバックされます。エージェントは、競合が現在順位が良いキーワードをターゲットにしたコンテンツを公開した場合、順位が変化する前にアラートをトリガーすることもできます。
ジョブポスティング分析
競合の求人情報の追跡は、戦略的意図を明らかにします。データエンジニアの突然の増員はプラットフォームの再構築を示唆します。エンタープライズセールスの役割の集まりは市場拡大を示唆します。エージェントは毎日キャリアページをモニタリングし、このシグナルを自動的に集約し、戦略チームに信頼性の高い先行指標を提供します。
これらのワークフローをサポートするスクレイピングツールの進化について詳しく知りたい場合は、2026年のトップウェブスクレイピングツールと最高のデータ抽出ツールをご覧ください。
比較:従来のスクレイパー vs AIエージェント
| 次元 | 従来のスクレイパー | AIエージェント |
|---|---|---|
| タスクの定義 | 固定セレクター、厳格な経路 | 目標指向型、適応型 |
| レイアウト変更の処理 | 破損、手動修正が必要 | 検出と適応 |
| 複数ステップのナビゲーション | 限られている | 本来の機能 |
| エラー回復 | 手動介入 | 自動リトライロジック |
| CAPTCHAの処理 | パイプラインをブロック | 解決サービスと統合可能 |
| スケーラビリティ | 工程の努力に比例して線形に成長 | コンピューティングに比例して成長 |
| コンプライアンスへの認識 | 内蔵されていない | ルールを尊重するように指示可能 |
CAPTCHAの問題:AIエージェントが壁にぶつかる場面
AIエージェント業界の最も高度なパイプラインでも、最終的にはCAPTCHAに遭遇します。ウェブサイトは、自動アクセスに対する主要な防御としてCAPTCHAを使用しています。一般的なタイプには次のものがあります:
- reCAPTCHA v2 — イメージ選択チャレンジ(「交通信号をすべて選択してください」)
- reCAPTCHA v3 — 隠し、スコアベースのリスク評価
- Cloudflare Turnstile — 新しいプライバシー重視のチャレンジで、従来のCAPTCHAを置き換えます
- GeeTest — アジアのプラットフォームで一般的なスライダーと行動チャレンジ
エージェントがCAPTCHAに遭遇すると、パイプラインが停止します。有効なトークンや完了したチャレンジなしでは、エージェントは進むことができません。これはエッジケースではなく、構造的な問題です。高価値なデータソースはほぼ常に保護されています。
コンプライアンスに配慮した解決策は、エージェントの観察レイヤーにCAPTCHA解決APIを統合することです。エージェントがチャレンジを検出すると、関連するパラメータを解決サービスに渡し、トークンを受け取り、リクエストにインジェクトして継続します。エージェントは停止する必要がありません。
CapSolverは、この統合パターンに特化したAI駆動のCAPTCHA解決サービスです。reCAPTCHA v2/v3/Enterprise、Cloudflare Turnstile、GeeTest、AWS WAF CAPTCHAをサポートしています。解決はREST API経由で1〜5秒で行われ、人間の関与は一切ありません。このフローは完全に自動化されています。
AIエージェント業界のパイプラインをPythonで構築しているチームには、CapSolverの公式APIドキュメントに記載されているパターンに従って統合が可能です。エージェントはタスクを送信し、結果をポーリングし、返されたトークンを使用して保護されたリクエストを完了します。これにより、手動介入なしでパイプラインが継続的に動作します。
CAPTCHAをウェブスクレイピング中に解決する方法についての実践的なウォークスルーを知りたい場合は、ウェブスクレイピング中にCAPTCHAを解決する方法をご覧ください。
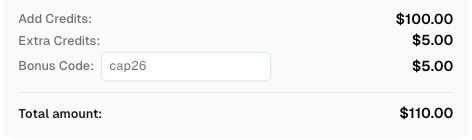
CapSolverのボーナスコードを取得する
自動化予算を即座に増やす!
CapSolverアカウントにチャージする際にボーナスコード CAP26 を使用すると、毎回チャージに5%のボーナスが追加されます。制限はありません。
今すぐCapSolverダッシュボードでボーナスコードを取得してください。
スクレイピングワークフローで使用されるAIエージェントフレームワーク
データ収集におけるAIエージェント業界の用途をサポートするために、いくつかのオープンソースおよび商用フレームワークが登場しています:
- LangChain / LangGraph — ツールの使用を伴う複数ステップの推論エージェントの構築に人気があります
- AutoGen(マイクロソフト) — マルチエージェントの協働をサポートし、並列スクレイピングタスクに役立ちます
- CrewAI — ロールベースのエージェントオーケストレーションで、競争分析ワークフローに適しています
- Crawl4AI — AIフレンドリーなウェブクローリングに特化し、構造化された出力を提供します
- ScrapeGraph AI — LLMとスクレイピングを組み合わせて、自然言語の指示でデータを抽出します
主要なオプションの詳細な分析については、2026年のトップ9のAIエージェントフレームワークをご覧ください。
各フレームワークは計画と実行レイヤーを異なる方法で扱いますが、すべてのフレームワークが最終的に同じインフラストラクチャの課題に直面します。つまり、レート制限、IPブロック、CAPTCHAです。フレームワークの選択はアーキテクチャに影響を与えますが、CAPTCHA解決レイヤーは別途のコンポーザブルコンポーネントです。
コンプライアンスと責任ある使用
AIエージェント業界は、チームが真剣に取り組むべき法的および倫理的な環境で運用されています。自動データ収集は本質的に違法ではありませんが、責任ある方法で行われなければなりません。
重要な原則:
- robots.txtを尊重する — このファイルは、サイトオーナーが自動アクセスを許可しているパスを示しています。エージェントはこれを解析し、遵守する必要があります。
- 利用規約を確認する — 多くのサイトでは自動スクレイピングが明確に禁止されています。高容量または商業的に機密性の高い使用ケースでは、法的レビューが適切です。
- レートリミット — エージェントは遅延を実装し、Retry-Afterヘッダーを尊重して、ターゲットサーバーに過剰な負荷をかけないようにする必要があります。
- 個人情報 — 個人識別情報の収集はGDPR、CCPA、その他の規制を引き起こします。エージェントは必要な情報のみを収集するように設定する必要があります。
- データの新鮮さと正確性 — 競争分析は、データが信頼できる場合にのみ価値があります。エージェントは、異常をフラグとして表示する検証ステップを含める必要があります。
Deloitteのagentic AIに関する研究では、プロダクションでエージェントを導入するエンタープライズチームにとって、ガバナンスと監督が最大の懸念事項であると指摘されています。コンプライアンスをエージェントの指示セットに最初から組み込むことは、後から追加するよりもはるかに簡単です。
結論
AIエージェントは、AIエージェント業界において研究コンセプトからプロダクションツールへと進化し、ウェブスクレイピングと競争分析はその価値の明確な証明です。動的なページを処理し、レイアウト変更に適応し、複数ステップのナビゲーションを実行し、人間のプロセスでは到底対応できないボリュームにスケールします。
技術的な課題は現実的です。CAPTCHA、レート制限、ボット検出システムは、まさにこの種の自動化を妨げるために設計されています。CapSolverのような信頼性の高いCAPTCHA解決サービスをエージェントのパイプラインに統合することで、最も一般的な障害ポイントの一つを除去し、データ収集を継続的かつコンプライアンスに沿った状態に保つことができます。
AIエージェントを用いた競合情報の業界パイプラインを構築または評価する際には、明確なデータ目標から始め、オーケストレーションのニーズに合ったフレームワークを選択し、CAPTCHAの処理を含むインフラ層の計画を本番環境への移行前に実施してください。
FAQ
Q1: データ収集におけるウェブスラッパーとAIエージェントの違いは何ですか?
従来のウェブスラッパーは固定された指示に従います。つまり、特定のセレクター、予め定義されたURL、そして厳密な実行経路です。AIエージェントは推論の層を追加します。目標を解釈し、達成に必要なステップを計画し、ページが変更されたときに適応し、エラーから自動的に回復する能力を持っています。スケールした競合情報収集において、この適応能力が重要な違いとなります。
Q2: 競合情報収集のためにウェブスラッピングにAIエージェントを使用することは合法ですか?
多くの管轄区域において、公開されている情報に自動化されたデータ収集を行うことは合法です。ただし、サイトのロボット.txt、利用規約、および適用可能なデータ保護法(GDPR、CCPAなど)に準拠する必要があります。法的な枠組みは国や使用ケースによって異なります。スケールしたエージェントの展開を行う前に、チームはロボット.txt、利用規約、および関連する規制を確認する必要があります。
Q3: AIエージェントはスラッピング中にCAPTCHAをどのように処理しますか?
エージェントがCAPTCHAに遭遇した場合、CAPTCHAを解くAPIと統合できます。エージェントはチャレンジのパラメータをAPIに渡し、有効なトークンを受け取り、リクエストに挿入して処理を続けます。CapSolverなどのサービスは、reCAPTCHA、hCaptcha、Cloudflare Turnstileなど、他の一般的なチャレンジタイプに対応しており、REST APIを介して数秒で解決策を返します。
Q4: 競合情報パイプラインに最適なAIエージェントフレームワークはどれですか?
適切な選択は、あなたのスタックやワークフローの複雑さに依存します。LangChainやLangGraphは広く採用されており、強力なコミュニティサポートがあります。CrewAIはロールベースのマルチエージェントワークフローに適しています。Crawl4AIやScrapeGraph AIはウェブデータ抽出に特化しています。多くのチームは、パイプラインが成熟するにつれて、プロキシ、CAPTCHAソルバー、ストレージなどの組み合わせ可能なインフラ構成要素を追加します。
Q5: 競合情報エージェントはどのくらいの頻度で実行すべきですか?
頻度はデータの変動性に依存します。ECサイトの価格データは毎時間更新する必要があります。機能追跡や求人情報は毎日または毎週実行できます。SERPモニタリングは通常毎日実行されます。エージェントは、基盤となるデータの変化の速さに基づいてスケジュールされ、ターゲットサーバーへの負荷とコンピューティングコストのバランスを考慮する必要があります。