Pengambilan Data Web Penanganan CAPTCHA: Panduan Otomasi Aman

Emma Foster
Machine Learning Engineer
TL;DR
- Penanganan CAPTCHA scraping web sebaiknya dimulai dengan izin, kontrol laju, dan aturan berhenti yang jelas sebelum menambahkan integrasi teknis apa pun.
- Jenis tantangan utama termasuk reCAPTCHA, Cloudflare Turnstile, pengenalan gambar, dan alur validasi lalu lintas khusus halaman.
- CapSolver dapat menyesuaikan alur kerja CAPTCHA scraping yang disetujui dengan menyediakan API pembuatan tugas dan pengambilan hasil yang terdokumentasi untuk jenis tantangan umum.
- Otomasi yang baik memperlakukan token sebagai artefak validasi berumur pendek dan mencatat setiap tugas, ulang coba, domain target, dan status kegagalan.
Pendahuluan
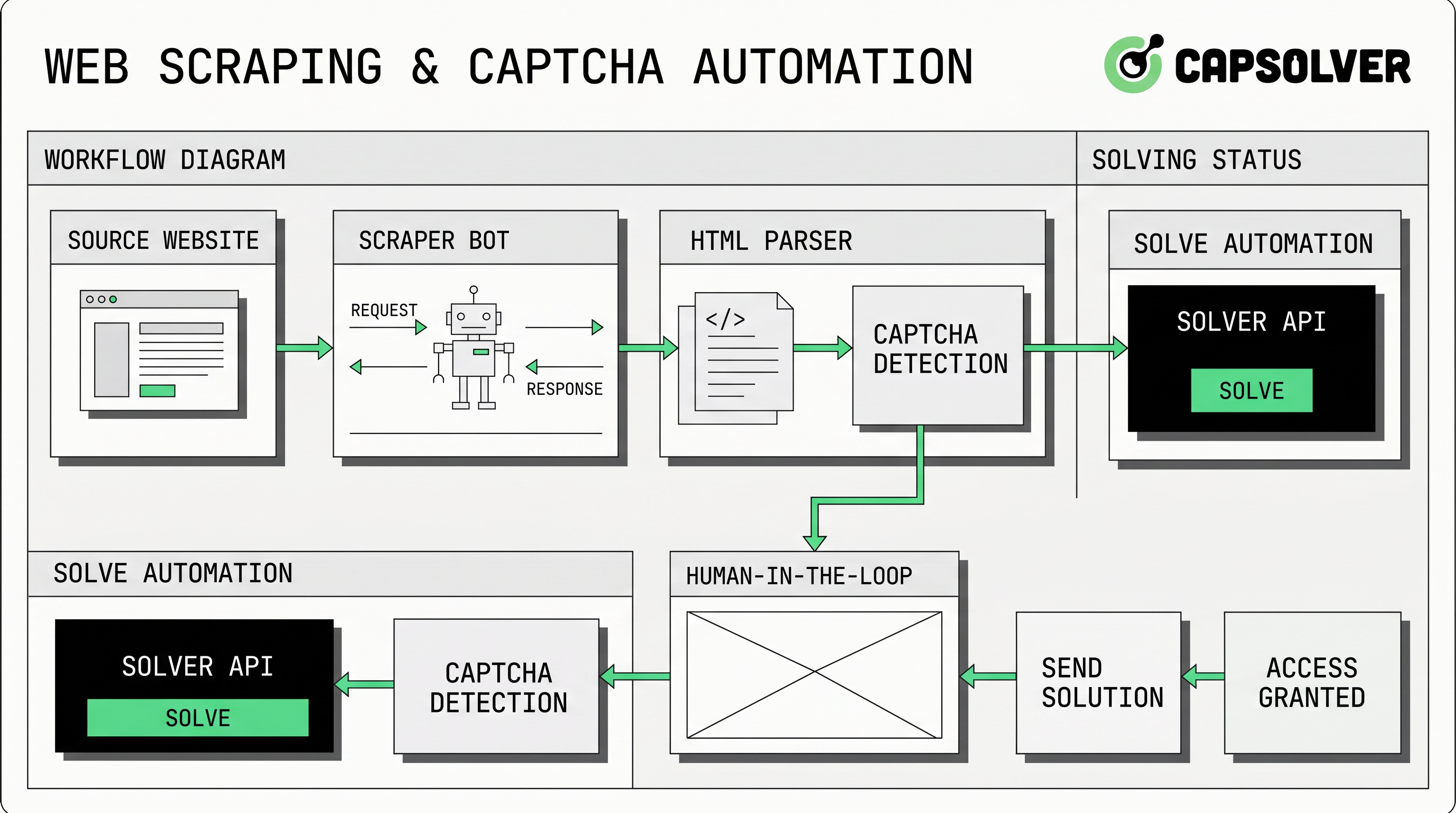
Penanganan CAPTCHA scraping web adalah masalah praktis bagi tim yang mengumpulkan data publik yang diizinkan, menjalankan pemantauan pasar, menguji aplikasi yang dimiliki, atau menjalankan otomasi internal. CapSolver dapat mendukung alur kerja ini ketika tujuannya adalah penanganan tantangan yang sah dan terkendali, bukan lalu lintas yang tidak terkendali. Pendekatan terbaik bukanlah menambahkan solver terlebih dahulu. Yang terpenting adalah memastikan izin, mengurangi permintaan yang tidak perlu, mengidentifikasi jenis tantangan, mempertahankan konteks browser, dan menambahkan alur API hanya di tempat yang diizinkan. Panduan ini menjelaskan cara merancang proses scraping web yang teknisnya andal, lebih mudah diaudit, dan sejalan dengan aturan otomasi yang bertanggung jawab.
Mengapa CAPTCHA scraping muncul dalam alur kerja otomasi
Pemeriksaan CAPTCHA scraping web biasanya muncul ketika situs ingin lebih banyak kepercayaan tentang pengunjung, pola permintaan, lingkungan browser, atau perilaku akun. Beberapa tantangan terlihat, sementara yang lain berbasis skor atau token. Google menyatakan bahwa reCAPTCHA v3 berjalan tanpa mengganggu pengguna dan mengembalikan skor risiko dari 0,0 hingga 1,0 untuk setiap permintaan. Cloudflare menyatakan bahwa token Turnstile harus divalidasi di server, bersifat satu kali, dan berlaku selama 300 detik. Sistem ini merupakan bagian dari pola validasi lalu lintas yang lebih luas, bukan hanya teka-teki visual.
Artinya, penanganan CAPTCHA scraping web tidak dapat dipisahkan dari kualitas permintaan. Laju permintaan tinggi, reputasi IP yang tidak stabil, sinyal browser yang hilang, atau status sesi yang tidak konsisten dapat meningkatkan frekuensi tantangan. Sebelum menambahkan API, tim sebaiknya mengurangi pemicu yang dapat dihindari dengan caching yang bertanggung jawab, menghormati robots dan ketentuan, membatasi konkurensi, mengidentifikasi kasus penggunaan yang sesuai, dan berhenti ketika situs menolak atau membatasi akses.
| Penyebab | Respons praktis | Mengapa membantu |
|---|---|---|
| Laju permintaan tinggi | Tambahkan batas antrean dan backoff | Mengurangi beban dan kegagalan. |
| Ketidakcocokan browser | Gunakan profil otomasi browser yang konsisten | Menjaga konteks halaman tetap stabil. |
| Ketidaksesuaian proxy | Pertahankan proxy, sesi, dan tugas tantangan yang sejalan | Mencegah ketidakcocokan konteks token. |
| Jenis tantangan yang tidak diketahui | Deteksi reCAPTCHA, Turnstile, atau tantangan gambar sebelum pembuatan tugas | Mengirim payload API yang benar. |
| Izin yang tidak jelas | Tinjau ketentuan, robots, kontrak, dan sensitivitas data | Menjaga otomasi dalam batas yang disetujui. |
Bangun kebijakan sebelum integrasi CAPTCHA scraping web
Pekerjaan penanganan CAPTCHA scraping web sebaiknya dimulai dengan tata kelola. OWASP menggambarkan otomasi yang tidak diinginkan sebagai perangkat lunak yang menyimpang dari perilaku yang diterima dan menciptakan efek yang tidak diinginkan untuk aplikasi web, dan klasifikasi ancaman otomatisnya mencakup skenario penipuan dan abusi terkait CAPTCHA. Bagi tim, ini berarti alur teknis yang sama dapat diterima dalam satu konteks dan tidak diterima dalam konteks lain.
Kebijakan yang bertanggung jawab harus mencantumkan domain yang diizinkan, jenis data yang diizinkan, tujuan bisnis, batas laju permintaan, aturan akun, aturan penyimpanan, dan kontak eskalasi. Kebijakan ini juga harus menjelaskan apa yang tidak boleh dilakukan oleh otomasi, seperti mengakses area pribadi, mengumpulkan data sensitif tanpa izin, atau terus berjalan setelah sinyal penolakan. Kebijakan ini melindungi situs target dan organisasi Anda sendiri karena menciptakan garis jelas antara pengumpulan data yang disetujui dan aktivitas yang dilarang.
Pilih alur CAPTCHA scraping web yang tepat
Penanganan CAPTCHA scraping web biasanya sesuai dengan tiga pola teknis. Pertama adalah penghindaran melalui kebersihan permintaan yang lebih baik: jumlah permintaan yang lebih sedikit, caching yang lebih baik, dan perilaku browser yang lebih tidak mencolok. Kedua adalah tinjauan manusia untuk kasus tepi, di mana proses dengan volume rendah mengarahkan halaman sulit ke operator. Ketiga adalah alur tantangan berbasis API, di mana pekerjaan yang disetujui mengirim parameter tantangan ke pemasok dan mengambil solusi.
Dokumentasi API resmi CapSolver menjelaskan alur berbasis tugas dengan createTask dan getTaskResult. Dalam model ini, scraper mendeteksi tantangan, mengirim objek tugas yang benar, menerima ID tugas, dan memantau hingga hasilnya siap. Guia createTask menyatakan bahwa permintaan memerlukan clientKey dan objek tugas, dan guia getTaskResult mendokumentasikan status processing dan ready untuk tugas asinkron.
Untuk halaman reCAPTCHA, tim sebaiknya meninjau guia reCAPTCHA v2 atau guia reCAPTCHA v3 CapSolver daripada menyalin payload umum. Untuk halaman Turnstile, gunakan guia Cloudflare Turnstile dan ingat bahwa aturan validasi server-side Cloudflare membuat keaslian token penting.
Pertahankan konsistensi konteks browser, proxy, dan token
Kesalahan CAPTCHA scraping web sering berasal dari ketidakcocokan konteks. Jika browser meminta halaman melalui satu proxy tetapi tugas tantangan menggunakan jalur jaringan lain, token yang dikembalikan mungkin tidak cocok dengan lingkungan yang diharapkan. Jika tindakan halaman berubah antara deteksi dan pengiriman, token berbasis skor mungkin tidak diverifikasi seperti yang diinginkan. Jika pekerjaan menunggu terlalu lama, token dapat kedaluwarsa.
Inilah sebabnya lapisan otomasi harus mengikat tugas tantangan dengan ID pekerjaan, sesi browser, proxy, URL target, kunci situs, dan timestamp. Sumber daya CapSolver tentang Selenium dalam otomasi web dan Puppeteer dalam otomasi web adalah tautan internal yang berguna bagi tim yang perlu menyamakan browser driver sebelum menambahkan penanganan tantangan. Ketika proxy terlibat, panduan port proxy untuk scraping dan otomasi dapat membantu menjaga pengaturan jaringan tetap konsisten.
Kode Bonus
Tukarkan Kode Bonus CapSolver Anda
Tingkatkan anggaran otomasi Anda secara instan!
Gunakan kode bonus CAP26 saat menambahkan dana ke akun CapSolver Anda untuk mendapatkan tambahan 5% bonus pada setiap pengisian ulang — tanpa batas.
Tukarkan sekarang di Dasbor CapSolver
Ringkasan Perbandingan: Opsi CAPTCHA scraping web umum
Penanganan CAPTCHA scraping web harus sesuai dengan volume, tingkat izin, dan kebutuhan keandalan pekerjaan. Tugas penelitian dengan volume rendah mungkin hanya memerlukan tinjauan manusia. Pekerjaan pemantauan berulang biasanya memerlukan pengelolaan status berbasis API, log, dan kondisi berhenti. Pekerjaan volume tinggi yang tidak terkendali sebaiknya tidak dilanjutkan sama sekali, bahkan jika integrasi teknis berjalan.
| Opsi | Kasus penggunaan terbaik | Risiko utama |
|---|---|---|
| Hanya kebersihan permintaan | Halaman publik dengan frekuensi tantangan rendah | Mungkin tidak dapat menangani halaman tantangan ketika muncul. |
| Tinjauan manusia | Penelitian atau debugging volume rendah | Lambat dan tidak cocok untuk pekerjaan yang dijadwalkan. |
| Penanganan berbasis API | Alur kerja berulang yang disetujui dengan jenis tantangan yang diketahui | Membutuhkan konteks yang akurat, log audit, dan kontrol kebijakan. |
| Jangan lanjutkan | Akses yang dibatasi, pribadi, sensitif, atau ditolak | Melanjutkan dapat menciptakan risiko hukum, privasi, dan keamanan. |
Artikel CapSolver tentang Selenium versus Puppeteer untuk penyelesaian CAPTCHA berguna saat memilih alat otomasi browser, sementara panduan otomasi browser untuk pengembang dapat membantu tim memisahkan kontrol browser dari penanganan tantangan.
Checklist Implementasi untuk CAPTCHA scraping web
Implementasi CAPTCHA scraping web sebaiknya kecil, teramati, dan dapat dibatalkan. Mulai dengan alur kerja staging dan daftar putih terbatas. Catat jenis tantangan, URL target, kunci situs, ID proxy, ID tugas, status tugas, latensi, dan hasil akhir. Jika situs mengubah kebijakan, perilaku tantangan, atau status respons, hentikan pekerjaan dan tinjau alur kerja daripada meningkatkan ulang coba.
Checklist praktis mencakup tinjauan izin, tinjauan robots dan ketentuan, minimisasi data, daftar putih domain, batas laju, profil browser, konsistensi proxy, deteksi tantangan, pembuatan tugas API, kebijakan polling, timeout, penanganan kesalahan, log audit, dan ulasan setelah eksekusi. Tim dapat menambahkan panduan tentang menggunakan layanan scraping dan penyelesaian CAPTCHA ke dokumentasi internal karena ini menggambarkan layanan sebagai bagian dari alur kerja yang lebih luas, bukan sebagai jalan pintas terpisah.
Kesalahan Umum yang Harus Dihindari
Proyek CAPTCHA scraping sering kali gagal ketika tim memperlakukan penanganan tantangan sebagai tambahan terpisah. Token yang dikembalikan oleh API hanya berguna jika sesuai dengan keadaan browser, halaman target, tindakan, dan jendela waktu. Kesalahan umum lainnya adalah retry yang tidak terbatas. Jika tugas gagal berulang, respons yang benar adalah memeriksa parameter, izin, dan sinyal situs, bukan meningkatkan beban.
Tim juga sebaiknya menghindari menyimpan rahasia dalam skrip scraper, berbagi kunci API di antara lingkungan, atau mengirim tugas tantangan untuk domain di luar daftar putih yang disetujui. Gunakan konfigurasi pusat, penyimpanan rahasia, dan log pekerjaan. Jika alur kerja Anda menggunakan API, dokumentasi API CapSolver dan panduan getTaskResult harus tetap menjadi sumber kebenaran untuk perilaku endpoint.
Kesimpulan/CTA
Penanganan CAPTCHA scraping web paling aman ketika dirancang sebagai alur kerja yang terkendali: izin terlebih dahulu, kebersihan permintaan kedua, deteksi tantangan ketiga, dan integrasi API hanya di tempat yang diizinkan. Pengaturan yang tepat menjaga konteks browser tetap stabil, memperlakukan token sebagai berumur pendek, mencatat setiap hasil, dan berhenti ketika akses tidak diizinkan. Jika tim Anda membutuhkan penanganan tantangan yang terdokumentasi untuk scraping, QA, atau pemantauan yang disetujui, mulailah dengan alur kerja kecil menggunakan CapSolver.
FAQ
Apa yang dimaksud dengan CAPTCHA scraping web?
CAPTCHA scraping web berarti scraper menghadapi tantangan validasi lalu lintas saat mengumpulkan data. Jawaban yang benar tergantung pada izin, jenis tantangan, batas laju, dan aturan akses situs.
Apakah CAPTCHA scraping dapat ditangani dengan API?
Ya, dalam alur kerja yang disetujui, API dapat membuat tugas tantangan dan mengembalikan solusi melalui endpoint hasil yang terdokumentasi. Untuk tinjauan umum, lihat bagaimana layanan scraping dan penyelesaian CAPTCHA menyediakan API.
Mengapa scraper Selenium dan Puppeteer melihat pemeriksaan CAPTCHA?
Selenium dan Puppeteer dapat menghasilkan pola browser yang situs tinjau selama validasi lalu lintas, terutama pada laju permintaan tinggi atau sesi yang tidak stabil. Menstandarkan otomasi web Selenium atau pengaturan Puppeteer membantu mengurangi ketidaksesuaian yang dapat dihindari.
Bagaimana proxy seharusnya digunakan dalam alur CAPTCHA scraping?
Gunakan proxy hanya di tempat yang sah dan diizinkan, dan pertahankan identitas proxy konsisten antara sesi browser dan tugas tantangan. Tujuannya adalah konteks yang stabil, bukan volume permintaan yang agresif.
Apakah penanganan CAPTCHA scraping legal untuk situs web publik apa pun?
Tidak. Ketersediaan publik tidak secara otomatis menciptakan izin untuk pengumpulan otomatis. Tinjau ketentuan situs, panduan robots, kontrak, persyaratan privasi, sensitivitas data, dan batas laju sebelum menjalankan scraper apa pun.
Lihat Lebih Banyak
Web ScrapingApr 22, 2026
Arsitektur Pengambilan Data Web Rust untuk Ekstraksi Data yang Dapat Diskalakan
Pelajari arsitektur pengambilan data web Rust yang dapat diskalakan dengan reqwest, scraper, pengambilan data asinkron, pengambilan data browser tanpa tampilan, rotasi proxy, dan penanganan CAPTCHA yang sesuai aturan.
Web ScrapingFeb 17, 2026
Cara menyelesaikan Captcha di Nanobot dengan CapSolver
Mengotomasi penyelesaian CAPTCHA dengan Nanobot dan CapSolver. Gunakan Playwright untuk menyelesaikan reCAPTCHA dan Cloudflare secara otomatis.

