Cara melakukan Web Scraping dengan Puppeteer dan NodeJS | Tutorial Puppeteer

Ethan Collins
Pattern Recognition Specialist

Web scraping adalah teknik yang kuat yang digunakan untuk mengekstrak data dari situs web. Dalam tutorial ini, kita akan menjelajahi cara melakukan web scraping menggunakan Puppeteer dan Node.js, dua teknologi populer dalam ekosistem pengembangan web. Puppeteer adalah perpustakaan Node.js yang menyediakan API tingkat tinggi untuk mengontrol browser Chrome atau Chromium tanpa antarmuka. Ini memungkinkan kita untuk mengotomasi tindakan browser, menelusuri halaman web, dan mengekstrak data yang diinginkan. Dengan menggabungkan Puppeteer dengan fleksibilitas Node.js, kita dapat membangun solusi web scraping yang kuat dan efisien. Mari kita masuk ke langkah-langkah yang terlibat dalam mengambil data dari situs web menggunakan Puppeteer.
Apa Itu Puppeteer?
Puppeteer adalah kerangka kerja terkini yang memungkinkan penguji untuk melakukan pengujian browser tanpa antarmuka dengan Google Chrome. Dengan pengujian Puppeteer, penguji dapat mengeksekusi perintah JavaScript untuk berinteraksi dengan halaman web, termasuk tindakan seperti mengklik tautan, mengisi formulir, dan mengirim tombol.
Dikembangkan oleh Google, Puppeteer adalah perpustakaan Node.js yang memungkinkan kontrol yang mulus terhadap Chrome tanpa antarmuka melalui Protokol DevTools. Ini menyediakan sejumlah API tingkat tinggi yang memfasilitasi pengujian otomatis, pengembangan fitur situs web, debugging, inspeksi elemen, dan profiling kinerja.
Dengan Puppeteer, Anda dapat menggunakan (tanpa antarmuka) Chromium atau Chrome untuk membuka situs web, mengisi formulir, mengklik tombol, mengekstrak data, dan secara umum melakukan tindakan apa pun yang dapat dilakukan manusia saat menggunakan komputer. Ini membuat Puppeteer menjadi alat yang sangat kuat untuk web scraping, tetapi juga untuk mengotomasi alur kerja yang kompleks di web. Memiliki pemahaman yang jelas tentang Puppeteer dan kemampuannya sangat berharga bagi penguji dan pengembang dalam lingkungan pengembangan web modern.
Apa Keuntungan Menggunakan Puppeteer untuk Web Scraping?
Axios dan Cheerio adalah pilihan yang sangat baik untuk mengambil data dengan JavaScript. Namun, ini menimbulkan dua masalah: mengambil konten dinamis dan perangkat lunak anti-scraping. Karena Puppeteer adalah browser tanpa antarmuka, ia tidak mengalami kesulitan dalam mengambil konten dinamis.
Juga Puppeteer menawarkan sejumlah keuntungan signifikan untuk web scraping:
-
Otomatisasi Browser Tanpa Antarmuka: Dengan Puppeteer, Anda dapat mengontrol browser Chrome tanpa antarmuka secara programatis, memungkinkan otomatisasi tindakan browser seperti mengklik, menggulir, mengisi formulir, dan mengekstrak data tanpa jendela browser yang terlihat.
-
Fungsi Chrome Penuh dan Manipulasi DOM: Puppeteer menyediakan akses ke seluruh fungsi Chrome, membuatnya cocok untuk mengambil data dari situs web modern dengan konten yang berat JavaScript. Anda dapat dengan mudah berinteraksi dengan elemen halaman, mengubah atribut, dan melakukan tindakan seperti mengklik tombol atau mengirim formulir.
-
Simulasi Interaksi Pengguna dan Penangkapan Peristiwa: Puppeteer memungkinkan Anda untuk mensimulasikan interaksi pengguna dan menangkap permintaan dan respons jaringan. Ini memungkinkan pengambilan data dari halaman yang memerlukan input pengguna atau konten yang dimuat secara dinamis melalui permintaan AJAX atau WebSocket.
-
Kemampuan Kinerja dan Debugging: Mesin Chrome yang dioptimalkan dari Puppeteer memastikan pengambilan data yang efisien, dan integrasinya dengan DevTools menawarkan kemampuan debugging dan pengujian yang kuat. Anda dapat melakukan debugging halaman web, mencatat pesan konsol, melacak aktivitas jaringan, dan menganalisis metrik kinerja.
Dalam panduan berikut, saya akan menjelajahi proses web scraping menggunakan Puppeteer dan Node.js, serta mengintegrasikan solusi penyelesaian CAPTCHA terkini, CapSolver, untuk mengatasi salah satu tantangan utama yang dihadapi selama web scraping.
Kode Bonus
Kode bonus untuk solusi CAPTCHA terbaik; CapSolver : WEBS. Setelah Anda menukarkannya, Anda akan mendapatkan bonus tambahan 5% setiap kali recharge, Tak Terbatas

Cara Menyelesaikan CAPTCHA dalam Puppeteer menggunakan CapSolver saat Web Scraping
Tujuannya adalah menyelesaikan CAPTCHA yang terletak di recaptcha-demo.appspot.com menggunakan CapSolver.
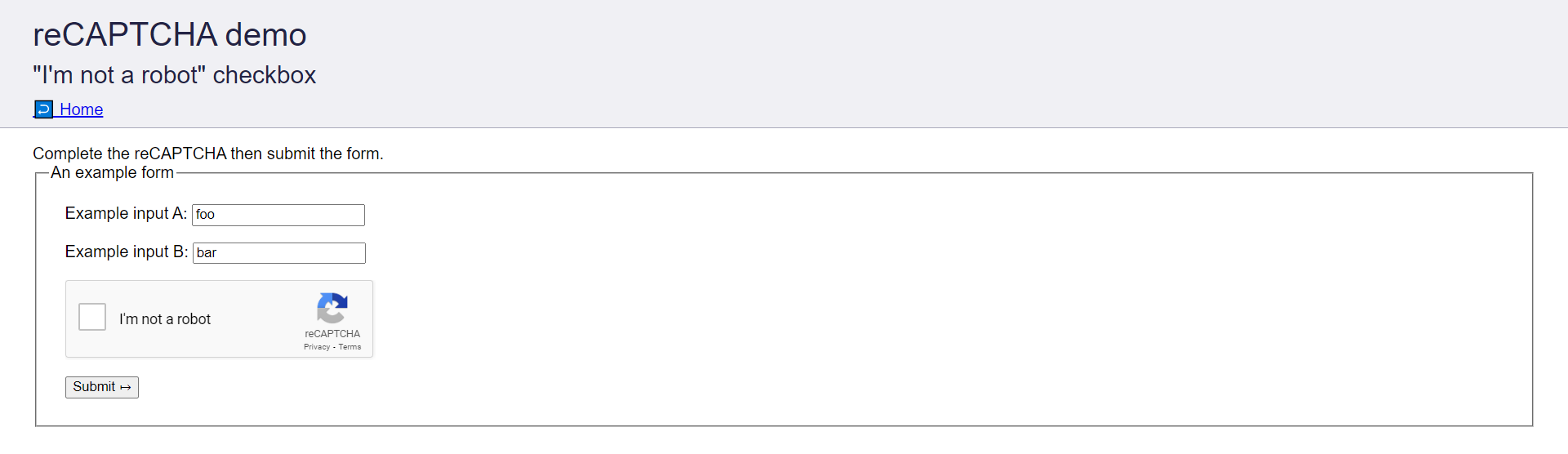
Selama tutorial ini, kita akan mengambil langkah-langkah berikut untuk menyelesaikan CAPTCHA di atas:
- Instal dependensi yang diperlukan.
- Temukan kunci situs dari Form CAPTCHA.
- Atur CapSolver.
- Selesaikan CAPTCHA.
Instalasi Dependensi yang Diperlukan
Untuk memulai, kita perlu menginstal dependensi berikut untuk tutorial ini:
- capsolver-python: SDK Python resmi untuk integrasi yang mudah dengan API CapSolver.
- pyppeteer: pyppeteer adalah port Python dari Puppeteer.
Instal dependensi ini dengan menjalankan perintah berikut:
python -m pip install pyppeteer capsolver-pythonSekarang, Buat file bernama main.py di mana kita akan menulis kode Python untuk menyelesaikan CAPTCHA.
bash
touch main.pyDapatkan Kunci Situs dari Form CAPTCHA
Kunci Situs adalah identifikasi unik yang diberikan oleh Google yang secara unik mengidentifikasi setiap CAPTCHA.
Untuk menyelesaikan CAPTCHA, diperlukan untuk mengirim Kunci Situs ke CapSolver.
Mari kita temukan Kunci Situs dari Form CAPTCHA dengan mengikuti langkah-langkah berikut:
- Kunjungi Form CAPTCHA.
- Buka Chrome Dev Tools dengan menekan
Ctrl/Cmd+Shift+I. - Pergi ke tab
Elementsdan caridata-sitekey. Salin nilai atributnya.
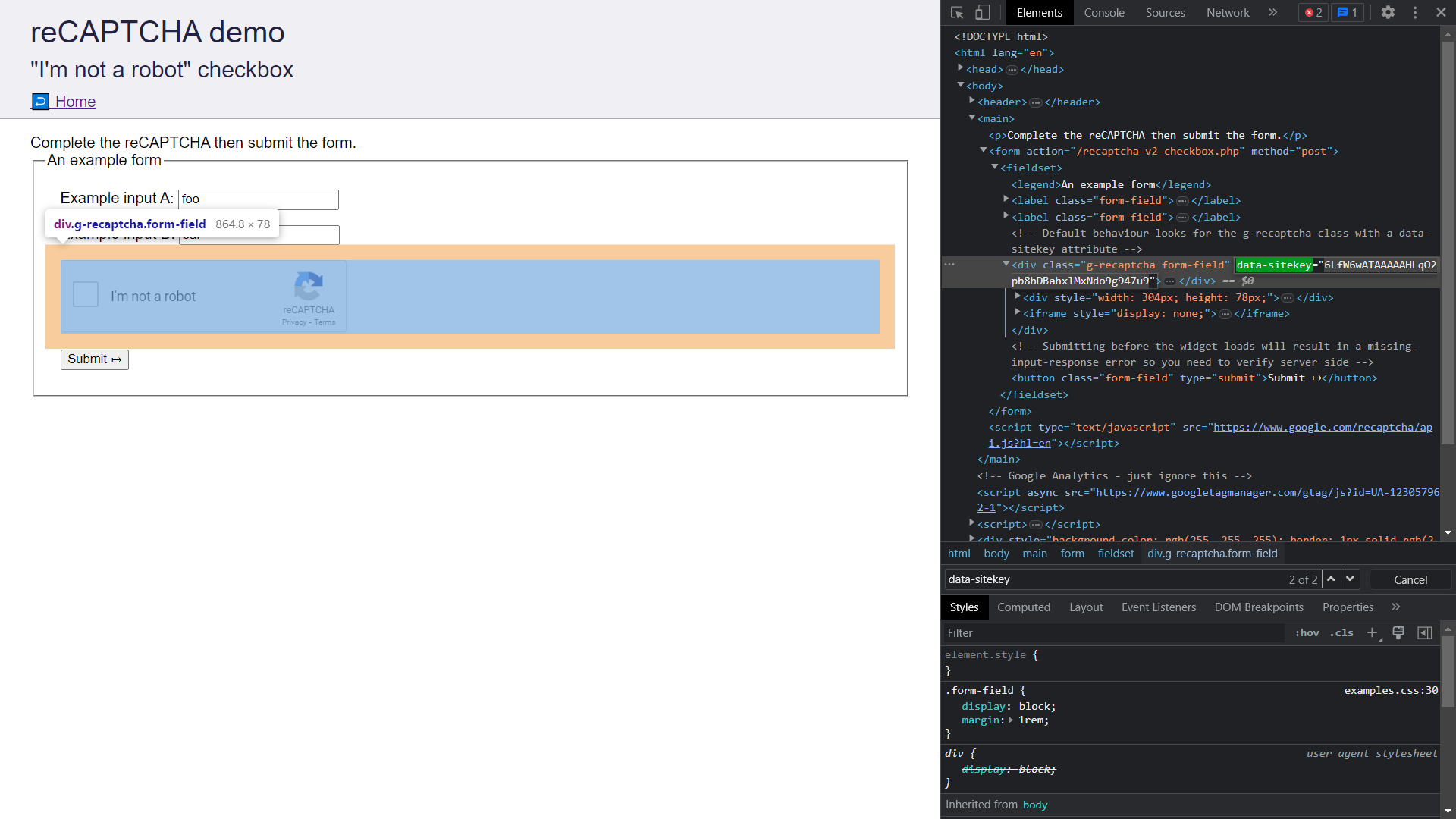
- Simpan Kunci Situs di tempat yang aman karena akan digunakan dalam bagian berikutnya saat kita mengirim CAPTCHA ke CapSolver.
Atur CapSolver
Untuk menyelesaikan CAPTCHA menggunakan CapSolver, Anda perlu membuat akun CapSolver, menambahkan dana ke akun Anda, dan mendapatkan Kunci API. Ikuti langkah-langkah berikut untuk menyiapkan akun CapSolver Anda:
-
Daftar untuk akun CapSolver dengan mengunjungi CapSolver
-
Tambahkan dana ke akun CapSolver Anda menggunakan PayPal, Kripto, atau metode pembayaran lain yang tercantum. Harap dicatat bahwa jumlah deposit minimum adalah $6, dan pajak tambahan berlaku.
-
Sekarang, salin Kunci API yang diberikan oleh CapSolver dan simpan dengan aman untuk digunakan nanti.
Menyelesaikan CAPTCHA
Sekarang, kita akan melanjutkan untuk menyelesaikan CAPTCHA menggunakan CapSolver. Proses keseluruhan melibatkan tiga langkah:
- Memulai browser dan mengunjungi halaman CAPTCHA menggunakan pyppeteer.
- Menyelesaikan CAPTCHA menggunakan CapSolver.
- Mengirimkan respons CAPTCHA.
Baca potongan kode berikut untuk memahami langkah-langkah ini.
Memulai browser dan mengunjungi halaman CAPTCHA:
python
# Mulai browser.
browser = await launch({'headless': False})
# Muat halaman target.
captcha_page_url = "https://recaptcha-demo.appspot.com/recaptcha-v2-checkbox.php"
page = await browser.newPage()
await page.goto(captcha_page_url)Menyelesaikan CAPTCHA menggunakan CapSolver:
python
# Selesaikan reCAPTCHA menggunakan CapSolver.
capsolver = RecaptchaV2Task("YOUR_API_KEY")
site_key = "6LfW6wATAAAAAHLqO2pb8bDBahxlMxNdo9g947u9"
task_id = capsolver.create_task(captcha_page_url, site_key)
result = capsolver.join_task_result(task_id)
# Dapatkan kode reCAPTCHA yang telah diselesaikan.
code = result.get("gRecaptchaResponse")Menyetel CAPTCHA yang telah diselesaikan pada formulir dan mengirimkannya:
python
# Setel kode reCAPTCHA yang telah diselesaikan pada formulir.
recaptcha_response_element = await page.querySelector('#g-recaptcha-response')
await page.evaluate(f'(element) => element.value = "{code}"', recaptcha_response_element)
# Kirim formulir.
submit_btn = await page.querySelector('button[type="submit"]')
await submit_btn.click()Menggabungkan Semuanya
Berikut adalah kode lengkap untuk tutorial ini, yang akan menyelesaikan CAPTCHA menggunakan CapSolver.
python
import asyncio
from pyppeteer import launch
from capsolver_python import RecaptchaV2Task
# Kode berikut menyelesaikan tantangan reCAPTCHA v2 menggunakan CapSolver.
async def main():
# Mulai Browser.
browser = await launch({'headless': False})
# Muat halaman target.
captcha_page_url = "https://recaptcha-demo.appspot.com/recaptcha-v2-checkbox.php"
page = await browser.newPage()
await page.goto(captcha_page_url)
# Selesaikan reCAPTCHA menggunakan CapSolver.
print("Menyelesaikan CAPTCHA")
capsolver = RecaptchaV2Task("YOUR_API_KEY")
site_key = "6LfW6wATAAAAAHLqO2pb8bDBahxlMxNdo9g947u9"
task_id = capsolver.create_task(captcha_page_url, site_key)
result = capsolver.join_task_result(task_id)
# Dapatkan kode reCAPTCHA yang telah diselesaikan.
code = result.get("gRecaptchaResponse")
print(f"Berhasil menyelesaikan reCAPTCHA. Kode penyelesaian adalah {code}")
# Setel kode reCAPTCHA yang telah diselesaikan pada formulir.
recaptcha_response_element = await page.querySelector('#g-recaptcha-response')
await page.evaluate(f'(element) => element.value = "{code}"', recaptcha_response_element)
# Kirim formulir.
submit_btn = await page.querySelector('button[type="submit"]')
await submit_btn.click()
# Berhenti sementara eksekusi sehingga Anda dapat melihat layar setelah pengiriman sebelum menutup driver
input("Pengiriman CAPTCHA Berhasil. Tekan enter untuk melanjutkan")
# Tutup Browser.
await browser.close()
if __name__ == "__main__":
asyncio.get_event_loop().run_until_complete(main())Tempelkan kode di atas ke file main.py Anda. Ganti YOUR_API_KEY dengan Kunci API Anda dan jalankan kode.
Anda akan melihat bahwa CAPTCHA akan diselesaikan, dan Anda akan dihargai dengan halaman sukses.
Cara Menyelesaikan CAPTCHA dalam NodeJS menggunakan CapSolver saat Web Scraping
Prasyarat
- Proxy (Opsional)
- Node.JS terinstal
- Kunci API Capsolver
Langkah 1: Instal Paket yang Diperlukan
Jalankan perintah berikut untuk menginstal paket yang diperlukan:
python
npm install axiosKode Node.JS untuk menyelesaikan reCaptcha v2 tanpa proxy
Berikut adalah skrip contoh Node.JS untuk menyelesaikan tugas:
js
const axios = require('axios');
const PAGE_URL = ""; // Ganti dengan Situs Anda
const SITE_KEY = ""; // Ganti dengan Situs Anda
const CLIENT_KEY = ""; // Ganti dengan Kunci API CAPSOLVER Anda
async function createTask(payload) {
try {
const res = await axios.post('https://api.capsolver.com/createTask', {
clientKey: CLIENT_KEY,
task: payload
});
return res.data;
} catch (error) {
console.error(error);
}
}
async function getTaskResult(taskId) {
try {
success = false;
while(success == false){
await sleep(1000);
console.log("Mengambil hasil tugas untuk ID tugas: " + taskId);
const res = await axios.post('https://api.capsolver.com/getTaskResult', {
clientKey: CLIENT_KEY,
taskId: taskId
});
if( res.data.status == "ready") {
success = true;
console.log(res.data)
return res.data;
}
}
} catch (error) {
console.error(error);
return null;
}
}
async function solveReCaptcha(pageURL, sitekey) {
const taskPayload = {
type: "ReCaptchaV2TaskProxyless",
websiteURL: pageURL,
websiteKey: sitekey,
};
const taskData = await createTask(taskPayload);
return await getTaskResult(taskData.taskId);
}
function sleep(ms) {
return new Promise(resolve => setTimeout(resolve, ms));
}
async function main() {
try {
const response = await solveReCaptcha(PAGE_URL, SITE_KEY );
console.log(`Menerima token: ${response.solution.gReCaptcharesponse}`);
}
catch (error) {
console.error(`Error: ${error}`);
}
}
main();👀 Informasi Lebih Lanjut
Kesimpulan:
Dalam tutorial ini, kita telah belajar cara menyelesaikan CAPTCHA menggunakan CapSolver saat melakukan web scraping dengan Puppeteer dan Node.js. Dengan memanfaatkan API CapSolver, kita dapat mengotomatisasi proses penyelesaian CAPTCHA dan membuat tugas web scraping menjadi lebih efisien dan andal. Ingatlah untuk mematuhi ketentuan dan kondisi situs web yang Anda ambil data dan gunakan web scraping secara bertanggung jawab.
Lihat Lebih Banyak
Web ScrapingApr 22, 2026
Arsitektur Pengambilan Data Web Rust untuk Ekstraksi Data yang Dapat Diskalakan
Pelajari arsitektur pengambilan data web Rust yang dapat diskalakan dengan reqwest, scraper, pengambilan data asinkron, pengambilan data browser tanpa tampilan, rotasi proxy, dan penanganan CAPTCHA yang sesuai aturan.

Web ScrapingFeb 17, 2026
Cara menyelesaikan Captcha di Nanobot dengan CapSolver
Mengotomasi penyelesaian CAPTCHA dengan Nanobot dan CapSolver. Gunakan Playwright untuk menyelesaikan reCAPTCHA dan Cloudflare secara otomatis.
