वेब स्क्रैपिंग क्या है | सामान्य उपयोग के मामले और समस्याएं

Rajinder Singh
Deep Learning Researcher

आपने संभवतः एक बात सुनी होगी कि डेटा को वर्तमान सूचना समाज में नए तेल कहा जाता है। ऑनलाइन उपलब्ध जानकारी के बड़े आकार के कारण, वेब डेटा को प्रभावी ढंग से एकत्र करने और विश्लेषित करने की क्षमता व्यवसायों, अनुसंधानकर्ताओं और विकासकर्ताओं के लिए एक महत्वपूर्ण कौशल बन गई है। इसी समय वेब स्क्रैपिंग का उपयोग करने का अवसर आता है। वेब स्क्रैपिंग, जिसे वेब डेटा निकालना भी कहा जाता है, वेबसाइटों से जानकारी के स्वचालित एकत्रीकरण के लिए एक शक्तिशाली तकनीक है। कल्पना करें कि आपको वेबसाइट से बहुत सारी महत्वपूर्ण जानकारी प्राप्त करने के लिए हाथ से डेटा कॉपी और पेस्ट करने की आवश्यकता नहीं होती है, लेकिन वेब स्क्रैपिंग का उपयोग सावधानी और सुसंगतता के साथ किया जाना चाहिए। इस ब्लॉग में वेब स्क्रैपिंग का एक संक्षिप्त परिचय दिया गया है और आपके सामने आ सकने वाली कुछ समस्याओं को संबोधित किया गया है। इसके अलावा इसमें कुछ सामान्य मामलों के बारे में भी बात की गई है।
वेब स्क्रैपिंग की समझ
वेब स्क्रैपिंग स्वचालित सॉफ्टवेयर उपकरणों के उपयोग के साथ वेब पेजों से डेटा एकत्र करता है, जिन्हें वेब स्क्रैपर कहा जाता है। इन उपकरणों को मानव ब्राउजिंग व्यवहार के नकली ढंग से वेबसाइटों के चारों ओर घूमने, लिंक पर क्लिक करने और HTML सामग्री से जानकारी निकालने के लिए डिज़ाइन किया गया है। निकाले गए डेटा में पाठ, चित्र, लिंक और अन्य मल्टीमीडिया तत्व शामिल हो सकते हैं। एकत्रित करने के बाद, डेटा को डेटाबेस या स्प्रेडशीट में संग्रहित किया जा सकता है जिससे आगे के विश्लेषण के लिए उपलब्ध हो सके।
वेब स्क्रैपर वेबसाइटों पर HTTP मांग भेजकर और HTML उत्तरों के विश्लेषण के माध्यम से काम करते हैं। उन्हें लिंक का पालन करने, पैजिनेशन का निपटारा करने और अधिक जटिल वेब एप्लिकेशन के साथ अंतःक्रिया करने के लिए कोडित किया जा सकता है। वेब स्क्रैपिंग के लिए लोकप्रिय प्रोग्रामिंग भाषाएं पायथन हैं, जिनमें BeautifulSoup, Scrapy और सेलेनियम जैसे लाइब्रेरी शामिल हैं, जो डेटा निकालने और वेब ऑटोमेशन के लिए शक्तिशाली कार्यक्षमता प्रदान करते हैं।
CapSolver बोनस कोड के लाभ उठाएं
अपने स्वचालन बजट को तुरंत बढ़ाएं!
CapSolver खाता भरने के समय बोनस कोड CAPN का उपयोग करके प्रत्येक भरोसा पर 5% बोनस प्राप्त करें — कोई सीमा नहीं।
CapSolver डैशबोर्ड में अभी बोनस कोड का उपयोग करें
।
वेब स्क्रैपिंग की कानूनीता
वेब स्क्रैपिंग के बारे में सबसे आम गलतफहमी यह है कि यह अवैध है। यह सही नहीं है!
वेब स्क्रैपिंग तब तक पूरी तरह से कानूनी है जब आप कुछ निर्देशों का पालन करते हैं: CCPA और GDPR नियमों का पालन करें, लॉगिन आंकड़ों द्वारा सुरक्षित डेटा में प्रवेश करने से बचें, और निजी रूप से पहचाने जा सकने वाले जानकारी के एकत्रीकरण से बचें। हालांकि, इसका अर्थ यह नहीं है कि आप बिना किसी चिंता के किसी भी वेबसाइट को स्क्रैप कर सकते हैं। नैतिक विचारों का ध्यान रखना आवश्यक है, जिसका अर्थ है कि आप हमेशा वेबसाइट के शर्तों के सेवा, robots.txt फ़ाइल और गोपनीयता नीतियों के सम्मान करना चाहिए।

मूल रूप से, वेब स्क्रैपिंग अवैध नहीं है, लेकिन विशिष्ट नियमों और नैतिक मानकों का पालन करना महत्वपूर्ण है।
वेब स्क्रैपिंग उपयोग मामले
आजकल डेटा-आधारित दुनिया में डेटा की कीमत तेल से अधिक हो गई है, और वेब उपयोगी जानकारी के एक बहुत बड़े स्रोत है। विभिन्न उद्योगों में कई कंपनियां वेब स्क्रैपिंग द्वारा निकाले गए डेटा का उपयोग अपने व्यापार ऑपरेशन को बेहतर बनाने के लिए करती हैं।
वेब स्क्रैपिंग के अनेक अनुप्रयोग हैं, यहां कुछ सबसे आम उपयोग मामले दिए गए हैं:
मूल्य तुलना
वेब स्क्रैपिंग उपकरणों के उपयोग से, व्यवसाय और उपभोक्ता विभिन्न खुदरा बिक्रीकर्ता और ऑनलाइन प्लेटफॉर्मों से उत्पाद मूल्य एकत्र कर सकते हैं। इस डेटा का उपयोग मूल्य तुलना, सबसे अच्छे लाभ प्राप्त करने और समय और पैसा बचाने के लिए किया जा सकता है। इसके अलावा, यह कंपनियों के प्रतियोगियों के मूल्य नीति की निगरानी करने में सहायता करता है।
बाजार निगरानी
वेब स्क्रैपिंग बाजार प्रवृत्ति, उत्पाद उपलब्धता और वास्तविक समय में मूल्य परिवर्तन की निगरानी करने की अनुमति देता है। अपडेटेड बाजार जानकारी के साथ रहने से, कंपनियां अपनी रणनीति के तेजी से अनुकूलन, नए अवसरों के उपयोग और बदलती ग्राहक मांग के जवाब देने में सक्षम होती हैं। यह प्रतिक्रियाशील दृष्टिकोण प्रतिस्पर्धी लाभ बनाए रखने में मदद करता है।
प्रतिद्वंद्वी विश्लेषण
प्रतिद्वंद्वी के उत्पादों, मूल्यों, प्रचार और ग्राहक प्रतिक्रिया के बारे में जानकारी एकत्र करके, कंपनियां अपने प्रतिद्वंद्वियों के बल और कमजोरियों के बारे में मूल्यवान दृष्टिकोण प्राप्त कर सकती हैं। स्वचालित उपकरण प्रतिद्वंद्वी वेबसाइटों और बाजार गतिविधियों के फोटो फ़िल्म को भी ले सकते हं, जो उन्हें बेहतर रणनीति विकसित करने के लिए एक व्यापक दृष्टिकोण प्रदान करते हैं।
नेतृत्व जनन
वेब स्क्रैपिंग नेतृत्व जनन को बदल दिया है, जो कि पहले एक कार्य के लिए कार्य करने वाली प्रक्रिया को एक स्वचालित प्रक्रिया में बदल दिया है। जनता के उपलब्ध संपर्क जानकारी जैसे ईमेल पते और फोन नंबर के निकाले गए डेटा के माध्यम से, कंपनियां तेजी से संभावित नेतृत्व के डेटाबेस बना सकती हैं। इस तेजी से दृष्टिकोण नेतृत्व जनन प्रक्रिया को तेज करता है।
भावना विश्लेषण
वेब स्क्रैपिंग रीव्यू साइटों और सोशल मीडिया प्लेटफॉर्मों से उपयोगकर्ता प्रतिक्रिया निकालकर भावना विश्लेषण की अनुमति देता है। इस डेटा के विश्लेषण से कंपनियों को अपने उत्पादों, सेवाओं और ब्रांड के बारे में जनता के विचार को समझने में मदद मिलती है। ग्राहक भावनाओं में जानकारी प्राप्त करके, कंपनियां ग्राहक संतुष्टि में सुधार कर सकती हैं और समस्याओं को पूर्वानुमान के साथ संबोधित कर सकती हैं।
सामग्री संग्रह
विभिन्न स्रोतों से सामग्री को एक एकल प्लेटफॉर्म में संग्रहित करने के लिए वेब स्क्रैपिंग का उपयोग किया जा सकता है। यह खबर वेबसाइटों, ब्लॉग और अनुसंधान पोर्टल के लिए विशेष रूप से उपयोगी है जिन्हें विभिन्न स्रोतों से अद्यतन जानकारी प्रदान करने की आवश्यकता होती है। सामग्री के स्वचालित संग्रह के माध्यम से, कंपनियां समय बचा सकती हैं और अपने प्लेटफॉर्म को अद्यतन रख सकती हैं।
अचल संपत्ति सूचियां
वेब स्क्रैपिंग का उपयोग अचल संपत्ति उद्योग में विभिन्न वेबसाइटों से संपत्ति सूचियां एकत्र करने के लिए किया जाता है। इस डेटा का उपयोग अचल संपत्ति एजेंसियों और संभावित खरीदारों के लिए उत्पादों की तुलना, बाजार प्रवृत्ति के विश्लेषण और ज्ञानपूर्ण निर्णय लेने में मदद करता है। अचल संपत्ति डेटा के संग्रह को स्वचालित करने से बाजार के बारे में व्यापक दृष्टिकोण प्रदान करता है।
वेब स्क्रैपिंग के प्रकार
वेब स्क्रैपर विभिन्न रूपों में आते हैं, जिनमें से प्रत्येक अलग-अलग उद्देश्यों और उपयोगकर्ता की आवश्यकताओं के लिए अनुकूलित होते हैं। आमतौर पर, उन्हें चार मुख्य प्रकारों में वर्गीकृत किया जा सकता है, जिनमें प्रत्येक विशिष्ट कार्यक्षमता और लाभ प्रदान करता है:
- डेस्कटॉप स्क्रैपर
डेस्कटॉप स्क्रैपर उपयोगकर्ता के कंप्यूटर में स्थापित एक स्वतंत्र सॉफ्टवेयर एप्लिकेशन हैं। इन उपकरणों में आमतौर पर बिना कोड के उपयोगकर्ता-मित्र इंटरफ़ेस होते हैं जो उपयोगकर्ताओं को सरल बिंदु-और-क्लिक अंतर्क्रिया के माध्यम से डेटा निकालने की अनुमति देते हैं। डेस्कटॉप स्क्रैपर के कार्यक्रमों में कार्य योजना, डेटा पार्सिंग और निर्यात विकल्प शामिल होते हैं, जो शुरुआती और उन्नत उपयोगकर्ताओं के लिए उपलब्ध होते हैं। ये मध्यम पैमाने पर स्क्रैपिंग कार्यों के लिए उपयुक्त हैं और कार्यक्षमता और उपयोग में आसानी के बीच एक अच्छा संतुलन प्रदान करते हैं।
- कस्टम-बिल्ट स्क्रैपर
कस्टम-बिल्ट स्क्रैपर विकासकर्ताओं द्वारा विभिन्न प्रौद्योगिकियों के उपयोग के साथ विकसित किए गए अत्यधिक लचीले समाधान हैं। इन स्क्रैपर को विशिष्ट डेटा निकालने की आवश्यकताओं के अनुरूप डिज़ाइन किया गया है, जो जटिल और बड़े पैमाने पर परियोजनाओं के लिए आदर्श हैं। अनुकूलित प्रकृति के कारण, कस्टम-बिल्ट स्क्रैपर जटिल वेब संरचना, डायनामिक सामग्री के नेविगेशन और बहुत से स्रोतों से डेटा निकालने में अत्यधिक कुशल होते हैं। इन्हें अपनी आवश्यकताओं के अनुरूप अनुकूलित स्क्रैपिंग समाधान की आवश्यकता वाले व्यवसायों के लिए अपनाया जाता है जिन्हें आसानी से विस्तारित और बदलती आवश्यकताओं के अनुरूप अनुकूलित किया जा सकता है।
- ब्राउज़र एक्सटेंशन स्क्रैपर
ब्राउज़र एक्सटेंशन स्क्रैपर चीजों जैसे कि क्रोम, फायरफॉक्स और सैफारी जैसे लोकप्रिय वेब ब्राउज़र के एड-ऑन हैं। इन एक्सटेंशन के उपयोग से उपयोगकर्ता वेबसाइटों पर ब्राउज़ करते समय डेटा निकाल सकते हैं। एक सीधा बिंदु-और-क्लिक इंटरफ़ेस के उपयोग से, उपयोगकर्ता वेब पृष्ठों से डेटा तत्वों का चयन और निकालना आसानी से कर सकते हैं। हालांकि, ब्राउज़र एक्सटेंशन स्क्रैपर छोटे और त्वरित कार्यों के लिए प्रभावी होते हैं, लेकिन अन्य स्क्रैपर प्रकारों की तुलना में कार्यक्षमता और विस्तार के मामले में सीमित होते हैं।
- क्लाउड-आधारित स्क्रैपर
क्लाउड-आधारित स्क्रैपर क्लाउड में काम करते हैं, जो विस्तारित और वितरित स्क्रैपिंग समाधान प्रदान करते हैं। इन स्क्रैपर को बड़े पैमाने पर डेटा निकालने के कार्यों के लिए अच्छी तरह से अनुकूलित किया गया है और अक्सर निर्मित डेटा प्रक्रिया और संग्रह क्षमता के साथ आते हैं। उपयोगकर्ता क्लाउड-आधारित स्क्रैपर के द्वारा दूरस्थ रूप से पहुंच कर सकते हैं, स्क्रैपिंग कार्यों की योजना बना सकते हैं, और स्थानीय बुनियादी ढांचा के बिना डेटा निकालने के नियंत्रण में रह सकते हैं। जबकि वे उच्च आयतन स्क्रैपिंग के लिए मजबूत क्षमता प्रदान करते हैं, जटिल और डायनामिक वेब सामग्री के साथ लचीलापन के मामले में कस्टम-बिल्ट स्क्रैपर के मुकाबले कम होते हैं।
जब कोई वेब स्क्रैपर चुनते हैं, तो कार्य की जटिलता, डेटा के आयतन और परियोजना के विस्तार और तकनीकी आवश्यकताओं को ध्यान में रखना आवश्यक है। प्रत्येक स्क्रैपर प्रकार के अपने अपने बल और उपयोग के मामले होते हैं, और चयन उपयोगकर्ता या संगठन की विशिष्ट आवश्यकताओं पर निर्भर करता है।
वेब स्क्रैपिंग में चुनौतियों का सामना करना
वेब स्क्रैपिंग, जबकि शक्तिशाली है, तेजी से बदलते इंटरनेट वातावरण और वेबसाइटों द्वारा उपयोग की जाने वाली सुरक्षा उपायों के कारण बड़ी बाधाओं का सामना करता है, यह एक सरल कार्य नहीं है, और आपके पास निम्नलिखित प्रकार की समस्याओं के साथ आने की उच्च संभावना है
वेब स्क्रैपिंग की प्राथमिक कठिनाई वेबपेज के HTML संरचना पर निर्भरता है। जब भी कोई वेबसाइट अपने उपयोगकर्ता इंटरफेस को अपडेट करती है, अभीष्ट डेटा रखने वाले HTML तत्व बदल सकते हैं, जिससे आपका स्क्रैपर अकार्यकारी हो जाता है। इन बदलावों के अनुकूलन के लिए आपको अपने निकालने के तर्क को लगातार अपडेट करने की आवश्यकता होती है। कमजोर HTML तत्व चयनकर्ता का उपयोग इस समस्या को कम कर सकता है, लेकिन कोई एक आकार सभी के लिए उपयुक्त समाधान नहीं है।
दुर्भाग्य से, अब अधिक जटिलता है, और अधिक जटिल है।
वेबसाइट अपने डेटा को स्वचालित स्क्रैपर से बचाने के लिए उन्नत प्रौद्योगिकी का उपयोग करती हैं। इन प्रणालियां स्वचालित मांगों की पहचान कर सकती हैं और इसके लिए रेड लाइट दिखा सकती हैं, जो एक महत्वपूर्ण बाधा है। यहां कुछ सामान्य चुनौतियां हैं जिनका सामना स्क्रैपर करते हैं:
- IP बैन: सर्वर आकस्मिक पैटर्न के लिए आने वाले मांगों की निगरानी करते हैं। स्वचालित सॉफ्टवेयर की पहचान आमतौर पर IP ब्लैकलिस्टिंग के कारण होती है, जो वेबसाइट तक पहुंच को रोकती है।
- भू-सीमा सीमाबद्धता: कुछ वेबसाइट उपयोगकर्ता के भू-भाग पर आधारित एक्सेस को सीमित करती हैं। इसका अर्थ है कि विदेशी उपयोगकर्ताओं को कुछ सामग्री तक पहुंच से रोका जा सकता है या भू-भाग के आधार पर अलग-अलग डेटा प्रस्तुत किया जा सकता है, जो स्क्रैपिंग प्रक्रिया को जटिल बना देता है।
- दर सीमाबद्धता: एक छोटे समय अवधि में बहुत सारी मांग करना DDoS सुरक्षा उपायों या IP बैन को चालू कर सकता है, जो स्क्रैपिंग ऑपरेशन को बाधित कर सकता है।
- कैप्चा: वेबसाइट आमतौर पर कैप्चा का उपयोग मानव और बॉट के बीच अंतर करने के लिए करती हैं, विशेष रूप से जब आकस्मिक गतिविधि का पता लगाया जाता है। कैप्चा को कार्यक्रम के माध्यम से हल करना बहुत चुनौतिपूर्ण है, जो आमतौर पर स्वचालित स्क्रैपर को असफल कर देता है।
पहले तीन समस्याओं को प्रॉक्सी बदलकर या फिंगरप्रिंटिंग ब्राउज़र का उपयोग करके हल किया जा सकता है, लेकिन अंतिम कैप्चा के लिए जटिल अस्थायी समाधान होते हैं जो अस्थायी परिणाम देते हैं या केवल छोटे समय अवधि में हल किए जा सकते हैं। किसी भी तकनीक का उपयोग करने के बावजूद, इन बाधाओं वेब स्क्रैपिंग उपकरण की प्रभावशीलता और स्थिरता को कम कर देती हैं।
खुश बात यह है कि इस समस्या के लिए एक समाधान है, जो CapSolver है, जो इन चुनौतियों के लिए व्यापक समाधान प्रदान करता है। CapSolver कैप्चा हल करने में विशेषज्ञ है और वेब स्क्रैपिंग के लिए उन्नत तकनीक के माध्यम से प्रभावी और स्थिर वेब स्क्रैपिंग की सुविधा प्रदान करता है। CapSolver के साथ अपने स्क्रैपिंग प्रक्रिया में एकजुट करके, आप इन चुनौतियों के बाहर निकल सकते हैं, यहां कुछ आधारभूत कदम हैं।
कैप्चा हल करने वाले सेवाओं के एकीकरण
आपके स्क्रैपिंग स्क्रिप्ट में एकीकृत करने के लिए कई कैप्चा हल करने वाली सेवाएं उपलब्ध हैं। यहां हम CapSolver सेवा का उपयोग करेंगे। पहले, आपको CapSolver के सेवाओं का उपयोग करने के लिए पंजीकरण करना होगा और अपना API कुंजी प्राप्त करना होगा।
चरण 1: CapSolver के लिए पंजीकरण करें
CapSolver के सेवाओं का उपयोग करने से पहले, आपको यूजर पैनल में जाकर अपना खाता पंजीकृत करें।
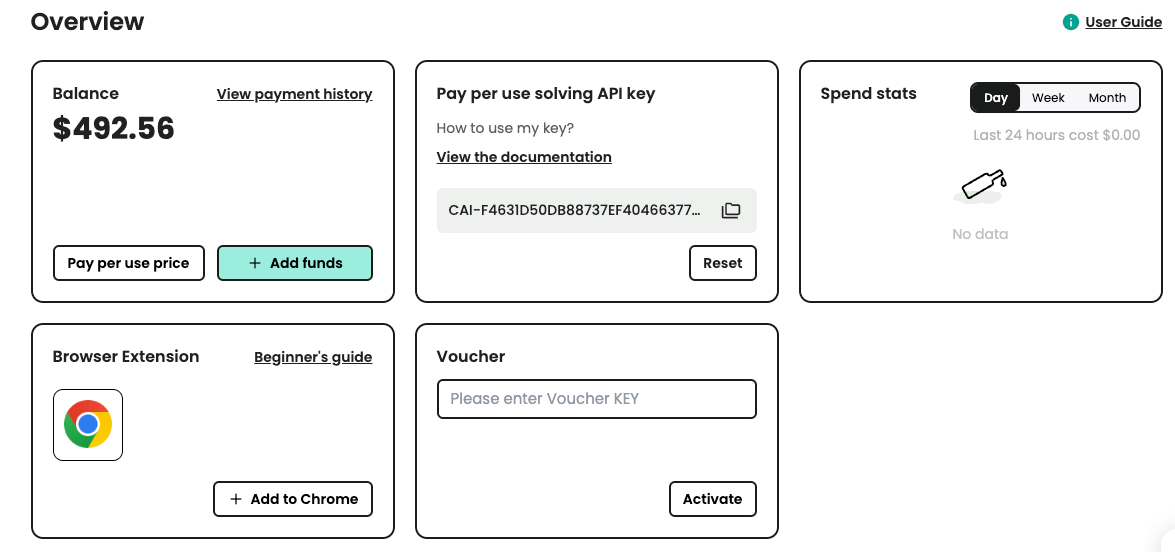
चरण 2: अपना API कुंजी प्राप्त करें
जब आप पंजीकृत हो जाते हैं, तो आप अपना api कुंजी होम पेज पैनल से प्राप्त कर सकते हैं
CapSolver के लिए उदाहरण कोड
आपके वेब स्क्रैपिंग या ऑटोमेशन परियोजना में CapSolver का उपयोग करना सरल है। यहां हम आपके कार्यप्रणाली में CapSolver के एकीकरण के बारे में एक तेज उदाहरण पायथन में देखते हैं:
python
# pip install requests
import requests
import time
# TODO: set your config
api_key = "YOUR_API_KEY" # अपना capsolver का api कुंजी
site_key = "6Le-wvkSAAAAAPBMRTvw0Q4Muexq9bi0DJwx_mJ-" # अपने लक्ष्य साइट का साइट कुंजी
site_url = "" # अपने लक्ष्य साइट का पृष्ठ URL
def capsolver():
payload = {
"clientKey": api_key,
"task": {
"type": 'ReCaptchaV2TaskProxyLess',
"websiteKey": site_key,
"websiteURL": site_url
}
}
res = requests.post("https://api.capsolver.com/createTask", json=payload)
resp = res.json()
task_id = resp.get("taskId")
if not task_id:
print("कार्य बनाने में असफल:", res.text)
return
print(f"कार्य आईडी प्राप्त की गई: {task_id} / परिणाम प्राप्त कर रहे हैं...")
while True:
time.sleep(3) # देर
payload = {"clientKey": api_key, "taskId": task_id}
res = requests.post("https://api.capsolver.com/getTaskResult", json=payload)
resp = res.json()
status = resp.get("status")
if status == "ready":
return resp.get("solution", {}).get('gRecaptchaResponse')
if status == "failed" or resp.get("errorId"):
print("हल करना असफल रहा! प्रतिक्रिया:", res.text)
return
token = capsolver()
print(token)इस उदाहरण में, capsolver कार्य आवश्यक पैरामीटर के साथ CapSolver के API को मांग भेजता है और कैप्चा हल वापस करता है। यह सरल एकीकरण वेब स्क्रैपिंग और ऑटोमेशन कार्यों के दौरान कैप्चा हल करने में हजारों घंटों के कार्य को बचा सकता है।
निष्कर्ष
वेब स्क्रैपिंग ऑनलाइन डेटा के एकत्रीकरण और विश्लेषण के तरीकों को बदल दिया है। मूल्य तुलना से लेकर बाजार प्रवृत्ति और नेतृत्व जनन तक, इसके अनुप्रयोग विविध और शक्तिशाली हैं। वेबसाइटों द्वारा उपयोग की जाने वाली रक्षा उपायों के कारण चुनौतियों के बावजूद, CapSolver जैसे समाधान वेब स्क्रैपिंग की प्रक्रिया को आसान बनाते हैं।
नैतिक निर्देशों का पालन करते हुए और उन्नत उपकरणों का उपयोग करके, व्यवसाय और विकासकर्ता वेब स्क्रैपिंग के पूर्ण संभावनाओं का उपयोग कर सकते हैं। डेटा एकत्र करना केवल एक बात नहीं है; यह दृष्टिकोण के अंतर्दृष्टि के खुलासा करने, नवाचार के अनुप्रयोग के अनुमोदन करने और आज के डिजिटल परिदृश्य में प्रतिस्पर्धा बनाए रखने में मदद करने वाली बात है।
अक्सर पूछे
सबसे सुरक्षित और विश्वसनीय तरीका रीकैपचा, हीकैपचा या क्लाउडफ्लार टर्नस्टाइल को बीपीसी करने के लिए एक विशेष रूप से डिज़ाइन किए गए कैपचा हल करने वाले एपीआई का उपयोग करना है, जैसे कि कैपसॉल्वर। यह स्क्रैपिंग स्क्रिप्ट्स, ब्राउजर ऑटोमेशन टूल्स (पुप्पेटीयर, प्लेयराइट, सीलेनियम) के साथ एकीकृत होता है और मैनुअल हस्तक्षेप के बिना चुनौती टोकन को स्वचालित रूप से संभालता है। अनुशंसित स्क्रिप्ट या बॉट का उपयोग करने से बचें ताकि खाता ब्लॉक करने या सुरक्षा जोखिम से बचा जा सके।
2. मेरा स्क्रैपर क्यों ब्लॉक हो जाता है जब मैं प्रॉक्सी के चक्रण का उपयोग करता हूं?
अब वेबसाइट्स बॉट डिटेक्शन के कई स्तरों का उपयोग करती हैं, जैसे ब्राउजर फिंगरप्रिंट चेक, व्यवहार विश्लेषण, टीएलएस फिंगरप्रिंटिंग और कैपचा चुनौतियां। यहां तक कि प्रॉक्सी के चक्रण के साथ, भी अगर आपका ब्राउजर पर्यावेशन स्वचालित लगता है तो स्क्रैपिंग विफल हो सकती है। वास्तविक ब्राउजर इंजन के साथ सही हेडर्स, मानव-जैसे समय और कैपचा हल करने वाली सेवा का उपयोग करने से सफलता दर में महत्वपूर्ण वृद्धि होती है।
3. स्वचालन कार्यों के लिए कैपचा हल करने वाली सेवाओं के उपयोग करना कानूनी है?
हां—कैपचा हल करने वाली सेवाएं कानूनी होती हैं जब उनका उपयोग संगत कार्यों जैसे डेटा अनुसंधान, एसईओ मॉनिटरिंग, मूल्य ट्रैकिंग या वेबसाइट की शर्तों के उल्लंघन या सुरक्षित डेटा के अनुप्रयोग के बिना स्वचालन के लिए किया जाता है। हमेशा अपने उपयोग के मामले को स्थानीय गोपनीयता नियमों (जीडीपीआर, सीसीपीए) के अनुसार रखें और प्लेटफॉर्म नियमों का सम्मान करें।
4. जावास्क्रिप्ट-रेंडर्ड वेबसाइट्स के लिए स्क्रैपिंग का सबसे अच्छा तरीका क्या है?
जावास्क्रिप्ट-भारी वेबसाइट्स के लिए, पुप्पेटीयर, प्लेयराइट या सीलेनियम जैसे हेडलेस ब्राउजर उच्चतम सफलता दर प्रदान करते हैं। वे पूरी तरह से स्क्रिप्ट को चलाते हैं, डायनामिक सामग्री लोड करते हैं और वास्तविक उपयोगकर्ता व्यवहार की नकल करते हैं। बड़े पैमाने पर डेटा निकालने के लिए, इन टूल्स के साथ प्रॉक्सी, दर सीमा निर्धारण और कैपचा हल करने के एकीकरण का उपयोग करें।
5. कैपसॉल्वर सुरक्षित वेबसाइट्स पर स्वचालन सफलता को कैसे सुधारता है?
कैपसॉल्वर उच्च सटीकता के साथ रीकैपचा, जियेटी, टर्नस्टाइल और अन्य बॉट-प्रतिबंध चुनौतियों को स्वचालित रूप से हल करता है। यह स्क्रैपिंग फ्रेमवर्क के साथ बिना किसी असुविधा के काम करता है और सत्यापन दीवारों के कारण विफलता दर को कम करता है। इससे बेहतर ड्रॉलिंग, कम अवरोध और स्वचालन दक्षता में सुधार होता है।
6. मैं अपने स्वचालन के बॉट के रूप में पहचाने जाने की संभावना कम कैसे कर सकता हूं?
वास्तविक ब्राउजर फिंगरप्रिंट का उपयोग करें, उच्च गुणवत्ता वाले प्रॉक्सी के चक्रण का उपयोग करें, प्राकृतिक देरी का अनुकरण करें, संसाधनों को सामान्य रूप से लोड करें और तेज अनुरोधों के साथ एंडपॉइंट को बरसाने से बचें। इन कदमों के साथ कैपचा हल करने के साथ संयोजन करने से आपका स्क्रैपर वास्तविक मानव सत्र के रूप में दिखाई देता है।
और देखें
Web ScrapingApr 22, 2026
रस्ट वेब स्क्रैपिंग आर्किटेक्चर लिए स्केलेबल डेटा निष्कर्षण
Rust में वेब स्क्रैपिंग के स्केलेबल आर्किटेक्चर सीखें, reqwest, scraper, असिंक्रोनस स्क्रैपिंग, हेडलेस ब्राउज़र स्क्रैपिंग, प्रॉक्सी रोटेशन, और संगत CAPTCHA का निपटारा।
Web ScrapingFeb 03, 2026
रॉक्सीब्राउज़र में कैप्चा हल करना कैपसॉल्वर एकीकरण के साथ
CapSolver के साथ RoxyBrowser के एकीकरण करें ताकि ब्राउज़र के कार्यों को स्वचालित किया जा सके और reCAPTCHA, Turnstile और अन्य CAPTCHAs को बायपास किया जा सके।