एआई डेटा निष्कर्षण कैसे काम करता है: CAPTCHA हल करना, LLM पार्सिंग और संरचित वेब डेटा पाइपलाइन्स

Rajinder Singh
Deep Learning Researcher
परिचय: विश्लेषण से आगे, यह अधिग्रहण के बारे में है
पारंपरिक वेब डेटा निष्कर्षण निर्माण वाले मिलान विधियों पर निर्भर करता है जैसे कि CSS सेलेक्टर, XPath और नियमित अभिव्यक्तियां, जो डीओएम (DOM) पेड़ में निश्चित स्थानों पर बंधे रहते हैं ताकि मान प्राप्त किए जा सकें। अक्सर पृष्ठ डिज़ाइन पुनर्निर्माण, डायनामिक रेंडरिंग के व्यापक उपयोग और बहु-स्तरीय एंटी-स्क्रैपिंग अपग्रेड के सामने, इस परंपरा ने उच्च रखरखाव लागत और असिंक्रोनस सामग्री के "अंधापन" जैसी संरचनात्मक कमजोरियां उजागर की हैं। बड़े भाषा मॉडल (LLM) की परिपक्वता एक मोड़ लाती है: डेटा निष्कर्षण अब "कौन से टैग में डेटा स्थित है?" के स्थान पर "पृष्ठ सामग्री कौन सा प्रश्न उत्तर देती है?" को समझने के लिए कहता है, एक नए परंपरा में प्रवेश करता है जो प्राकृतिक भाषा समझ पर आधारित है। यह परिवर्तन शुद्ध रूप से सैद्धांतिक नहीं है; AXE जैसे फ्रेमवर्क, असंबंधित DOM नोड्स को काटकर और छोटे मॉडल के साथ संयोजन में संरचित आउटपुट उत्पन्न करके, SWDE डेटासेट पर 88.1% के F1 स्कोर तक पहुंच गए, अर्थात सामग्री निष्कर्षण की संभावना और दक्षता की पुष्टि करता है। इस लेख में, डेटा अधिग्रहण परत जो एंटी-क्रॉलिंग और CAPTCHAs के साथ निपटती है, सामग्री साफ करने और LLM सामग्री निष्कर्षण की प्रक्रिया परत तक पहुंचती है, अंत में संरचित डेटा के भंडारण और उपभोग पर ध्यान केंद्रित करते हुए, इंजीनियरिंग के अभिन्न दृष्टिकोण से प्रत्येक चरण के तकनीकी सिद्धांत और मुख्य व्यापारिक विकल्पों का विश्लेषण किया जाएगा।
I. परंपरा का परिवर्तन: नियम-आधारित विश्लेषण से प्राकृतिक भाषा प्रसंस्करण तक
AI डेटा निष्कर्षण के तकनीकी विवरण में प्रवेश करने से पहले, यह समझना आवश्यक है कि पुरानी परंपरा जिसे यह बदल रहा है, क्यों अपनी सीमा तक पहुंच गई है, और नई परंपरा किस आयाम में एक अप्रत्याशित उपलब्धि हासिल कर रही है।
1.1 नियम-आधारित विश्लेषण के तीन विवाद
पारंपरिक वेब डेटा निष्कर्षण की मुख्य विधि "पथ स्थान निर्धारण" है: विकसकर ब्राउज़र डेवलपर टूल्स का उपयोग करके लक्ष्य डेटा के स्थान पर DOM नोड की जांच करते हैं, फिर हाथ से CSS सेलेक्टर या XPath अभिव्यक्तियां लिखते हैं जो उस नोड को निर्दिष्ट करती हैं। इस परंपरा ने पिछले दशक में वेब डेटा संग्रह की बहुत बड़ी मांग को समर्थित किया है, लेकिन वेब प्रौद्योगिकी के विकास के साथ लगातार बढ़ती तीन संरचनात्मक कमजोरियां हैं।
1.1.1 भंगुर आधार: स्थिर नियम एक डायनामिक दुनिया में अनुकूलित नहीं हो सकते
आधुनिक वेबसाइट औसतन 3 से 6 महीने में बड़े पैमाने पर DOM संरचना परिवर्तन करती हैं। प्रत्येक डिज़ाइन बदलाव के कारण, निश्चित पथ पर आधारित क्रॉलर नियम अमान्य हो जाते हैं। एक साथ सैकड़ों लक्ष्य नोड्स के रखरखाव करने वाली टीमों के लिए, यह एक लगातार "मूंछ वाले मुर्गे" रखरखाव चक्र बन जाता है। चित्र 1-1 आधुनिक वेबसाइटों के सामने पारंपरिक क्रॉलर के पूर्ण कार्यप्रणाली को दर्शाता है, प्रत्येक चरण से अनुक्रम में अनुरोध से डेटा निष्कर्षण तक और सामना की गई समस्याओं को दर्शाता है:
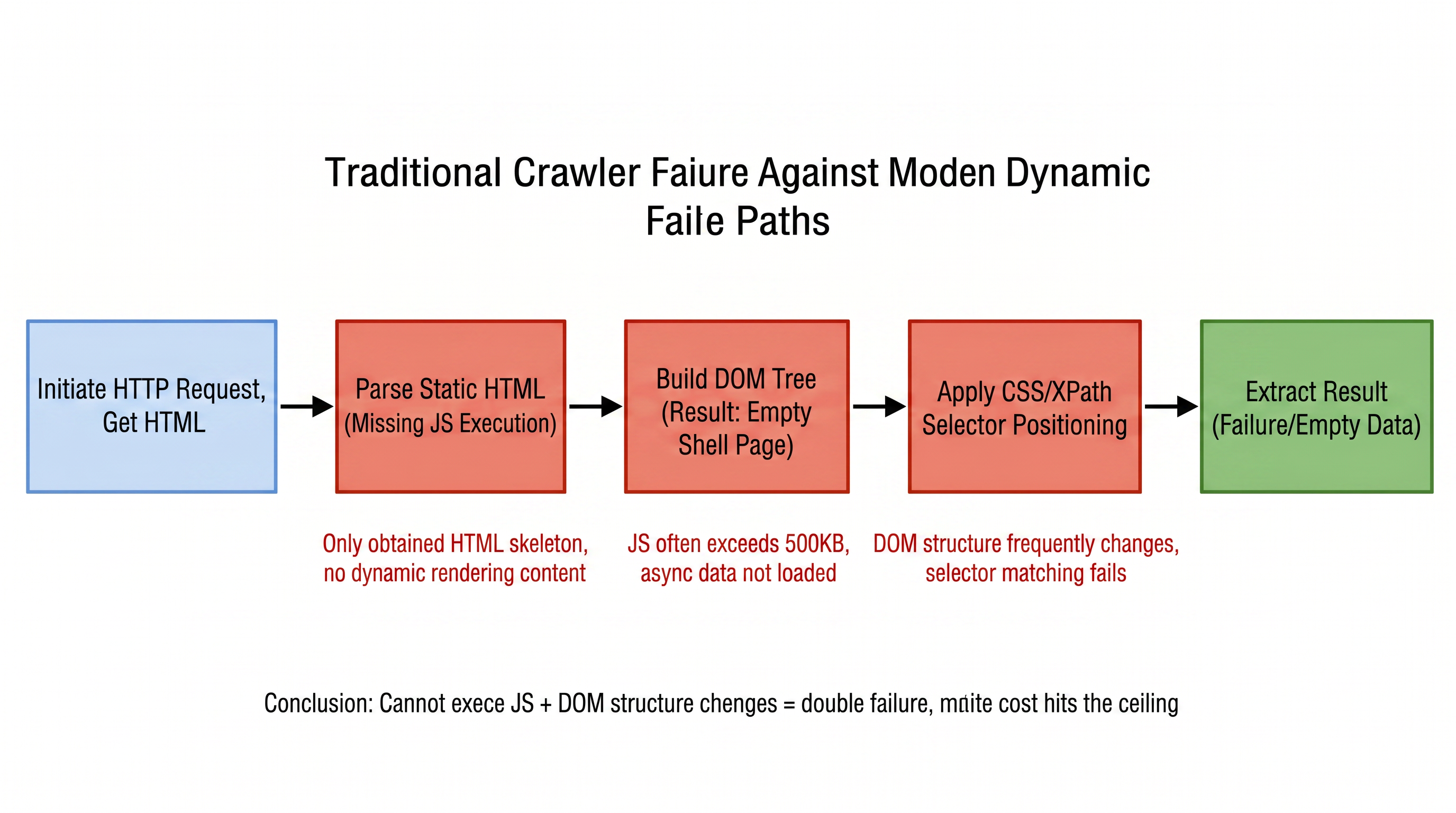
इस प्रक्रिया में पहली चुनौती के मूल तर्क का पता लगाया जाता है: स्थिर विश्लेषण क्षमता और डायनामिक रेंडरिंग सामग्री के बीच असंगति। W3Techs के आंकड़ों के अनुसार, 2025 के अंत तक, विश्व के लगभग X% वेबसाइट Cloudflare जैसे एंटी-स्क्रैपिंग सेवाओं का उपयोग करेंगे। नेटक्राफ्ट के समान समय में वेबसाइटों की कुल संख्या के पता लगाने के आधार पर, यह 290 मिलियन साइटों के बराबर है, और वेब पृष्ठों के माध्यम जीएस का आकार 500 केबी से अधिक है। पारंपरिक क्रॉलर केवल अनरेंडर्ड स्केलेटन प्राप्त कर सकते हैं, न कि "कोई डेटा नहीं देख रहे हैं" बल्कि, जब वेबसाइट फिर से डिज़ाइन की जाती है, तो मेहनत से लिखे गए सेलेक्टर तुरंत अमान्य हो जाते हैं। इस "तकनीकी अक्षमता" और "रखरखाव की भंगुरता" के संयोजन में, नियम-आधारित विश्लेषण के क्षेत्र को लगातार सीमित कर दिया जाता है।
1.1.2 अंधी आंखें: व्याकरणिक मिलान पूरी तरह से अर्थ को समझ नहीं पाता
पारंपरिक विधियां केवल "डेटा इस स्थान पर है" का उत्तर दे सकती हैं, न कि "इस स्थान पर डेटा क्या है?" एक ही उत्पाद सूची पृष्ठ पर, प्रचार मूल्य, सुझाए गए मूल्य और उत्पाद मूल्य एक साथ हो सकते हैं - उनके पास DOM में समान टैग होते हैं, जिसके कारण पारंपरिक नियम उन्हें अलग नहीं कर सकते। तीन असमान तारीख फॉर्मेट के सामने, जैसे "2026-04-28", "April 28, 2026", और "28/04/2026", पारंपरिक पार्सर को प्रत्येक फॉर्मेट के लिए अलग-अलग नियमित अभिव्यक्ति लिखनी पड़ती है और फॉर्मेट में डायनामिक परिवर्तन के सामने असमर्थ हो जाते हैं। चित्र 1-2 छह मुख्य आयामों में पारंपरिक नियम-आधारित पार्सिंग और AI सामग्री निष्कर्षण के बीच अंतर को दृश्य रूप से तुलना करता है:
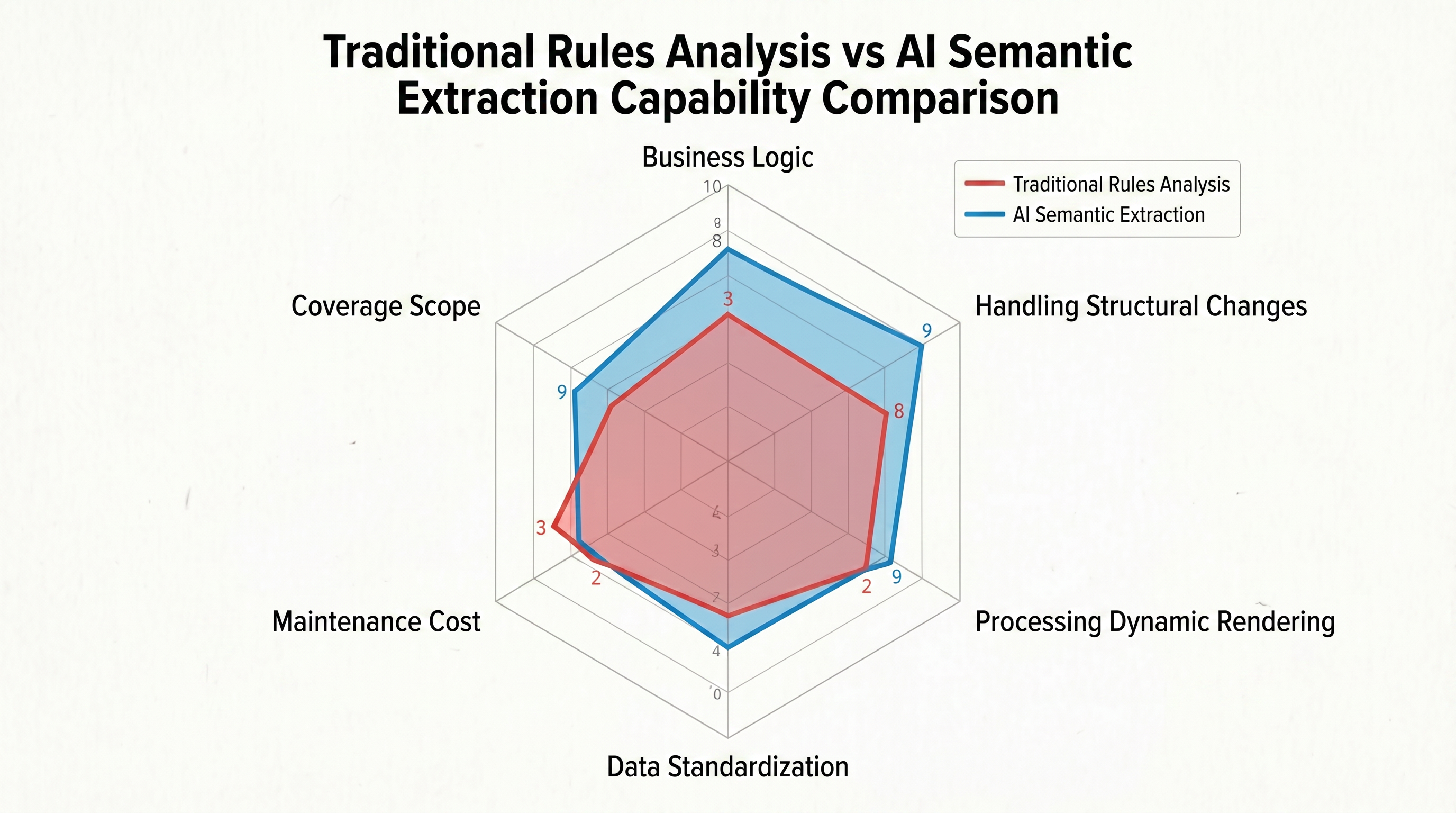
रेडार चार्ट के आकार स्पष्ट रूप से बताता है कि पारंपरिक नियम-आधारित पार्सिंग "कार्यक्रम तर्क" आयाम में निश्चित DOM पथ स्थान निर्धारण पर निर्भर करता है, जो इसकी एकमात्र कार्यकारी रणनीति है। हालांकि, अन्य पांच आयामों में, इसकी क्षमता समग्र रूप से सीमित है - इसकी संरचनात्मक परिवर्तन के प्रति अनुकूलन क्षमता बहुत कम है, डायनामिक रेंडरिंग प्रसंस्करण बाहरी उपकरणों पर निर्भर करता है, डेटा मानकीकरण के लिए हाथ से नियमित अभिव्यक्ति लिखना आवश्यक होता है, रखरखाव लागत साइटों की संख्या के साथ रैखिक रूप से बढ़ती है, और इसकी कवरेज एक साइट के लिए एक सेट नियम तक सीमित है। छह अक्षों में पांच गंभीर रूप से घुटे हुए हैं, और चित्र एक "संकुचित" अनियमित बहुभुज के रूप में दिखाई देता है।
विपरीत, AI सामग्री निष्कर्षण के लिए रेडार चार्ट आंतरिक रूप से और बाहरी रूप से बराबर रूप से विस्तारित होता है: यह अर्थ के आधार पर संरचनात्मक परिवर्तन के साथ स्वयं अनुकूलित होता है, ब्राउज़र के साथ डायनामिक रेंडरिंग के पूर्ण प्रसंस्करण करता है, LLM के आंतरिक फॉर्मेट रूपांतरण क्षमता के माध्यम से शून्य-नियम मानकीकरण हासिल करता है, रखरखाव लागत मॉडल क्षमता में सुधार के साथ कम हो जाती है, और एक ही स्कीमा एक पूरे साइट के समान पृष्ठों को कवर कर सकता है।
इन छह क्षमता की कमियों में से प्रत्येक एक स्वतंत्र तकनीकी बाधा नहीं है, बल्कि "मैकेनिकल मिलान" के नींव के तर्क के प्राकृतिक परिणाम हैं - जब तक डेटा निष्कर्षण व्याकरणिक स्तर पर रहता है, चाहे नियम कितना भी चालाक रूप से डिज़ाइन किया गया हो, इस संरचनात्मक असमानता को दूर नहीं किया जा सकता। इसलिए, इन समस्याओं को पूरी तरह से हल करने के लिए, नियमों के अपडेट की आवश्यकता नहीं है, बल्कि परंपरा को बदलना आवश्यक है।
1.1.3 स्पष्ट छत: क्यों इस परंपरा को बदला जाना है
नियम-आधारित पार्सिंग परंपरा के सभी विवाद एक स्रोत से उत्पन्न होते हैं: यह हमेशा "व्याकरणिक स्तर" पर "मैकेनिकल मिलान" करता है। यह कार्यक्रम तर्क इसकी "सटीक स्थान निर्धारण" क्षमता के लिए निर्भर करता है - डेटा के डीओएम पथ की सटीक खोज, लेकिन "सक्रिय रूप से बदले गए पृष्ठ संरचना के प्रति अनुकूलन" के लाभ के बदले। यदि साइट के डिज़ाइन बदल जाते हैं, तो नियम अमान्य हो जाते हैं; यदि डेटा प्रकार असमान हैं, तो नए नियमित अभिव्यक्ति के हाथ से लिखने की आवश्यकता होती है। लक्ष्य वेबसाइट द्वारा नेतृत्व करने वाले इस प्रकार के मोड के कारण "संरचनात्मक छत" है जिसे नियम-आधारित पार्सिंग अतिक्रमित नहीं कर सकता। चित्र 1-3 इस परंपरा के मूल लंबे समय तक उत्परिवर्तन के रूप में एक तुलनात्मक विकास के रूप में अग्रणी दिशा के बारे में पूर्वानुमान देता है।
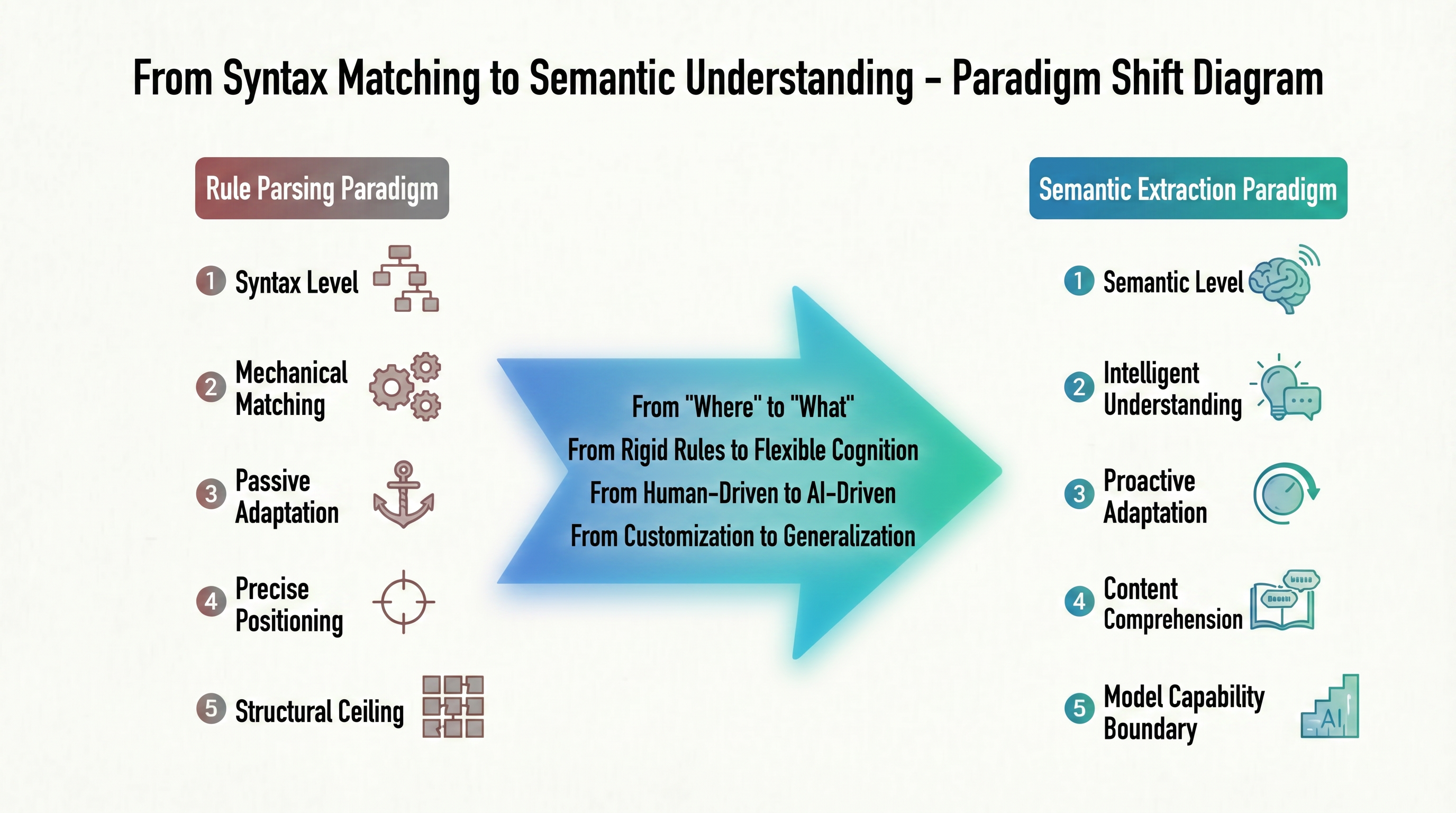
ऊपर के चित्र से स्पष्ट है कि यह एक ही मार्ग पर तकनीकी सुधार नहीं है, बल्कि दो आधुनिक अलग मार्ग हैं। बाएं ओर की नियम-आधारित पार्सिंग परंपरा "व्याकरणिक स्तर" पर बनी हुई है, "सटीक स्थान निर्धारण" के लक्ष्य के साथ, बदले गए संरचना के प्रति सक्रिय रूप से अनुकूलन करती है, और तेजी से "संरचनात्मक छत" तक पहुंच जाती है - यह एक व्यक्ति के समान है जिसे एक पुस्तक में एक अध्याय पृष्ठ 3, पंक्ति 5 पर होने का पता लगा है, लेकिन उस अध्याय के बारे में कुछ नहीं पता है। दाएं ओर की अर्थ निष्कर्षण परंपरा अपने कार्यक्रम स्तर को बदल देती है: "व्याकरण" से "अर्थ" तक, "मैकेनिकल मिलान" से "बुद्धिमान समझ" तक। इसका उद्देश्य अब नोड निर्देशांक की स्थिति नहीं खोजना है, बल्कि पृष्ठ सामग्री को सीधे समझना है, और इसकी क्षमता सीमाएं डीओएम परिवर्तन द्वारा निर्धारित नहीं होतीं।
यही कारण है कि नियम-आधारित पार्सिंग युग के तीन विवाद अलग-अलग समस्याएं नहीं हैं, बल्कि "व्याकरणिक मिलान" के नींव के विविध रूप हैं। जब तक डेटा निष्कर्षण तकनीक व्याकरणिक स्तर पर रहती है, चाहे नियम डिज़ाइन कितना भी जटिल किया गया हो, इस संरचनात्मक विरोधाभास को अतिक्रमित नहीं किया जा सकता। इसलिए, AI अर्थ निष्कर्षण परंपरा का उदय पुराने मार्ग पर त्वरण नहीं है, बल्कि संज्ञानात्मक स्तर पर क्रांति है, "स्थान खोजने" से "सामग्री समझने" तक। इस परंपरा के परिवर्तन के विशिष्ट यांत्रिकी और लाभ अनुभाग 1.2 में विस्तृत रूप से वर्णित किए जाएंगे।
1.2 AI परंपरा: व्याकरणिक मिलान से अर्थ के बोध तक
AI-चालित विधियां समस्याओं के प्रक्रिया को पूरी तरह से नए ढंग से देखती हैं। चित्र 1-4 चार आयामों में नियम-आधारित पार्सिंग और AI अर्थ परंपरा के बीच मूल अंतर की तुलना करता है: मुख्य समस्या, निर्भर कारक, परिवर्तन के प्रति अनुकूलन और विस्तार मोड:
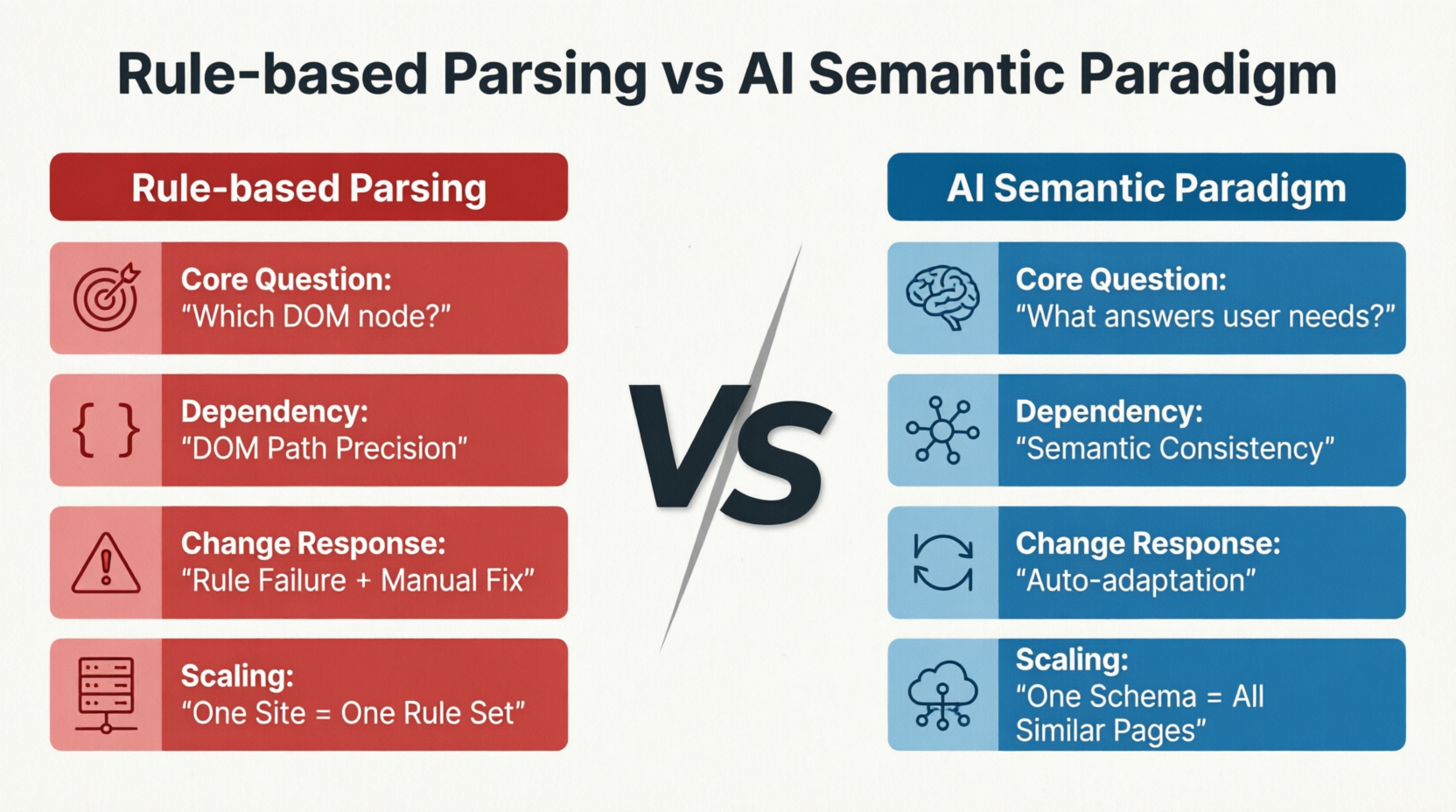
पारंपरिक विधियां "डीओएम नोड में डेटा कहां है?" के सवाल करती हैं, जबकि AI विधियां "पृष्ठ पर कौन सी सामग्री उपयोगकर्ता के लिए मुख्य जानकारी है?" के सवाल करती हैं। इस सवाल के अंतर ने सभी बाद के तकनीकी मार्गों के विचलन का निर्धारण किया: पहला डीओएम पथ की सटीकता पर निर्भर करता है, और जब पृष्ठ फिर से डिज़ाइन किया जाता है या नोड्स बदल जाते हैं, तो नियम अमान्य हो जाते हैं और हाथ से ठीक किए जाने की आवश्यकता होती है; दूसरा अपने पृष्ठ के अर
- डेटा अधिग्रहण परत (यूआरएल क्यू → वेब स्क्रैपिंग → विरोधी-स्क्रैपिंग निरीक्षण): लक्ष्य पृष्ठ के एचटीएमएल को जटिल नेटवर्क परिस्थितियों में "प्राप्त" करने के लिए जिम्मेदार। यह पाइपलाइन के सबसे ज्यादा जोखिम वाले क्षेत्र में है, जहां चित्र 2-2 में दिखाए गए 14% मुख्य बॉटलनॉक इस परत पर है।
- सामग्री प्रसंस्करण परत (सामग्री साफ करना → एलएलएम पार्सिंग → स्कीमा प्रमाणीकरण): शोर वाले कच्चे एचटीएमएल को उच्च गुणवत्ता वाले संरचित डेटा में बदलने के लिए जिम्मेदार। एक्यूरेसी बॉटलनॉक (18%) इस परत के सामग्री साफ करने चरण में मुख्य रूप से केंद्रित है।
- डेटा भंडारण परत (डेटा भंडारण): नीचे की ओर के उपभोक्ता के लिए अंतिम आउटपुट, पूरे लिंक के लगभग 5% के लिए।
इस अध्याय में हम परत 2, सामग्री प्रसंस्करण परत के तकनीकी विवरण पर केंद्रित होंगे, दिखाते हुए कि कैसे एआई अर्थग्रहण विवरण पारंपरिक नियम इंजनों के मुकाबले आधुनिक रूप से बेहतर है। परत 1 के लिए, जो डेटा के प्रसंस्करण परत में प्रवेश करने के लिए आवश्यक प्रारंभिक शर्त है, हम अगले अध्याय 3 में विशेष विश्लेषण और व्यावहारिक समाधान चर्चा करेंगे।
2.1 एआई डेटा निकास पाइपलाइन
प्रसंस्करण परत में प्रवेश करने से पहले, चित्र 2-1 के माध्यम से पूरे पाइपलाइन का एक पक्ष दृष्टिकोण लें ताकि यूआरएल क्यू से डेटा भंडारण तक पूरा मार्ग और प्रत्येक चरण में वास्तविक ट्रैफिक वितरण की समझ प्राप्त करें। यह अध्याय के लिए एक समीक्षा है और अगले अध्याय 3 में बॉटलनॉक के समाधान के लिए आधार तैयार करता है।

यूआरएल क्यू पाइपलाइन का प्रवेश बिंदु है, जो छापे जाने वाले यूआरएल की सूची को प्रबंधित करता है और मांग की ritm को नियंत्रित करता है। चित्र 2-1 में दिखाए गए अनुसार, यूआरएल योजना चरण में लगभग 32% मांग अग्रिम रूप से कैप्चा जोखिम के साथ चिह्नित कर दिए गए हैं, जबकि 68% सीधे सामान्य मांग शुरू कर सकते हैं। वेब स्क्रैपिंग चरण एचटीएमएल मांग शुरू करने या ब्राउजर रेंडरिंग चलाने के लिए जिम्मेदार है ताकि पृष्ठ के कच्चा सामग्री प्राप्त कर सके। इस बिंदु पर, 12% मांग कैप्चा द्वारा सीधे अवरुद्ध कर दी जाती है, और 80% बाद के चरणों में सुचारू रूप से प्रवेश कर सकते हैं।
प्रारंभिक स्क्रैपिंग के बाद, मांग विरोधी-स्क्रैपिंग निरीक्षण चरण में प्रवेश करती है। आधुनिक विरोधी-स्क्रैपिंग प्रणालियां चार आयामों से संकेतों का समान रूप से विश्लेषण करती हैं: आईपी प्रतिष्ठा, टीएलएस फिंगरप्रिंट, ब्राउजर विशेषताएं, और व्यवहार पैटर्न, बहु-स्तरीय अंतर-प्रमाणीकरण करती हैं। चित्र 2-1 दिखाता है कि विरोधी-स्क्रैपिंग निरीक्षण चरण में लगभग 10% ट्रैफिक को स्वचालित मांग के रूप में पहचाना जाता है और अवरुद्ध कर दिया जाता है, और 20% के लिए आईपी प्रॉक्सी पूल और टीएलएस फिंगरप्रिंट झूठ बोलने पर निर्भर करना पड़ता है। यह पूरे पाइपलाइन में सबसे अनिश्चित नोड है। जब कोई कैप्चा ट्रिगर होता है और निपटाया नहीं जाता, तो बाद के सभी चरणों के गणना संसाधन अक्रिय हो जाते हैं।
विरोधी-स्क्रैपिंग निरीक्षण पारित करने के बाद, कच्चा एचटीएमएल सामग्री प्राप्त होता है। एक सामान्य समाचार पृष्ठ के कच्चा एचटीएमएल 2MB से अधिक हो सकता है, जो ओपनएआई के टिकटॉकन टोकनाइजर के साथ प्रसंस्करण के बाद 300,000 से 500,000 टोकन तक पहुंच जाता है, जिसमें नेविगेशन मेनू, एम्बेडेड सीएसएस, बेस 64 एनकोडेड ट्रैकिंग पिक्सेल, और संपीड़ित जावास्क्रिप्ट शामिल होते हैं। इसलिए, सामग्री साफ करना आवश्यक चरण है। चित्र 2-1 दिखाता है कि एचटीएमएल से मार्कडाउन रूपांतरण इस चरण में काम के 50% के लिए है, और डीओएम सरलीकरण और शोर हटाना 30% के लिए है। इन दो के संयोजन से कच्चा एचटीएमएल उच्च घनत्व वाले अर्थग्रहण पाठ में संकुचित कर दिया जाता है, जो एलएलएम की प्रभावी गणना क्षमता को शोर के बजाय जानकारी पर केंद्रित करता है।
साफ किया गया पाठ एलएलएम पार्सिंग चरण में प्रवेश करता है, जहां मॉडल एक पूर्व निर्धारित स्कीमा के अनुसार पाठ से संरचित क्षेत्रों को निकालता है। चित्र 2-1 इस चरण के साथ अगले स्कीमा प्रमाणीकरण को जोड़ता है, 94.7% की सटीकता दर दिखाता है। इसका मतलब है कि लगभग 1 में 20 निकास फील्ड पूर्णता या फॉर्मेट संगतता जांचों को पास नहीं कर सकते। सफल आउटपुट संरचित जेसॉन डेटा बन जाते हैं, जो नीचे के व्यावसायिक उपभोग के लिए पोस्टग्रेसक्यूएल या मोंगोडीबी जैसी प्रणालियों में संग्रहीत कर दिए जाते हैं।
इस चरण के तकनीकी वाहक, प्रदर्शन संकेतक और इंजीनियरिंग बॉटलनॉक को अधिक स्पष्ट रूप से तोड़ने के लिए, चित्र 2-2 एक डैशबोर्ड के रूप में एक व्यापक दृश्य प्रस्तुत करता है:
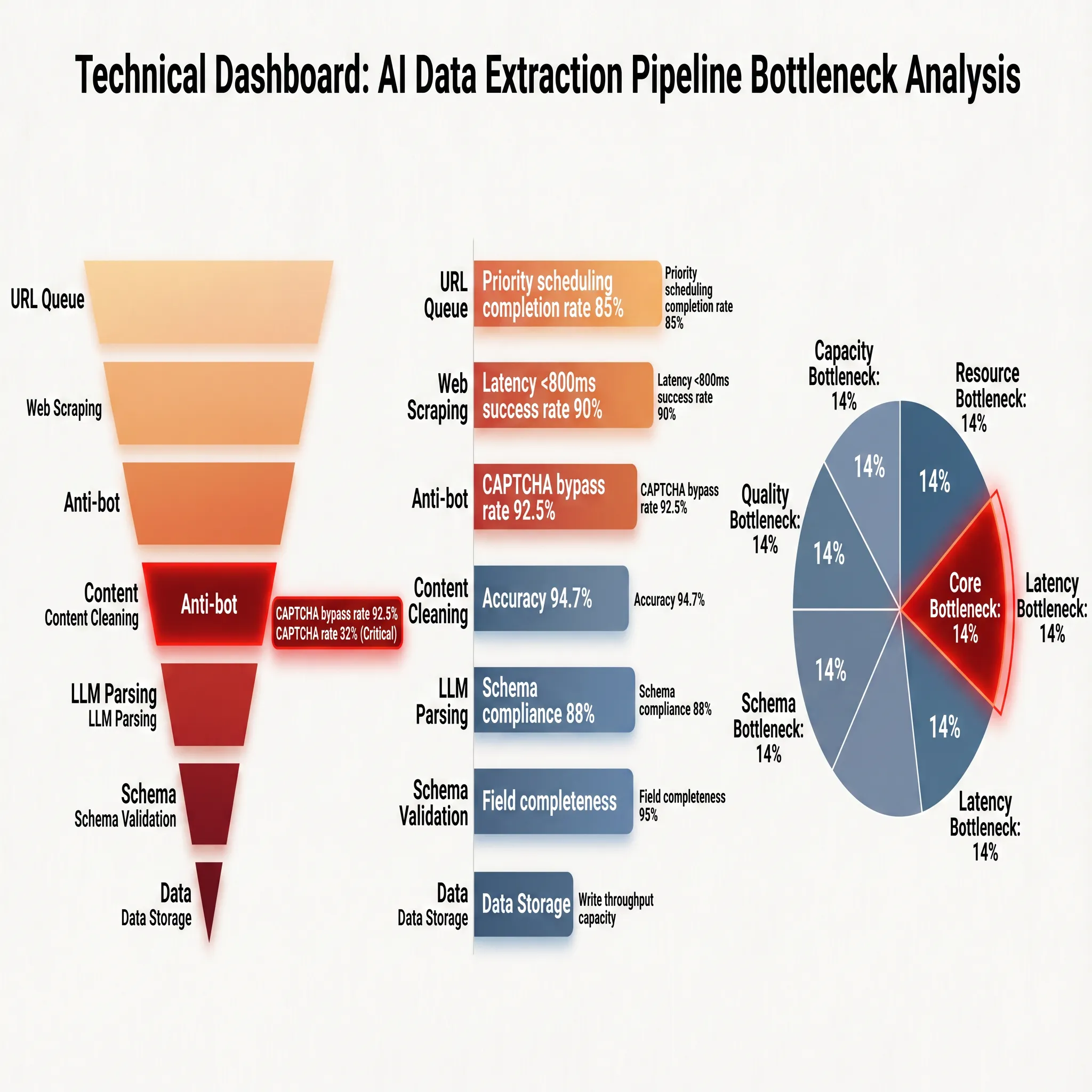
चित्र के दाईं ओर प्रदर्शित प्रदर्शन संकेतक वास्तविक संचालन आधार रेखा दर्शाते हैं: यूआरएल क्यू की प्राथमिकता योजना प्राप्ति दर 85% है, जिसका अर्थ है लगभग 15% कार्य योजना प्रतिस्पर्धा के कारण देरी हो रही है या गिरावट आई है; वेब स्क्रैपिंग की सफलता दर 90% है, 800 मिलीसेकंड के अंतराल के भीतर, जो नेटवर्क और रेंडरिंग संसाधनों की सीमाओं को स्पष्ट रूप से दिखाता है; विरोधी-स्क्रैपिंग तंत्र की सटीकता दर 94.7% है, जिसका अर्थ है लगभग 5 प्रत्येक 100 मांग में अवरुद्ध हो जाते हैं या सत्यापन ट्रिगर हो जाते हैं। सामग्री साफ करने के बाद, स्कीमा संगतता दर 88% और फील्ड पूर्णता 95% है। इन दो संकेतकों के संयोजन से डेटा गुणवत्ता की शुरुआत की सीमा निर्धारित की जाती है, जहां लगभग 12% पृष्ठों में मुख्य सामग्री पहचान में विचलन होता है और 5% आवश्यक क्षेत्र गायब होते हैं।
चित्र 2-2 के नीचे, बॉटलनॉक वितरण सीधे दिखाया गया है: मुख्य बॉटलनॉक विरोधी-स्क्रैपिंग तंत्र (14%) पर है, सटीकता बॉटलनॉक सामग्री साफ करने (18%) पर है, क्षमता बॉटलनॉक यूआरएल योजना और वेब स्क्रैपिंग चरणों में विशेष रूप से हैं, और लागत बॉटलनॉक स्कीमा प्रमाणीकरण के गुणवत्ता जांच लागत पर है। ये आंकड़े ऊपर के विश्लेषण के साथ बहुत अधिक संगत हैं। विरोधी-स्क्रैपिंग निरीक्षण पूरे श्रृंखला का "गले" है; जब एक विरोधी-स्क्रैपिंग रणनीति ट्रिगर होती है और इसे प्रभावी ढंग से बचा नहीं जा सकता, तो कोई भी बाद के चरणों की गणना क्षमता असफल हो जाती है क्योंकि इनपुट डेटा की कमी के कारण। यह पारंपरिक नियम-आधारित क्रॉलर की मुख्य समस्या के साथ मेल खाता है: एआई अर्थग्रहण निकास के युग में, सटीकता के छत काफी बढ़ गई है, लेकिन डेटा प्राप्ति के लिए "प्रवेश योग्यता" इंजीनियरिंग कार्यान्वयन के लिए पहला बाधा बना रहता है। इस कारण से, अध्याय 3 में हम विरोधी-स्क्रैपिंग लड़ाई तकनीक और उपायों के विकास पर विशेष रूप से चर्चा करेंगे।
2.2 सामग्री साफ करना: शोर एचटीएमएल से एलएलएम-पठनीय पाठ
कच्चे एचटीएमएल को एलएलएम के लिए संरचित निकास के लिए सीधे खिलाना इंजीनियरिंग में बहुत असमायोजित है। एलएलएम के ध्यान योजना को डीओएम बॉयलरप्लेट कोड, जैसे गहरे एनवाईटी टैग के नेस्टिंग, एम्बेडेड सीएसएस स्टाइल, ट्रैकिंग स्क्रिप्ट, नेविगेशन मेनू और फूटर लिंक से भटका सकता है। इन तत्वों के पास शून्य अर्थग्रहण मूल्य है और टोकन उपभोग को बहुत बढ़ा देते हैं। हजारों पृष्ठ प्रतिदिन प्रसंस्करण के बड़े पैमाने पर अवसरों में, यह बर्बादी जल्दी वित्तीय अस्थिरता बन जाती है। एक सामान्य समाचार पृष्ठ के एचटीएमएल के संगठन इस समस्या की गंभीरता को सीधे दिखाता है। चित्र 2-3 कच्चे एचटीएमएल में विभिन्न शोर के लिए प्रभावी जानकारी के अनुपात को एक वृत्ताकार चित्र में प्रस्तुत करता है:
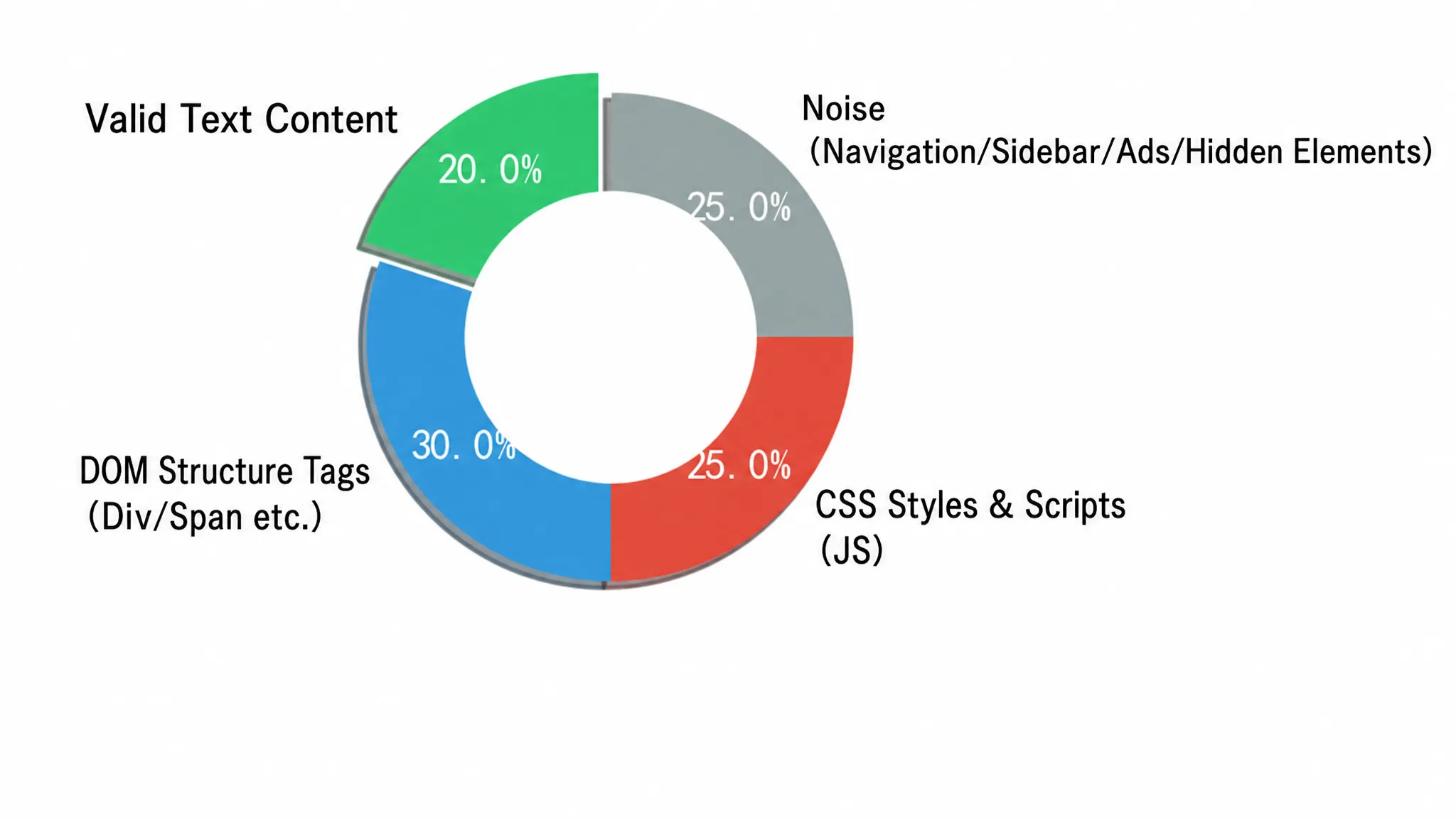
वृत्ताकार चित्र कच्चे एचटीएमएल को चार क्षेत्रों में विभाजित करता है। हरे भाग (45%) प्रभावी शरीर सामग्री है, जिसमें पाठ और चित्र शामिल हैं - यह एलएलएम के लिए वास्तविक संकेत है। पीला भाग (20%) संरचनात्मक और शैली शोर है, अर्थात् <script>, <style>, <svg> टैग; नीला भाग (20%) नेविगेशन और साइडबार है; लाल भाग (15%) विज्ञापन और ट्रैकर हैं। शोर के तीन हिस्से मिलकर 55% से अधिक हैं, जिसका अर्थ है कि एलएलएम को भेजे गए टोकन के आधे से अधिक शून्य अर्थग्रहण मूल्य के बिना बिल किए जाते हैं।
इस "संकेत शोर में डूब गया" वास्तविकता ने एक तीन-स्तरीय प्रगतिशील साफ करने की रणनीति के उद्भव के लिए कारण बना। चित्र 2-4 एचटीएमएल से एलएलएम-पठनीय पाठ तक पूरा प्रसंस्करण श्रृंखला दिखाता है:
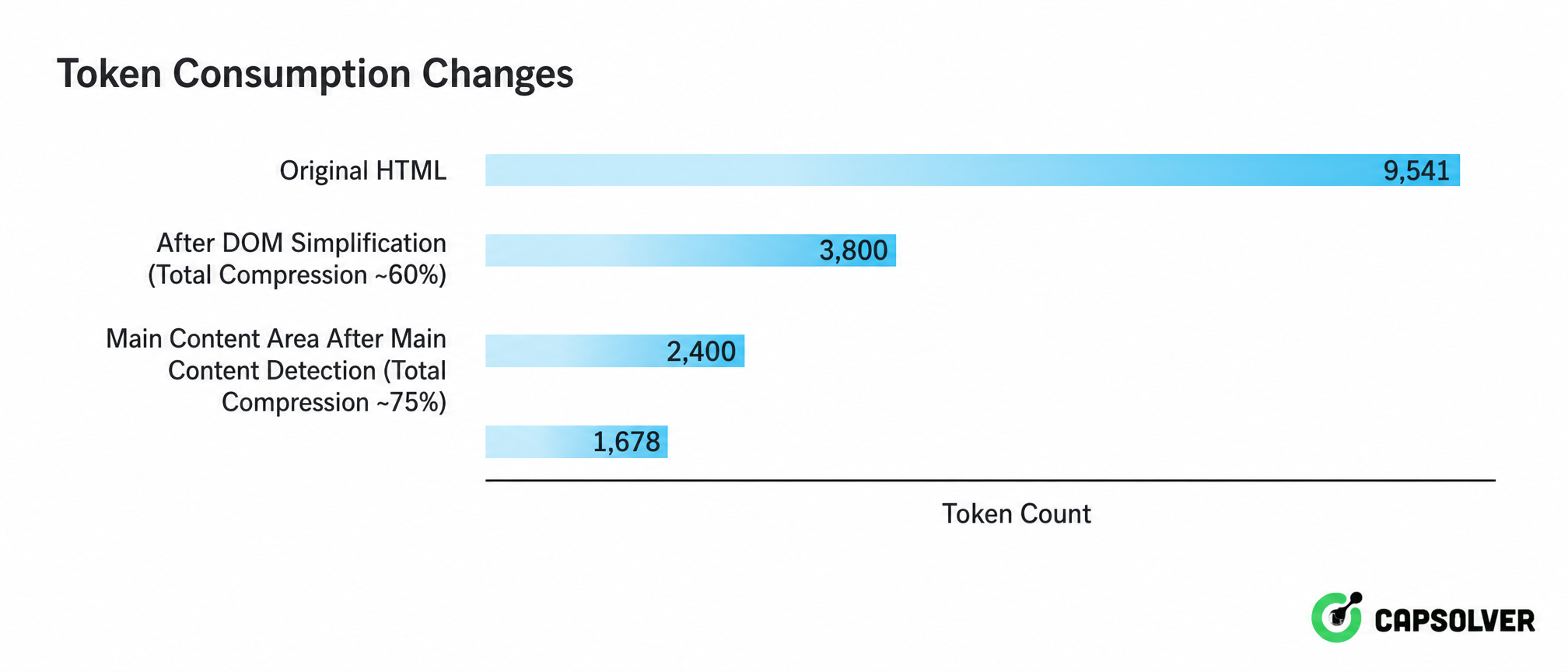
दृष्टिकोण से, तीन स्तर के साफ करने ने 9,541 से 1,678 टोकन को संकुचित कर दिया, जो मूल एचटीएमएल के केवल 18% है। इस संकुचन अनुपात का अर्थ है कि बड़े पैमाने पर प्रसंस्करण में एपीआई कॉल लागत कम हो जाती है, जो मूल के एक पांचवां हिस्से से कम हो जाती है, और सेमैंटिक संदर्भ फ़िल्टरिंग द्वारा प्राप्त 10-100 गुना संदर्भ कमी एलएलएम के ध्यान को संकेत पर बजाय शोर पर केंद्रित करती है। यह एआई डेटा निकास इंजीनियरिंग के लिए अनिवार्य भाग है।
2.3 एलएलएम पार्सिंग और स्कीमा प्रमाणीकरण: पाठ से संरचित डेटा तक
सामग्री साफ करने के मार्कडाउन पाठ, एलएलएम पार्सिंग चरण में प्रवेश करता है, जिसका उद्देश्य एक पूर्व निर्धारित स्कीमा के अनुरूप संरचित जेसॉन उत्पादन करना है। परिस्थिति के आधार पर, तीन प्रमुख तकनीकी मार्ग उपलब्ध हैं। पथ एक सामान्य बड़े मॉडल जैसे GPT-4o का उपयोग करता है, जिसके पास 128K संदर्भ खिड़की है, जो सबसे तेज अनुमान गति और सबसे अच्छा गुणवत्ता स्कोर प्रदान करता है, लेकिन मध्यम लागत, जो कम क्षेत्रों और सरल प्रारूप के साथ तेजी से प्रोटोटाइप परीक्षण के लिए उपयुक्त है। पथ दो स्कीमा-पहले विशेष मॉडल जैसे Schematron-3B का उपयोग करता है, जो छोटे सर्वर-पक्ष डेप्लॉयमेंट में चलता है, बीच-उच्च गति और जनरल बड़े मॉडल के बराबर 0.12 बिंदु तक गुणवत्ता स्कोर कम हो जाता है, जबकि लागत कम कर दी जाती है, जो बड़े पैमाने पर उत्पादन परिदृश्य के लिए अद्वितीय विकल्प है। पथ तीन बहुमाध्यमिक भाषा मॉडल का उपयोग करके हाइब्रिड व्यवस्था बनाता है, जो स्क्रीनशॉट और एचटीएमएल के साथ समानांतर विश्लेषण करता है, जो अत्यधिक गतिशील अंतरक्रिया पृष्ठों जैसे असीमित स्क्रॉलिंग और मॉडल पॉप-अप के साथ निपट सकता है, लेकिन मध्यम गति, उच्च लागत और तुलनात्मक रूप से निम्नतम गुणवत्ता स्कोर के साथ, जो जटिल अंतरक्रिया परिदृश्य के लिए लगभग एकमात्र व्यावहारिक रास्ता बन जाता है। चयनित मार्ग के आधार पर, शुरू में उत्पादित संरचित जेसॉन को अंतिम डेटा के रूप में आउटपुट करने से पहले तीन स्तरों के स्कीमा प्रमाणीकरण के माध्यम से गुजरना होता है - फील्ड पूर्णता, प्रकार संगतता और फॉर्मेट संगतता। चित्र 2-5 इन तीन मार्गों और स्कीमा प्रमाणीकरण के बीच पूर्ण संबंध को प्रक्रिया श्रृंखला और मुख्य मापदंडों के दृष्टिकोण से दिखाता है।

मैट्रिक्स स्पष्ट रूप से एक विपरीत लेकिन महत्वपूर्ण इंजीनियरिंग तथ्य दिखाता है: सबसे बड़ा मॉडल हमेशा उत्तम समाधान नहीं होता। Schematron-3B, जिसमें केवल 3B पैरामीटर हैं, बड़े मॉडल जैसे GPT-4o के गुणवत्ता स्कोर के पास पहुंच जाता है, जबकि लागत में बहुत अधिक कमी आ जाती है। जब प्रसंस्करण एक दिन में एक मिलियन पृष्ठ तक पहुंच जाता है, तो इसकी अनुमान लागत बड़े सामान्य मॉडल की तुलना में लगभग 1/80 हो जाती है, जो "तकनीकी रूप से संभव" से "व्यावसायिक रूप से लाभदायक" तक के एक महत्वपूर्ण मोड़ है। हालांकि Webscraper+MLLM की लागत सबसे अधिक है और गुणवत्ता स्कोर तुलनात्मक रूप से कम है, यह अत्यधिक गतिशील अंतरक्रिया परिदृश्य के लिए लगभग एकमात्र व्यावहारिक रास्ता है, जो एक सिद्धांत की पुष्टि करता है: तकनीकी चयन की सहीता परिदृश्य की सीमा पर निर्भर करती है, न कि निरपेक्ष मापदंड मूल्यों पर।
स्कीमा प्रमाणीकरण डेटा उपयोगिता के अंतिम चेकपॉइंट है। इनमें से फॉर्मेट संगतता जांच विशेष रूप से तारीखों, मुद्राओं और फोन नंबरों जैसे क्षेत्रों के लिए आवश्यक है। पारंपरिक नियम आधारित समाधान अलग-अलग इनपुट विकल्पों के लिए हर बार नियम लिखने की आवश्यकता होती है, जबकि एलएलएम के आंतरिक फॉर्मेट रूपांतरण क्षमता शून्य नियम के साथ मानकीकरण प्राप्त कर सकती है। शुद्धता के मामले में, AXE फ्रेमवर्क ने SWDE डेटासेट पर 88.1% की F1 स्कोर हासिल की। वास्तविक उत्पादन परिस्थितियों में अनुभव दिखाता है कि 90% स्वचालित निकास शुद्धता के साथ तेजी से हस्तचालित समीक्षा मार्ग के साथ एक अधिक व्यावहारिक इंजीनियरिंग रणनीति है, जो लागत के दस गुना बढ़ाए बिना 100% सैद्धांतिक शुद्धता के लिए बर्बाद हो रहा है। इस व्यापार रेखा की स्थिति प्रत्येक टीम के "डेटा निरंतरता" और "बजट छत" के विशिष्ट गणना पर निर्भर करती है, लेकिन स्पष्ट रूप से मध्यम शुद्धता अधिक व्यावसायिक रूप से लाभदायक है।
तृतीय: एआई डेटा निकास के तीन द्वार: विरोधी-स्क्रैपिंग, कैप्चा अपघटन और लागत नियंत्रण
अध्याय 2 में, हमने सामग्री प्रसंस्करण परत के तकनीकी श्रृंखला की विस्तृत खोज की - एचटीएमएल साफ करने से स्कीमा प्रमाणीकरण तक - दिखाया कि एआई अर्थग्रहण निकास ने शुद्धता के छत को बहुत अधिक बढ़ा दिया है। हालांकि, अध्याय 2.1 के चित्र 2-2 में खुलासा किया गया है कि पूरे पाइपलाइन का मुख्य बॉटलनॉक (14%) प्रसंस्करण परत में नहीं है, बल्कि पूर्व में डेटा अधिग्रहण परत में है। यदि एचटीएमएल प्राप्त नहीं किया जा सकता है, तो सभी बाद के बुद्धिमान पार्सिंग वायु में बने रहते हैं। इस अध्याय में हम "प्रवेश योग्यता" के लिए निर्णायक चरण के सीधे सामना करेंगे।
3.1 डेटा अधिग्रहण परत: पाइपलाइन का पहला महान बॉटलनॉक
अगर सामग्री साफ करना और एलएलएम पार्सिंग "कैसे डेटा प्रसंस्करण करें" के समस्या को हल करता है, तो डेटा अधिग्रहण परत एक अधिक मूल और जटिल समस्या का सामना करता है: "क्या डेटा प्राप्त किया जा सकता है?" यूआरएल क्यू से सामान्य पहुंच तक के मार्ग में, विरोधी-स्क्रैपिंग प्रणाली पूरे पाइपलाइन में सबसे अनियंत्रित चर है।
आधुनिक विरोधी-स्क्रैपिंग प्रणालियां चार-स्तरीय रक्षा-गहराई वाली व्यवस्था में विकसित हो गई हैं, जो प्रत्येक मांग को नेटवर्क, परिवहन, ब्राउजर और व्यवहार स्तरों से समान रूप से विश्लेषण करती हैं। चित्र 3-1 क्षैतिज रूप से इस चार-स्तरीय निरीक्षण व्यवस्था का विस्तार करता है।
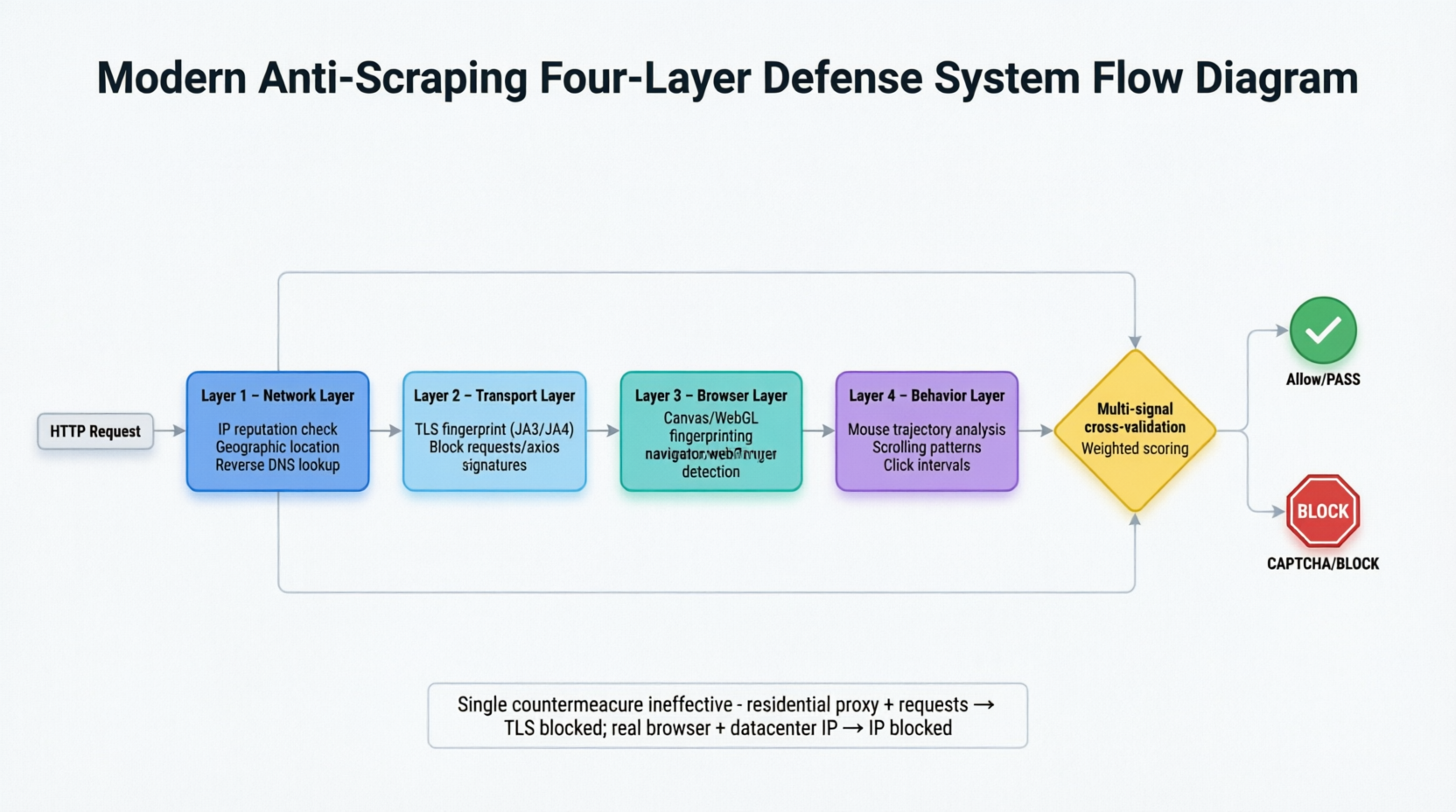
मांग चार स्तरीय फ़िल्टरिंग के माध्यम से अनुक्रम में गुजरती है। नेटवर्क स्तर निर्धारित संकेतों की जांच करता है जैसे आईपी स्थान, क्या यह डेटा केंद्र के साथ संबंधित है, और विपरीत डीएनएस की कमी; परिवहन स्तर टीएलएस फिंगरप्रिंट की तुलना करता है; ब्राउजर स्तर ऑटोमेशन ट्रेस जैसे हेडलेस मोड में navigator.webdriver गुण, कैनवास फिंगरप्रिंट, और वेबजीएल रेंडरर जानकारी का पता लगाता है; व्यवहार स्तर मानव व्यवहार विशेषताओं का विश्लेषण करता है जो ठीक से समायोजित करना मुश्किल है, जैसे माउस बैठक, स्क्रॉल पैटर्न और क्लिक अंतराल। चार स्तरीय संकेतों का एक भारित स्कोर बनाने के लिए एक दूसरे के साथ अंतर-प्रमाणीकरण करता है, जिससे कोई भी एक स्तर के धोखा बर्दाश्त नहीं कर सकता। जब प्रणाली ट्रैफिक की प्रकृति को स्पष्ट रूप से निर्धारित नहीं कर सकती, तो अंतिम रक्षा - कैप्चा - ट्रिगर हो जाता है।
जब सभी गैर-सक्रिय निरीक्षण विधियां ट्रैफिक की प्रकृति को स्पष्ट रूप से निर्धारित नहीं कर सकतीं, तो प्रणाली कैप्चा खोल देती है, जो विरोधी-स्क्रैपिंग प्रणालियों के अंतिम रक्षा के रूप में कार्य करती है। आधुनिक कैप्चा अब सरल विकृत अक्षर पहचान नहीं हैं बल्कि जोखिम स्कोर पर आधारित बुद्धिमान चुनौति प्रणालियां हैं। टेबल 3-1 वर्तमान में उपलब्ध चार प्रमुख कैप्चा प्रणालियों की तुलना करता है।
| CAPTCHA प्रणाली | अंतरक्रिया रूप | निर्णय यंत्र | AI अनुकूलन क्षमता/विशेषताएं | क्रॉलर्स के लिए खतरा |
|---|---|---|---|---|
| reCAPTCHA v2 | चेकबॉक्स क्लिक करें / छवि पहचान | उपयोगकर्ता अंतरक्रिया + AI व्यवहार अंकन | सटीकता 85%–100% | उच्च, लेकिन अनुकूलित किया जा सकता है |
| reCAPTCHA v3 | पूरी तरह से अदृश्य, कोई दृश्य चुनौती नहीं | पृष्ठभूमि लगातार व्यवहार अंकन | सीधे "अनुकूलित किया जा सकता है", व्यवहार सिमुलेशन पर निर्भर करता है | अत्यधिक उच्च, अदृश्य अंकन |
| Cloudflare Turnstile | ब्राउज़र वातावरण सामंजस्य जांच | गैर-अंतरक्रिया सत्यापन | ब्राउज़र की अखंडता की जांच करता है | उच्च, reCAPTCHA के स्थान पर |
| AWS WAF CAPTCHA | जोखिम-आधारित, विनियमित चुनौतियां | AWS एकीकृत वातावरण निर्णय | बाद में वातावरण विशिष्ट | मध्यम, विशिष्ट पारिस्थितिक तंत्र |
CAPTCHA पाइपलाइन की अंतिम रक्षा श्रृंखला में स्थित है। जब एक चुनौती द्वारा ट्रिगर किया जाता है और इसका समाधान नहीं किया जाता है, तो बाद के सभी सामग्री साफ करने और LLM पार्सिंग चरण पूर्णतः अकार्यक्षम हो जाते हैं। यह पाइपलाइन के "प्रथम मृत्यु बिंदु" के रूप में डेटा अधिग्रहण परत के नामकरण का मूल कारण है: प्रतिक्रॉलर तकनीक डेटा के प्रवेश को निर्धारित करती है, और यह लक्ष्य वेबसाइट द्वारा गहराई से नियंत्रित एक चर है। जब एआई अर्थग्रहण में डेटा प्रसंस्करण की दक्षता में महत्वपूर्ण सुधार हुआ है, तो अधिग्रहण परत पर आक्रमण और रक्षा इंजीनियरिंग सफलता के क्रीड़ा के महत्वपूर्ण बिंदु रहे हैं।
3.2 पहेली पूरी करें: आधुनिक CAPTCHA अपराध के तकनीकी मार्ग
चार-स्तरीय प्रतिक्रॉलर रक्षा-गहराई प्रणाली में, CAPTCHA अनुकूलित हल करने के लिए अंतिम और सबसे कठिन बाधा है। CAPTCHA अनुकूलन समाधान जैसे CapSolver पाइपलाइन में "फ्यूज के समान भूमिका" निभाते हैं - यह "प्रतिक्रॉलर निर्णय" और "सामान्य पहुंच" के बीच एम्बेडेड होता है। जब एक क्रॉलर के सामने reCAPTCHA v2/v3, Cloudflare Turnstile या AWS WAF CAPTCHA जैसी चुनौतियां होती हैं, तो यह सेकंड में पहचान करता है और एक वैध टोकन वापस करता है, डेटा प्रवाह बहाल करता है। चित्र 3-2 CapSolver के उदाहरण के रूप में पाइपलाइन में इस प्रकार के समाधान के हस्तक्षेप स्थिति और प्रक्रिया तर्क को स्पष्ट करता है:
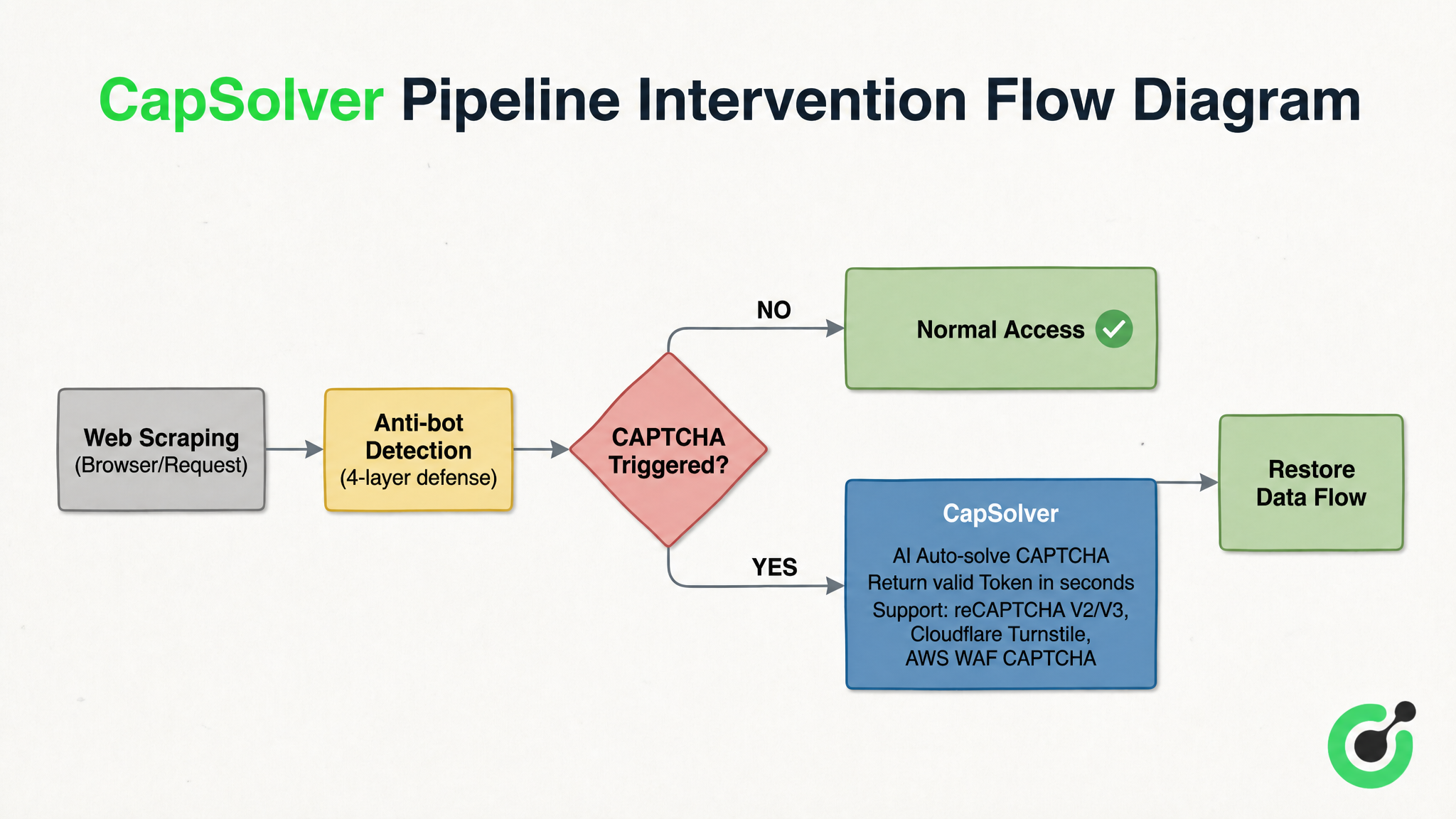
चित्र 3-2 से, इस प्रकार के समाधान के कार्य तंत्र स्पष्ट है: जब खोज मांग चार-स्तरीय रक्षा प्रणाली द्वारा निर्देशित होती है, तो CAPTCHA ट्रिगर नहीं होता है, तो यह सीधे सामान्य पहुंच के लिए जारी कर दिया जाता है; जब एक CAPTCHA चुनौती ट्रिगर होती है, तो सीधे अनुकूलन सेवा हस्तक्षेप करती है और CAPTCHA प्रकार और पैरामीटर के साथ जमा करती है। AI सेकंड में पहचान करता है और एक वैध टोकन वापस करता है, और डेटा प्रवाह ब्रेकपॉइंट पर पुनः संयोजित हो जाता है। यह कोई भी मौजूदा घटक को बदलता नहीं है, बल्कि विद्युत प्रणाली में एक फ्यूज के समान कार्य करता है, जब असामान्यता के समय पूरी प्रणाली के टूटने से बचता है।
CapSolver इस क्षेत्र में प्रतिनिधि समाधानों में से एक है। 2Captcha और Anti-Captcha जैसी समान सेवाएं भी समान क्षमताएं प्रदान करती हैं, और विकासकर्ता लेटेंसी आवश्यकताओं, समर्थित प्रकारों और मूल्य नीतियों के आधार पर सबसे उपयुक्त विक्रेता का चयन कर सकते हैं। इस एम्बेडिंग ने डेटा अधिग्रहण परत के विश्वसनीयता मॉडल को बदल दिया है। चित्र 3-3 CapSolver के मामले में अध्ययन करके पाइपलाइन में अनुकूलन समाधान पेश करने के बाद आवश्यक सूचकांकों में परिवर्तन की मात्रा को संख्यात्मक रूप से दर्शाया गया है:
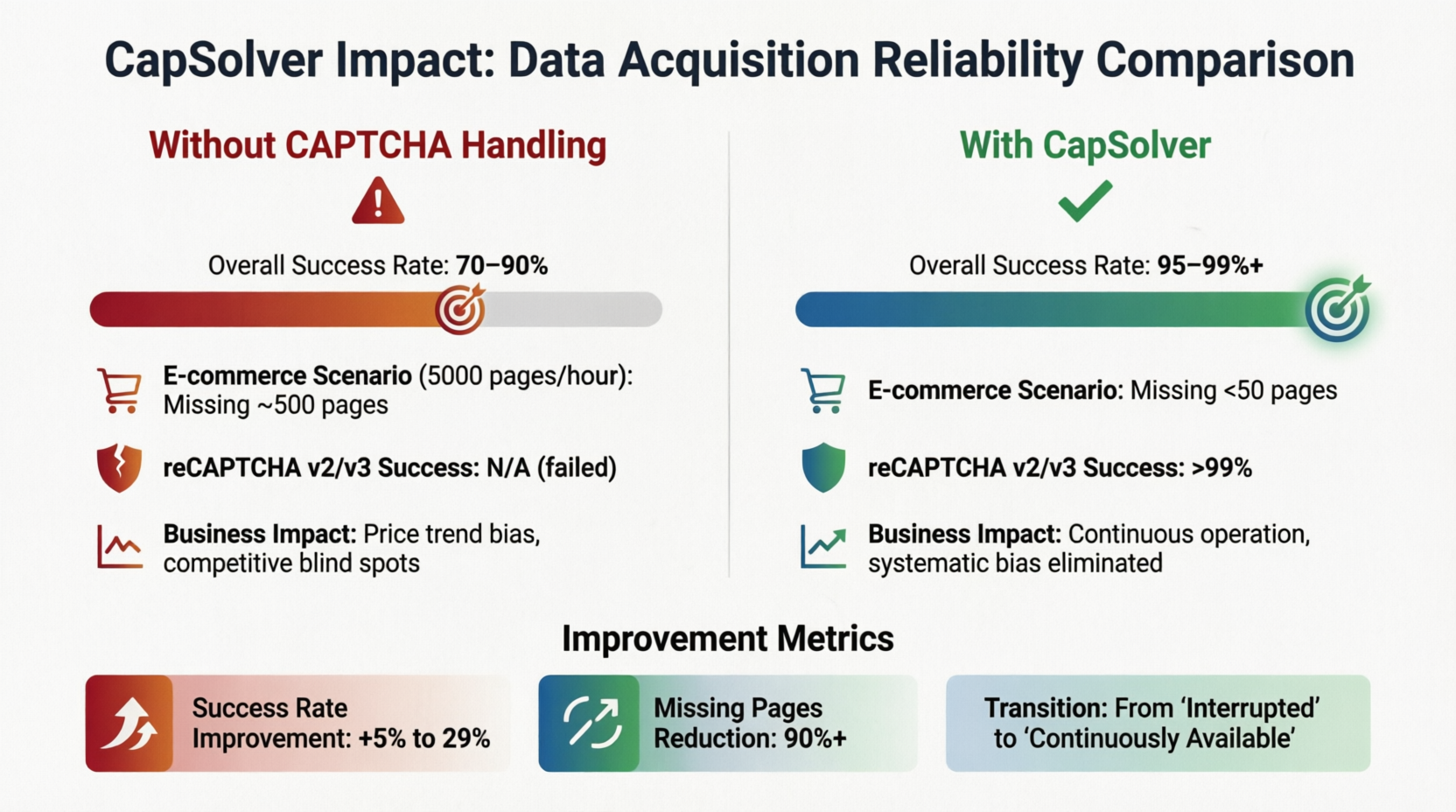
अनुकूलन समाधान के बिना, समग्र सफलता दर 70%–90% के बीच उतार-चढ़ाव करती है। जब लक्ष्य साइट CAPTCHA लगाती है, तो डेटा प्रवाह रोके जाने की संभावना 10%–30% होती है। एक ई-कॉमर्स मूल्य निगर्मण प्रणाली में जो घंटे में 5,000 उत्पाद पृष्ठों के अधिग्रहण करती है, यहां आधारभूत सफलता दर 90% होने पर प्रति घंटा लगभग 500 पृष्ठ के डेटा खो जाते हैं, जो मूल्य तर्क विश्लेषण में दिशा विचलन और प्रतिद्वंद्वी रणनीति में प्रणालीगत अंधापन के लिए पर्याप्त होता है। हालांकि, अनुकूलन समाधान पेश करने के बाद, सफलता दर 95%–99% तक बढ़ जाती है, और लुप्त पृष्ठों की संख्या 50 तक कम हो जाती है। reCAPTCHA v2/v3 के लिए अनुकूलन सफलता दर सही रूप से सेट करने पर 99% से अधिक होती है। नीचे कार्ड उन सुधारों के सारांश के साथ है: सफलता दर में 5%–29% वृद्धि, और लुप्त पृष्ठों में 90% से अधिक कमी। "लगातारता व्यापार मूल्य है" बड़े पैमाने पर परिस्थितियों में एक नारा नहीं है, बल्कि इन संख्याओं द्वारा पुष्टि की गई इंजीनियरिंग अभ्यास है।
AI बेंचमार्क परीक्षण प्लेटफॉर्म और LLM शिक्षण डेटा संग्रह परिदृश्य भी इस चुनौती का सामना करते हैं: अनुसंधानकर्ता लगातार विविध डेटा के अधिग्रहण की आवश्यकता होती है, और इस डेटा के आधार पर वेबसाइटें अक्सर reCAPTCHA का उपयोग ऑटोमेटेड पहुंच को रोकने के लिए करती हैं, जो एक विरोधाभास बन जाता है जहां "AI अनुसंधान टीमें अपने अध्ययन कर रहे प्रौद्योगिकी द्वारा बाधा डाली जाती हैं।" CAPTCHA अनुकूलन सेवाएं इन चुनौतियों के समाधान के लिए एक प्रोग्रामेटिक तरीका प्रदान करती हैं, डेटा संग्रह की अविच्छिन्नता सुनिश्चित करती हैं और पूर्ण बेंचमार्क परीक्षण परिणाम प्रदान करती हैं।
एक एकीकरण स्तर पर, ऐसे समाधान ब्राउज़र ऑटोमेशन फ्रेमवर्क, प्रॉक्सी नेटवर्क सेवाओं और कम कोड ऑटोमेशन प्लेटफॉर्म के साथ सहयोग कर सकते हैं। विकासकर्ता केवल CAPTCHA प्रकार और पैरामीटर को API पर जमा करते हैं, और प्रणाली सेकंड में एक टोकन वापस करती है। n8n जैसे प्लेटफॉर्म विशेष नोड प्रदान करते हैं, जिससे व्यापार व्यक्ति को कोड लिखे बिना कार्यप्रवाह में CAPTCHA अनुकूलन सेट करने में सक्षम होते हैं। विकासकर्ता व्यापार तर्क और स्कीमा डिज़ाइन पर ध्यान केंद्रित कर सकते हैं, जबकि प्रतिक्रॉलर संघर्ष को विशेषज्ञ उपकरणों के लिए छोड़ दिया जाता है।
आर्किटेक्चर के दृष्टिकोण से, CAPTCHA अनुकूलन समाधान कोई भी मौजूदा घटक को बदलते नहीं हैं, बल्कि पूरे पाइपलाइन के प्रवेश बिंदु के लिए "उपलब्धता गारंटी" की एक परत प्रदान करते हैं। जब CAPTCHA अनुकूलन सेकंड में स्वचालित रूप से पूरा हो जाता है, तो डेटा अधिग्रहण "अस्थायी अंधापन" से "लगातार डेटा आपूर्ति" में बदल जाता है, जो पूरे AI डेटा संरचित निष्कर्षण श्रृंखला के स्थिर संचालन के लिए आवश्यकता है।
3.3 सटीकता और लागत: इंजीनियरिंग कार्यान्वयन में अंतिम व्याज
AI डेटा संरचित निष्कर्षण को उत्पादन वातावरण में ले जाते समय, अंतिम निर्णायक चर आमतौर पर "क्या सटीकता पर्याप्त है?" नहीं होता है, बल्कि "क्या लागत सहनीय है?" होता है। टोकन उपभोग इस समस्या के केंद्र में है: एक मध्यम जटिलता वाला उत्पाद पृष्ठ, चाहे साफ कर दिया गया हो, लगभग 8,000 से 15,000 टोकन खपत कर सकता है। मौजूदा मुख्य मॉडल API शुल्क के आधार पर, प्रति निष्कर्षण लागत $0.001 से $0.01 के बीच होती है। यह प्रोटोटाइप चरण में लगभग अनावश्यक है, लेकिन जब निष्कर्षण क्षमता दिन में लाखों पृष्ठों तक बढ़ जाती है, तो मासिक लागत दस हजार डॉलर तक पहुंच जाती है, जिस स्थिति में लागत नियंत्रण अब एक अनुकूलन विषय नहीं है, बल्कि एक प्रवेश आवश्यकता है। वर्तमान में उद्योग में लागत कम करने के तीन समानांतर मार्ग हैं। चित्र 3-4 इनकी स्थिति और पूरे पार्सिंग श्रृंखला में सहयोग के संबंध को दर्शाता है:
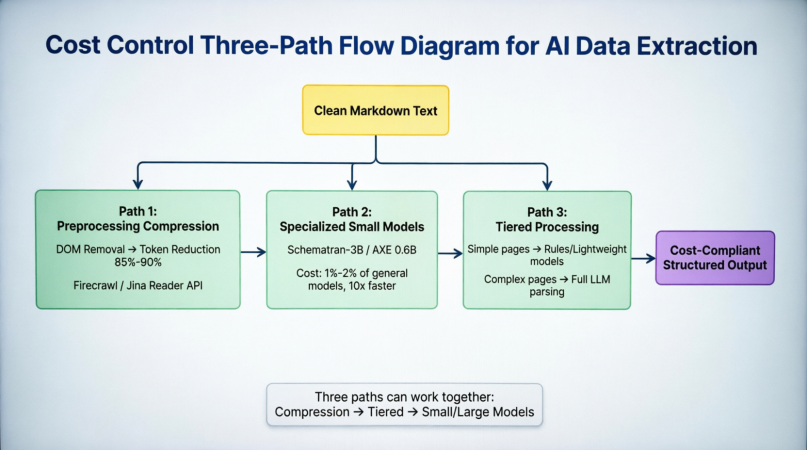
साफ किए गए मार्कडाउन के पहले, पथ एक आगे के अंत में DOM हटाने और मुख्य सामग्री निर्धारण द्वारा 85%–90% टोकन कम करता है। Firecrawl और Jina Reader ने इसे एक API में संकलित कर दिया है, जिससे विकासकर्ताओं को अपने स्वयं के साफ करने पाइपलाइन बनाने की आवश्यकता नहीं होती है। पथ द्वितीय मॉडल स्तर पर सामान्य बड़े मॉडल के स्थान पर कार्य-विशिष्ट मॉडल जैसे Schematron-3B और AXE 0.6B का उपयोग करता है, अनुमान लगाने की लागत को 1%–2% तक संकुचित करता है और 10 गुना से अधिक गति प्रदान करता है। पथ तीन संरचनात्मक रूप से सरल पृष्ठों पर नियंत्रण स्तर पर नियम या हल्के मॉडल का उपयोग करता है, केवल जटिल पृष्ठों को पूर्ण बड़े मॉडल के लिए हस्तांतरित करता है। यह ई-कॉमर्स श्रेणी निगर्मण जैसे अनुप्रयोगों में विशेष रूप से प्रभावी होता है, जहां एक ही साइट के भीतर अधिकांश पृष्ठों की संरचना अत्यधिक समान होती है, और केवल कुछ असामान्य पृष्ठों को पूर्ण पृष्ठ के हस्तांतरण की आवश्यकता होती है। तीन मार्ग एक दूसरे के विपरीत नहीं हैं, बल्कि एक साथ संयोजित हो सकते हैं: पहले टोकन कम करें, फिर जटिलता के आधार पर वर्गीकृत करें, और अंत में एक कार्य-मैचिंग मॉडल के साथ प्रक्रिया करें। चित्र 3-5 आगे इन तीन रणनीतियों के मूल सिद्धांत, टोकन कमी, प्रतिनिधि समाधान और लागत कमी के परिमाण के आधार पर तीन डेटा गुणवत्ता जांच के साथ इन तीन रणनीतियों की तुलना करता है:

पूर्व-प्रक्रिया संपीड़न सीधे डॉम शोर को हटाकर इनपुट आयतन को कम करता है, 85%–90% टोकन कमी प्राप्त करता है, जिसके लिए 80%–90% लागत बचत होती है। विशेषज्ञ छोटे मॉडल आकार के संकुचन द्वारा एक अनुमान की लागत कम करते हैं, जिसमें पैरामीटर 10 बिलियन से 0.6B–3B तक कम हो जाते हैं, जिससे अनुमान लगाने की लागत में लगभग 98% की बचत होती है। परत वाली प्रक्रिया असमान गणना संसाधन आवंटन के माध्यम से समग्र दक्षता में सुधार करती है, जिसके लिए बचत आसान पृष्ठों के अनुपात पर निर्भर करती है। ये तीन दृष्टिकोण, "कम भेजें", "कम गणना करें" और "बुद्धिमानी से गणना करें" के आधार पर, इनपुट स्तर, मॉडल स्तर और नियंत्रण स्तर को कवर करने वाली पूर्ण लागत कमी प्रणाली बनाते हैं।
दूसरा आधा गुणवत्ता आश्वासन की ओर झुकता है। डेटा गुणवत्ता जांच लागत नियंत्रण में अक्सर अनदेखा किया जाता है, लेकिन समान रूप से महत्वपूर्ण होता है। नीचे के व्यापार में प्रवेश करने वाले कम गुणवत्ता वाले डेटा के लागत आमतौर पर निष्कर्षण चरण में जांच करने में निवेश के बराबर होती है। उत्पादन वातावरण में, कम से कम तीन स्वचालित जांचें डेप्लॉय करनी चाहिए: क्षेत्र भराव दर जांच सुनिश्चित करती है कि स्कीमा में आवश्यक क्षेत्र खाली नहीं हैं, असामान्य रिकॉर्ड को हस्तक्षेप के लिए चिह्नि