कॉर्पोरेट स्वचालन को उन्नत करते हुए: LLM-संचालित बुनियादी ढांचा सीमाहीन CAPTCHA पहचान एवं संचालन की कार्यक्षमता

Rajinder Singh
Deep Learning Researcher

डिजिटल रूपांतरण के तेजी से विकसित होते वातावरण में, CAPTCHA के बुनियादी सुरक्षा जांच से लेकर जटिल व्यावसायिक प्रक्रिया फ़िल्टर तक के रूप में बदल गए हैं। सुरक्षा के लिए आवश्यक, लेकिन वे अक्सर गतिशीलता के "दक्षता अंतर" बना देते हैं। वैश्विक स्तर पर, व्यावसायिक अनुकूलन के अवरोध के कारण, एंटरप्राइजेस द्वारा दैनिक रूप से लगभग 500,000 घंटे मैन्युअल CAPTCHA समाधान में बर्बाद किए जाते हैं।
इस मैन्युअल हस्तक्षेप के कारण कई चुनौतियाँ होती हैं:
- उच्च ऑपरेशनल लागत: बढ़ते व्यावसायिक आकार के साथ मानव ऑपरेटरों पर निर्भरता खराब तरीके से पैमाने पर बढ़ती है।
- प्रक्रिया अस्थिरता: ऑटोमेटेड स्क्रिप्ट अक्सर CAPTCHA के सामने रुक जाते हैं, व्यावसायिक प्रक्रियाओं की निरंतरता तोड़ देते हैं।
- गोपनीयता और तकनीकी दबाव: बदलते गोपनीयता मानक व्यवहार-आधारित सत्यापन विधियों के लिए चुनौतियाँ पैदा करते हैं, अधिक पारदर्शी और कुशल समाधान की आवश्यकता होती है।
हमारी दृष्टि: हम मानते हैं कि CAPTCHA को व्यावसायिक वृद्धि को बल देना चाहिए, न कि रोक देना। कृत्रिम बुद्धिमत्ता ऑटोमेशन इंफ्रास्ट्रक्चर के माध्यम से स्वचालित CAPTCHA पहचान प्रदान करके, हम एंटरप्राइजेस को मानवीय हस्तक्षेप को बहुत कम करने, ऑपरेशनल लागत को अनुकूलित करने और उनकी मुख्य व्यावसायिक प्रक्रियाओं के पारिस्थितिकी दक्षता को बढ़ाने में सक्षम बनाने के लिए समर्पित हैं।
📈 I. सत्यापन का विकास: स्थिर नियमों से बुद्धिमान संयोजन तक
पिछले 25 वर्षों में सत्यापन प्रौद्योगिकी की यात्रा सुरक्षा और उपयोगकर्ता अनुभव के बीच संतुलन की लगातार खोज को दर्शाती है। बड़े भाषा मॉडल (LLM) के उदय ने एक महत्वपूर्ण बदलाव ला दिया, एक नई बुद्धिमान, संयुक्त प्रक्रिया के युग की शुरुआत की।
| चरण | मुख्य प्रौद्योगिकी | प्रक्रिया तार्क | व्यावसायिक प्रभाव |
|---|---|---|---|
| V1 (2000s) | विकृत अक्षर | सरल OCR पहचान | आधुनिक ऑटोमेशन के लिए असुरक्षित, शुरुआती दक्षता उच्च |
| V2 (2014s) | छवि चयन | वस्तु डिटेक्शन और वर्गीकरण | विस्तृत मैनुअल लेबलिंग की आवश्यकता होती है, ऑपरेशनल लागत बढ़ जाती है |
| V3 (2024s) | व्यवहार विश्लेषण | जोखिम बिंदु और फिंगरप्रिंटिंग | गोपनीयता के सवाल, ऑटोमेशन के लिए कठिन |
| V4 (2026+) | LLM संयोजन | अर्थग्रहण और उत्पादन | उच्च विश्वसनीयता, उच्च दक्षता, पूर्ण ऑटोमेशन |
मुख्य अवधारणा: जैसे-जैसे CAPTCHA सामान्य और बहुमाध्यमिक दिशा की ओर बढ़ते हैं, पारंपरिक नियम-आधारित या कोडबेस्ड समाधान अपर्याप्त साबित हो रहे हैं। उद्योग को अपनी ऑटोमेशन आवश्यकताओं के लिए उन्नत अर्थग्रहण क्षमता वाले बुद्धिमान इंफ्रास्ट्रक्चर की आवश्यकता होती है। यहीं पर CAPTCHA के लिए LLM अनिवार्य हो जाता है।
🧠 II. LLM शक्ति: ऑटोमेशन इंफ्रास्ट्रक्चर की मुख्य क्षमताएं
बड़े मॉडल को सत्यापन प्रक्रिया परिसर में एम्बेड करना उन्हें व्यावसायिक प्रक्रिया दक्षता के चालक इंजन बनाता है।
इस प्रवृत्ति में, कुछ व्यावसायिक ऑटोमेशन इंफ्रास्ट्रक्चर प्लेटफॉर्म ने LLM क्षमताओं को डिज़ाइन करना शुरू कर दिया है। उदाहरण के लिए, CapSolver बहुमाध्यमिक पहचान के साथ बड़े मॉडल अनुमान क्षमताओं के संयोजन के माध्यम से स्थिर CAPTCHA ऑटोमेशन प्रक्रिया सेवाएं प्रदान करता है, जिससे एंटरप्राइजेस बिना मानवीय हस्तक्षेप बढ़ाए व्यावसायिक प्रक्रियाओं की निरंतरता और कार्यक्षमता में सुधार कर सकते हैं।
इस तरह के समाधान का मुख्य मूल्य एकल बिंदु क्षमता में नहीं है, बल्कि व्यावसायिक प्रक्रियाओं के लिए स्थिर ऑटोमेशन क्षमता और नियंत्रित लागत बनाए रखने के लिए नींव के रूप में काम करना है।
2.1 मुख्य क्षमता 1: बुद्धिमान जोखिम निर्णय इंजन
पारंपरिक ऑटोमेशन अक्सर CAPTCHA के प्रबंधन के लिए कठोर if-else नियमों पर निर्भर करता है, जिसके कारण अंशकालिक, बनाए रखने में कठिन और आसानी से बचे जा सकने वाले प्रणालियाँ बन जाती हैं। LLM-संचालित इंफ्रास्ट्रक्चर एक बुद्धिमान जोखिम निर्णय इंजन के रूप में काम करता है, विविध संकेतों को एकीकृत, अनुकूलन और स्पष्टीकरण वाले प्रक्रिया के साथ संयोजित करता है।
पारंपरिक दृष्टिकोण (नियम-आधारित):
python
# पारंपरिक तरीका
if ip_risk > 0.8 and device_new == True:
captcha_type = "hard"
elif behavior_score < 0.5:
captcha_type = "medium"
else:
captcha_type = "none"LLM-संचालित दृष्टिकोण (संदर्भ में निर्णय लेना):
python
# LLM तरीका
context = {
"ip_reputation": "medium",
"device_fingerprint": "new_device",
"behavior_score": 0.65,
"request_frequency": "high",
"geo_location": "anomalous",
"historical_pattern": "deviation_detected"
}
# LLM आउटपुट: {"risk_level": "high", "captcha_type": "semantic_image",
# "difficulty": 0.8, "reason": "उपकरण फिंगरप्रिंट नए IP भू-स्थिति के साथ टकराता है"}मूल्य पेशकश:
- ✅ गलत धन कमी (20%+): वैध उपयोगकर्ताओं के लिए बाधाओं को कम करें, उपयोगकर्ता अनुभव में सुधार करें।
- ✅ स्पष्ट निर्णय: सुरक्षा संचालन और लगातार अनुकूलन के लिए जांच करने योग्य दृष्टिकोण प्रदान करें।
- गतिशील समायोजन: बदलते सत्यापन चुनौतियों और व्यावसायिक आवश्यकताओं के साथ स्वयं अनुकूलित हो जाएं।
2.2 मुख्य क्षमता 2: जनरेटिव सत्यापन इंजन
पारंपरिक CAPTCHA के लिए सीमित प्रश्न बैंक अक्सर ऑफ़लाइन शिक्षण और जटिल ऑटोमेशन द्वारा अपराध के लिए खतरनाक होते हैं। जनरेटिव AI के माध्यम से, जैसे कि डिफ्यूज़न मॉडल, अद्वितीय, गतिशील सत्यापन चुनौतियाँ बनाई जाती हैं। प्रत्येक उदाहरण एक नवीन रचना है, अवैध ऑटोमेशन के प्रयास के लिए लागत और जटिलता में वृद्धि करती है।
mermaid
graph TD
A[पारंपरिक CAPTCHA] --> B{सीमित प्रश्न बैंक}
B --> C[ऑफ़लाइन शिक्षण/अपराध के लिए खतरनाक]
D[जनरेटिव सत्यापन इंजन] --> E{LLM + डिफ्यूज़न मॉडल}
E --> F[असीमित, अद्वितीय CAPTCHA उदाहरण]
F --> G[अवैध ऑटोमेशन के लिए असंभव लागत]मुख्य सिद्धांत: अवैध ऑटोमेशन के लिए सामान्यीकरण लागत अपराध के बचाव के संभावित लाभ से अधिक होनी चाहिए।
2.3 मुख्य क्षमता 3: गहरा व्यवहार अनुक्रम विश्लेषण
जबकि पारंपरिक व्यवहार विश्लेषण आसान पैटर्न (जैसे, सीधे माउस गति के रूप में रोबोटिक) को चिह्नित कर सकता है, LLM गहरा व्यवहार अनुक्रम विश्लेषण कर सकता है। उपयोगकर्ता क्रिया अनुक्रमों को वेक्टराइज करके और ट्रांसफॉर्मर मॉडलों के माध्यम से प्रक्रिया करके, प्रणाली अत्यधिक सटीक ऑटोमेटेड स्क्रिप्ट से छिपे मानवीय नुक्शान के अंतर को पहचान सकती है।
व्यवहार अनुक्रम विश्लेषण प्रवाह:
mermaid
graph LR
A[उपयोगकर्ता क्रिया अनुक्रम] --> B[एम्बेडिंग वेक्टराइजेशन]
B --> C[ट्रांसफॉर्मर कोडिंग]
C --> D[जोखिम बिंदु]
subgraph उपयोगकर्ता क्रियाएं
E[माउस गति]
F[क्लिक स्थिति]
G[स्थिरता समय]
H[पृष्ठ स्क्रॉलिंग]
I[कीबोर्ड रिथ्म]
end
E --> A
F --> A
G --> A
H --> A
I --> A
D --> J{LLM निर्णय: "अस्पष्ट वास्तविक उपयोगकर्ता" विरुद्ध "पूर्ण ऑटोमेटेड स्क्रिप्ट"}इससे प्रणाली एक "अस्पष्ट, वास्तविक उपयोगकर्ता" और एक "पूर्ण ऑटोमेटेड स्क्रिप्ट" के बीच अंतर कर सकती है, वास्तविक अंतरक्रिया में अंतर्निहित "मानवीय असंगतता" के आधार पर।
🗺️ III. रणनीतिक लाभ: LLM के साथ ऑटोमेशन लागत को अनुकूलित करें
कारगर ऑटोमेशन की आत्मा निर्विवाद रोकथाम नहीं है, बल्कि अवैध बचाव के आर्थिक अनुकूलता को बनाए रखना है। LLM इस लागत असमानता को बढ़ाता है, वैध ऑटोमेशन को अधिक कुशल बनाता है और अवैध ऑटोमेशन को असंभव बनाता है।
अवैध ऑटोमेशन की तुलना में बुद्धिमान इंफ्रास्ट्रक्चर:
| लागत कारक | अवैध ऑटोमेशन | बुद्धिमान इंफ्रास्ट्रक्चर |
|---|---|---|
| डेटा संग्रह | उच्च (शिक्षण के लिए) | कम (व्यवहार डेटा अर्जित करें) |
| मॉडल शिक्षण | उच्च (पुनरावृत्ति शिक्षण) | मध्यम (जनरेटिव मॉडल डेप्लॉयमेंट) |
| अवैध नमूना उत्पादन | उच्च | N/A |
| प्रभावी जीवनकाल | कम (CAPTCHA अप्रचलित हो जाता है) | उच्च (डायनामिक रणनीति अपडेट) |
| खोज जोखिम | उच्च | कम |
| गलत धन निपटान | N/A | मध्यम (अपील प्रक्रिया) |
निष्कर्ष: अवैध ऑटोमेशन की ऑपरेशनल लागत लंबे समय तक LLM-संचालित इंफ्रास्ट्रक्चर के बर्ताव की स्थायी लागत से बहुत अधिक है, जो लंबे समय तक बल्कि विश्वसनीय ऑटोमेशन सुनिश्चित करता है।
LLM के माध्यम से लागत अनुकूलन कैसे बढ़ता है:
- सामान्यीकरण लागत बढ़ाएं: जनरेटिव CAPTCHA असीमित दृश्य अंतराल बनाते हैं, पूर्व-शिक्षित मॉडलों को रोकते हैं।
- अनुमान लागत बढ़ाएं: अर्थग्रहण CAPTCHA बहु-चरण तर्क की आवश्यकता होती है, अवैध प्रयासों के लिए बड़े संगणनात्मक संसाधनों का उपयोग करते हैं।
- समय-लाइव कम करें: छोटे CAPTCHA वैधता अवधि उन्हें व्यापक रूप से डेप्लॉय करने से पहले अप्रासंगिक बना देती हैं।
- डेटा प्रदूषण: वास्तविक ट्रैफिक के साथ होनीपॉट डेटा के साथ डायनामिक ओब्फुस्केशन अवैध ऑटोमेशन के लिए शिक्षण डेटासेट को प्रदूषित करता है।
🚀 IV. भविष्य की दृष्टि: एक असंगत, विश्वसनीय ऑटोमेशन पारिस्थितिकी निर्माण
हम एक ऐसा भविष्य देखते हैं जहां सत्यापन एक अदृश्य, लगातार प्रक्रिया है, उपयोगकर्ता अनुभव में बिना किसी बाधा के एम्बेड किया गया है।
4.1 चरण 1: LLM के रूप में "दक्षता को-पायलट" (वर्तमान - निकट भविष्य)
इस प्रारंभिक चरण में, LLM एक बुद्धिमान सहायक के रूप में काम करते हैं, सुरक्षा संचालन की दक्षता में सुधार करते हैं, न कि महत्वपूर्ण निर्णय लेते हैं। वे जटिल सत्यापन तार्क को प्रक्रिया करते हैं, मानवीय हस्तक्षेप की आवृत्ति में बहुत कमी लाते हैं और मानव विशेषज्ञों के लिए कार्यान्वयन अवसर प्रदान करते हैं।
mermaid
graph TD
A[उपयोगकर्ता अनुरोध] --> B{पारंपरिक सत्यापन प्रणाली}
B --> C{CAPTCHA मिला}
C --> D[LLM को-पायलट: CAPTCHA और संदर्भ विश्लेषण]
D --> E{मानव सुरक्षा विशेषज्ञ: समीक्षा और निर्णय}
E --> F[सत्यापन परिणाम]
D -- "समाधान सुझाता है" --> E
E -- "प्रतिक्रिया प्रदान करता है" --> Dमुख्य सिद्धांत: LLM एक को-पायलट के रूप में काम करते हैं, मानव विशेषज्ञता को बढ़ाकर ऑपरेशनल दक्षता में सुधार करते हैं।
4.2 चरण 2: डायनामिक जनरेटिव सत्यापन (निकट भविष्य - मध्य-समय)
इस चरण में LLM के साथ जनरेटिव मॉडल (जैसे, डिफ्यूज़न मॉडल) का संयोजन किया जाता है, जो CAPTCHA के लिए पूर्व-शिक्षित नहीं हो सकते। प्रत्येक सत्यापन उदाहरण अद्वितीय होता है, जिसके कारण किसी भी सफल बचाव के बाद अगले प्रयासों के लिए कोई लाभ नहीं होता। सत्यापन "प्रश्न बैंक निकालने" मॉडल से "वास्तविक समय बनाने" में बदल जाता है।
mermaid
graph TD
A[उपयोगकर्ता पहुंच] --> B[LLM: पृष्ठ संदर्भ समझें]
B --> C["जनरेटिव AI (डिफ्यूज़न): सार्थक CAPTCHA बनाएं"]
C --> D[उपयोगकर्ता: अद्वितीय CAPTCHA हल करें]
D --> E[सत्यापन सफलता/असफलता]
subgraph उदाहरण CAPTCHA
F["इस लेख में 3 शहरों के बारे में बताया गया है, कृपया नक्शे पर उनके स्थान चिह्नित करें।"]
end
C --> Fभविष्य के CAPTCHA का उदाहरण:
उपयोगकर्ता पृष्ठ पर पहुंचता है → LLM पृष्ठ के सामग्री को समझता है → एक सार्थक सत्यापन प्रश्न बनाता है।
- "इस लेख में 3 शहरों के बारे में बताया गया है; कृपया नक्शे पर उनके स्थान चिह्नित करें।"
इसके लिए लेख की सामग्री, भौगोलिक ज्ञान और छवि अंतःक्रिया की आवश्यकता होती है, जो ऑटोमेटेड बचाव के लिए बहुत महंगा होता है, जबकि मानव उपयोगकर्ताओं के लिए प्रबंधनीय होता है।
4.3 चरण 3: लगातार विश्वास इंजन (मध्य-समय - दूर भविष्य)
अंतिम लक्ष्य "स्पष्ट CAPTCHA" के विलोपन के साथ एक लगातार, पृष्ठभूमि विश्वास मूल्यांकन है। उपयोगकर्ता को विश्वास चरण के बारे में अनुभव नहीं होता, क्योंकि प्रणाली वास्तविक समय व्यवहार संकेतों पर विश्वास के लगातार मूल्यांकन करती है।
mermaid
graph TD
A[उपयोगकर्ता एप्प खोलता है] --> B[पृष्ठभूमि: व्यवहार संकेत एकत्र करें]
B --> C[LLM: वास्तविक समय विश्वास स्कोर की गणना करें]
C --> D{विश्वास स्कोर > घोषित सीमा?}
D -- हाँ --> E[असीमित ऑपरेशन]
D -- नहीं (छिपा हुआ अवमूल्यन) --> F[सीमित कार्यक्षमता]
D -- नहीं (स्पष्ट सत्यापन) --> G[CAPTCHA/हस्तक्षेप ट्रिगर करें]2030 के भविष्य के अनुभव का अनुमान:
उपयोगकर्ता एप्प खोलता है → पृष्ठभूमि लगातार व्यवहार संकेत एकत्र करता है → LLM वास्तविक समय विश्वास स्कोर की गणना करता है।
- विश्वास स्कोर > सीमा: सभी ऑपरेशन बिना किसी बाधा के आगे बढ़ते हैं।
- विश्वास स्कोर < सीमा: कुछ कार्यक्षमताएं छिपे हुए अवमूल्यन होती हैं।
- विश्वास स्कोर << सीमा: स्पष्ट सत्यापन या हस्तक्षेप ट्रिगर करता है।
उपयोगकर्ता को कभी-कभी "मैं एक रोबोट नहीं हूं" पर क्लिक करने की आवश्यकता नहीं होगी, एक वास्तविक बिना किसी बाधा और कुशल अनुभव प्राप्त करता है।
4.4 आगे: AI-नेटिव सत्यापन के भविष्य की अग्रणी अवधारणाएं
हम उन्नत अवधारणाओं के अध्ययन में भी जा रहे हैं, जैसे कि "AI-विशिष्ट CAPTCHA" – मानव-सहायता AI (उदाहरण के लिए, उपयोगकर्ता द्वारा AI सहायक का उपयोग) और शुद्ध ऑटोमेटेड स्क्रिप्ट के बीच अंतर करने के लिए डिज़ाइन किए गए। जैसे-जैसे AI सहायक सामान्य होते जाते हैं, इस अंतर की आवश्यकता न्यायसंगत और सुरक्षित डिजिटल अंतरक्रिया बनाए रखने के लिए महत्वपूर्ण होगी।
⚠️ V. नैतिकता और जिम्मेदार AI कार्यान्वयन
हालांकि, LLM के अपने अद्वितीय अवसर प्रदान करते हैं, हम AI कार्यान्वयन के लिए एक जिम्मेदार दृष्टिकोण की प्राथमिकता देते हैं, जो पारदर्शिता और नैतिक विचारों पर ध्यान केंद्रित करता है:
mermaid
graph TD
A[LLM-चालित ऑटोमेशन] --> B{पारदर्शिता पहले}
A --> C{लागत नियंत्रण}
A --> D["सुरक्षा नेट: मानव-में-दृष्टि"]
B --> B1["डेटा गोपनीयता संरक्षण"]
B --> B2[भेदभाव निवारण]
B --> B3[स्पष्टीकरण विश्लेषण]
C --> C1[अनुकूलित मॉडल अनुमान]
C --> C2[उच्च ROI विपरीत मानव प्रक्रिया]
D --> D1[मानव निरीक्षण]
D --> D2[जटिल परिस्थितियों के लिए मानव समीक्षा]मुख्य विचार:
- डेटा गोपनीयता: सभी डेटा संग्रह और प्रक्रिया वैश्विक गोपनीयता संरक्षण मानकों के अनुरूप होना चाहिए।
- भेदभाव निवारण: LLM-चालित निर्णय में संभावित भेदभाव की निरंतर निगरानी और निवारण करें ताकि न्यायसंगतता सुनिश्चित की जा सके।
- पारदर्शिता और स्पष्टीकरण: उपयोगकर्ता असहमति के मामलों में LLM के सत्यापन निर्णय कैसे करते हैं, इसके स्पष्ट अंतर्दृष्टि प्रदान करें।
- मानव-में-दृष्टि: जटिल या अस्पष्ट परिस्थितियों में मानव निरीक्षण और हस्तक्षेप के तंत्र बनाए रखें।
मुख्य सिद्धांत: AI-चालित निर्णय प्राथमिक हैं, नियम-आधारित फॉलबैक और मानव-AI सहयोग बल्कि नैतिक ऑपरेशन सुनिश्चित करते हैं।
💡 VI. एंटरप्राइजेस के लिए कार्यान्वयन रणनीतियां: बुद्धिमान ऑटोमेशन का उपयोग करें
LLM-चालित ऑटोमेशन की शक्ति का उपयोग करने के लिए, एंटरप्राइजेस निम्नलिखित रणनीतियां अपना सकते हैं:
- 📊 वर्तमान स्थिति का मूल्यांकन करें: वर्तमान सत्यापन प्रणालियों की खोज करें जो ओपन-सोर्स OCR/डिटेक्शन मॉडल के लिए असुरक्षित हैं और महत्वपूर्ण मापदंडों के विश्लेषण करें जैसे कि गलत धन दर, उपयोगकर्ता शिकायत दर और ऑटोमेशन सफलता दर।
- 🧪 पायलट और अनुकूलित करें: कम जोखिम वाली व्यावसायिक रेखाओं के साथ "सीमाना बिना सत्यापन" या "डायनामिक कठिनाई" समाधान के पायलट शुरू करें। नए रणनीतियों के प्रभाव को मापने के लिए A/B टेस्टिंग फ्रेमवर्क स्थापित करें।
- 📚 अग्रणी रहें: जनरेटिव AI (जैसे, डिफ्यूज़न मॉडल) और बहुमाध्यमिक LLM के विकास की निगरानी करें जिनका उपयोग सत्यापन और ऑटोमेशन में किया जाता है। उद्योग सुरक्षा सम्मेलनों (जैसे, BlackHat, DEF CON, RSA) में भाग लेकर अपडेट रहें।
- 🗄️ डेटा-केंद्रित दृष्टिकोण: "मानव-मशीन व्यवहार के अंतर" को दर्शाने वाले उच्च गुणवत्ता वाले डेटासेट बनाना शुरू करें। गोपनीयता के बरकरार रखते हुए सहयोगात्मक डेटा बुद्धिमत्ता के लिए फेडरेटेड लर्निंग की खोज करें।
- 👥 अंतर-कार्यकारी सहयोग: एआई इंजीनियर, सुरक्षा अनुसंधानकर्ता, उत्पाद प्रबंधक और विशेषज्ञों वाली टीमों को बढ़ावा दें। नियमित आंतरिक रेड-टीमिंग अभ्यास करें और ज्ञान साझा करने की व्यवस्था स्थापित करें।
🎯 निष्कर्ष: सत्यापन का भविष्य असंघटित दक्षता है
कैप्चा के 25 साल के इतिहास के बारे में एक चक्र दिखाई देता है: एआई निर्माण → एआई रक्षा के लिए कैप्चा → एआई कैप्चा को पार कर जाता है → कैप्चा अपग्रेड करता है, मानवों को बेहाल करता है → मानव बिना खर्चे के एआई को प्रशिक्षित करते हैं → एआई अधिक शक्तिशाली हो जाता है... हालांकि, बड़े भाषा मॉडल (LLMs) के आगमन ने एक परिवर्तन ला दिया है।
स्मार्ट कृत्रिम बुद्धिमत्ता ऑटोमेशन इंफ्रास्ट्रक्चर के साथ, सत्यापन एक साधारण बाधा से परे जाता है। यह व्यापार प्रक्रियाओं को बिना रुके घेर लेता है, खुफिया जोखिम का संवेदनशील रूप से अनुभव करता है, डायनामिक रूप से तीव्रता को समायोजित करता है और सुरक्षा और उपयोगकर्ता अनुभव के बीच आदर्श संतुलन बनाए रखता है।
सत्यापन का अंतिम रूप "असंघटित दक्षता" है। यह सुरक्षा की आवश्यकता के अभाव का संकेत नहीं है, बल्कि सत्यापन के अदृश्य एकीकरण का संकेत है। हमारा लक्ष्य यह सुनिश्चित करना है कि 90% वैध उपयोगकर्ता कभी-कभी सत्यापन चरण को महसूस नहीं करेंगे, जबकि 100% अवैध ऑटोमेशन को आर्थिक रूप से असहनीय लागत का सामना करना पड़ेगा।
एक नेतृत्वकर्ता वैश्विक कैप्चा स्वीकृति ऑटोमेशन समाधान प्रदाता के रूप में, हम व्यापार प्रक्रियाओं में घर्षण को दूर करने वाले नवाचार में विश्वास रखते हैं। हम एक बेहतर और अधिक कुशल ऑटोमेशन पारिस्थितिकी बनाना चाहते हैं, जो कंपनियों को सत्यापन चुनौतियों के बिना मुख्य वृद्धि पर ध्यान केंद्रित करने की अनुमति देता है।
एक अधिक कुशल ऑटोमेशन प्रणाली बनाना शुरू करें
अगर आप जटिल सत्यापन वातावरण में अधिक स्थिर और कुशल ऑटोमेशन प्रक्रियाओं के बारे में खोज रहे हैं, तो एक विश्वसनीय कृत्रिम बुद्धिमत्ता ऑटोमेशन इंफ्रास्ट्रक्चर महत्वपूर्ण होगा।
👉 CapSolver के माध्यम से, आप:
- मुख्य कैप्चा प्रकार के स्वचालित पहचान और प्रसंस्करण हासिल कर सकते हैं
- हस्तक्षेप की लागत कम करें और प्रक्रिया निरंतरता में सुधार करें
- डायनामिक सत्यापन वातावरण में स्थिर सफलता दर बनाए रखें
- मौजूदा व्यापार प्रणालियों के साथ तेजी से एकीकरण करें
डेटा संग्रह, विकास ऑटोमेशन, या जटिल व्यापार प्रक्रिया अनुकूलन के बारे में, CapSolver आपके लिए एक अधिक कुशल ऑटोमेशन प्रणाली बनाने में आधारभूत क्षमता के रूप में काम कर सकता है।
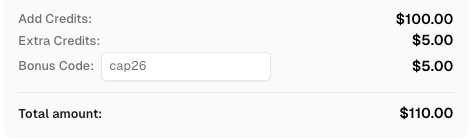
🎁 विशेष लाभ
CapSolver पर पंजीकरण करते समय कोड
CAP26का उपयोग करें ताकि आपको अतिरिक्त क्रेडिट मिले!
और देखें
AIMar 27, 2026
LLM ट्रेनिंग के लिए डेटा संग्रह के पैमाने को बढ़ाना: CAPTCHAs को पैमाने पर हल करना
LLM प्रशिक्षण के लिए पैमाने पर डेटा संग्रह कैसे करें, जैसे कि CAPTCHAs को हल करके। AI मॉडल के लिए उच्च गुणवत्ता वाले डेटासेट बनाने के लिए स्वचालित रणनीतियाँ खोजें।

AIMar 24, 2026
CAPTCHA कैसे हल करें OpenBrowser में CapSolver का उपयोग करके (AI एजेंट स्वचालन गाइड)
OpenBrowser में CapSolver के माध्यम से CAPTCHA हल करें। AI एजेंट के लिए reCAPTCHA, Turnstile आदि को स्वचालित करें आसानी से।