Técnicas de evasión de detección para el raspado de web: Extracción estable de datos

Anh Tuan
Data Science Expert
TL;Dr
- Rotación de IP y proxies: Distribuir las solicitudes a través de proxies residenciales o móviles evita el bloqueo basado en IP y el límite de tasa.
- Optimización de encabezados: Simular encabezados de navegador real, especialmente User-Agent y Referer, ayuda a evadir la filtración HTTP básica.
- Mitigación de la huella digital del navegador: Gestionar las huellas Canvas, WebGL y TLS es esencial para evitar la detección avanzada de comportamiento.
- Manejo de desafíos de JavaScript: Los navegadores headless pueden ejecutar JavaScript, pero requieren una configuración cuidadosa para evitar la detección.
- Resolución de CAPTCHA: Integrar servicios de resolución automática de CAPTCHA como CapSolver asegura flujos de extracción de datos ininterrumpidos.
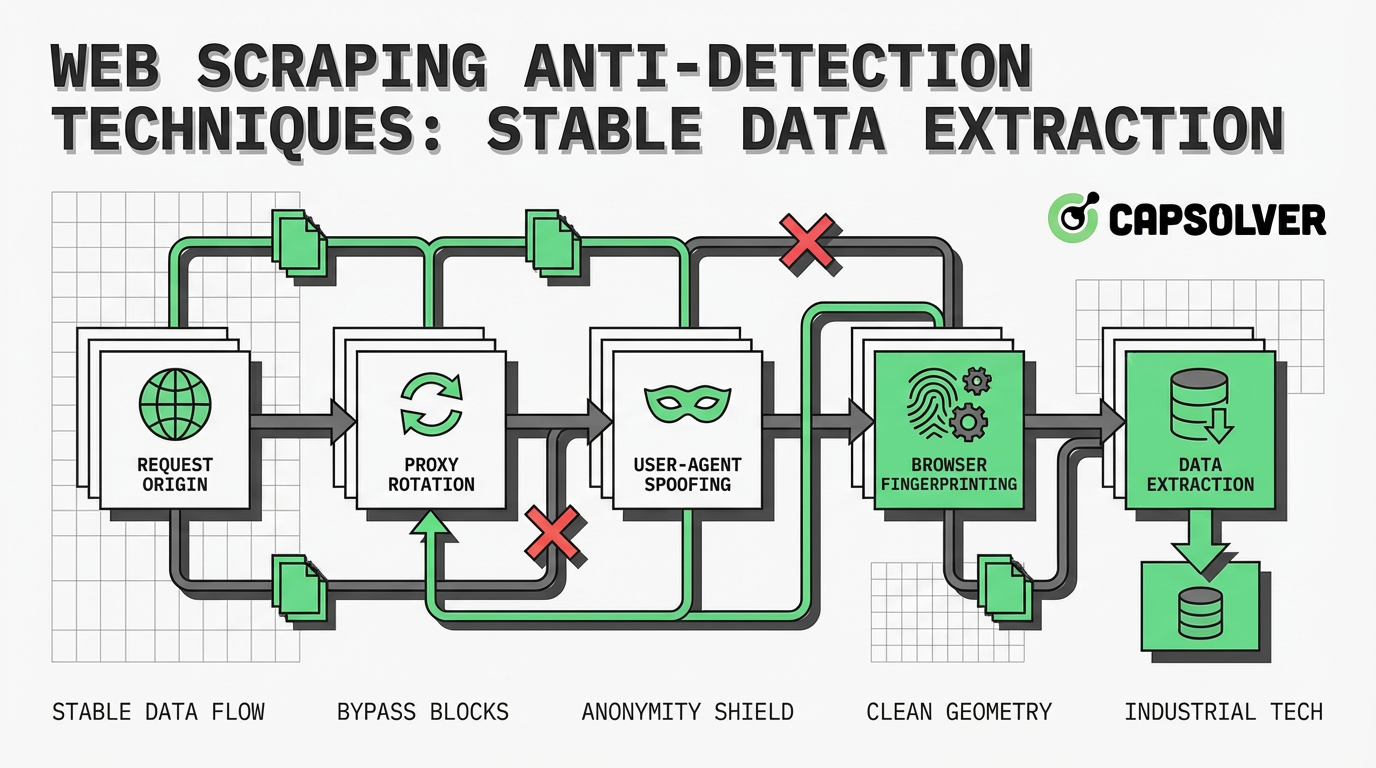
Introducción
La extracción de datos es un componente crucial de la inteligencia empresarial moderna, pero los sitios web están implementando defensas cada vez más sofisticadas para bloquear el acceso automatizado. Comprender las técnicas de anti-detección en el raspado de web ya no es opcional para los desarrolladores; es un requisito fundamental para mantener pipelines de datos estables y confiables. Este guía explora los mecanismos básicos detrás de la detección de bots, desde el límite de tasa de IP básico hasta la huella digital del navegador avanzada. Al examinar estas estrategias defensivas, los ingenieros de datos y profesionales de raspado pueden implementar metodologías sólidas para garantizar un acceso constante a la información pública. El enfoque aquí es en enfoques prácticos y estructurados para evadir la detección mientras se mantienen prácticas éticas y compatibles con las normativas.
¿Qué es la anti-detección en el raspado de web?
Las técnicas de anti-detección en el raspado de web se refieren a los métodos y herramientas utilizados por los desarrolladores para evitar que sus scripts automatizados sean identificados y bloqueados por los sitios web objetivo. Cuando un raspador accede a un sitio web, deja una huella digital. Si esta huella difiere del comportamiento típico de un usuario humano, los sistemas de seguridad del sitio marcarán la actividad como automatizada.
El objetivo principal de la anti-detección es imitar lo más posible la interacción humana. Esto implica gestionar identificadores a nivel de red, como las direcciones IP, y características a nivel de aplicación, como los encabezados HTTP y las huellas digitales del navegador. Sin estas técnicas, los raspadores enfrentan prohibiciones inmediatas de IP, desafíos de CAPTCHA o respuestas engañosas como honeypots. Comprender la tecnología subyacente de la detección de bots es el primer paso para construir sistemas de extracción de datos resistentes.
Cómo detectan los sitios web a los raspadores
Los administradores de sitios web emplean un enfoque multicapa para identificar y mitigar el tráfico automatizado. Estas defensas van desde filtros basados en reglas simples hasta algoritmos de aprendizaje automático complejos que analizan el comportamiento del usuario en tiempo real.
Dirección IP y límite de tasa
El método de detección más fundamental implica monitorear la frecuencia y el origen de las solicitudes entrantes. Si una sola dirección IP genera un volumen inusualmente alto de tráfico en un corto período, el servidor probablemente la bloqueará. Esto se conoce como límite de tasa. Además, los sitios web suelen mantener listas negras de rangos de IP de centros de datos, marcando inmediatamente como sospechoso el tráfico que proviene de estas fuentes.
Análisis de encabezados HTTP
Cada solicitud HTTP contiene encabezados que proporcionan información sobre el cliente. Los sistemas de seguridad revisan estos encabezados, especialmente el User-Agent, que identifica el navegador y el sistema operativo. Los raspadores que usan bibliotecas predeterminadas suelen enviar encabezados faltantes o anómalos. Por ejemplo, una solicitud que carece del encabezado Accept-Language o que presenta una cadena User-Agent obsoleta es una fuerte indicación de actividad automatizada.
Huella digital del navegador
Los sistemas de detección avanzados van más allá de los encabezados para analizar las características únicas del navegador del cliente. Esta técnica, conocida como huella digital del navegador, recopila datos sobre la resolución de pantalla, fuentes instaladas, complementos compatibles y la concurrencia de hardware. Métodos aún más sofisticados involucran la huella digital de Canvas y WebGL, que instruyen al navegador para renderizar una imagen oculta y analizar las pequeñas diferencias en cómo el hardware procesa las gráficas. Estas variaciones sutiles crean un identificador altamente preciso para el dispositivo.
Análisis de comportamiento y honeypots
Las soluciones de seguridad modernas evalúan cómo un usuario interactúa con la página. Rastrean movimientos del mouse, patrones de desplazamiento y el tiempo entre clics. Los bots suelen mostrar un comportamiento lineal y predecible, mientras que los humanos son erráticos. Además, los sitios web implementan honeypots: enlaces o campos de formulario ocultos que no son visibles para los usuarios humanos, pero que son descubiertos por los raspadores que analizan el HTML. Interactuar con un honeypot revela inmediatamente la presencia de un bot.
Técnicas fundamentales de anti-detección en el raspado de web
Para mantener una extracción de datos estable, los desarrolladores deben implementar estrategias que contrarresten cada capa de defensa del sitio web. Los siguientes métodos forman la base de una anti-detección efectiva.
Implementar rotación de IP y proxies
Depender de una sola dirección IP es un camino garantizado para ser bloqueado. Para evitar el límite de tasa y las prohibiciones de IP, los raspadores deben utilizar redes de proxies. Al enrutar las solicitudes a través de direcciones IP diferentes, el raspador distribuye su tráfico, haciendo que parezca que múltiples usuarios acceden al sitio.
Aunque los proxies de centros de datos son rápidos y económicos, son fáciles de identificar. Para objetivos de alta seguridad, son necesarios proxies residenciales. Estos enrutan el tráfico a través de dispositivos reales proporcionados por proveedores de servicios de Internet (ISPs), ofreciendo un nivel mucho más alto de legitimidad. Para aprender más sobre la gestión efectiva de direcciones IP, revise esta guía sobre cómo evitar prohibiciones de IP.
Optimizar los encabezados HTTP
Crear encabezados HTTP realistas es crucial para evitar la filtración básica. La cadena User-Agent debe coincidir con un navegador moderno y ampliamente utilizado. Sin embargo, simplemente cambiar el User-Agent no es suficiente; el perfil completo de encabezados debe ser coherente.
Por ejemplo, si el User-Agent indica una máquina Windows, el encabezado Sec-Ch-Ua-Platform también debe reflejar Windows. Incluir encabezados como Accept, Accept-Encoding y Referer agrega autenticidad a la solicitud. El encabezado Referer, que indica la página anterior visitada, puede configurarse en un motor de búsqueda popular para simular tráfico orgánico. Para recomendaciones detalladas, consulte este recurso sobre la selección de los mejores User-Agent.
Utilizar navegadores headless
Muchos sitios web modernos dependen en gran medida de JavaScript para renderizar contenido dinámicamente. Los clientes HTTP tradicionales no pueden ejecutar JavaScript, lo que resulta en una extracción incompleta de datos. Los navegadores headless, como Puppeteer, Playwright o Selenium, resuelven este problema al ejecutar un entorno de navegador completo sin una interfaz gráfica.
Los navegadores headless pueden ejecutar JavaScript, manejar contenido dinámico y interactuar con la página como lo haría un usuario real. Sin embargo, las configuraciones predeterminadas de navegadores headless revelan variables identificables, como navigator.webdriver = true. Los desarrolladores deben usar plugins de stealth o marcos especializados para ocultar estos indicadores y evitar que el navegador headless sea detectado.
Gestionar la cadencia de las solicitudes
Para vencer el análisis de comportamiento, los raspadores deben abandonar patrones predecibles de solicitudes. Implementar retrasos aleatorios entre las solicitudes simula las pausas naturales que un humano toma al leer o navegar por un sitio. Además, agregar movimientos aleatorios del mouse y acciones de desplazamiento dentro de un entorno de navegador headless puede ayudar a evadir sistemas que monitorean la interacción del usuario.
Resumen comparativo: Detección vs. Mitigación
| Método de detección | Descripción | Estrategia de mitigación |
|---|---|---|
| Límite de tasa de IP | Bloqueo de IPs que superan un umbral específico de solicitudes. | Usar redes de proxies residenciales o móviles rotatorios. |
| Filtrado de encabezados | Análisis de encabezados HTTP en busca de anomalías o datos faltantes. | Crear encabezados consistentes, modernos (User-Agent, Referer, Accept). |
| Huella digital del navegador | Identificación de dispositivos basada en rasgos de hardware y software. | Usar navegadores anti-detección o plugins de stealth para falsificar huellas digitales. |
| Desafíos de JavaScript | Requerir ejecución de JS para acceder al contenido o verificar al cliente. | Implementar navegadores headless (Playwright, Puppeteer) con configuraciones de stealth. |
| Trampas de honeypot | Elementos HTML ocultos diseñados para captar analizadores automatizados. | Analizar propiedades de visibilidad CSS antes de interactuar con elementos. |
Desafíos avanzados: CAPTCHAS y sistemas de seguridad
Incluso con una rotación de IP perfecta y una optimización de encabezados, los raspadores frecuentemente encuentran CAPTCHAS. Estos desafíos están específicamente diseñados para diferenciar a humanos de bots, requiriendo que el usuario resuelva acertijos visuales o analice datos de comportamiento complejos.
Sistemas de seguridad como Cloudflare Turnstile y DataDome emplean análisis de riesgo avanzado, evaluando la reputación de la IP del cliente, la huella TLS y el historial de interacción antes de decidir si presentar un CAPTCHA. Cuando un raspador encuentra estas barreras, la intervención manual es imposible a gran escala. Es aquí donde los servicios de resolución automática se convierten en esenciales para mantener la cadena de suministro de datos. Para conocer las tendencias actuales, lea sobre resolver CAPTCHA mientras se raspadea en 2025.
Automatizar la resolución de CAPTCHA con CapSolver
Cuando las técnicas de anti-detección en el raspado de web alcanzan sus límites, CapSolver ofrece una solución sólida para manejar CAPTCHAS complejos. CapSolver es un servicio impulsado por inteligencia artificial que automatiza la resolución de diversos desafíos, incluyendo reCAPTCHA, Cloudflare Turnstile y acertijos basados en imágenes.
Al integrar CapSolver en su arquitectura de raspado, puede evitar programáticamente estas interrupciones. El servicio utiliza modelos de aprendizaje automático avanzados para analizar y resolver desafíos rápidamente y con precisión, asegurando que sus procesos de extracción de datos permanezcan eficientes e ininterrumpidos. Este enfoque es especialmente valioso al manejar tareas de raspado de alto volumen donde es inevitable encontrar CAPTCHAS.
Use el código
CAP26al registrarse en CapSolver para recibir créditos adicionales!
Ejemplo de integración: Resolver reCAPTCHA v2
Integrar CapSolver en un script de raspado basado en Python es sencillo. El siguiente ejemplo muestra cómo usar la API de CapSolver para resolver un desafío reCAPTCHA v2. Este método utiliza el tipo de tarea ReCaptchaV2TaskProxyLess, que aprovecha la infraestructura de proxy integrada de CapSolver.
python
import requests
import time
# Configuración
API_KEY = "SU_CLAVE_DE_API_DE_CAPSOLVER"
SITE_KEY = "6Le-wvkSAAAAAPBMRTvw0Q4Muexq9bi0DJwx_mJ-"
SITE_URL = "https://www.google.com/recaptcha/api2/demo"
def solve_recaptcha():
# Paso 1: Crear la tarea
payload = {
"clientKey": API_KEY,
"task": {
"type": "ReCaptchaV2TaskProxyLess",
"websiteKey": SITE_KEY,
"websiteURL": SITE_URL
}
}
response = requests.post("https://api.capsolver.com/createTask", json=payload)
task_data = response.json()
task_id = task_data.get("taskId")
if not task_id:
print("No se pudo crear la tarea:", response.text)
return None
print(f"Tarea creada correctamente. ID de tarea: {task_id}")
# Paso 2: Consultar el resultado
while True:
time.sleep(2)
result_payload = {
"clientKey": API_KEY,
"taskId": task_id
}
result_response = requests.post("https://api.capsolver.com/getTaskResult", json=result_payload)
result_data = result_response.json()
status = result_data.get("status")
if status == "ready":
print("CAPTCHA resuelto correctamente!")
return result_data.get("solution", {}).get("gRecaptchaResponse")
elif status == "failed" or result_data.get("errorId"):
print("No se pudo resolver el CAPTCHA:", result_response.text)
return None
# Ejecutar el solucionador
token = solve_recaptcha()
if token:
print(f"Token recibido: {token[:50]}...")
# Continuar enviando el token al sitio objetivoPara más estrategias de implementación detalladas, explore esta guía completa sobre cómo resolver reCAPTCHA en el raspado de web usando Python.
Consideraciones éticas y cumplimiento
Mientras que dominar las técnicas de anti-detección en el raspado de web es crucial para el éxito técnico, debe equilibrarse con consideraciones éticas. La extracción de datos debe respetar siempre la infraestructura del sitio web objetivo y sus términos de servicio.
Los desarrolladores deben seguir las pautas especificadas en el archivo robots.txt, que indica las áreas permitidas y prohibidas para el rastreo. Además, implementar límites razonables de tasa garantiza que la actividad de raspado no degrada el rendimiento del sitio para usuarios legítimos. El raspado responsable se enfoca en extraer datos públicos disponibles sin causar daño o violar regulaciones de privacidad.
Conclusión
Navegar con éxito las complejidades de la extracción de datos requiere un profundo entendimiento de las técnicas de anti-detección en el raspado de web. Al implementar una rotación robusta de IP, optimizar los encabezados HTTP y gestionar las huellas digitales del navegador, los desarrolladores pueden reducir significativamente la probabilidad de ser bloqueados. Sin embargo, a medida que los sistemas de seguridad evolucionan, enfrentar CAPTCHAS sigue siendo un desafío constante. Integrar soluciones automatizadas como CapSolver asegura que su infraestructura de raspado permanezca resistente, permitiendo una recolección de datos estable y continua en un entorno digital cada vez más restringido.
Preguntas frecuentes
¿Cuáles son las técnicas más comunes de anti-detección en el raspado de web?
Las técnicas más comunes incluyen la rotación de direcciones IP usando redes de proxies, el spoofing de encabezados HTTP (especialmente el User-Agent), el uso de navegadores headless con plugins de stealth y la implementación de retrasos aleatorios entre solicitudes para imitar el comportamiento humano.
Los sitios web bloquean a los scrapers para proteger sus recursos de servidores de ser sobrecargados por tráfico automatizado, para proteger datos propietarios o con derechos de autor y para evitar que los competidores monitoren sus estrategias de precios o contenido. Según Cloudflare, los bots maliciosos pueden consumir un gran ancho de banda y degradar la experiencia del usuario.
¿Cómo funciona la huella digital del navegador en la detección de bots?
La huella digital del navegador recopila detalles específicos sobre el dispositivo del usuario, como la resolución de pantalla, el sistema operativo, las fuentes instaladas y las capacidades del hardware. Al combinar estos puntos de datos, los sistemas de seguridad crean un identificador único que puede rastrear y bloquear a los scrapers incluso si cambian su dirección IP o borran sus cookies.
¿Pueden los navegadores sin interfaz gráfica evadir todos los sistemas de detección?
No. Aunque los navegadores sin interfaz gráfica pueden ejecutar JavaScript y manejar contenido dinámico, las configuraciones predeterminadas son fácilmente detectadas por sistemas de seguridad avanzados como DataDome, que analizan las técnicas de detección de bots incluyendo las variables de WebDriver. Los desarrolladores deben usar modificaciones de stealth para ocultar la naturaleza automatizada del navegador.
¿Cómo debo manejar los CAPTCHAs durante la extracción de datos?
Cuando se encuentran con CAPTCHAs, el enfoque más eficiente para la extracción a gran escala es integrar una API de resolución automatizada como CapSolver. Estos servicios utilizan aprendizaje automático para resolver desafíos de forma programática, permitiendo que el script de extracción continúe su operación sin intervención manual.
Ver más
Web ScrapingApr 22, 2026
Arquitectura de raspado de web para extracción de datos escalable
Aprende una arquitectura de raspado web escalable en Rust con reqwest, scraper, raspado asíncrono, raspado con navegador sin cabeza, rotación de proxies y manejo de CAPTCHA conforme.

Web ScrapingFeb 17, 2026
Cómo resolver Captcha en Nanobot con CapSolver
Automatiza la resolución de CAPTCHA con Nanobot y CapSolver. Utiliza Playwright para resolver reCAPTCHA y Cloudflare autónomamente.


