Cómo los agentes de IA manejan los CAPTCHAs a gran escala

Aloísio Vítor
Image Processing Expert
Resumen
- Los agentes de IA requieren infraestructura robusta para manejar CAPTCHAs a gran escala durante operaciones web automatizadas.
- Los sistemas modernos de validación de tráfico utilizan análisis de comportamiento y huella digital del dispositivo para detectar solicitudes automatizadas.
- Integrar una API confiable para resolver CAPTCHAs asegura operaciones continuas para agentes autónomos.
- Las arquitecturas distribuidas y la rotación de proxies son esenciales para gestionar desafíos de control de riesgo de alto volumen.
- Las políticas de cumplimiento ético y uso responsable deben guiar todos los esfuerzos de recolección de datos automatizados.
Introducción
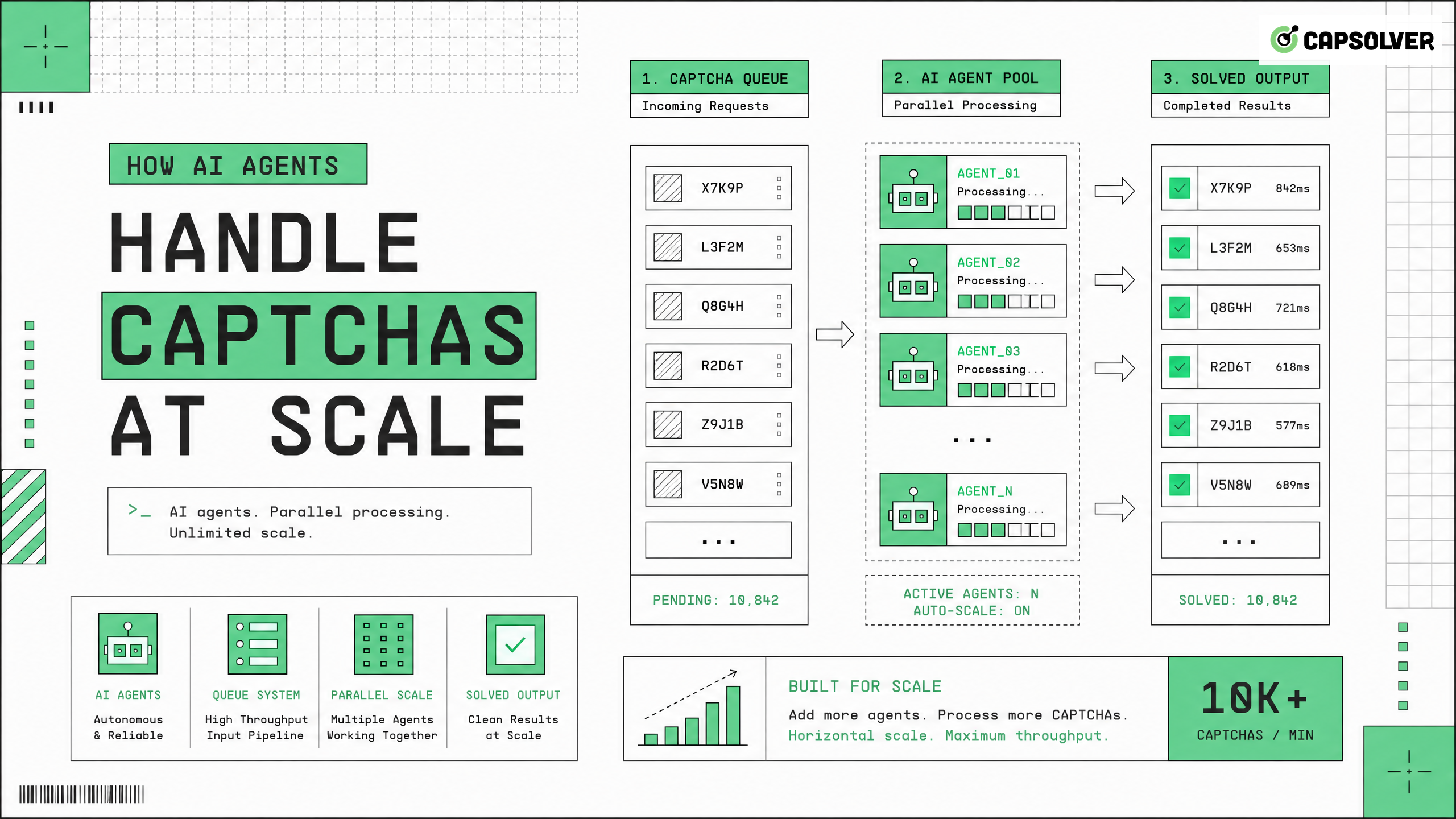
Los sistemas autónomos deben manejar CAPTCHAs a gran escala de manera eficiente para mantener operaciones web continuas. A medida que los sitios web implementan medidas de validación de tráfico más estrictas, los scripts de automatización tradicionales fallan con frecuencia al enfrentarse a desafíos complejos de control de riesgo. Los agentes de IA resuelven este problema integrando infraestructura especializada diseñada para procesar estos desafíos automáticamente. CapSolver proporciona los puntos finales de API y modelos de aprendizaje automático necesarios para procesar solicitudes de alto volumen de manera confiable. Al delegar el proceso de validación a un servicio dedicado, los desarrolladores pueden enfocarse en la lógica del agente principal en lugar de mantener pilas de automatización de navegadores complejas. Este enfoque asegura altas tasas de éxito mientras se cumple con los límites de velocidad de los sitios objetivo y las directrices de uso responsable.
La evolución de la validación de tráfico
Los sistemas de seguridad web han evolucionado desde la reconocimiento de texto simple hasta análisis de comportamiento complejo. Los primeros sistemas de CAPTCHA dependían de texto distorsionado, que el reconocimiento óptico de caracteres (OCR) podía procesar fácilmente. Hoy en día, las plataformas de control de riesgo evalúan movimientos del mouse, huellas digitales del navegador y reputación de red para diferenciar entre usuarios humanos y scripts automatizados.
Cuando los agentes de IA manejan CAPTCHAs a gran escala, deben navegar por estas capas de validación avanzadas. Los desafíos modernos a menudo requieren ejecutar JavaScript, renderizar imágenes complejas o resolver acertijos espaciales. Esta complejidad exige recursos computacionales significativos y algoritmos especializados. Para los desarrolladores que construyen sistemas autónomos, gestionar esta infraestructura internamente se convierte en un gran desafío de ingeniería.
Para comprender los mecanismos subyacentes, los investigadores a menudo se refieren a las directrices de W3C sobre alternativas a CAPTCHA, que detallan las implicaciones de accesibilidad y seguridad de las pruebas de Turing automatizadas.
Infraestructura básica para agentes autónomos
Construir la infraestructura adecuada es crucial para sistemas que manejan CAPTCHAs a gran escala. Una arquitectura efectiva separa la lógica del agente principal del proceso de validación. Esta separación de responsabilidades permite que cada componente se escale independientemente según las demandas de trabajo.
Gestión de navegadores sin cabeza
Los agentes de IA dependen con frecuencia de navegadores sin cabeza para interactuar con aplicaciones web modernas. Estos navegadores deben configurarse cuidadosamente para evitar la detección por parte de los sistemas de control de riesgo. Una gestión adecuada incluye la rotación de agentes de usuario, la modificación de propiedades del navegador y el manejo de la huella digital del lienzo. Puede obtener más información sobre ¿qué es la detección de navegadores sin cabeza y cómo evitarla? en nuestro guía detallada.
Redes de proxies y reputación de IP
La reputación de red juega un papel crucial en la validación de tráfico. Cuando los sistemas manejan CAPTCHAs a gran escala, deben distribuir las solicitudes entre direcciones IP diversas para evitar límites de velocidad. Proxies de alta calidad residenciales o móviles proporcionan la reputación necesaria para pasar las primeras verificaciones de seguridad. Combinar la rotación de proxies con una API confiable para resolver CAPTCHAs para agentes autónomos crea una pila de automatización resistente.
Procesamiento asíncrono
Los desafíos de validación introducen latencia variable en los flujos de trabajo automatizados. Un desafío puede tardar desde unos segundos hasta más de un minuto en resolverse. Los agentes deben implementar patrones de procesamiento asíncrono para manejar esta latencia sin bloquear otras operaciones. Colas de mensajes y arquitecturas orientadas a eventos son soluciones estándar para gestionar estos flujos de trabajo asíncronos.
Técnicas avanzadas para la validación de tráfico
A medida que los sistemas de control de riesgo se vuelven más sofisticados, las técnicas utilizadas para procesarlos también deben avanzar. Cuando las organizaciones manejan CAPTCHAs a gran escala, emplean una variedad de métodos avanzados para garantizar altas tasas de éxito.
Simulación de comportamiento
Algunos sistemas de validación monitorean cómo un usuario interactúa con la página. Para pasar estas verificaciones, los agentes deben simular un comportamiento humano, incluyendo movimientos de mouse realistas, velocidades de escritura variadas y patrones naturales de desplazamiento. Implementar estas simulaciones requiere un profundo conocimiento de las métricas de interacción humano-computadora. El último estudio sobre biometría de comportamiento destaca la creciente sofisticación de estos mecanismos de detección.
Mitigación de la huella digital del dispositivo
Las plataformas de control de riesgo recopilan datos extensos sobre el dispositivo cliente, incluyendo resolución de pantalla, fuentes instaladas y concurrencia de hardware. Para manejar CAPTCHAs a gran escala, los agentes deben presentar huellas digitales de dispositivo consistentes y realistas. Esto implica inyectar scripts personalizados en el entorno del navegador para reemplazar propiedades predeterminadas y presentar un perfil unificado.
Canjea tu código de bonificación de CapSolver
¡Aumenta tu presupuesto de automatización instantáneamente!
Usa el código de bonificación CAP26 al recargar tu cuenta de CapSolver para obtener un 5% adicional de bonificación en cada recarga — sin límites.
Canjéalo ahora en tu Panel de CapSolver

Integración de modelos de aprendizaje automático
Los agentes de IA avanzados manejan CAPTCHAs a gran escala utilizando modelos de aprendizaje automático especializados. Estos modelos se entrenan en grandes conjuntos de datos de desafíos de validación, lo que les permite reconocer patrones y resolver acertijos con alta precisión.
Visión por computadora para desafíos de imagen
Los desafíos basados en imágenes requieren algoritmos avanzados de visión por computadora. Los modelos de detección de objetos identifican elementos específicos dentro de una cuadrícula, mientras que los modelos de segmentación delinean formas complejas. Entrenar estos modelos requiere actualizaciones continuas para adaptarse a nuevos tipos de desafíos introducidos por proveedores de control de riesgo.
Procesamiento de desafíos de audio
Por razones de accesibilidad, muchos sistemas de validación ofrecen alternativas de audio. Los agentes pueden manejar CAPTCHAs a gran escala procesando estos archivos de audio utilizando modelos de reconocimiento de voz. Este enfoque suele proporcionar un camino más confiable cuando los desafíos visuales se vuelven demasiado complejos. El evaluaciones de reconocimiento de voz del NIST proporcionan benchmarks para la precisión de estos modelos.
Para una visión general completa de los componentes necesarios, revise la pila de infraestructura de automatización web para agentes de IA.
Gestión de operaciones de alto volumen
Cuando las organizaciones necesitan manejar CAPTCHAs a gran escala, la eficiencia operativa se convierte en primordial. Procesar miles de solicitudes por minuto requiere manejo de errores robusto, lógica de reintentos y monitoreo de rendimiento.
Manejo de errores y reintentos
Los desafíos de validación pueden fallar por múltiples razones, incluyendo tiempos de espera de red, prohibiciones de proxy o inexactitudes de modelos. Los agentes deben implementar mecanismos de reintentos inteligentes con retroalimentación exponencial para manejar estos fallos de manera elegante. Es esencial distinguir entre problemas de red temporales y bloqueos permanentes para optimizar el uso de recursos.
Monitoreo de rendimiento
Monitorear la tasa de éxito y la latencia del procesamiento de validación es crucial. Los dashboards deben rastrear métricas como el tiempo promedio de resolución, las tasas de error por tipo de desafío y el rendimiento de los proxies. Estos datos permiten a los equipos de ingeniería identificar cuellos de botella y optimizar su infraestructura. Elegir un solucionador de CAPTCHA para infraestructura de agentes 2026 requiere una evaluación cuidadosa de estas métricas de rendimiento.
El papel de las APIs en sistemas autónomos
Las APIs proporcionan el tejido conectivo que permite a los agentes interactuar con servicios externos. Cuando los sistemas manejan CAPTCHAs a gran escala, dependen de APIs especializadas para transferir la carga computacional del procesamiento de validación.
APIs síncronas frente a asíncronas
Las APIs de validación pueden ser síncronas o asíncronas. Las APIs síncronas bloquean al agente hasta que se resuelve el desafío, lo que puede provocar cuellos de botella de rendimiento. Las APIs asíncronas permiten al agente enviar un desafío y consultar el resultado más tarde, mejorando el rendimiento general.
Límites de velocidad y cuotas de API
Cuando los agentes manejan CAPTCHAs a gran escala, deben gestionar cuidadosamente los límites de velocidad y cuotas de API. Exceder estos límites puede resultar en prohibiciones temporales o en un rendimiento degradado. Implementar algoritmos de cubo de tokens y colas de solicitudes ayuda a garantizar el cumplimiento de las políticas de uso de API. Para más detalles, consulte nuestro guía sobre infraestructura para resolver CAPTCHA para agentes de IA.
Escalado de flujos de trabajo de recolección de datos
La recolección de datos es un caso de uso principal para agentes autónomos. A medida que el volumen de datos aumenta, los sistemas deben escalar en consecuencia. Cuando los agentes manejan CAPTCHAs a gran escala, permiten a las organizaciones recopilar inteligencia competitiva, monitorear tendencias del mercado y agrupar información pública de manera eficiente.
Arquitecturas de raspado distribuidas
Para procesar millones de páginas, los agentes suelen desplegarse en clústeres distribuidos. Cada nodo del clúster opera de forma independiente, obteniendo páginas y procesando desafíos de validación según sea necesario. Este enfoque distribuido asegura que el sistema pueda manejar CAPTCHAs a gran escala sin crear un punto único de fallo.
Normalización y almacenamiento de datos
Una vez que los datos se recopilan, deben normalizarse y almacenarse para su análisis. Los agentes suelen integrarse con pipelines de datos que limpian y estructuran el HTML crudo antes de insertarlo en una base de datos. Este pipeline debe ser resistente a interrupciones causadas por desafíos de validación.
Consideraciones de seguridad para la infraestructura de agentes
La seguridad es una preocupación crítica al desplegar agentes autónomos. Los sistemas que manejan CAPTCHAs a gran escala deben proteger credenciales sensibles, claves de API y configuraciones de proxies contra el acceso no autorizado.
Gestión de credenciales
Los agentes nunca deben codificar en sus fuentes las credenciales. En su lugar, deben usar sistemas de gestión de secretos seguros para recuperar claves de API y contraseñas de proxy en tiempo de ejecución. Esta práctica minimiza el riesgo de exposición de credenciales si el código base se compromete.
Seguridad de red
La comunicación entre el agente y la API de validación debe estar encriptada usando TLS. Esta encriptación previene ataques de hombre en el medio y asegura la integridad de los tokens de validación. Las organizaciones también deben monitorear su tráfico de red en busca de anomalías que puedan indicar una brecha de seguridad.
Comparación de enfoques para el procesamiento de validación
| Enfoque | Escalabilidad | Carga de mantenimiento | Tasa de éxito | Caso de uso ideal |
|---|---|---|---|---|
| Modelos de ML internos | Alta | Muy alta | Variable | Desafíos especializados y propietarios |
| Equipos de resolución manual | Baja | Alta | Alta | Tareas de bajo volumen y altamente complejas |
| Servicios API automatizados | Muy alta | Baja | Muy alta | Desafíos de alto volumen y estándar |
| Extensiones de navegador | Baja | Media | Media | Automatización de escritorio, pruebas |
Cumplimiento y uso responsable
La recolección de datos automatizada debe siempre cumplir con estándares legales y éticos. Cuando los sistemas manejan CAPTCHAs a gran escala, interactúan con infraestructura de terceros que tiene términos de servicio específicos. Las organizaciones deben asegurarse de que sus prácticas de automatización cumplan con las regulaciones pertinentes, como el RGPD y la CCPA.
El uso responsable incluye respetar las directivas de robots.txt, implementar límites de velocidad razonables y evitar interrumpir el servicio objetivo. El guías de la Electronic Frontier Foundation sobre acceso automatizado proporcionan contexto valioso para mantener estándares éticos en el raspado web. Para más información sobre la construcción de sistemas cumplidores, explore nuestro guía sobre infraestructura de protección contra bots para agentes de IA.
Tendencias futuras en la validación de tráfico
El panorama de la seguridad web está en constante evolución. A medida que los agentes de IA se vuelven más sofisticados, los sistemas de control de riesgo se adaptarán para detectarlos. Las organizaciones que manejan CAPTCHAs a gran escala deben mantenerse al día con estas tendencias para mantener operaciones continuas.
Arquitecturas de confianza cero
Las arquitecturas de confianza cero asumen que todo el tráfico es potencialmente malicioso. Estos sistemas requieren validación continua durante toda la sesión del usuario, en lugar de una verificación única al iniciar sesión. Los agentes necesitarán adaptarse a estos modelos de validación continua para mantener el acceso.
Validación que preserva la privacidad
Nuevos métodos de validación están emergiendo que priorizan la privacidad del usuario. Estos métodos utilizan pruebas criptográficas para verificar la interacción humana sin recopilar datos sensibles. A medida que estas tecnologías maduren, los agentes necesitarán integrar nuevos protocolos para manejar CAPTCHAs a gran escala. El especificaciones de IETF sobre pass privado establecen las bases técnicas para estos nuevos mecanismos de validación.
Conclusión
Construir sistemas que manejen eficientemente CAPTCHAs a gran escala es esencial para la automatización web moderna. Al separar el procesamiento de validación de la lógica del agente principal y utilizar APIs especializadas, los desarrolladores pueden lograr altas tasas de éxito y mantener operaciones continuas. Implementar un manejo robusto de errores, gestión de proxies y procesamiento asíncrono asegura que los sistemas autónomos puedan navegar por entornos complejos de control de riesgo de manera confiable. Para procesamiento de validación de nivel empresarial, CapSolver ofrece la infraestructura y capacidades de aprendizaje automático necesarias para respaldar implementaciones a gran escala de agentes de IA.
Preguntas frecuentes
¿Cuál es la forma más eficiente de procesar los desafíos de validación?
Usar un servicio de API dedicado es generalmente la forma más eficiente. Transfiere la carga computacional y los requisitos de mantenimiento a infraestructura especializada, permitiendo a tus agentes enfocarse en sus tareas principales.
¿Cómo afectan las redes de proxies a las tasas de éxito de validación?
Las redes de proxies son críticas para distribuir las solicitudes y mantener una buena reputación de IP. Los proxies residenciales de alta calidad reducen la probabilidad de activar medidas de control de riesgo avanzadas, mejorando así las tasas de éxito generales.
¿Pueden los sistemas autónomos simular el comportamiento humano?
Sí, los sistemas avanzados pueden simular movimientos del mouse similares a los humanos, patrones de escritura y comportamiento de desplazamiento. Esta simulación es a menudo necesaria para pasar las verificaciones de análisis de comportamiento implementadas por plataformas de seguridad modernas.
¿Cuáles son las consideraciones legales para operaciones web automatizadas?
Las operaciones automatizadas deben cumplir con las regulaciones de privacidad de datos, los términos de servicio y las leyes de derechos de autor. Es esencial implementar prácticas responsables de raspado, respetar los límites de tasa y evitar causar daño a la infraestructura objetivo.
¿Cómo resuelven los modelos de aprendizaje automático los desafíos de imágenes?
Los modelos de aprendizaje automático utilizan técnicas de visión por computadora, como la detección de objetos y la segmentación de imágenes, para analizar y resolver acertijos visuales. Estos modelos se entrenan continuamente con nuevos datos para mantener una alta precisión frente a tipos de desafíos en evolución.
Ver más
AIJun 26, 2026
CAPTCHA: El componente faltante en la infraestructura de agentes de IA
Descubre por qué gestionar la validación del tráfico es el componente faltante en la infraestructura de agentes de IA. Aprende cómo integrar soluciones robustas para agentes autónomos.
AIJun 26, 2026
Resolviendo CAPTCHA para Agentes de IA basados en navegador
- Los agentes de IA basados en navegador requieren una infraestructura robusta para gestionar desafíos complejos de validación de tráfico. - Integrar una API de CAPTCHA confiable garantiza una operación continua para tareas web automatizadas. - La infraestructura adecuada de protección contra bots es esencial para mantener el cumplimiento y el uso responsable. - Seleccionar el solucionador de CAPTCHA adecuado implica evaluar velocidad, precisión y capacidades de integración.