C# is a versatile programming language widely used in enterprise-level projects and applications. With its roots in the C family, it boasts efficiency and power, making it an invaluable addition to any developer's toolkit.
Thanks to its widespread use, C# offers a plethora of tools that empower developers to solve sophisticated solutions, and web scraping is no exception.
In this tutorial, we’ll walk you through creating a straightforward web scraper using C# and its user-friendly scraping libraries. Additionally, we’ll reveal a nifty trick to help you avoid getting blocked with just a single line of code. Are you ready? Let's go!
Table of Contents
Introduction to Web Scraping
Why Choose C# Over C for Web Scraping?
Setting Up Your Environment
Prerequisites
Installing Libraries
Creating a C# Web Scraping Project in Visual Studio
Basic Web Scraping with C#
Making HTTP Requests
Parsing HTML Content
Advanced HTML Parsing
How to Handle Scraped Data
Handling CAPTCHAs in Web Scraping
Integrating CAPTCHA Solvers
Sample Code for CapSolver
Conclusion
1. Introduction to Web Scraping
Web scraping is the process of automatically extracting information from websites. This can be done for various purposes, including data analysis, market research, and competitive intelligence. However, many websites implement mechanisms to detect and block automated scraping attempts, making it essential to use sophisticated techniques to avoid getting blocked.
Why Choose C# Over C for Web Scraping?
Web scraping often involves interacting with web elements, managing HTTP requests, and handling data extraction and parsing. While C is a powerful and efficient language, it lacks the built-in libraries and modern features that make web scraping easier and more efficient. Here are a few reasons why C# is a better choice for web scraping:
Rich Libraries: C# has extensive libraries such as HtmlAgilityPack for HTML parsing and Selenium for browser automation, simplifying the scraping process.
Asynchronous Programming: C#'s async and await keywords allow for efficient asynchronous operations, essential for handling multiple web requests simultaneously.
Ease of Use : C#'s syntax is more modern and user-friendly compared to C, making the development process faster and less error-prone.
Integration: C# integrates seamlessly with the .NET framework, providing powerful tools and services for building robust applications.
Struggling with the repeated failure to completely solve the irritating captcha?
Discover seamless automatic captcha solving with Capsolver AI-powered Auto Web Unblock technology!
Claim Your Bonus Code for top captcha solutions;
: WEBS. After redeeming it, you will get an extra 5% bonus after each recharge, Unlimited
2. Setting Up Your Environment
Before we start scraping, we need to set up our development environment. Here’s how you can do it:
Prerequisites
Visual Studio: the free Community edition of Visual Studio 2022 will be fine.
.NET 6+: any LTS version greater than or equal to 6 will do.
HtmlAgilityPack library for HTML parsing
RestSharp library for making HTTP requests
Creating a C# Web Scraping Project in Visual Studio
Setting Up a Project in Visual Studio
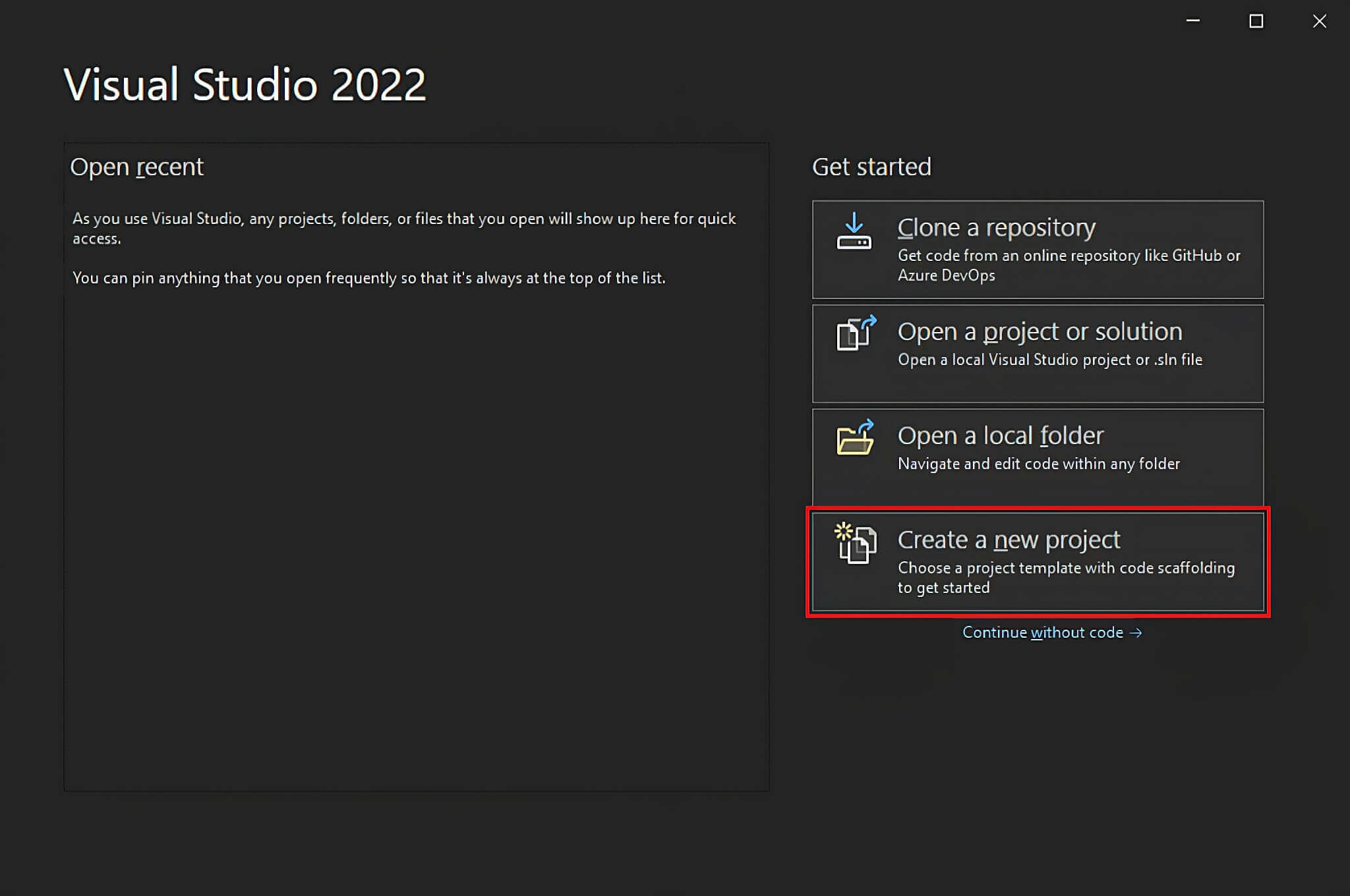
Open Visual Studio and click on the “Create a new project” option.
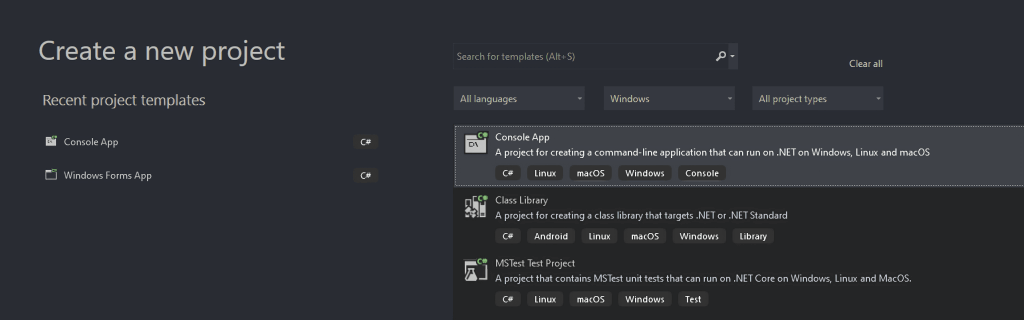
In the “Create a new project” window, select the “C#” option from the dropdown list. After specifying the programming language, select the “Console App” template, and click “Next”.
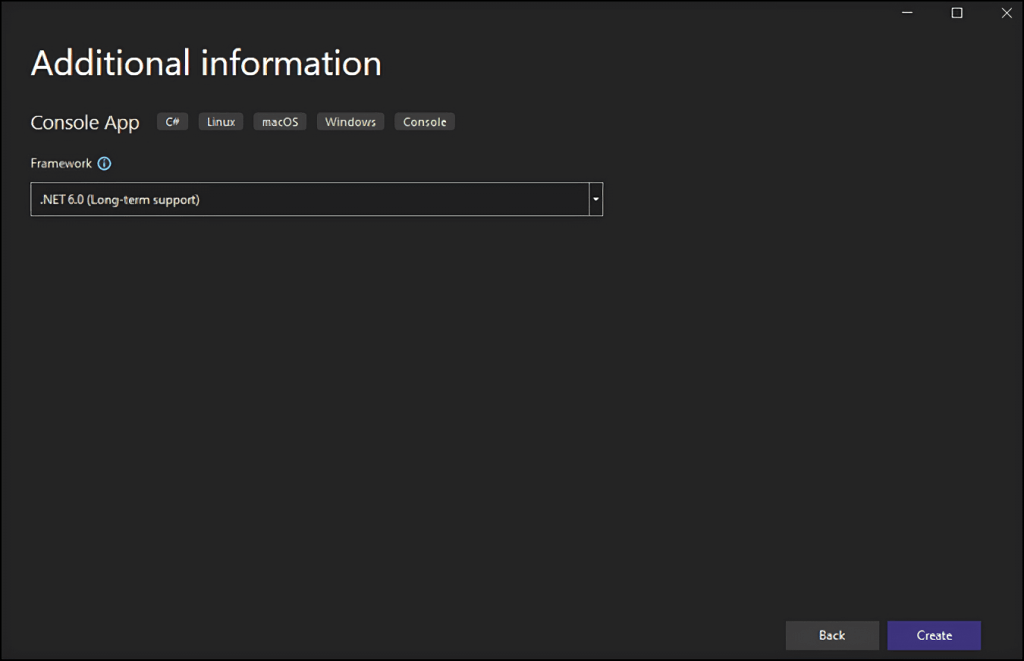
Name your project StaticWebScraping, click “Select”, and choose the .NET version. If you have installed .NET 6.0, Visual Studio should already select it for you.
Click the “Create” button to initialize your C# web scraping project. Visual Studio will initialize a StaticWebScraping folder containing an App.cs file. This file will store your web scraping logic in C#:
csharpCopy
namespace WebScraping {
public class Program {
public static void Main() {
// scraping logic...
}
}
}
Now it’s time to understand how to build a web scraper in C#!
3. Basic Web Scraping with C#
In this section, we will create a C# application that makes HTTP requests to a website, fetches the HTML content, and parses it to extract information.
Making HTTP Requests
First, let’s create a basic C# application that makes HTTP requests to a website and fetches the HTML content.
csharpCopy
using System;
using RestSharp;
class Program
{
static void Main()
{
// Create a new RestClient instance with the target URL
var client = new RestClient("https://www.example.com");
// Create a new RestRequest instance with the GET method
var request = new RestRequest(Method.GET);
// Execute the request and get the response
IRestResponse response = client.Execute(request);
// Check if the request was successful
if (response.IsSuccessful)
{
// Print the HTML content of the response
Console.WriteLine(response.Content);
}
else
{
Console.WriteLine("Failed to retrieve content");
}
}
}
Parsing HTML Content
Next, we will use the HtmlAgilityPack to parse the HTML content and extract the information we need.
csharpCopy
using HtmlAgilityPack;
using System;
using RestSharp;
class Program
{
static void Main()
{
// Create a new RestClient instance with the target URL
var client = new RestClient("https://www.example.com");
// Create a new RestRequest instance with the GET method
var request = new RestRequest(Method.GET);
// Execute the request and get the response
IRestResponse response = client.Execute(request);
// Check if the request was successful
if (response.IsSuccessful)
{
// Load the HTML content into HtmlDocument
var htmlDoc = new HtmlDocument();
htmlDoc.LoadHtml(response.Content);
// Select the nodes that match the specified XPath query
var nodes = htmlDoc.DocumentNode.SelectNodes("//h1");
// Loop through the selected nodes and print their inner text
foreach (var node in nodes)
{
Console.WriteLine(node.InnerText);
}
}
else
{
Console.WriteLine("Failed to retrieve content");
}
}
}
Advanced HTML Parsing
Let’s take it a step further by scraping more complex data from a sample website. Assume we want to scrape a list of articles with titles and links from a blog page.
csharpCopy
using HtmlAgilityPack;
using System;
using RestSharp;
class Program
{
static void Main()
{
// Create a new RestClient instance with the target URL
var client = new RestClient("https://www.example.com/blog");
// Create a new RestRequest instance with the GET method
var request = new RestRequest(Method.GET);
// Execute the request and get the response
IRestResponse response = client.Execute(request);
// Check if the request was successful
if (response.IsSuccessful)
{
// Load the HTML content into HtmlDocument
var htmlDoc = new HtmlDocument();
htmlDoc.LoadHtml(response.Content);
// Select the nodes that match the specified XPath query
var nodes = htmlDoc.DocumentNode.SelectNodes("//div[@class='post']");
// Loop through the selected nodes and extract titles and links
foreach (var node in nodes)
{
var titleNode = node.SelectSingleNode(".//h2/a");
var title = titleNode.InnerText;
var link = titleNode.Attributes["href"].Value;
Console.WriteLine("Title: " + title);
Console.WriteLine("Link: " + link);
Console.WriteLine();
}
}
else
{
Console.WriteLine("Failed to retrieve content");
}
}
}
In this example, we scrape a blog page, selecting each article’s title and link. The XPath query //div[@class='post'] is used to locate the individual posts.
4. How to Handle Scraped Data
Store it in a database for easy querying whenever needed.
Convert it into JSON format and use it to call various APIs.
Transform it into human-readable formats like CSV, which can be opened with Excel.
These are just a few examples. The key point is that once you have the scraped data in your code, you can utilize it as you see fit. Typically, scraped data is converted into a more useful format for your marketing, data analysis, or sales teams.
However, keep in mind that web scraping comes with its own set of challenges.
5. Handling CAPTCHAs in Web Scraping
One of the biggest challenges in web scraping is dealing with CAPTCHAs, which are designed to differentiate human users from bots. If you encounter a CAPTCHA, your scraping script will need to solve it to proceed. Especially if you want to scale up your web scraping, CapSolver exists to help you through its high accuracy and fast solving of whatever CAPTCHA you may encounter.
Integrating CAPTCHA Solvers
There are several CAPTCHA solving services available that can be integrated into your scraping script. Here, we will use the CapSolver service. First, you need to sign up for CapSolver and get your API key.
Step. 1: Sign up for CapSolver
Before you are ready to use CapSolver's services, you need to go to the user panel and register your account.
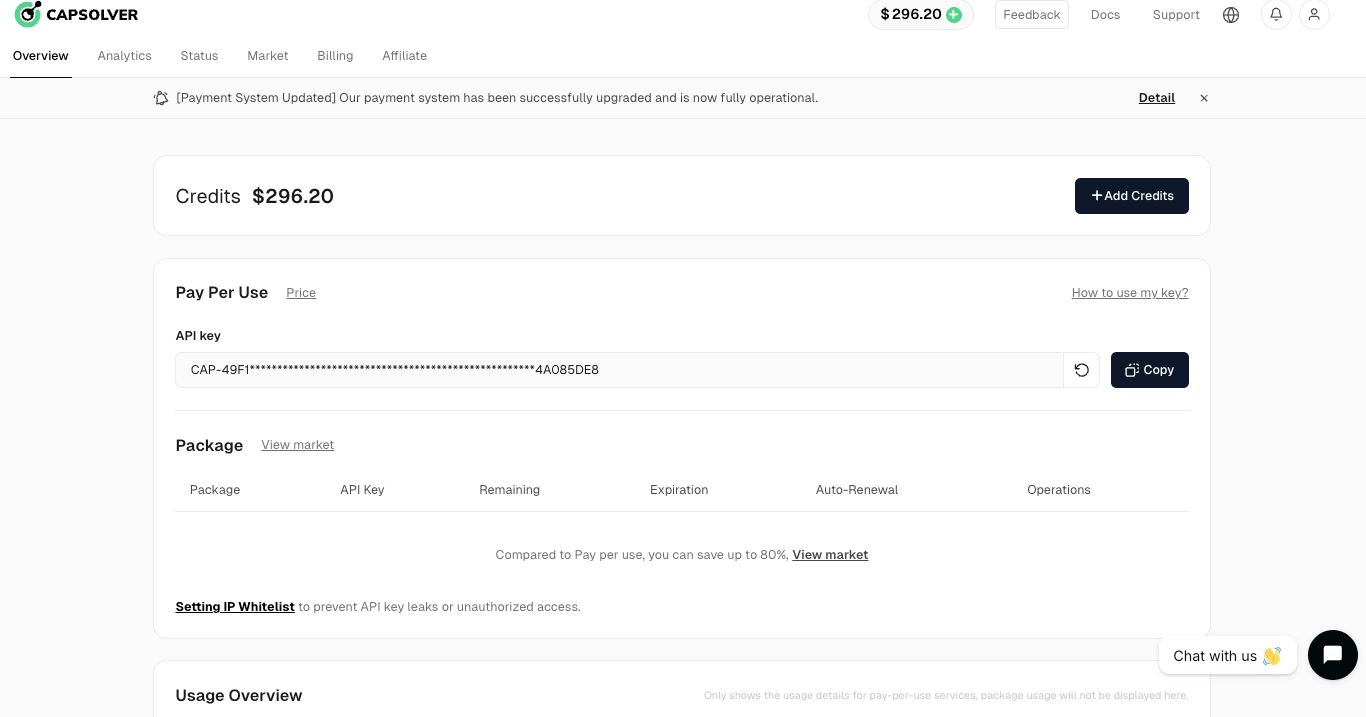
Step. 2: Get your API Key
Once you have registered, you can obtain your api key from the home page panel
Sample Code for CapSolver
Using CapSolver in your web scraping or automation project is simple. Here’s a quick example in Python to demonstrate how you can integrate CapSolver into your workflow:
pythonCopy
# pip install requests
import requests
import time
# TODO: set your config
api_key = "YOUR_API_KEY" # your api key of capsolver
site_key = "6Le-wvkSAAAAAPBMRTvw0Q4Muexq9bi0DJwx_mJ-" # site key of your target site
site_url = "" # page url of your target site
def capsolver():
payload = {
"clientKey": api_key,
"task": {
"type": 'ReCaptchaV2TaskProxyLess',
"websiteKey": site_key,
"websiteURL": site_url
}
}
res = requests.post("https://api.capsolver.com/createTask", json=payload)
resp = res.json()
task_id = resp.get("taskId")
if not task_id:
print("Failed to create task:", res.text)
return
print(f"Got taskId: {task_id} / Getting result...")
while True:
time.sleep(3) # delay
payload = {"clientKey": api_key, "taskId": task_id}
res = requests.post("https://api.capsolver.com/getTaskResult", json=payload)
resp = res.json()
status = resp.get("status")
if status == "ready":
return resp.get("solution", {}).get('gRecaptchaResponse')
if status == "failed" or resp.get("errorId"):
print("Solve failed! response:", res.text)
return
token = capsolver()
print(token)
In this example, the capsolver function sends a request to CapSolver’s API with the necessary parameters and returns the CAPTCHA solution. This simple integration can save you countless hours and effort in manually solving CAPTCHAs during web scraping and automation tasks.
6. Conclusion
Web scraping in C# empowers developers with a robust framework to automate data extraction from websites efficiently. By leveraging libraries like HtmlAgilityPack and RestSharp, along with CAPTCHA-solving services such as CapSolver, developers can navigate through web pages, parse HTML content, and handle challenges seamlessly. This capability not only streamlines data collection processes but also ensures compliance with ethical scraping practices, enhancing the reliability and scalability of web scraping projects in diverse applications.