







What Is Web Scraping | Common Use Cases and Issues

Ethan Collins
Pattern Recognition Specialist
05-Jul-2024

You may have heard an saying about data being called the new oil in the present information society. Due to the sheer volume of information available online, the ability to effectively collect and analyze web data has become a key skillset for businesses, researchers and developers. This is where web scraping comes into play. Web scraping, also known as web data extraction, is a powerful technology used to automatically collect information from websites. Imagine being able to get a lot of key information from a website without having to manually copy and paste data, but web scraping must be used with care and compliance. This blog will briefly introduce web scraping and address some of the issues you may encounter. It will also talk about some common cases
Understanding Web Scraping
Web scraping involves using automated software tools, known as web scrapers, to collect data from web pages. These tools simulate human browsing behavior, allowing them to navigate websites, click on links, and extract information from HTML content. The data extracted can include text, images, links, and other multimedia elements. Once collected, the data can be stored in databases or spreadsheets for further analysis.
Web scrapers operate by sending HTTP requests to websites and parsing the HTML responses. They can be programmed to follow links, handle pagination, and even interact with complex web applications. Popular programming languages for web scraping include Python, with libraries like BeautifulSoup, Scrapy, and Selenium, which offer robust functionalities for data extraction and web automation.
Redeem Your CapSolver Bonus Code
Boost your automation budget instantly!
Use bonus code CAPN when topping up your CapSolver account to get an extra 5% bonus on every recharge — with no limits.
Redeem it now in your CapSolver Dashboard
.
The Legality of Web Scraping
One of the most common misconceptions about web scraping is that it's illegal. This isn't accurate!
Web scraping is perfectly legal as long as you follow certain guidelines: adhere to the CCPA and GDPR regulations, avoid accessing data protected by login credentials, and stay clear of collecting any personally identifiable information. However, this doesn't grant free rein to scrape any website indiscriminately. Ethical considerations are crucial, meaning you should always respect the site's terms of service, robots.txt file, and privacy policies.

In essence, web scraping itself is not against the law, but it is important to adhere to specific rules and ethical standards.
Web Scraping Use Cases
In today's data-driven world, the value of data has surpassed that of oil, and the Web is an abundant source of valuable information. Numerous companies across various industries leverage data extracted through web scraping to enhance their business operations.
While there are countless applications of web scraping, here are some of the most prevalent ones:
Price Comparison
Using web scraping tools, businesses and consumers can gather product prices from different retailers and online platforms. This data can be used to compare prices, find the best deals, and save both time and money. Additionally, it enables companies to keep an eye on their competitors' pricing strategies.
Market Monitoring
Web scraping allows businesses to track market trends, product availability, and price changes in real-time. By staying updated with the latest market information, companies can quickly adapt their strategies, seize new opportunities, and respond to evolving customer demands. This proactive approach helps maintain a competitive edge.
Competitor Analysis
By collecting data on competitors' products, pricing, promotions, and customer feedback, businesses can gain valuable insights into their competitors' strengths and weaknesses. Automated tools can also capture snapshots of competitors' websites and marketing efforts, providing a comprehensive view for developing strategies to outperform them.
Lead Generation
Web scraping has revolutionized lead generation, transforming what used to be a labor-intensive process into an automated one. By extracting publicly available contact information such as email addresses and phone numbers, businesses can quickly build a database of potential leads. This streamlined approach accelerates the lead generation process.
Sentiment Analysis
Web scraping enables sentiment analysis by extracting user feedback from review sites and social media platforms. Analyzing this data helps businesses understand public opinion about their products, services, and brand. By gaining insights into customer sentiments, companies can improve customer satisfaction and address issues proactively.
Content Aggregation
Web scraping can be used to aggregate content from various sources into a single platform. This is particularly useful for news websites, blogs, and research portals that need to provide up-to-date information from multiple sources. By automating content collection, businesses can save time and ensure their platforms remain current.
Real Estate Listings
Web scraping is also used in the real estate industry to gather property listings from various websites. This data helps real estate agencies and potential buyers compare properties, analyze market trends, and make informed decisions. Automating the collection of real estate data provides a comprehensive view of the market.
Types of Web Scrapers
Web scrapers come in various forms, each tailored to different purposes and user needs. Generally, they can be categorized into four main types, each offering unique functionalities and benefits:
- Desktop Scrapers
Desktop scrapers are standalone software applications installed directly onto a user's computer. These tools often provide a no-code, user-friendly interface that allows users to extract data through simple point-and-click interactions. Desktop scrapers are equipped with features like task scheduling, data parsing, and export options, catering to both beginners and advanced users. They are suitable for medium-scale scraping tasks and offer a good balance between functionality and ease of use.
- Custom-built Scrapers
Custom-built scrapers are highly flexible solutions developed by programmers using various technologies. These scrapers are designed to meet specific data extraction requirements, making them ideal for complex and large-scale projects. Due to their bespoke nature, custom-built scrapers can handle intricate web structures, navigate dynamic content, and extract data from multiple sources efficiently. They are the go-to choice for businesses requiring tailored scraping solutions that can be easily scaled and adapted to evolving needs.
- Browser Extension Scrapers
Browser extension scrapers are add-ons for popular web browsers such as Chrome, Firefox, and Safari. These extensions enable users to scrape data directly while browsing websites. By using an intuitive point-and-click interface, users can easily select and extract data elements from web pages. Although browser extension scrapers are effective for quick, small-scale tasks, they often come with limitations in terms of functionality and scalability compared to other types of scrapers.
- Cloud-based Scrapers
Cloud-based scrapers operate in the cloud, providing scalable and distributed scraping solutions. These scrapers are well-suited for handling large-scale data extraction tasks and often come with built-in data processing and storage capabilities. Users can access cloud-based scrapers remotely, schedule scraping tasks, and manage data extraction without the need for local infrastructure. While they offer robust capabilities for high-volume scraping, their flexibility in handling complex and dynamic web content may be less than that of custom-built scrapers.
When selecting a web scraper, it is essential to consider the complexity of the task, the volume of data to be collected, and the project's scalability and technical requirements. Each type of scraper has its own strengths and use cases, and the choice will depend on the specific needs of the user or organization.
Overcoming Challenges in Web Scraping
Web scraping, while powerful, also presents huge obstacles due to the rapidly changing internet environment and protections employed by websites, it's not a simple task, and there's a high probability that you'll run into the following types of issues
The primary difficulty in web scraping stems from the reliance on a webpage’s HTML structure. Whenever a website updates its user interface, the HTML elements containing the desired data may change, rendering your scraper ineffective. Adapting to these changes requires constant maintenance and updating of your scraping logic. Using robust HTML element selectors that adapt to minor UI changes can mitigate this issue, but there is no one-size-fits-all solution.
Unfortunately, more complexity is yet to come, and much more complex than maintenance.
Websites deploy sophisticated technologies to protect their data from automated scrapers. These systems can detect and red light for automated requests, posing a significant obstacle. Here are some common challenges scrapers face:
- IP Bans: Servers monitor incoming requests for suspicious patterns. Detecting automated software often leads to IP blacklisting, preventing further access to the site.
- Geo-Restrictions: Some websites restrict access based on the user's geographical location. This can either block foreign users from accessing certain content or present different data based on location, complicating the scraping process.
- Rate Limiting: Making too many requests in a short time frame can trigger DDoS protection measures or IP bans, disrupting the scraping operation.
- CAPTCHAs: Websites often use CAPTCHAs to distinguish between humans and bots, especially if suspicious activity is detected. Solving CAPTCHAs programmatically is highly challenging, often thwarting automated scrapers.
While solving the first three problems can be solved by changing proxies or using a fingerprinting browser, the latter captcha requires complex workarounds that usually have inconsistent results or can only be solved in a short period of time. Regardless of the technique used, these obstacles undermine the effectiveness and stability of any web scraping tool.
Thankfully, there is a solution to this issue, and it is CapSolver, which offers comprehensive solutions to these challenges. CapSolver specializes in CAPTCHA resolution and effectively helps web scraping with advanced technology to ensure stable and effective web scraping. By integrating CapSolver into your scraping workflow, you can overcome these challenges, here are some basic steps.
Integrating CAPTCHA Solvers
There are several CAPTCHA solving services available that can be integrated into your scraping script. Here, we will use the CapSolver service. First, you need to sign up for CapSolver and get your API key.
Step. 1: Sign up for CapSolver
Before you are ready to use CapSolver's services, you need to go to the user panel and register your account.
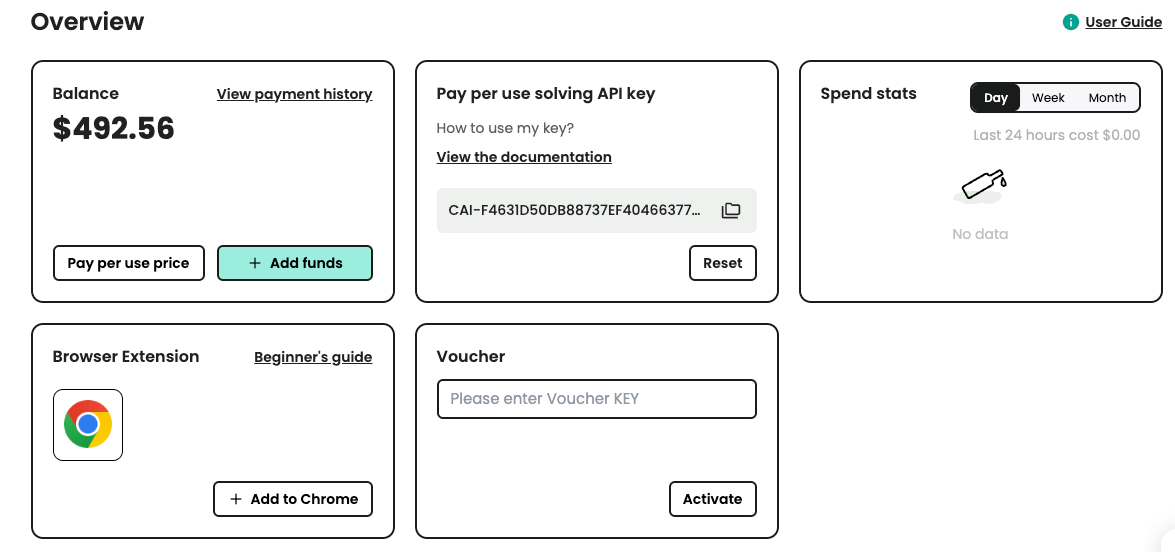
Step. 2: Get your API Key
Once you have registered, you can obtain your api key from the home page panel
Sample Code for CapSolver
Using CapSolver in your web scraping or automation project is simple. Here’s a quick example in Python to demonstrate how you can integrate CapSolver into your workflow:
python
# pip install requests
import requests
import time
# TODO: set your config
api_key = "YOUR_API_KEY" # your api key of capsolver
site_key = "6Le-wvkSAAAAAPBMRTvw0Q4Muexq9bi0DJwx_mJ-" # site key of your target site
site_url = "" # page url of your target site
def capsolver():
payload = {
"clientKey": api_key,
"task": {
"type": 'ReCaptchaV2TaskProxyLess',
"websiteKey": site_key,
"websiteURL": site_url
}
}
res = requests.post("https://api.capsolver.com/createTask", json=payload)
resp = res.json()
task_id = resp.get("taskId")
if not task_id:
print("Failed to create task:", res.text)
return
print(f"Got taskId: {task_id} / Getting result...")
while True:
time.sleep(3) # delay
payload = {"clientKey": api_key, "taskId": task_id}
res = requests.post("https://api.capsolver.com/getTaskResult", json=payload)
resp = res.json()
status = resp.get("status")
if status == "ready":
return resp.get("solution", {}).get('gRecaptchaResponse')
if status == "failed" or resp.get("errorId"):
print("Solve failed! response:", res.text)
return
token = capsolver()
print(token)In this example, the capsolver function sends a request to CapSolver’s API with the necessary parameters and returns the CAPTCHA solution. This simple integration can save you countless hours and effort in manually solving CAPTCHAs during web scraping and automation tasks.
Conclusion
Web scraping has transformed how we gather and analyze data online. From price comparisons to market trends and lead generation, its applications are diverse and powerful. Despite the challenges posed by anti-scraping measures like CAPTCHAs, solutions like CapSolver enable smoother data extraction processes.
By adhering to ethical guidelines and leveraging advanced tools, businesses and developers can harness the full potential of web scraping. It's not just about gathering data; it's about unlocking insights, driving innovation, and staying competitive in today's digital landscape.
FAQs
1. How do I bypass reCAPTCHA or hCaptcha safely during web scraping?
The safest and most reliable way to bypass reCAPTCHA, hCaptcha, or Cloudflare Turnstile is by using a dedicated CAPTCHA-solving API such as CapSolver. It integrates with scraping scripts, browser automation tools (Puppeteer, Playwright, Selenium), and handles challenge tokens automatically without manual intervention. Avoid using untrusted scripts or bots to prevent account bans or security risks.
2. Why does my scraper get blocked even when rotating proxies?
Websites now use multiple layers of bot detection, including browser fingerprint checks, behavioral analysis, TLS fingerprinting, and CAPTCHA challenges. Even with rotating proxies, scraping can fail if your browser environment looks automated. Using a real browser engine with correct headers, human-like timing, and a CAPTCHA-solving service significantly increases success rates.
3. Is it legal to use CAPTCHA-solving services for automation tasks?
Yes—CAPTCHA-solving services are legal when used for compliant tasks such as data research, SEO monitoring, price tracking, or automation that does not violate website terms or access protected data. Always ensure your use case follows local privacy regulations (GDPR, CCPA) and respects platform rules.
4. What is the best method to scrape JavaScript-rendered websites?
For JavaScript-heavy websites, headless browsers like Puppeteer, Playwright, or Selenium provide the highest success rate. They fully execute scripts, load dynamic content, and mimic real user behavior. For large-scale data extraction, use these tools together with proxies, rate limiting, and CAPTCHA-solving integrations.
5. How does CapSolver improve automation success on protected websites?
CapSolver automatically solves reCAPTCHA, Geetest, Turnstile, and other anti-bot challenges with high accuracy. It works seamlessly with scraping frameworks and reduces failure rates caused by verification walls. This leads to smoother crawling, fewer interruptions, and improved automation efficiency.
6. How can I reduce the chance of my automation being detected as a bot?
Use realistic browser fingerprints, rotate high-quality proxies, simulate natural delays, load assets normally, and avoid flooding endpoints with fast requests. Pairing these steps with CAPTCHA solving helps your scraper appear more like a real human session.
Compliance Disclaimer: The information provided on this blog is for informational purposes only. CapSolver is committed to compliance with all applicable laws and regulations. The use of the CapSolver network for illegal, fraudulent, or abusive activities is strictly prohibited and will be investigated. Our captcha-solving solutions enhance user experience while ensuring 100% compliance in helping solve captcha difficulties during public data crawling. We encourage responsible use of our services. For more information, please visit our Terms of Service and Privacy Policy.
More
Web Scraping Anti-Detection Techniques: Stable Data Extraction
Master web scraping anti-detection techniques to ensure stable data extraction. Learn how to avoid detection with IP rotation, header optimization, browser fingerprinting, and CAPTCHA solving methods.

Anh Tuan
03-Apr-2026
How to Choose CAPTCHA Solving API? 2026 Buyer's Guide & Comparison
Learn how to choose CAPTCHA solving API for web scraping and AI agents. Compare accuracy, speed, and cost to find the best automated solution for your needs.
Ethan Collins
02-Apr-2026

Web Scraping Security: Best Practices to Protect Data & Avoid Detection
Learn best practices for web scraping security, including ethical considerations, anti-bot system bypass, and CAPTCHA solutions to protect data and avoid detection risks. Essential for data professionals.

Nikolai Smirnov
02-Apr-2026

Browser Automation for Developers: Mastering Selenium & CAPTCHA in 2026
Master browser automation for developers with this 2026 guide. Learn Selenium WebDriver Java, Actions Interface, and how to solve CAPTCHA using CapSolver.

Adélia Cruz
02-Mar-2026

PicoClaw Automation: A Guide to Integrating CapSolver API
Learn to integrate CapSolver with PicoClaw for automated CAPTCHA solving on ultra-lightweight $10 edge hardware.
Ethan Collins
26-Feb-2026

How to Solve Captcha in Nanobot with CapSolver
Automate CAPTCHA solving with Nanobot and CapSolver. Use Playwright to solve reCAPTCHA and Cloudflare autonomously.
Ethan Collins
26-Feb-2026