







CapSolver Blogger
How to use CapSolver
-
Compliance Disclaimer: The information provided on this blog is for informational purposes only. CapSolver is committed to compliance with all applicable laws and regulations. The use of the CapSolver network for illegal, fraudulent, or abusive activities is strictly prohibited and will be investigated. Our captcha-solving solutions enhance user experience while ensuring 100% compliance in helping solve captcha difficulties during public data crawling. We encourage responsible use of our services. For more information, please visit our Terms of Service and Privacy Policy.
More
Image Recognition API for Custom CAPTCHAs: How It Works in Automation
Discover how an Image Recognition API for custom CAPTCHAs streamlines automation. Learn about AI vision logic, OCR vs. AI, and CapSolver's modular solutions.

Rajinder Singh
03-Apr-2026

How to Handle Web Scraping Blocks: Practical Methods That Work
Learn how to handle web scraping blocks effectively. Discover practical methods, technical insights into bot detection, and reliable solutions for data extraction.

Ethan Collins
03-Apr-2026
Optimize CAPTCHA Solving API Response Time for Faster Automation
Learn how to optimize CAPTCHA solving API response time for faster and more reliable automation. This guide covers key factors like CAPTCHA complexity, API performance, and polling strategies, with practical tips using CapSolver to achieve sub-10-second solve times.
Ethan Collins
03-Apr-2026
Web Scraping Anti-Detection Techniques: Stable Data Extraction
Master web scraping anti-detection techniques to ensure stable data extraction. Learn how to avoid detection with IP rotation, header optimization, browser fingerprinting, and CAPTCHA solving methods.

Anh Tuan
03-Apr-2026
How to Build Scrapers for Web Scraping in n8n with CapSolver
Learn how to build web scrapers in n8n for captcha-protected sites using CapSolver. This step-by-step guide covers solving reCAPTCHA, submitting tokens correctly, extracting product data, and automating workflows with schedule and webhook triggers.
Ethan Collins
03-Apr-2026
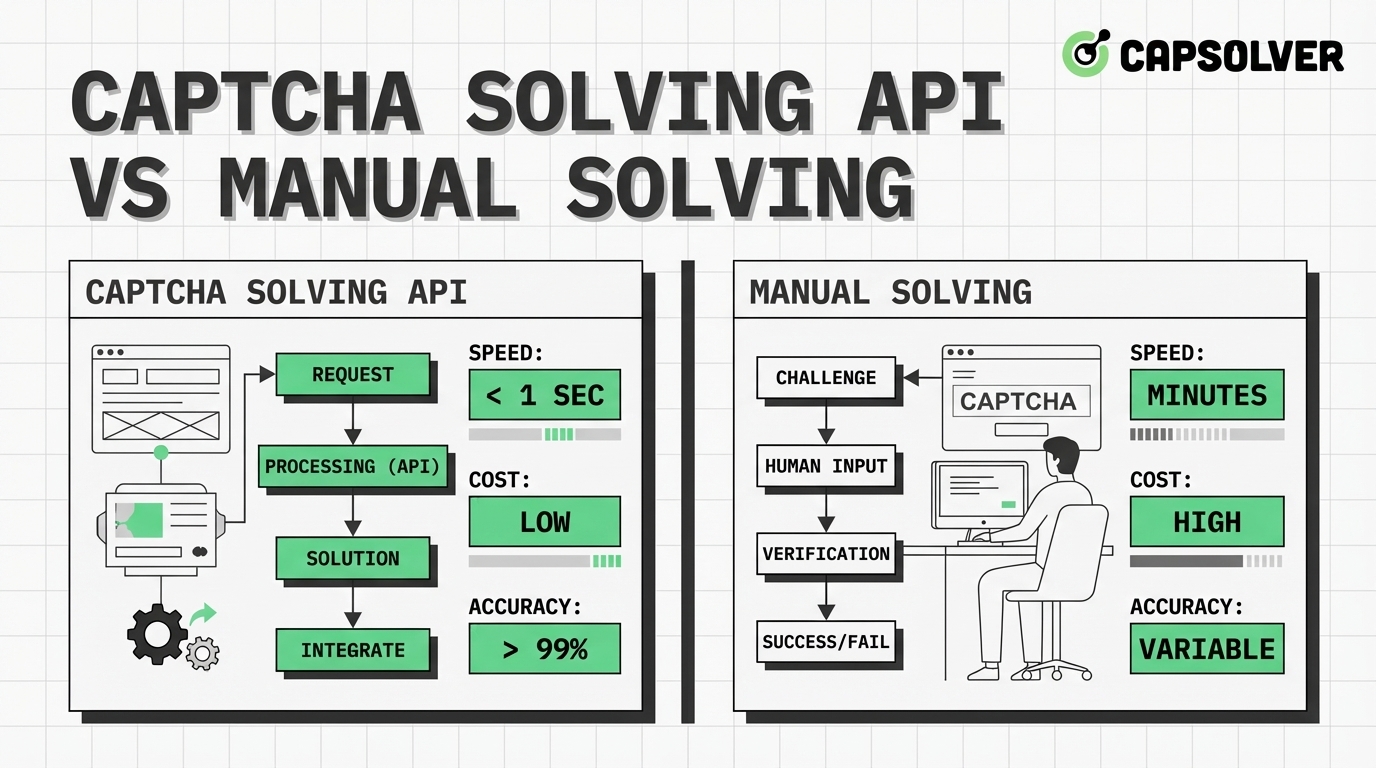
CAPTCHA Solving API vs Manual Solving: Costs & Efficiency (2026)
Compare CAPTCHA solving API vs manual solving. Learn about costs, speed, and efficiency. Discover why AI-powered APIs like CapSolver are the best choice for automation.

Adélia Cruz
03-Apr-2026