网络爬虫验证码处理:安全自动化指南

Ethan Collins
Pattern Recognition Specialist
TL;DR
- 网页抓取验证码处理应在任何技术集成之前先获得许可、控制速率并明确停止规则。
- 主要挑战类型包括 reCAPTCHA、Cloudflare Turnstile、图像识别和页面特定流量验证流程。
- CapSolver 可通过为常见挑战类型提供文档化的任务创建和结果检索 API,适配经批准的网页抓取验证码工作流。
- 优秀的自动化流程将令牌视为短期验证工件,并记录每次任务、重试、目标域名和失败状态。
引言
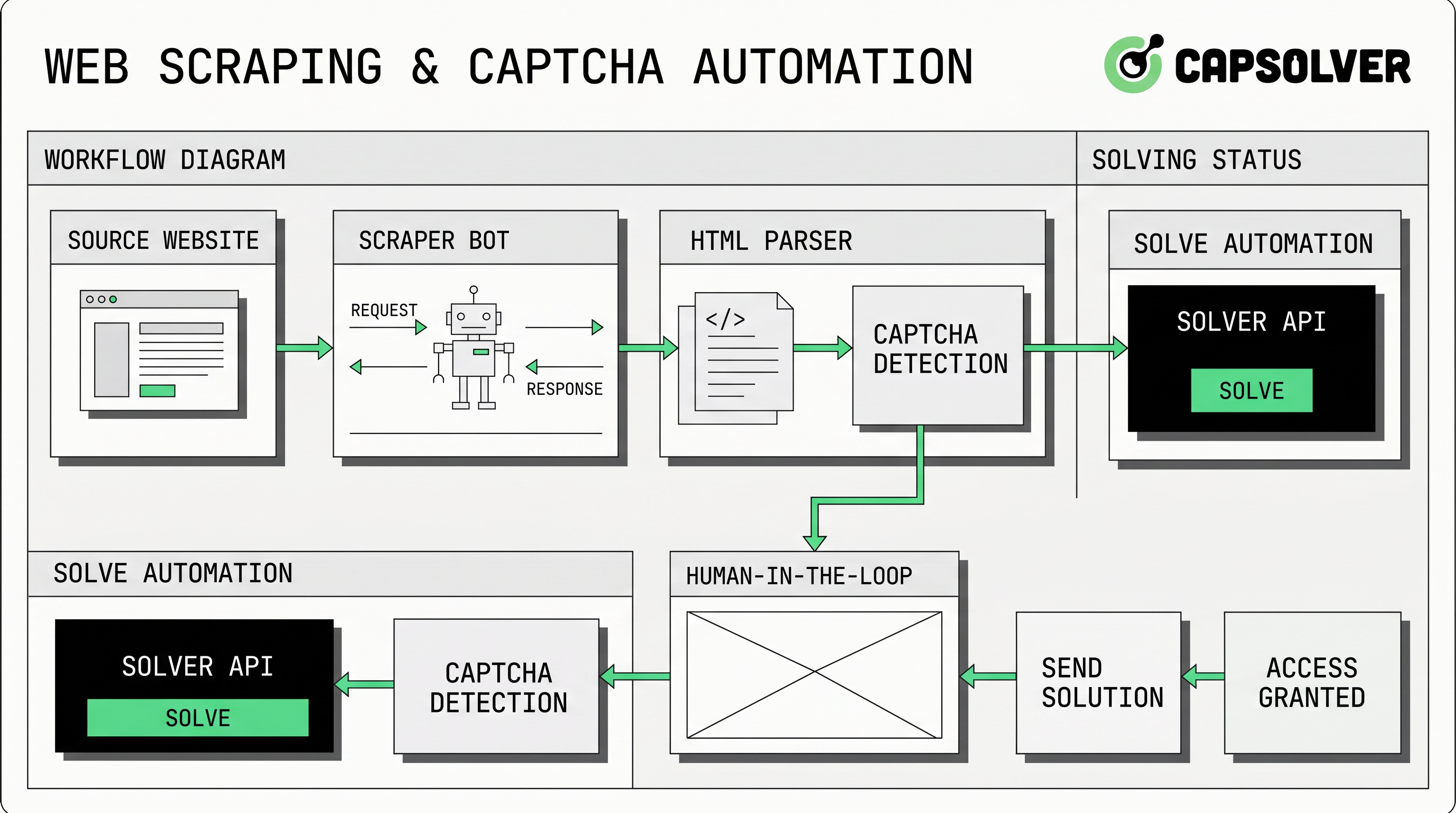
网页抓取验证码处理是团队收集合法公开数据、运行市场监控、测试自有应用或执行内部自动化时面临的实际问题。CapSolver 可在目标为合法、可控挑战处理而非无控制流量时支持这些工作流。最佳方法不是首先添加求解器,而是先确认许可、减少不必要的请求、识别挑战类型、保留浏览器上下文,并仅在允许的情况下添加 API 工作流。本指南解释了如何设计一个技术可靠、更易审计并符合负责任自动化规则的网页抓取验证码流程。
为什么网页抓取验证码会出现在自动化流程中
网页抓取验证码检查通常在网站希望对访客、请求模式、浏览器环境或账户行为有更多信心时出现。一些挑战是可见的,而其他则是基于评分或令牌的。Google 指出 reCAPTCHA v3 在不中断用户的情况下运行,并为每个请求返回 0.0 到 1.0 的风险评分。Cloudflare 指出 Turnstile 令牌 必须在服务器端验证,为一次性使用,且在 300 秒内有效。这些系统是更广泛的流量验证模式的一部分,而不仅仅是一个视觉谜题。
这意味着网页抓取验证码处理无法与请求质量分离。高请求速率、不稳定的 IP 声誉、缺失的浏览器信号或不一致的会话状态可能会增加挑战频率。在添加 API 之前,团队应通过负责任地缓存、遵守 robots 和条款、限制并发量、在适当的情况下识别其使用场景,并在网站拒绝或限制访问时停止,以减少不必要的触发。
| 原因 | 实际响应 | 为什么有帮助 |
|---|---|---|
| 高请求速率 | 添加队列限制和退避 | 减少负载和失败尝试。 |
| 浏览器不匹配 | 使用一致的浏览器自动化配置文件 | 保持页面上下文稳定。 |
| 代理不一致 | 保持代理、会话和挑战任务一致 | 防止令牌上下文不匹配。 |
| 未知的挑战类型 | 在任务创建前检测 reCAPTCHA、Turnstile 或图像挑战 | 发送正确的 API 负载。 |
| 不明确的权限 | 审查条款、robots、合同和数据敏感性 | 使自动化保持在批准的边界内。 |
在网页抓取验证码集成之前建立策略
网页抓取验证码工作应从治理开始。OWASP 将不受欢迎的自动化 描述为偏离接受行为并为网页应用造成不良影响的软件,其自动化威胁分类包括抓取和与 CAPTCHA 相关的滥用场景。对团队而言,这意味着相同的技木工作流在一种情况下可能是可接受的,而在另一种情况下则不可接受。
负责任的策略应列出允许的域名、允许的数据类型、业务目的、请求速率限制、账户规则、保留规则和升级联系人。还应解释自动化不得做什么,例如访问私人区域、未经许可收集敏感数据或在拒绝信号后继续操作。该策略保护目标网站和您的组织,因为它在批准的数据收集和禁止活动之间建立了清晰的界限。
选择正确的网页抓取验证码工作流
网页抓取验证码处理通常符合三种技术模式之一。第一种是通过更好的请求规范来避免:减少请求、改善缓存和减少嘈杂的浏览器行为。第二种是针对边缘情况的人工审核,低流量流程会将困难页面路由给操作员。第三种是基于 API 的挑战工作流,其中经批准的任务将挑战参数发送给提供商并检索解决方案。
CapSolver 的 官方 API 文档 描述了一个基于任务的流程,包含 createTask 和 getTaskResult。在此模型中,抓取器检测挑战,提交正确的任务对象,接收任务 ID,并轮询直到结果就绪。createTask 指南 指出请求需要 clientKey 和任务对象,getTaskResult 指南 记录了异步任务的 processing 和 ready 状态。
对于 reCAPTCHA 页面,团队应参考 CapSolver 的 reCAPTCHA v2 指南 或 reCAPTCHA v3 指南,而不是复制通用负载。对于 Turnstile 页面,使用 [Cloudflare Turnstile 指南](https://docs.capsolver.com/en/guide/captcha/CloudflareTu


