自动化团队的最佳网页爬取与API选择对比

Ethan Collins
Pattern Recognition Specialist
TL;DR
- 最佳的网页抓取与API决策应从数据权利、源可用性、可靠性要求和维护成本开始。
- API通常更适合受控的生产系统,因为其模式、速率限制、身份验证和版本控制更容易记录。
- 当允许的公开数据没有合适的API时,网页抓取是有用的,但需要审查robots.txt、控制速率、监控页面变化并进行合规检查。
- 浏览器自动化对于动态页面有帮助,当批准的工作流遇到CAPTCHA或流量验证事件时,CapSolver可以帮助处理。
- 最具弹性的架构应优先使用API,其次使用网页抓取,仅在必要时使用浏览器自动化,并将CAPTCHA解决作为受控的例外路径。
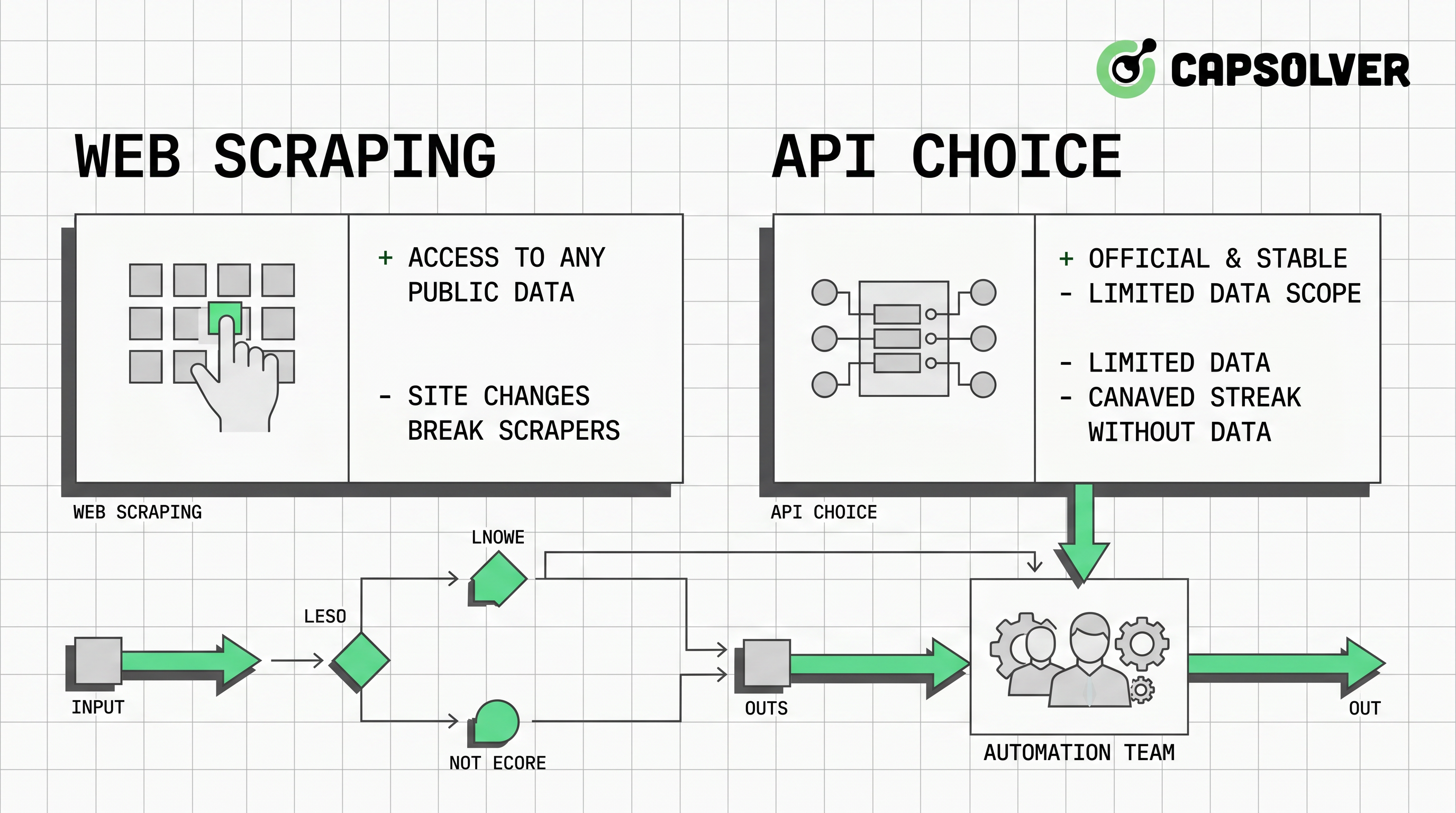
引言
最佳的网页抓取与API选择很少是关于哪种方法更强大。它们是关于哪种方法对您的团队所需数据更可靠、被允许、可维护和可审计。当API提供所需字段、新鲜度和条款时,通常应优先考虑API。当允许的公开页面是唯一可行的来源,或团队需要监控展示层变化时,网页抓取变得有用。如果批准的网页抓取或浏览器自动化流程遇到CAPTCHA挑战,CapSolver的网页抓取时的CAPTCHA解决指南可以提供一个符合更广泛自动化流程的文档解决路径。
以API为先应是默认决策
API通常是默认选择,因为它们表达了供应商支持的合同。设计良好的API为团队提供了可预测的字段、身份验证、速率限制、错误代码和版本控制。这些特性使工程审查更容易,并减少对脆弱解析的需求。API还简化了数据来源,因为每条记录都可以与端点、时间戳、请求ID或文档模式相关联。
REST API教程和参考解释了常见的API设计概念,如资源、方法和表示。 GitHub REST API速率限制文档说明了为什么速率限制不是障碍,而是运营合同。在许多自动化程序中,较慢的官方API比更快的抓取器更好,因为API在审计中更容易辩护,并且在数据消费者增长时更容易维护。
| 决策因素 | API优势 | 网页抓取优势 |
|---|---|---|
| 数据合同 | 稳定的模式和文档错误 | 可收集端点未暴露的可见字段 |
| 维护 | 版本控制和支持渠道 | 当没有合适的API时可用 |
| 新鲜度 | 可预测的轮询和速率限制 | 可快速反映页面级更新 |
| 动态页面 | 较少的浏览器开销 | 浏览器自动化可以检查渲染状态 |
| 挑战事件 | 通常可避免 | 可能需要受控的CAPTCHA解决工作流 |
关键是不要拒绝网页抓取。关键是证明在添加操作复杂性之前需要网页抓取。
当网页抓取是更好的选择
当数据是公开的、被允许的、无法通过合适的API获得,并且有价值到值得监控时,网页抓取是更好的选择。常见例子包括公开价格页面、产品可用性页面、公开职位列表、公开目录和网站更改监控。即使如此,团队也应记录数据字段、来源页面、爬取频率、排除规则以及负责工作流的业务负责人。
RFC 9309 机器人排除协议定义了网站如何向自动化客户端传达爬取规则。 MDN URL参考对于URL规范化很有用,这是去重和爬取边界的最基本要求。这些参考资料支持一个实用规则:网页抓取应被视为具有权限和边界的工程系统,而不是非正式脚本。
网页抓取还受益于分层设计。静态页面通常可以通过HTTP请求和解析器处理。JavaScript密集型页面可能需要浏览器自动化。具有流量验证的页面可能需要文档化的挑战处理政策。当自动化层需要提取和受控挑战处理时,CapSolver的Playwright集成指南很有用。
CAPTCHA解决在决策中的位置
CAPTCHA解决应位于最佳网页抓取与API决策树的后期。如果存在满足需求的API,请使用它。如果可以通过允许的静态提取收集公共页面,请使用该方法。如果需要浏览器自动化,请添加渲染和交互控制。在这些选择之后,团队才应决定如何处理受支持的CAPTCHA或流量验证事件。
CapSolver的reCAPTCHA术语表和CAPTCHA术语指南帮助团队在选择解决路径之前识别常见的挑战家族。该决策应包括批准范围、支持的域名、重试限制、日志记录、代理策略和页面级成功检查。解决的挑战是不够的;工作流必须确认批准的任务正确完成。
批准数据自动化试点的优惠代码
领取您的CapSolver优惠代码
立即提升您的自动化预算!
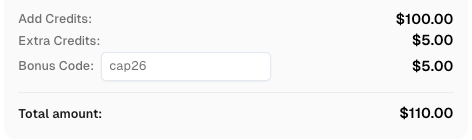
在充值CapSolver账户时使用优惠代码 CAP26,每次充值可额外获得 5% 的奖励 —— 无限制。
现在在您的 CapSolver仪表板 中领取
自动化团队的架构模式
强大的架构应分离访问方法、执行、验证和治理。访问方法可以是API、静态抓取器、浏览器自动化脚本或混合工作流。执行应应用速率限制、重试和安全停止条件。验证应比较记录数、所需字段、来源时间戳和模式变化。治理应记录谁批准了来源、允许哪些数据以及工作流何时必须再次审查。
对于浏览器密集型工作流,Playwright文档为受控页面渲染和交互提供了实用的起点。对于爬虫密集型工作流,Scrapy文档解释了蜘蛛、项目和管道。对于受挑战支持的工作流,CapSolver的浏览器扩展指南可以帮助工程师在设计可重复的API优先路径之前诊断真实页面行为。
| 架构模式 | 使用情况 | 添加此控制 |
|---|---|---|
| 仅API | 所需字段可用且条款允许使用 | 端点监控和速率限制处理 |
| 静态抓取 | 公共页面稳定且被允许 | robots.txt审查和选择器测试 |
| 浏览器自动化 | 需要渲染或交互 | 超时预算和页面状态验证 |
| 混合API加抓取 | API覆盖大部分字段但页面提供上下文 | 真实数据规则和去重 |
| 抓取加CapSolver | 批准的页面出现CAPTCHA挑战 | 批准票证、脱敏日志和重试限制 |
这种结构使最佳网页抓取与API选择透明化。它还减少了团队在证明更简单的方法无法满足业务需求之前添加浏览器自动化或CAPTCHA解决的风险。
负责任使用检查清单
负责任的自动化计划从源审查开始。确认数据是公开的或有其他授权,收集目的是合法的,并且敏感个人或受限数据不在范围内,除非有法律依据和安全控制措施。然后审查robots.txt、网站条款、API文档和合同义务。最后,以低流量测试,并在出现意外登录墙、权限更改、挑战激增或模式漂移时停止工作流。
OWASP自动化威胁项目是一个有用的提醒,说明相同的自动化技术可能被滥用。您的内部标准应要求获得授权、成比例的请求速率、适当的标识,并在工作流更改时进行人工审查。CapSolver仅应在拥有、暂存、客户批准或有其他授权的目标中使用,其中挑战处理是合法自动化流程的一部分。
结论
最佳的网页抓取与API决策应遵循一个简单的层次结构:在满足需求时使用API,当无法满足时使用允许的静态抓取,当需要渲染时使用浏览器自动化,并仅在文档化的情况下添加CAPTCHA解决。对于需要在批准自动化中进行可靠挑战处理的团队,CapSolver的网页抓取法律指南可以帮助将解决过程置于受控工作流中,与API、爬虫、浏览器自动化、监控和合规审查一起。
常见问题
最佳的网页抓取与API规则是什么?
最佳规则是优先使用API,其次使用网页抓取。当API在可接受条款下提供数据时使用API,仅在允许的页面是实际来源时使用网页抓取。
何时网页抓取比API更好?
当允许的公开页面数据无法通过合适的API获得,或页面展示本身是团队需要监控的数据时,网页抓取更好。
何时应添加浏览器自动化?
仅在静态HTTP提取无法捕获所需渲染内容、用户交互或后加载数据时添加浏览器自动化。
CapSolver如何融入网页抓取与API工作流?
当批准的网页抓取或浏览器自动化工作流遇到受支持的CAPTCHA或流量验证挑战并需要文档化解决路径时,CapSolver适用。
团队在抓取前应检查什么?
团队应检查权限、robots.txt、条款、数据敏感性、请求速率和监控规则。当挑战处理是批准计划的一部分时,也可以查看CapSolver的网页抓取常见问题解答。


