如何处理网页爬虫拦截:实用的方法

Ethan Collins
Pattern Recognition Specialist

TL;Dr:
- 了解机制: 网站通过IP追踪、浏览器指纹识别和行为分析来识别并阻止自动化脚本。
- 实施轮换: 使用轮换住宅代理和多样的User-Agent字符串来模拟人类流量模式。
- 应对挑战: 集成专用工具以高效解决CAPTCHA并管理复杂的机器人检测系统。
- 保持道德: 严格遵守robots.txt指南并实施请求节流,以减少对目标服务器的影响。
引言
网络数据抓取已成为现代数据驱动决策的重要组成部分,但自动化数据收集的环境正变得越来越具有挑战性。随着网站部署更复杂的网络安全措施,学习如何处理网络数据抓取阻止措施已不再是一种优势,而是任何成功提取项目所必需的。本指南全面概述了阻止发生的原因、检测机制背后的底层技术以及最有效且符合道德的策略,以确保您的抓取器保持运行。无论您是开发人员构建自定义爬虫,还是数据分析师监督大规模操作,了解这些实用方法将帮助您保持对所需信息的持续访问。
理解网络数据抓取阻止的本质
要有效管理障碍,首先必须了解它们是什么以及为何存在。网络数据抓取阻止是网站为防止自动化脚本访问其内容而实施的防御措施。这些措施通常是更广泛安全策略的一部分,旨在保护服务器资源、防止知识产权盗窃或维护用户数据的完整性。
根据最近的行业数据,自动化流量占所有网络请求的很大一部分,导致许多平台采用激进的过滤措施。您可以在 Statista机器人流量数据报告 中找到更多全球趋势的详细信息。当服务器检测到偏离标准人类行为模式的请求时,可能会通过显示CAPTCHA、降低连接速度或直接IP封禁来应对。学习如何在这些情况下处理网络数据抓取阻止是数据持续性的关键。
技术背景:检测机制如何运作
现代安全系统不会依赖单一因素来识别机器人。相反,它们使用多种技术来为每个传入请求构建风险档案。
1. 基于IP的追踪
这是最基本的防御层。服务器会监控特定时间范围内来自单一IP地址的请求数量。如果频率超过预定义的阈值,该IP将被标记。这就是为什么了解如何在网络层处理网络数据抓取阻止如此重要。数据中心IP通常会被预先阻止,因为它们很少被合法的人类访问者使用。
2. 浏览器指纹识别
除了IP地址,网站还可以从您的浏览器环境中收集大量信息。这包括屏幕分辨率、安装的字体、时区和硬件规格。如果这些细节不一致或过于“干净”(通常是无头浏览器的特征),系统会将请求识别为自动化。
3. 行为分析
先进的平台会跟踪用户与页面的互动方式。人类的鼠标移动呈非线性模式,阅读内容需要时间,并以不同的节奏点击元素。相比之下,脚本可能会直接跳转到URL并在毫秒内提取数据。任何偏离预期人类行为的模式都会触发红色警报。基于行为的检测是处理网络数据抓取阻止时最困难的挑战之一。
常见的CAPTCHA挑战类型
当系统不确定但怀疑时,通常会显示CAPTCHA。理解这些类型对于有效处理网络数据抓取阻止至关重要。
| 验证码类型 | 描述 | 主要检测逻辑 |
|---|---|---|
| 图像识别 | 用户必须从网格中选择特定对象(例如交通灯)。 | 测试处理视觉数据的能力,并识别类似人类的点击模式。 |
| 隐形验证码 | 在后台运行,无需用户交互。 | 分析浏览器环境和历史行为以分配风险评分。 |
| 文本/数学挑战 | 需要解决简单方程或输入扭曲文本。 | 依赖OCR(光学字符识别)的难度来应对旧版机器人。 |
| 拼图/滑块 | 用户必须拖动一块以完成图像。 | 专注于光标物理移动和操作时间。 |
处理网络数据抓取阻止的实用方法
实施正确的技术策略可以显著降低被检测的可能性。以下是专业人士今天使用的最有效方法。
使用轮换住宅代理
由于IP封禁很常见,使用住宅代理池是避免IP封禁并确保高成功率的最佳方法之一。这些代理是网络数据抓取最佳实践的核心。与数据中心IP不同,住宅IP与真实的家庭互联网连接相关联,使其更难以与合法用户区分。通过每几次请求轮换这些IP,您可以分散流量并保持隐蔽。
管理请求头和User-Agent
每个HTTP请求都包含告诉服务器客户端信息的头。常见的错误是使用默认库头如“python-requests/2.25.1”。相反,您应使用多样化的实际User-Agent字符串。参考 MDN User-Agent文档 以了解如何正确构建这些头。确保您的头包含“Accept-Language”和“Referer”等字段,以模拟真实浏览会话。
实现请求节流
速度通常是机器人的最大破绽。通过在请求之间添加随机延迟,您可以模拟人类浏览行为。这种技术称为节流,可防止您压垮目标服务器并减少触发速率限制警报的可能性。实施这些网络数据抓取最佳实践将帮助您在保持访问敏感数据的同时,避免大规模操作中的IP封禁。
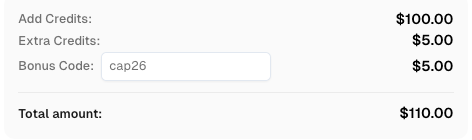
在 CapSolver 注册时使用代码
CAP26可获得额外积分!
自动解决验证码
即使拥有完美的头和代理,您最终仍会遇到挑战。这时,专用服务就变得至关重要。例如,CapSolver 提供了一个强大的API来解决各种挑战,如ReCaptcha和FriendlyCaptcha,确保您的自动化流程不受中断。这些工具是现代环境中处理网络数据抓取阻止的核心部分。
如果您使用cURL或Python进行自动化,可以按照以下通用流程集成解决方案:
- 提交任务: 将验证码详情(站点密钥、URL)发送给服务。
- 获取解决方案: 使用任务ID轮询API,直到解决方案就绪。
- 提交令牌: 使用返回的令牌在目标网站上绕过挑战。
以下是基于CapSolver文档提交任务的简化示例:
json
{
"clientKey": "YOUR_API_KEY",
"task": {
"type": "ReCaptchaV2TaskProxyLess",
"websiteURL": "https://www.example.com",
"websiteKey": "6LcR_okUAAAAAPYrPe-z_bx1oYxq6zz_S0vO49zV"
}
}抓取技术比较总结
为了帮助您选择合适的方法,以下是常见方法的比较。
| 方法 | 有效性 | 实现复杂度 | 成本 |
|---|---|---|---|
| 基础请求头 | 低 | 低 | 免费 |
| 数据中心代理 | 中等 | 中等 | 低 |
| 住宅代理 | 高 | 中等 | 中等 |
| 无头浏览器 | 高 | 高 | 高(资源) |
| 验证码解决服务 | 必要 | 低 | 低 |
道德与合规性考虑
在学习如何处理网络数据抓取阻止时,强调道德实践至关重要。自动化数据收集应始终以尊重目标网站条款和服务器健康的方式进行。始终检查域名的robots.txt文件,查看哪些区域受到限制。遵循这些网络数据抓取最佳实践不仅能保护您的法律地位,还能确保数据来源的长期性。
对于寻求更高级工具的用户,探索 最佳数据提取工具 可以提供构建稳健系统的额外见解。
自然过渡到解决方案
随着机器人检测技术的发展,维护爬虫的复杂性也在增加。许多开发者发现,为什么网页自动化在验证码上会失败 往往是由于缺乏专门的处理策略。使用 最佳验证码解决服务 可以让您专注于数据分析,而不是不断修复损坏的脚本。通过将这些专业服务集成到您的系统中,即使在最受保护的平台上,您也可以确保高成功率。
结论
掌握如何处理网络数据抓取阻止需要多层方法,结合技术精确性和道德责任。通过理解检测逻辑、实施强大的代理管理并利用专用解决服务,您可以构建可靠的数据显示管道。请记住,目标不仅是绕过单一障碍,而是创建一个可持续的系统,尊重数字生态系统的同时,为您的业务提供所需的洞察。
常见问题
1. 即使使用了代理,我为什么仍然会被阻止?
阻止可能由于浏览器指纹识别或不一致的请求头引起。确保您的User-Agent与代理的感知位置匹配,并且通过WebRTC不泄露真实IP。
2. 绕过网络数据抓取阻止是否合法?
合法性取决于您的司法管辖区和您收集的数据类型。通常,抓取公开数据是合法的,但您必须遵守版权和隐私数据保护法律。
3. 我应该多久轮换一次User-Agent?
在每个新会话或每几百次请求中使用新的User-Agent是最佳做法,尤其是如果您也在轮换IP地址的话。
4. 无头浏览器可以防止所有阻止吗?
虽然有助于隐藏,但像Puppeteer或Playwright这样的无头浏览器仍可能通过特定属性被检测到。您必须使用“隐蔽”插件来掩盖其自动化性质。
5. 处理验证码最经济有效的方法是什么?
使用基于API的验证码解决服务,如 CapSolver,通常比构建自己的机器学习模型或使用人工劳动更经济有效,因为它以低成本提供高速和高精度。


