如何在网络爬取中解决 reCAPTCHA Enterprise 挑战

Anh Tuan
Data Science Expert

当我第一次在网络爬取项目中遇到 reCAPTCHA Enterprise 时,我很快意识到它的挑战有多大。应对这些高级安全措施并不是一件容易的事,但通过反复试验,我开发出了能显著提高效率的策略。在本指南中,我将分享我克服 reCAPTCHA Enterprise 挑战的方法,确保你的爬取任务能够顺利进行。让我带你了解我发现最有效的技术。
关于 reCAPTCHA Enterprise
reCAPTCHA Enterprise 是谷歌推出的一项先进服务,旨在保护网站免受欺诈和爬取活动的侵害。它利用自适应风险引擎来评估用户互动,并防止未经授权的访问。
reCAPTCHA v3 Enterprise 看起来像这样:
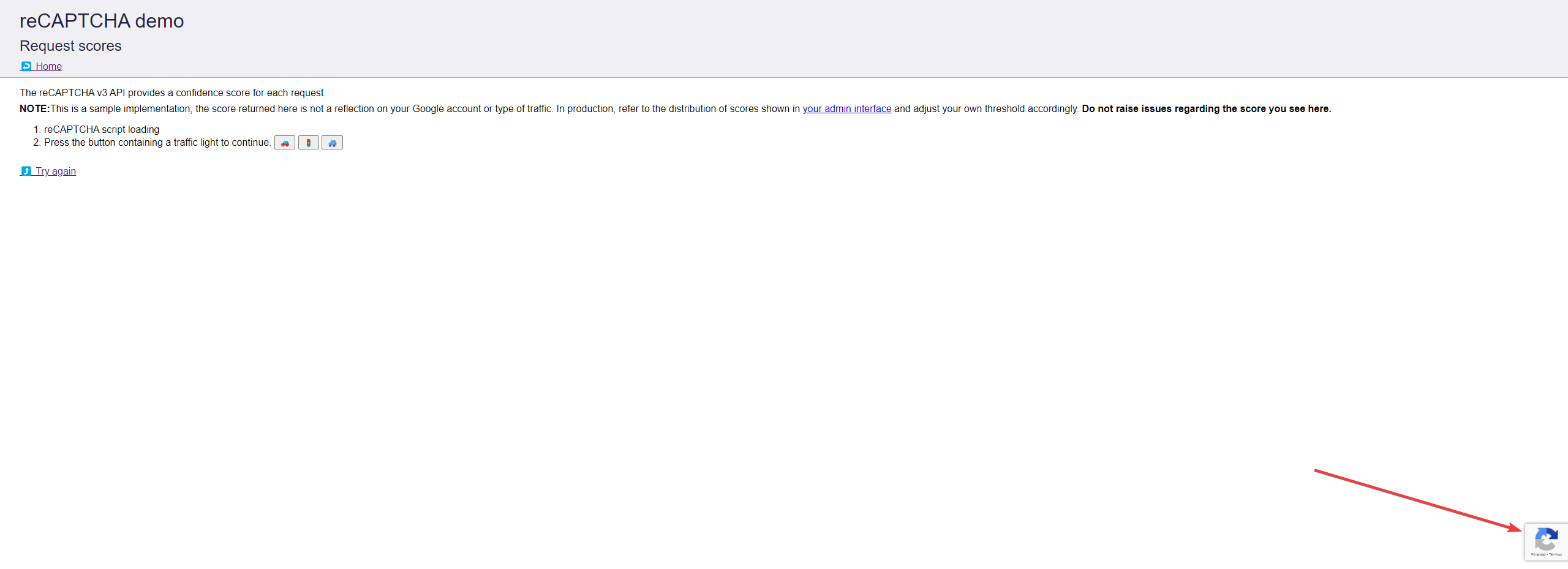
是否为反复无法解决烦人的验证码而苦恼?
发现无缝自动验证码解决方案,使用 Capsolver AI 驱动的自动网页解锁技术!
领取您的 优惠码,享受顶级验证码解决方案;CapSolver:WEBS。兑换后,您将获得每次充值额外 5% 的奖金,无限制

reCAPTCHA Enterprise 的工作原理
在与 reCAPTCHA Enterprise 交互的过程中,我观察到它分析了各种指标,如用户的平台、浏览器环境和导航行为。这些分析会产生一个从 0 到 1 的机器人评分。接近 0 的评分表示高风险活动,而接近 1 的评分则表明用户行为真实合法。
使用 reCAPTCHA Enterprise 识别机器人
reCAPTCHA Enterprise 使用评分系统来检测类似机器人的活动。它通过允许低风险评分的请求通过,同时阻止高风险请求,从而确保只有真实用户可以访问,而自动化脚本和网络爬虫则被有效阻止。
reCAPTCHA Enterprise 中的 CAPTCHA 类型
根据我的观察,reCAPTCHA Enterprise 不依赖于传统的 CAPTCHA,如视觉谜题。相反,它对高风险评分做出各种保护措施。这些措施可能包括显示实体 CAPTCHA、封禁 IP 地址、请求两步验证或重定向到蜜罐。未能达到所需机器人评分的自动化脚本会在到达目标数据之前被阻止。
通过脚本识别 reCAPTCHA v3 Enterprise
reCAPTCHA v3 Enterprise 的一个显著特征是其名为 enterprise.js 的独特脚本。使用 reCAPTCHA v3 Enterprise 的网站需要包含此特定脚本以确保其功能,因此其存在是该服务的一个强指示符。
您可以在网站的源代码中找到 enterprise.js 脚本,通常嵌入在 <script> HTML 标签中。该标签的 src 属性将指向 JavaScript 文件的位置。对于 reCAPTCHA v3 Enterprise,脚本将位于以下 URL 之一:
https://recaptcha.net/recaptcha/enterprise.js
https://google.com/recaptcha/enterprise.js在网站的 HTML 中,脚本标签将如下所示:
html
<script src="https://recaptcha.net/recaptcha/enterprise.js" async defer></script>或者
html
<script src="https://google.com/recaptcha/enterprise.js" async defer></script>async 和 defer 属性确保脚本异步加载,不会影响网页的加载速度和性能。
如何在网络爬取中解决 reCAPTCHA Enterprise 挑战
在我的网络爬取项目中,我发现 CapSolver 是克服 reCAPTCHA Enterprise 挑战的极为有效的工具,特别是在处理 reCAPTCHA v3 Enterprise 时。以下是我使用 CapSolver 解决 reCAPTCHA v3 Enterprise 挑战的方法:
前提条件
在开始实施之前,请确保您已具备以下条件:
- 系统上安装了 Python
- 获取了 CapSolver API 密钥(可从 CapSolver Dashboard 获取)
- 代理(可选,但推荐用于更好的效果)
步骤 1:设置环境
首先,我总是确保安装了必要的包。我们需要的主要包是 capsolver。可以使用 pip 安装:
pip install capsolver步骤 2:实施解决方案
现在,让我们看看如何使用 CapSolver 解决 reCAPTCHA v3 Enterprise 挑战。我将提供两个版本的代码:一个使用代理,另一个不使用代理。
版本 1:使用代理
这是我在希望使用代理解决 reCAPTCHA v3 Enterprise 时使用的 Python 脚本:
python
import capsolver
from urllib.parse import urlparse
# 配置
PROXY = "http://username:password@ip:port"
capsolver.api_key = "YourApiKey"
PAGE_URL = ""
PAGE_KEY = ""
PAGE_ACTION = ""
def solve_recaptcha_v3_enterprise(url, key, pageAction):
solution = capsolver.solve({
"type": "ReCaptchaV3EnterpriseTask",
"websiteURL": url,
"websiteKey": key,
"pageAction": pageAction,
"proxy": PROXY
})
return solution
def main():
print("正在解决 reCaptcha v3 Enterprise")
solution = solve_recaptcha_v3_enterprise(PAGE_URL, PAGE_KEY, PAGE_ACTION)
print("解决方案:", solution)
token = solution["gRecaptchaResponse"]
print("Token 解决方案:", token)
if __name__ == "__main__":
main()版本 2:不使用代理
在不需要或不想使用代理的情况下,我使用这个稍作修改的版本:
python
import capsolver
from urllib.parse import urlparse
# 配置
capsolver.api_key = "YourApiKey"
PAGE_URL = ""
PAGE_KEY = ""
PAGE_ACTION = ""
def solve_recaptcha_v3_enterprise(url, key, pageAction):
solution = capsolver.solve({
"type": "ReCaptchaV3EnterpriseTaskProxyless",
"websiteURL": url,
"websiteKey": key,
"pageAction": pageAction
})
return solution
def main():
print("正在解决 reCaptcha v3 Enterprise")
solution = solve_recaptcha_v3_enterprise(PAGE_URL, PAGE_KEY, PAGE_ACTION)
print("解决方案:", solution)
token = solution["gRecaptchaResponse"]
print("Token 解决方案:", token)
if __name__ == "__main__":
main()关键配置点
使用这些脚本时,我总是确保更新以下变量:
PROXY:如果使用代理版本,我会使用格式为http://username:password@ip:port的代理详细信息来更新此项。capsolver.api_key:在此插入我的 CapSolver API 密钥。PAGE_URL:设置为我正在解决 reCAPTCHA 的网站 URL。PAGE_KEY:更新为特定的 reCAPTCHA 网站密钥。PAGE_ACTION:设置为 reCAPTCHA 挑战的 pageAction。
要找到 PAGE_KEY 和 PAGE_ACTION 的正确值,我通常参考 Capsolver 的 博客文章 了解如何识别 reCAPTCHA v3 值。
为什么这种方法有效
这种方法在我的爬取项目中非常有效,原因如下:
- 高成功率:CapSolver 一致提供有效的令牌,成功解决 reCAPTCHA v3 Enterprise 挑战。
- 灵活性:使用代理的能力允许我分发请求,减少被封锁的风险。
- 简便性:简单明了的 API 使得集成到现有脚本中很容易。
- 速度:解决方案通常在几秒钟内交付,保持了我的爬取操作的效率。
关于 reCAPTCHA v2 Enterprise 的进一步阅读
如果您还在处理 reCAPTCHA v2 Enterprise 挑战,您可能会发现以下博客文章很有帮助
:
希望这个指南对你解决 reCAPTCHA Enterprise 挑战有所帮助。如果你有任何问题或需要进一步的帮助,请随时联系我!
结论
在网络爬取领域,处理 reCAPTCHA Enterprise,尤其是 reCAPTCHA v3 Enterprise,可能是一个令人望而生畏的任务。然而,通过利用像 CapSolver 这样的先进解决方案,你可以显著简化这个过程。
根据我的经验,将 CapSolver 集成到你的爬取工作流中,不仅可以提高效率,还能确保在解决这些复杂安全措施时获得更高的成功率。无论你选择使用代理还是直接方法,CapSolver 都提供了处理 reCAPTCHA 挑战所需的工具和灵活性。
记住,尽管 CapSolver 是一个强大的助手,但在进行网络爬取时保持最佳实践和遵守法律标准至关重要。 通过将有效的工具与道德实践结合起来,你可以在不妥协诚信的情况下实现你的爬取目标。
欲了解更多关于 CapSolver 的信息并开始克服 CAPTCHA 挑战,请访问 CapSolver 的网站。


