如何在 Python 中集成 reCAPTCHA v2 解决方案以进行数据提取

Anh Tuan
Data Science Expert
简介
随着互联网的不断发展,网络抓取和数据提取被广泛用于从网站收集信息,以用于各种目的,包括商业智能、内容聚合和市场分析。然而,随着机器人的不断发展,网站实施了工具来区分人类用户和自动化程序。reCAPTCHA 就是这样的工具之一。在本博文中,我们将探讨 reCAPTCHA 是什么,可用的不同版本以及如何使用 Python 中的 Capsolver 来 解决 reCAPTCHA v2 挑战。最后,我们将逐步介绍一个简单的示例代码,将 reCAPTCHA v2 集成到您的数据提取项目中。
什么是 reCAPTCHA?

reCAPTCHA 是 Google 开发的一项免费服务,它通过确保与网站交互的是真实的人(而不是自动化的机器人),来帮助保护网站免受垃圾邮件和滥用的侵害。当用户访问实施了 reCAPTCHA 的网站时,他们可能需要完成一项挑战以验证他们是否是人类。
reCAPTCHA 的不同版本
reCAPTCHA 有几个版本,每个版本都有其自身的优势和用例:
-
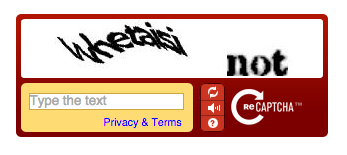
reCAPTCHA v1: 最早的版本,现在已弃用。它要求用户从图像中转录扭曲的文本。
-
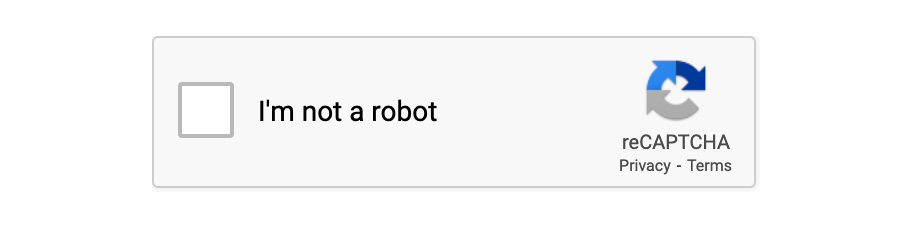
reCAPTCHA v2: 更高级的版本,为用户呈现一个复选框(“我不是机器人”)。如有必要,它还会挑战他们选择某些图像(如交通灯或人行横道)。此版本是当今最常用的版本。
-
reCAPTCHA v3: 此版本分析用户行为和与网站的交互,以分配从 0 到 1 的分数,其中 0 表示机器人,1 表示人类。它对用户来说更无缝,因为它不需要交互式挑战。

-
隐形 reCAPTCHA: 此版本在后台运行,只有在检测到可疑活动时才会提出挑战。它旨在对合法用户不可见。
什么是数据提取?

数据提取是指从非结构化来源(如网页、数据库或其他数字格式)中检索结构化数据的过程。它通常用于网络抓取,其中自动化程序从网站收集大量信息以进行分析或聚合。
数据提取的常见用例
-
市场研究: 公司提取竞争对手定价数据和客户评论,以调整其营销和销售策略。
-
商业智能: 组织抓取财务报告、新闻和其他资源,以做出明智的商业决策。
-
内容聚合: 从多个来源整理和显示信息的网站通常会从其他网页中提取数据。
-
SEO 分析: 从竞争对手网站提取内容、关键词和元标签有助于优化 SEO 策略。
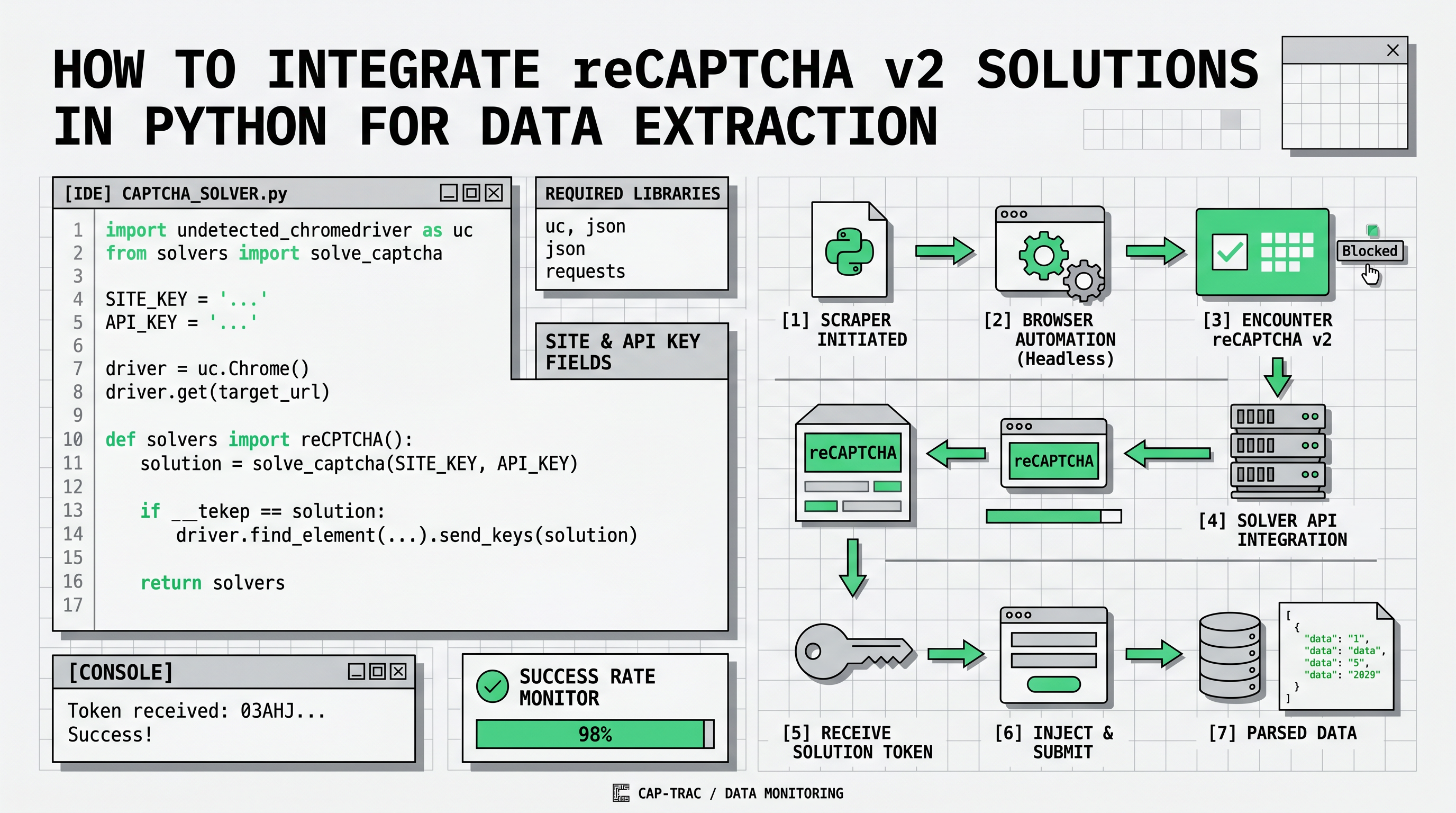
在 Python 中集成 reCAPTCHA v2 解决方案
从网站提取数据时,您可能会遇到 reCAPTCHA 挑战。这对自动化抓取提出了障碍。幸运的是,Capsolver 等工具可以以编程方式解决 reCAPTCHA v2 挑战,让您可以继续进行数据提取任务。
以下是如何使用 Capsolver 包解决 reCAPTCHA v2 的 Python 实现。
步骤:
-
通过运行以下命令安装
capsolver库:bashpip install capsolver -
使用以下 Python 代码解决 reCAPTCHA v2 挑战:
python
import capsolver
# 考虑使用环境变量来存储敏感信息
capsolver.api_key = "Your Capsolver API Key"
PAGE_URL = "PAGE_URL"
PAGE_KEY = "PAGE_SITE_KEY"
def solve_recaptcha_v2(url,key):
solution = capsolver.solve({
"type": "ReCaptchaV2TaskProxyless",
"websiteURL": url,
"websiteKey":key,
})
return solution
def main():
print("Solving reCaptcha v2")
solution = solve_recaptcha_v2(PAGE_URL, PAGE_KEY)
print("Solution: ", solution)
if __name__ == "__main__":
main()代码解释
-
Capsolver API 设置: 在代码中,我们定义了
capsolver.api_key,它应该包含您的 Capsolver API 密钥。此密钥将验证您对 Capsolver 服务的请求。 -
求解函数: 函数
solve_recaptcha_v2接受页面的url和site_key(即网站上存在的 reCAPTCHA 密钥)。它向 Capsolver 发送请求以解决 reCAPTCHA 挑战。 -
主函数: 主函数运行求解器并打印解决方案。
-
环境变量: 建议使用环境变量来存储 API 密钥等敏感信息,以提高安全性。在上面的示例中,您应该将
Your Capsolver API Key、PAGE_URL和PAGE_SITE_KEY替换为您的实际值。
附加代码
获取您 奖励代码 以获得顶级验证码解决方案;CapSolver: scrape. 兑换后,每次充值后您将获得额外 5% 的奖励,无限次

有关更多信息,请阅读此 博客
结论
reCAPTCHA 是保护网站免受机器人攻击的重要工具,但它会为合法自动化目的(如数据提取)带来挑战。使用 Capsolver 等工具,开发人员可以以编程方式解决 reCAPTCHA v2 挑战,从而实现不间断的数据提取。始终确保您的数据提取活动符合网站的 服务条款 和法律准则,以避免任何问题。
通过将上面提供的解决方案集成到您的 Python 项目中,您可以在克服 reCAPTCHA 障碍的同时继续从网站收集有价值的数据。


