如何应对电商价格监控中的验证码?

Ethan Collins
Pattern Recognition Specialist
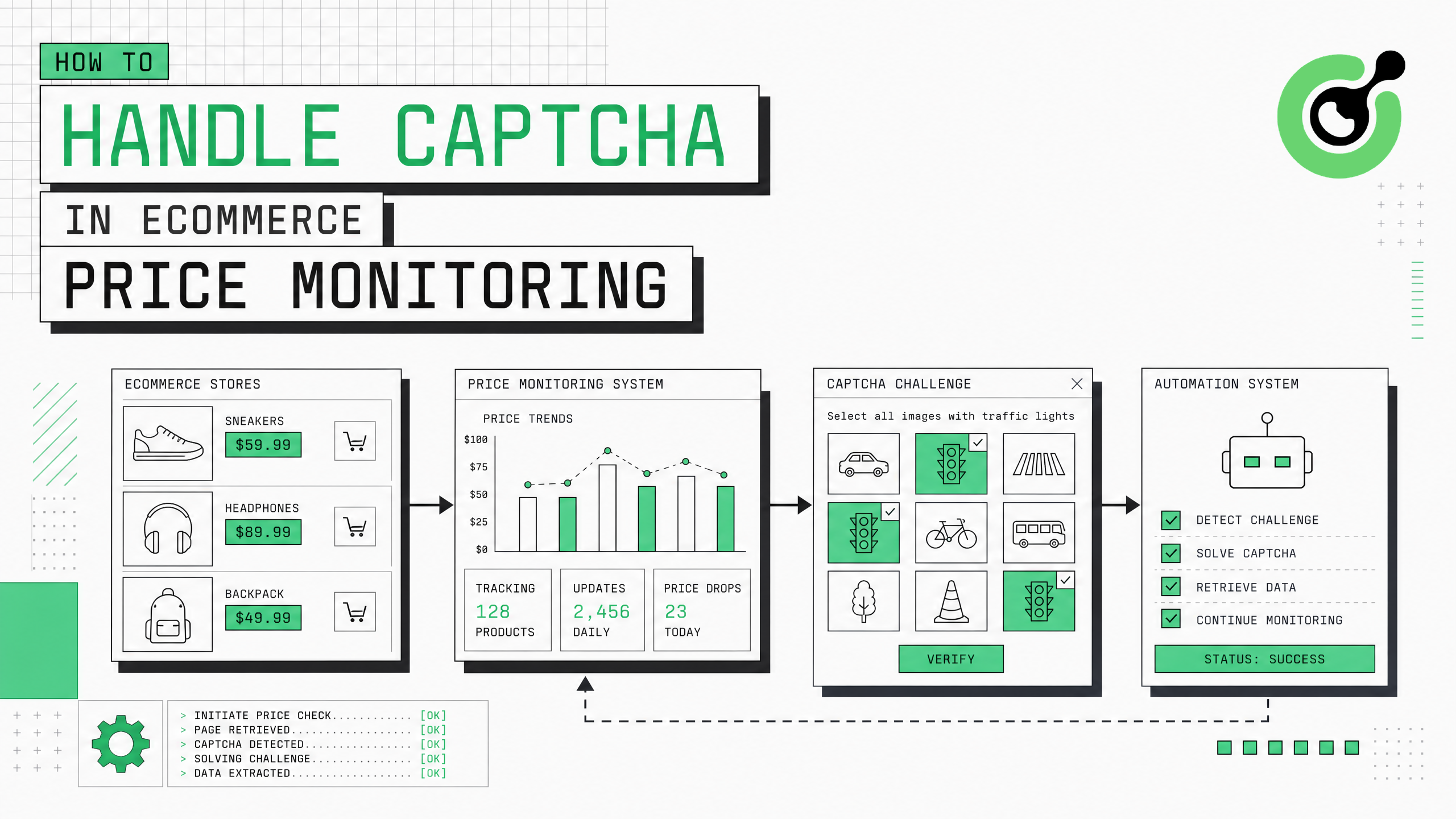
如何处理电子商务价格监控中的CAPTCHA
电子商务价格监控对于竞争情报、MAP合规性和动态定价策略至关重要。但最大的技术障碍是CAPTCHA——亚马逊、沃尔玛和塔吉特等零售商部署了激进的机器人保护措施,几分钟内就会阻止自动价格抓取器。本指南提供了将CAPTCHA求解集成到电子商务价格监控流程中的完整操作步骤,涵盖检测策略、API集成、会话管理和扩展性,以每天监控数千个SKU而不会中断。
TL;DR
- 主要电商平台部署reCAPTCHA、Cloudflare Turnstile和自定义挑战,在10-50次自动请求后触发。
- 忽略CAPTCHA处理的价格监控机器人会损失40-60%的数据收集尝试,导致竞争情报出现空白。
- CapSolver可在3-12秒内解决电子商务CAPTCHA,保持价格跟踪流程的持续数据流。
- 有效的实现结合CAPTCHA求解、代理轮换、会话管理和请求限速,以维持持续访问。
- 配置正确的流程每天可在多个零售商处监控10,000+ SKU,CAPTCHA求解成本低于15美元/天。
引言
大规模价格监控需要每天多次访问数十个电子商务平台的产品页面。根据Statista的数据,2024年全球电子商务销售额超过6.3万亿美元,竞争性定价是购买决策的主要驱动因素。零售商为应对这种竞争压力,部署了越来越复杂的机器人保护措施。没有CAPTCHA处理的价格监控系统本质上是不可靠的——它会在竞争对手最活跃的精确时间段内错过价格变化。本指南展示了如何构建一个具有CAPTCHA弹性的价格监控流程,以提供一致且完整的数据。
开始前需要准备的事项
在将CAPTCHA处理添加到价格监控系统之前,请准备以下组件:
- 一个CapSolver账户并配置API访问
- 你现有的爬虫框架(Scrapy、Playwright、Puppeteer或自定义HTTP客户端)
- 代理池,包含住宅或ISP代理(数据中心代理更容易触发CAPTCHA)
- 目标零售商列表并识别CAPTCHA类型(使用CapSolver的浏览器扩展进行识别)
- 用于存储价格历史数据的数据库或存储系统
- 对网络爬虫最佳实践的理解,包括速率限制和会话管理
第1步 — 在目标电子商务网站上识别CAPTCHA模式
要做什么
每个电子商务平台都有不同的CAPTCHA触发和挑战类型。在构建集成之前,请先映射这些模式:
- 通过编程访问每个目标零售商并记录CAPTCHA出现的时间(在N次请求后、特定页面类型上或基于浏览模式)。
- 识别部署的CAPTCHA系统——检查页面源代码中的reCAPTCHA、Cloudflare、DataDome、PerimeterX或自定义解决方案。
- 注意CAPTCHA是基于会话的(每个会话解决一次)还是基于请求的(每个页面解决一次)。
- 记录任何其他机器人检测信号,如JavaScript指纹或行为分析。
常见的电子商务CAPTCHA模式:
| 零售商类型 | 保护系统 | CAPTCHA触发 | 挑战类型 |
|---|---|---|---|
| 亚马逊规模的市场 | 自定义 + reCAPTCHA | 每会话20-50次请求 | 图像选择网格 |
| 中端零售商 | Cloudflare | 会话开始 + 速率限制 | 不可见的Turnstile |
| 时尚/奢侈品品牌 | DataDome | 行为分析 | 自定义滑块 |
| 电子产品零售商 | PerimeterX | 指纹不匹配 | reCAPTCHA v3 |
| 超市/本地零售商 | reCAPTCHA v2 | 每个搜索查询 | 复选框 + 图像 |
为什么这很重要
了解触发模式可以让你通过智能请求调度最小化CAPTCHA遭遇。如果一个网站只在每会话30次请求后触发CAPTCHA,每25次请求轮换会话可以主动消除大多数挑战。无法避免的CAPTCHA则由求解API处理。
避免的常见错误
- 使用数据中心IP进行测试:数据中心IP范围的CAPTCHA触发阈值要低得多。使用生产中将使用的相同代理类型进行测试,以获得准确的触发数据。
- 忽略JavaScript挑战:一些网站在CAPTCHA之前会提供JavaScript挑战。如果你的爬虫不执行JavaScript,将永远无法到达CAPTCHA阶段,只会收到空响应。
第2步 — 构建CAPTCHA检测和求解层
要做什么
实现一个中间件层,检测CAPTCHA响应并自动解决:
python
import requests
from bs4 import BeautifulSoup
import time
CAPSOLVER_KEY = "your-api-key"
class EcommerceCaptchaHandler:
def __init__(self):
self.solve_count = 0
self.session_solves = {}
def detect_captcha(self, response):
"""检测响应是否包含CAPTCHA挑战。"""
# 检查常见的CAPTCHA指示器
if response.status_code == 403:
return True
if response.status_code == 503 and "challenge" in response.text.lower():
return True
soup = BeautifulSoup(response.text, 'html.parser')
# reCAPTCHA检测
if soup.find('div', class_='g-recaptcha'):
return True
if 'recaptcha' in response.text.lower():
return True
# Cloudflare检测
if soup.find('div', id='cf-challenge-running'):
return True
if 'cf-turnstile' in response.text:
return True
return False
def extract_captcha_params(self, response, url):
"""从页面中提取站点密钥和CAPTCHA类型。"""
soup = BeautifulSoup(response.text, 'html.parser')
# 尝试reCAPTCHA
recaptcha_div = soup.find('div', class_='g-recaptcha')
if recaptcha_div:
site_key = recaptcha_div.get('data-sitekey', '')
return {
"type": "ReCaptchaV2TaskProxyLess",
"websiteKey": site_key,
"websiteURL": url
}
# 尝试Cloudflare Turnstile
turnstile_div = soup.find('div', class_='cf-turnstile')
if turnstile_div:
site_key = turnstile_div.get('data-sitekey', '')
return {
"type": "AntiCloudflareTask",
"websiteKey": site_key,
"websiteURL": url
}
return None
def solve(self, captcha_params):
"""将CAPTCHA发送到CapSolver并获取令牌。"""
payload = {
"clientKey": CAPSOLVER_KEY,
"task": captcha_params
}
resp = requests.post("https://api.capsolver.com/createTask", json=payload)
task_id = resp.json().get("taskId")
if not task_id:
raise Exception(f"无法创建任务: {resp.json()}")
for _ in range(40):
result = requests.post("https://api.capsolver.com/getTaskResult", json={
"clientKey": CAPSOLVER_KEY,
"taskId": task_id
}).json()
if result.get("status") == "ready":
self.solve_count += 1
return result["solution"]
time.sleep(3)
raise TimeoutError("CAPTCHA求解超时")为什么这很重要
检测优先的方法意味着你的爬虫只在真正需要时调用CAPTCHA求解器。这显著减少了API成本——如果代理轮换和会话管理防止了70%的CAPTCHA,你只需支付剩余30%的求解费用。
避免的常见错误
- 解决不存在的CAPTCHA:一些403响应是IP封锁,而不是CAPTCHA。在发送求解请求之前,始终验证响应是否包含实际的CAPTCHA挑战。
- 不缓存会话令牌:如果网站使用基于会话的CAPTCHA(解决一次,适用于整个会话),存储已解决的会话cookie并在该会话的后续请求中重复使用它。
第3步 — 与你的价格爬虫流程集成
要做什么
将CAPTCHA处理器连接到你现有的价格监控工作流:
python
import asyncio
from typing import Optional, Dict
class PriceMonitor:
def __init__(self, captcha_handler: EcommerceCaptchaHandler):
self.handler = captcha_handler
self.session = requests.Session()
self.prices = {}
def fetch_price(self, product_url: str, retry_count: int = 3) -> Optional[Dict]:
"""获取产品价格并自动处理CAPTCHA。"""
for attempt in range(retry_count):
response = self.session.get(product_url, headers={
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36"
})
if self.handler.detect_captcha(response):
# 检测到CAPTCHA - 解决它
params = self.handler.extract_captcha_params(response, product_url)
if params:
solution = self.handler.solve(params)
# 注入令牌并重试
token = solution.get("gRecaptchaResponse") or solution.get("token")
# 使用解决的令牌重新请求
response = self.submit_with_token(product_url, token)
if response.status_code == 200 and not self.handler.detect_captcha(response):
return self.extract_price(response)
time.sleep(2 ** attempt)
return None
def extract_price(self, response) -> Dict:
"""从产品页面中提取价格数据。"""
soup = BeautifulSoup(response.text, 'html.parser')
# 实现因零售商而异
price_elem = soup.find('span', class_='price')
return {
"price": price_elem.text if price_elem else None,
"timestamp": time.time(),
"available": True
}为什么这很重要
将CAPTCHA处理直接集成到获取循环中意味着你的价格监控可以自主运行。当出现CAPTCHA时,它会透明地被解决,无需人工干预或流程失败。这对于时间敏感的价格监控至关重要,因为即使错过竞争对手价格变化几小时也会影响收入。
避免的常见错误
- 未区分产品页面和搜索页面:搜索结果页面通常与单个产品页面有不同的CAPTCHA阈值。分别监控两者并相应调整请求模式。
- 忽略价格页面重定向:一些零售商会将用户重定向到CAPTCHA页面而不是直接显示它。检查响应中的URL变化以指示重定向到挑战页面。
代理轮换如何与价格监控中的CAPTCHA求解协同工作
代理轮换和CAPTCHA求解是互补策略,而不是替代方案。轮换代理通过将请求分布在许多IP地址上,减少CAPTCHA频率,使每个IP看起来请求量低。当CAPTCHA仍然出现(这在受保护严格的网站上会发生),CAPTCHA求解器会立即处理它们。最佳配置使用住宅代理,每IP轮换间隔5-10次请求,结合CapSolver处理仍触发挑战的10-30%请求。CapSolver的关于网络爬虫中解决CAPTCHA的指南提供了结合这些方法的额外背景信息。最佳代理服务的比较可以帮助你选择适合监控需求的代理提供商。
第4步 — 通过并发求解扩展到数千个SKU
要做什么
对于监控10,000+产品,实现并发CAPTCHA求解并进行适当的资源管理:
python
import asyncio
import aiohttp
from asyncio import Semaphore
class ScalablePriceMonitor:
def __init__(self, max_concurrent_solves=15, max_concurrent_requests=50):
self.solve_semaphore = Semaphore(max_concurrent_solves)
self.request_semaphore = Semaphore(max_concurrent_requests)
self.daily_stats = {"requests": 0, "captchas": 0, "solved": 0, "failed": 0}
async def monitor_product(self, product_url, session):
"""以速率限制监控单个产品。"""
async with self.request_semaphore:
response = await session.get(product_url)
if self.is_captcha(await response.text()):
self.daily_stats["captchas"] += 1
async with self.solve_semaphore:
token = await self.async_solve_captcha(product_url, await response.text())
if token:
self.daily_stats["solved"] += 1
return await self.retry_with_token(product_url, token, session)
else:
self.daily_stats["failed"] += 1
return None
self.daily_stats["requests"] += 1
return await self.parse_price(await response.text())
async def run_monitoring_cycle(self, product_urls):
"""运行所有产品的完整监控周期。"""
async with aiohttp.ClientSession() as session:
tasks = [self.monitor_product(url, session) for url in product_urls]
results = await asyncio.gather(*tasks, return_exceptions=True)
success_count = sum(1 for r in results if r and not isinstance(r, Exception))
print(f"周期完成: {success_count}/{len(product_urls)} 个价格已收集")
print(f"遇到的CAPTCHAs: {self.daily_stats['captchas']}, "
f"已解决: {self.daily_stats['solved']}")
return results为什么这很重要
按顺序处理10,000个产品,每个请求2秒,需要超过5.5小时。通过50个并发请求和自动CAPTCHA处理,相同的监控周期可在30分钟内完成。信号量模式防止过度负载CAPTCHA求解API,同时保持高吞吐量。
避免的常见错误
- 无限并发求解: 同时发送100个验证码任务可能会触发API速率限制并增加失败率。将并发求解限制在10-20个以获得最佳成功率。
- 无断路器: 如果零售商更改了他们的保护系统且所有验证码都失败,您的流水线应检测到此模式并暂停对该零售商的请求,而不是在无法解决的挑战上消耗API积分。
对比:价格监控方法与验证码处理
| 方法 | 验证码处理 | 每日SKU容量 | 数据完整性 | 每月成本(10K SKU) |
|---|---|---|---|---|
| 手动浏览 | 人工解决 | 50-200 | 95%+(缓慢) | $3,000-$5,000(人工) |
| 基础爬虫(无验证码) | 无——遇到挑战会失败 | 10,000+ | 40-60% | $50-$100(仅基础设施) |
| 爬虫 + CapSolver | 自动API解决 | 10,000+ | 95-99% | $150-$400(基础设施 + API) |
| 企业级监控SaaS | 内置(不透明) | 可变 | 90-95% | $2,000-$10,000 |
领取您的优惠码: 在CapSolver仪表板使用代码WEBS,每次充值可额外获得5%的奖金。非常适合正在扩展价格监控业务的电商团队。
步骤5 — 监控流水线健康状况并优化成本
应该怎么做
实施CAPTCHA求解预算的成本跟踪和优化:
- 跟踪每个零售商的验证码遭遇率——如果某个网站的遭遇率突然上升,调查是否需要调整请求模式。
- 计算每个成功价格数据点的成本:总CAPTCHA API支出除以成功提取的价格数据量。
- 实施智能调度:更频繁地监控高优先级产品(您的商品、顶级竞争对手),低优先级产品则较少监控。
- 使用CapSolver的响应时间优化技术以减少单次求解延迟并提高吞吐量。
- 设置每日成本警报:如果支出超过预期每日预算的150%,调查是否存在异常。
为什么这很重要
如果零售商增加挑战频率或爬虫中的错误导致不必要的页面刷新,未受控制的CAPTCHA求解成本会迅速上升。主动监控成本能确保您的价格监控业务保持盈利。
应避免的常见错误
- 过于频繁地监控同一产品: 如果产品每天只变化一次,每5分钟检查一次价格会浪费CAPTCHA求解次数。根据历史价格变化模式调整监控频率。
- 不跟踪投资回报率: 如果监控特定零售商的CAPTCHA求解成本超过了其价格数据带来的收益,考虑减少监控频率或放弃该来源。
结论
在电商价格监控中处理CAPTCHA需要分层方法:通过智能会话管理和代理轮换减少CAPTCHA遭遇次数,然后通过CapSolver的API自动解决不可避免的挑战。五步框架——映射CAPTCHA模式、构建检测层、与爬虫流水线集成、通过并发控制扩展、监控成本——创建了一个可生产使用的系统,每天可靠地收集数千SKU的价格数据。CapSolver支持电商平台上遇到的所有主要CAPTCHA类型,结合12秒以内的求解时间,使其成为需要持续数据完整性的价格监控团队的实用选择。
今天就在CapSolver上构建您的抗验证码价格监控流水线。
常见问题
监控10,000个产品时,您应该预期多少验证码?
通过适当的代理轮换和会话管理,根据目标零售商的不同,预期验证码遭遇率为10-30%。对于每天10,000次产品检查,这相当于每天1,000-3,000次验证码求解。CapSolver的定价为每1,000次求解1.5-3.0美元,因此每天的验证码成本在1.50到9.00美元之间。像亚马逊这样的高保护网站可能会有更高的比率,而较小的零售商可能很少触发挑战。
我可以监控亚马逊价格而不被封锁吗?
亚马逊使用验证码挑战和基于IP的速率限制。成功监控需要住宅代理、真实的浏览器指纹、每页之间3-10秒的请求延迟,以及自动解决仍会出现的验证码。CapSolver能有效处理亚马逊的图像网格reCAPTCHA挑战。关键是保持每IP的请求量低于亚马逊的检测阈值,同时将验证码解决作为安全网。
电商价格爬取合法吗?
显示在电商网站上的公开价格数据通常被视为公开信息。hiQ v. LinkedIn裁决确立了爬取公开数据不违反CFAA。然而,您应查阅每个零售商的使用条款,实施合理的速率限制,并避免访问任何认证或受限区域。仅将价格监控用于合法的市场竞争情报目的。
当零售商更换验证码提供商时会发生什么?
零售商验证码更改很常见——一个网站可能从reCAPTCHA迁移到Cloudflare Turnstile或部署DataDome。您的监控系统应通过步骤5中的健康监控检测到失败率增加并通知您的团队。由于CapSolver支持所有主要验证码类型,修复通常涉及在验证码配置中更新任务类型参数。维护一个模块化的检测系统,能够自动识别新的验证码类型。