如何解决网页抓取中的CAPTCHAs 2024

Anh Tuan
Data Science Expert

TL;DR:CAPTCHA 是“全自动公共图灵测试以区分计算机和人类”的缩写,是网站为区分人类用户和自动机器人而实施的安全措施。这些挑战旨在防止恶意活动,如垃圾邮件和数据爬取。然而,随着技术的进步和 CAPTCHA 解决服务的出现,网络爬虫中解决 CAPTCHA 已经成为可能。
什么是 CAPTCHA
CAPTCHA,即“全自动公共图灵测试以区分计算机和人类”,是网站为区分人类用户和自动机器人而实施的安全措施。CAPTCHA 作为门禁系统,通过验证用户身份来防止恶意活动。这些挑战通常包括呈现扭曲的字符、图像或谜题,这些内容对人类来说容易解决,但对机器来说却很困难。
CAPTCHA 的主要目的是防止垃圾邮件、数据爬取和暴力破解攻击等行为。通过引入只有人类可以解决的测试,网站确保其提供的信息由真实用户访问和使用,同时阻止自动机器人。通过要求用户成功完成这些挑战,网站可以验证访问其内容的实体是人类而不是自动脚本。
不同类型的 CAPTCHA
如今,CAPTCHA 挑战有多种形式和变体,以下是一些你经常遇到的常见类型:
-
ReCaptcha V2&v3:ReCaptcha 是由 Google 开发的一种广泛使用的 CAPTCHA 系统。它包括多种类型,如选择与给定描述匹配的图片或解决谜题。

-
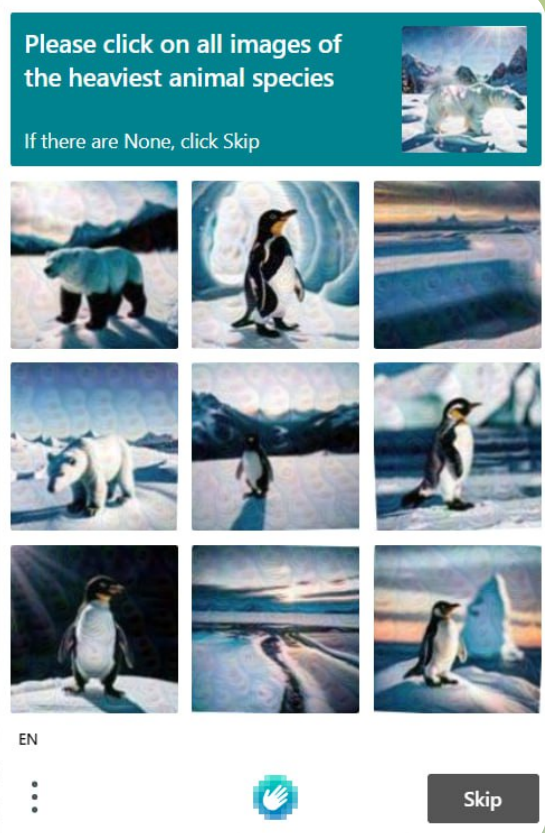
captcha:captcha 在 CAPTCHA 变体中独树一帜,它为用户提供有趣且互动的谜题。与传统的基于文本的挑战不同,captcha 会向用户展示视觉上吸引人的任务,如选择特定的物体或解决谜题。这种方法在保持高安全性的前提下提升了用户体验。
-
captcha:captcha 与 ReCaptcha 非常相似,主要区别在于 captcha 允许多个公司从用户在与网站互动时进行的数据标注中获益。而使用 ReCaptcha 时,只有 Google 能从众包数据标注的集体努力中受益。
-
基于文本的 CAPTCHA,基于文本的 CAPTCHA 也是常见的一种 CAPTCHA 形式,要求用户正确识别并输入以扭曲或创意字体显示的一系列字符。然后根据回答的准确性决定是否允许访问网站。
-
基于声音的 CAPTCHA
这种 CAPTCHA 也称为音频 CAPTCHA,它提供一个包含字母或数字的音频片段,用户需要分离并输入。这种 CAPTCHA 通常伴有背景噪音,以增加识别难度。 -
基于图像的 CAPTCHA,在基于图像的 CAPTCHA 中,用户必须识别并正确与图像互动才能获得访问权限。这些图像挑战具有视觉吸引力,对自动脚本来说具有挑战性,因为它们需要复杂的图像识别能力,这通常超出自动脚本的能力范围。
网络爬虫中可以解决 CAPTCHA 吗?
虽然 CAPTCHA 是为机器人设计的挑战,但存在一些方法和技术可以在网络爬虫中解决它们。随着时间的推移,CAPTCHA 技术已经进化,同时解决它的技术也在发展。随着技术的进步,包括人工智能,已经开发出自动解决方案来处理 CAPTCHA 挑战。然而,需要注意的是,这些解决方案的效果会因 CAPTCHA 实现的复杂性和安全措施而异。
市场上的一个显著解决方案是 CapSolver,它结合了速度、准确性、覆盖范围和成本效益。如以下更详细的解释所示
如何在网页爬取中解决 CAPTCHA
在进行网页爬取时,解决 CAPTCHA 挑战有几种方法。
利用 CAPTCHA 解决服务
作为额外的安全措施,网站通常会实施 CAPTCHA 来验证用户是人类而不是自动机器人。用 Python 进行高级网页爬取时,程序化解决 CAPTCHA 是一个关键方面。
将可靠的 CAPTCHA 解决服务如 CapSolver 集成到你的网页爬取流程中,可以简化解决这些挑战的过程。CapSolver 提供 API 和工具,可以程序化地解决各种类型的 CAPTCHA,使你的 Python 脚本能够无缝集成。
通过利用 CapSolver 的先进 CAPTCHA 解决能力,你可以克服这些障碍,即使在有强大安全措施的网站上也能确保成功提取数据。
领取 CapSolver 优惠码
立即提升你的自动化预算!
在充值 CapSolver 账户时使用优惠码 CAPN,每次充值可获得额外 5% 的奖励 —— 没有上限。
现在在你的 CapSolver 仪表板 中领取
。
使用高质量代理:
代理轮换可以作为解决 CAPTCHA 的一种方法,尽管其效果可能不如前面提到的其他方法。许多网站会对每个 IP 地址的请求数量进行限制,并可能向超过这些限制的用户显示 CAPTCHA。
通过使用代理轮换策略,可以隐藏你的 IP 地址,防止服务器识别请求的来源。这允许你进行隐蔽的网页爬取活动,并降低因 IP 被封而造成运行时中断的可能性。然而,处理 CAPTCHA 时请确保使用高质量的代理,因为免费代理通常无法使用。
使用网页爬取 API:
绕过 CAPTCHA 的一种高效方法是利用网页爬取 API。这些 API 提供对预爬取数据的访问,使你可以在不遇到 CAPTCHA 挑战的情况下提取信息。通过与网页爬取 API 服务集成,你可以简化爬取过程并专注于数据提取。
使用无头浏览器:
无头浏览器提供了一种在没有可见用户界面的情况下与网站进行自动交互的方法,因此是解决 CAPTCHA 的有效工具。通过在后台运行,无头浏览器可以执行自动任务,同时避免依赖用户界面的检测机制,如 CAPTCHA 挑战。
识别隐藏陷阱:
要成功解决 CAPTCHA,需要了解并克服隐藏陷阱。这些陷阱可能包括不可见的表单字段或基于 JavaScript 的挑战,这些设计用于检测机器人。通过了解并绕过这些陷阱,自动系统可以顺利通过而不触发额外的安全措施。
模拟人类行为:
为了避免被检测到并更像一个真实用户,应实施模拟人类行为的技术。这包括复制鼠标移动、滚动模式和输入速度。通过模拟这些操作,自动系统可以使其与网站的交互显得更自然,从而降低被标记为机器人的可能性。
管理 Cookie:
在自动化交互过程中,保存和管理 Cookie 对于保持会话信息至关重要。Cookie 存储如登录凭证和会话令牌等数据,可用于解决 CAPTCHA 并访问受限内容。通过正确处理 Cookie,自动系统可以保持必要的信息,以通过 CAPTCHA 保护的网站区域。
持续适应:
CAPTCHA 技术和安全措施在不断进化。为了保持领先,必须持续适应和更新 CAPTCHA 解决方法。跟上最新进展并积极研究新方法将有助于确保自动系统在解决 CAPTCHA 时的有效性。
使用 Python 通过 CapSolver 解决任何 CAPTCHA:
前提条件
- 一个可用的代理
- 安装了 Python
- CapSolver API 密钥
🤖 第1步:安装必要包
执行以下命令以安装所需包:
pip install capsolver
这是一个 reCAPTCHA v2 的示例:
👨💻 使用代理解决 reCAPTCHA v2 的 Python 代码
以下是一个 Python 示例脚本:
python
import capsolver
# 建议使用环境变量存储敏感信息
PROXY = "http://username:password@host:port"
capsolver.api_key = "你的 CapSolver API 密钥"
PAGE_URL = "PAGE_URL"
PAGE_KEY = "PAGE_SITE_KEY"
def solve_recaptcha_v2(url,key):
solution = capsolver.solve({
"type": "ReCaptchaV2Task",
"websiteURL": url,
"websiteKey":key,
"proxy": PROXY
})
return solution
def main():
print("解决 reCaptcha v2")
solution = solve_recaptcha_v2(PAGE_URL, PAGE_KEY)
print("解决方案:", solution)
if __name__ == "__main__":
main()👨💻 使用无代理解决 reCAPTCHA v2 的 Python 代码
以下是一个 Python 示例脚本:
python
import capsolver
# 建议使用环境变量存储敏感信息
capsolver.api_key = "你的 CapSolver API 密钥"
PAGE_URL = "PAGE_URL"
PAGE_KEY = "PAGE_SITE_KEY"
def solve_recaptcha_v2(url,key):
solution = capsolver.solve({
"type": "ReCaptchaV2TaskProxyless",
"websiteURL": url,
"websiteKey":key,
})
return solution
def main():
print("解决 reCaptcha v2")
solution = solve_recaptcha_v2(PAGE_URL, PAGE_KEY)
print("解决方案:", solution)
if __name__ == "__main__":
main()最后想法
CAPTCHA 是网站区分人类和自动机器人的重要防御机制。虽然它们对网络爬虫构成挑战,但有各种技术可以有效解决 CAPTCHA。通过利用先进的 CAPTCHA 解决服务、使用无头浏览器和模拟人类行为,网络爬虫可以克服 CAPTCHA 障碍,高效且有效地提取有价值的数据。随着 CAPTCHA 技术的持续发展,网络爬虫必须保持更新并调整其技术,以确保成功提取数据。
常见问题
1. 解决 CAPTCHA 是否合法?
是的,以合理速率通过解决 CAPTCHA 访问公开页面,不损害网站或违反网站规则是合法的。
2. 为什么在网页爬取中解决 CAPTCHA 很重要?
在网页爬取中解决 CAPTCHA 很重要,因为它使自动化从网站提取数据成为可能,而不会受到这些安全措施的阻碍。通过解决 CAPTCHA,网页爬虫可以节省时间和精力,从而高效地收集各种项目所需的信息。



