
The Other CAPTCHAJul 25, 2024
Scrapy对比Selenium:哪个最适合您的网络爬虫项目
探索Scrapy和Selenium在网络爬虫方面的优势和差异。了解哪种工具最适合您的项目,以及如何应对验证码等挑战。


reCAPTCHAJul 25, 2024
如何使用Python和Selenium解决reCAPTCHA
我们将深入探讨如何使用Python和Selenium来解决reCAPTCHA,为开发人员和数据科学家提供一条高效的解决方案。

CloudflareJul 16, 2024
如何解决 Cloudflare Turnstile 验证码:最佳验证码解决方案
在本文中,我们将探讨解决 Cloudflare Turnstile 的最佳解决方案,确保您的操作保持不中断和高效。

The Other CAPTCHAJul 16, 2024
API vs 网页抓取:获取数据的最佳方式
了解 Web Scraping 和 API Scraping 的区别、优点和缺点,从而选择最佳数据收集方法。探索 CapSolver 的机器人挑战解决方案。

The Other CAPTCHAJul 10, 2024
Puppeteer 是什么以及如何在网络抓取中使用它 | 2024 完整指南
本完整指南将深入探讨什么是 Puppeteer 以及如何在网络搜索中有效使用它。

The Other CAPTCHAJul 05, 2024
什么是网络抓取|常见用例和问题
了解网络抓取:了解其优势,轻松应对挑战,利用 CapSolver 促进业务发展。
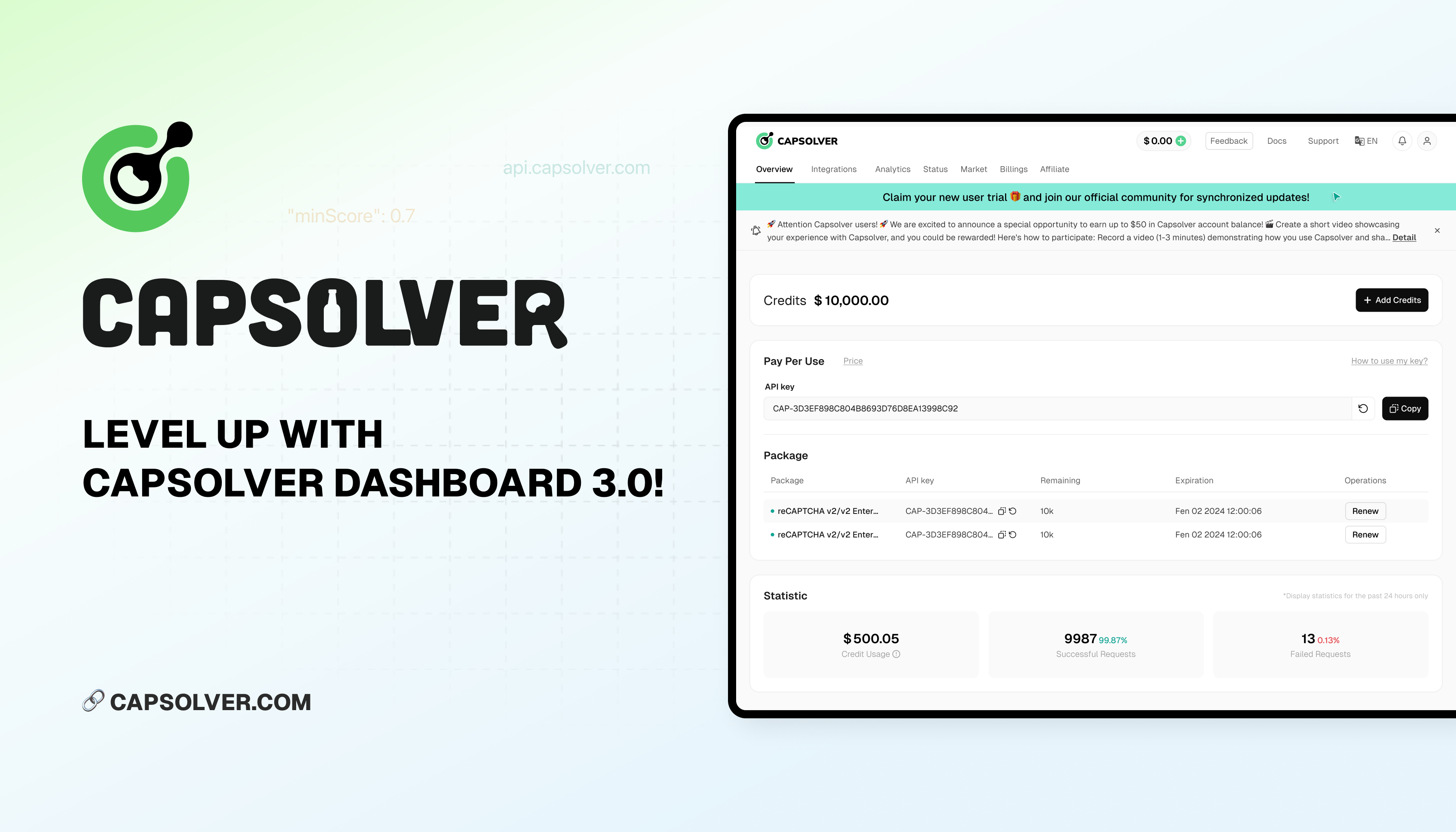
The Other CAPTCHAJul 04, 2024
提升体验:升级到 CapSolver 仪表板 3.0!
CapSolver Dashboard 3.0 经过全新升级,增强了互动性并增加了大量新功能。

The Other CAPTCHAJul 03, 2024
如何解决滑块验证码 | 最佳滑块拼图验证码解决方案
在本指南中,您将了解如何高效地解决滑块验证码问题,让您迅速成为滑块谜题验证码专家。

The Other CAPTCHAJun 26, 2024
如何快速解决验证码图像问题 | 最佳图像(OCR)验证码解决工具
本文将揭示最佳图像 (OCR) 验证码解决方案,让您轻松应对这些挑战!

The Other CAPTCHAJun 19, 2024
使用 Selenium 和 Python 进行网络抓取 | 解决网络抓取时的验证码问题
在这篇文章中,你将掌握使用 Selenium 和 Python 进行网络刮擦的方法,并学习如何解决该过程中涉及的验证码问题,以实现高效的数据提取。

The Other CAPTCHAJun 17, 2024
使用 Cheerio 和 Node.js 进行网络搜刮 2024
2024 年,使用 Cheerio 和 Node.js 进行 Web scraping 仍然是一种强大的数据提取技术。本指南包括设置项目、使用 Cheerio 的选择器 API、编写和运行脚本,以及处理验证码和动态页面等挑战。

ExtensionJun 17, 2024
最佳Google Chrome扩展和Mozilla Firefox扩展自动解决验证码
通过使用为谷歌浏览器和火狐浏览器设计的一些扩展程序,我们可以轻松实现这一过程的自动化,从而节省宝贵的时间和精力