ReCAPTCHA在电子商务抓取中的应用:以合规为先的指南

Ethan Collins
Pattern Recognition Specialist
要点总结
- 当电商平台需要更强的信任验证时会出现ReCAPTCHA。
- 将ReCAPTCHA视为工作流信号,而不仅仅是谜题。
- 首先检查权限、robots.txt、条款和数据范围。
- 通过控制节奏和稳定会话来减少不必要的挑战。
- 有官方API或数据源时优先使用。
- 仅在合法自动化和授权数据工作中使用CapSolver。
- 为每个爬虫记录日志、速率限制和升级规则。
引言
在电商数据抓取中处理ReCAPTCHA应以合规为首要原则。正确的做法不是更激进的爬取,而是更干净的工作流,尊重权限、减少噪音流量,并在允许的情况下使用已记录的解决步骤。本指南适用于数据工程师、SEO团队、定价分析师和增长团队,他们负责任地收集公开的电商数据。它解释了ReCAPTCHA出现的原因、何时需要减速,以及CapSolver在合法流程中的适用性。
为什么电商爬虫会遇到ReCAPTCHA
ReCAPTCHA出现是因为电商平台保护有价值客户和业务流程。产品页面、搜索页面、购物车和登录页面都存在商业风险。Google将ReCAPTCHA描述为一种服务,通过使用高级风险分析来区分人类和机器人,通过信号和评分来保护网站免受垃圾邮件和滥用 Google ReCAPTCHA文档。
电商团队添加ReCAPTCHA是因为自动化流量现在很常见。Thales和Imperva报告称,2024年自动化流量占网络流量的51%。他们还报告称,有害的自动化活动占互联网流量的37%,而API定向攻击占高级机器人流量的44% 2025年Imperva恶意机器人报告。这种背景解释了为什么网站会迅速挑战异常的爬取模式。
ReCAPTCHA也常见于支付和账户流程附近。Google Cloud表示,ReCAPTCHA的交易防护可帮助保护支付交易免受卡验证攻击和欺诈交易 Google Cloud交易防护。触碰购物车、结账或账户页面的爬虫会面临比公开产品监控更严格的检查。
第一条规则:确认数据是允许的
合规性应先于技术更改。爬虫应仅收集公开、授权和必要的数据。应避免在没有明确授权的情况下访问登录页面、私有客户数据、结账步骤和受限区域。
机器人排除协议也很重要。RFC 9309表示robots.txt为服务所有者提供了一种控制爬虫访问URI空间的方法,爬虫应请求遵守这些规则 RFC 9309机器人排除协议。robots.txt不是唯一的法律测试。但负责任的爬虫应在运行前解析它。
在处理ReCAPTCHA之前,应记录四项内容。定义业务目的、源页面、数据字段、允许的路径、条款、请求限制、并发性和保留期。这使ReCAPTCHA处理成为受监管的数据流程。
CapSolver的什么是ReCAPTCHA指南可以帮助利益相关者了解挑战类型。
诊断ReCAPTCHA类型
诊断应在代码更改之前进行。ReCAPTCHA v2通常以复选框或视觉挑战的形式出现。ReCAPTCHA v3通常返回一个分数而无需用户交互,因此页面可能会降级、阻止操作或稍后要求更强的检查。Google指出,ReCAPTCHA v3返回的分数使网站所有者可以选择不向用户显示挑战的操作 Google ReCAPTCHA v3概述。
| 情况 | 可能的含义 | 推荐响应 |
|---|---|---|
| 在许多快速请求后出现挑战 | 流量模式看起来异常 | 降低并发性并添加节奏控制 |
| 挑战仅出现在登录或结账时 | 页面风险较高 | 除非明确授权,否则停止 |
| 挑战出现在公开产品页面上 | 会话或请求模式需要审查 | 稳定cookie并减少突发请求 |
| v3分数导致空页面或降级页面 | 信任分数较低 | 审查浏览器上下文和请求节奏 |
| 挑战出现在重定向后 | 流程状态不一致 | 保持会话和页面顺序 |
这种诊断也可以控制成本。一个更冷静的爬虫通常会触发更少的挑战并返回更干净的电商数据。
对比总结
一个有用的电商爬虫应从最不侵入性的选项开始。下表比较了常见选择。
| 方法 | 最佳使用场景 | 合规注意事项 | 操作风险 | 成本概况 |
|---|---|---|---|---|
| 官方API或商家数据源 | 合作数据访问 | 可用时的最佳选择 | 低 | 可预测 |
| 带节奏的公开页面爬取 | 公开产品和价格监控 | 尊重robots.txt和条款 | 中 | 低到中 |
| 浏览器自动化 | JavaScript密集型产品页面 | 避免受限流程 | 中 | 中 |
| 人工审核队列 | 罕见的高价值检查 | 强审计跟踪 | 低 | 更高的劳动力成本 |
| CapSolver集成 | 遇到ReCAPTCHA的授权自动化 | 仅用于合法、无害的工作流程 | 中 | 按使用量计费 |
表格显示了一个实际的要点。ReCAPTCHA应作为爬虫内部的例外路径,爬虫尊重规则和限制。
构建更清洁的电商数据抓取工作流
更清洁的工作流减少了不必要的ReCAPTCHA事件。从页面选择开始。仅爬取公开和允许的类别或产品页面。除非企业拥有账户并获得授权,否则避免将商品添加到购物车、提交表单或打开账户页面。
接下来,控制流量形状。使用适度的并发性、退避规则和稳定的调度。电商网站在促销、发布和节假日高峰期间对敏感。尊重这些窗口的爬虫不太可能造成运营压力。
会话处理也很重要。在短时间爬取期间保持cookie一致。不要在一个会话中混合不相关的页面流程。产品发现路径不应突然请求结账页面。这种模式可能导致ReCAPTCHA出现。
跟踪挑战率、空页面、HTTP代码、价格解析失败和重复项。ReCAPTCHA率上升是早期预警。
如果您的团队在直接爬取和官方数据访问之间进行选择,这篇CapSolver文章网络爬取与API是内部讨论的有用链接。
CapSolver的适用场景
CapSolver适用于合法自动化流程在合规检查后遇到ReCAPTCHA的情况。它在SEO审计、广告验证和无害爬虫中很有用,当目标数据被允许时。CapSolver自己的立场指出,非法、欺诈或滥用活动是被禁止的,并将SEO、广告验证、无害爬虫和业务增长场景列为预期用途 CapSolver合规声明。
这一立场很重要。CapSolver集成绝不能针对私人账户、支付步骤、受限内容或明确不允许的数据。
当您的爬虫已经遵循了尊重的节奏但仍遇到允许的公共页面上的ReCAPTCHA时,CapSolver尤其相关。它可以帮助在不强制每次挑战都进行手动工作的情况下保持稳定的工作流。对于聚焦的电商场景,请参阅CapSolver的指南如何在爬取电商网站时解决CAPTCHAs。
官方CapSolver代码参考
以下代码遵循CapSolver官方文档中的ReCAPTCHA v2。在不检查当前文档的情况下,不要更改任务类型或参数。仅在授权的工作流程中使用,并使用有效的API密钥。
python
# pip install requests
import requests
import time
# TODO: set your config
api_key = "YOUR_API_KEY" # your api key of capsolver
site_key = "6Le-wvkSAAAAAPBMRTvw0Q4Muexq9bi0DJwx_mJ-" # site key of your target site
site_url = "https://www.google.com/recaptcha/api2/demo" # page url of your target site
def capsolver():
payload = {
"clientKey": api_key,
"task": {
"type": 'ReCaptchaV2TaskProxyLess',
"websiteKey": site_key,
"websiteURL": site_url
}
}
res = requests.post("https://api.capsolver.com/createTask", json=payload)
resp = res.json()
task_id = resp.get("taskId")
if not task_id:
print("Failed to create task:", res.text)
return
print(f"Got taskId: {task_id} / Getting result...")
while True:
time.sleep(1) # delay
payload = {"clientKey": api_key, "taskId": task_id}
res = requests.post("https://api.capsolver.com/getTaskResult", json=payload)
resp = res.json()
status = resp.get("status")
if status == "ready":
return resp.get("solution", {}).get('gRecaptchaResponse')
if status == "failed" or resp.get("errorId"):
print("Solve failed! response:", res.text)
return
token = capsolver()
print(token)官方CapSolver文档说明使用createTask创建任务,并使用getTaskResult检索结果。它还解释了websiteURL和websiteKey等字段是任务的必需字段。有关更多实现上下文,请阅读CapSolver的官方指南如何使用Python在网页爬取中解决ReCAPTCHA。
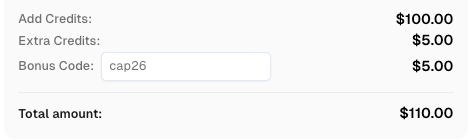
领取CapSolver优惠代码
立即提升您的自动化预算!
在充值CapSolver账户时使用优惠代码 CAP26,每次充值可获得额外 5% 的奖励 —— 没有限制。
现在在您的 CapSolver仪表板 中领取
生产环境的实用控制
生产环境的电商数据抓取需要非工程师可以审计的控制措施。在部署前创建爬虫策略。该策略应注明数据所有者、允许的域名、允许的路径、最大并发数、最大每日请求数、保留期和升级联系人。
使用ReCAPTCHA遇到率作为关键指标。如果该比率超过定义的阈值,请降低爬取速度或暂停。如果在受限流程中出现挑战,请停止任务。如果目标更改了robots.txt或条款,请在继续前审查爬虫。
保持数据范围狭窄。价格、可用性、标题、图片URL和公开评论数可能对某些业务案例有效。客户姓名、登录后的私有评论、购物车令牌和账户数据应排除在范围外,除非站点所有者已授权访问。
这也是备用队列有帮助的地方。爬虫可以存储未解决的页面以供审查,而不是反复重试。这一设计选择降低了负载、成本,并使ReCAPTCHA处理更具辩护性。
有关更多工程模式,CapSolver的文章三种解决CAPTCHA的方法可以支持实施计划。
需要避免的常见错误
第一个错误是将ReCAPTCHA仅视为技术障碍。它通常是爬虫过于广泛、过快或超出预期流程的标志。在添加工具之前修复工作流。
第二个错误是忽略页面上下文。电商网站对待搜索、产品、购物车、登录和结账页面的方式不同。您的爬虫也应如此。公开产品监控与账户自动化有不同的风险概况。
第三个错误是缺少审计日志。每个ReCAPTCHA事件都应记录URL组、时间戳、爬虫版本、响应代码和采取的操作。
第四个错误是使用过时的代码。ReCAPTCHA实现会变化。CapSolver文档应是代码结构、任务类型和所需字段的来源。
结论和CTA
电商数据抓取中的ReCAPTCHA最好通过治理、诊断和谨慎的工具处理。从权限检查、robots.txt、条款和数据最小化开始。然后通过节奏、稳定会话和有限范围减少不必要的挑战。如果在合法且授权的自动化流程中ReCAPTCHA仍然出现,CapSolver可以根据官方文档提供实用的解决层。
如果您的团队需要一种受控的方式来处理电商数据收集中的ReCAPTCHA,请查阅CapSolver文档,定义您的合规规则,并首先在低流量的公开页面上进行测试。负责任的爬虫应仅收集所需内容,规则变化时停止,并留下清晰的审计轨迹。
FAQ
在电商数据抓取中处理ReCAPTCHA是否合法?
这取决于权限、数据类型、司法管辖区和网站条款。更安全的工作流程使用公开允许的页面,遵守robots.txt,避免私有数据,并遵循记录的限制。商业项目进行法律审查是明智的。
为什么产品页面会出现ReCAPTCHA?
当请求量、会话历史、浏览器上下文或流量时间看起来异常时,ReCAPTCHA可能会出现。也可能是因为网站对价格和可用性页面应用了严格的保护。
我应该解决我看到的每个ReCAPTCHA吗?
不。高ReCAPTCHA率通常意味着爬虫需要审查。放慢速度,减少范围,检查允许的路径,并仅在授权的例外情况下使用解决方法。
CapSolver能帮助电商数据抓取吗?
是的,当合法的电子商务自动化工作流程遇到验证码时,CapSolver可以提供帮助。仅用于合法、良性且授权的数据工作,并遵循官方文档。
部署后我应该监控什么?
监控验证码速率、状态码、解析错误、流量、路径组和未解决的队列。当阈值被超过时暂停爬虫。