Cách giải Captchas khi quét web bằng Scrapling và CapSolver

Anh Tuan
Data Science Expert

Những điểm chính
- Scrapling là thư viện quét dữ liệu web mạnh mẽ với tính năng chống bot tích hợp và theo dõi phần tử thích ứng
- CapSolver cung cấp giải pháp tự động giải captcha cho ReCaptcha v2, v3 và Cloudflare Turnstile với thời gian giải nhanh (1-20 giây)
- Kết hợp Scrapling với CapSolver tạo ra giải pháp quét dữ liệu mạnh mẽ có thể xử lý hầu hết các trang web có bảo vệ captcha
- StealthyFetcher thêm tính năng chống phát hiện ở cấp độ trình duyệt khi các yêu cầu HTTP cơ bản không đủ
- Tất cả ba loại captcha sử dụng quy trình giống nhau của CapSolver: tạo nhiệm vụ → kiểm tra kết quả → chèn token
- Mã sản phẩm nên bao gồm xử lý lỗi, giới hạn tốc độ và tuân thủ điều khoản sử dụng trang web
Giới thiệu
Quét dữ liệu web đã trở thành công cụ thiết yếu cho thu thập dữ liệu, nghiên cứu thị trường và phân tích cạnh tranh. Tuy nhiên, khi các kỹ thuật quét phát triển, các biện pháp bảo vệ của trang web cũng được cải tiến. Trong số những trở ngại phổ biến nhất mà người quét phải đối mặt là captcha - những thử thách được thiết kế để phân biệt giữa người dùng và bot.
Nếu bạn từng cố gắng quét một trang web nhưng gặp thông báo "Vui lòng xác minh bạn là người thật", bạn sẽ hiểu sự khó chịu. Tin tốt là có một sự kết hợp mạnh mẽ có thể giúp: Scrapling cho quét dữ liệu thông minh và CapSolver cho giải captcha tự động.
Trong hướng dẫn này, chúng tôi sẽ hướng dẫn bạn mọi thứ cần biết để tích hợp các công cụ này và quét thành công các trang web có bảo vệ captcha. Dù bạn đang xử lý ReCaptcha v2 của Google, ReCaptcha v3 ẩn hoặc Cloudflare's Turnstile, chúng tôi sẽ hỗ trợ bạn.
Scrapling là gì?
Scrapling là thư viện quét dữ liệu web hiện đại mô tả bản thân là "thư viện quét thích ứng đầu tiên học hỏi từ các thay đổi của trang web và phát triển cùng chúng". Nó được thiết kế để trích xuất dữ liệu dễ dàng đồng thời cung cấp khả năng chống bot mạnh mẽ.
Tính năng chính
- Theo dõi phần tử thích ứng: Scrapling có thể tìm thấy nội dung ngay cả sau khi trang web được thiết kế lại bằng thuật toán tương đồng thông minh
- Nhiều phương pháp truy xuất: Yêu cầu HTTP với mô phỏng dấu vân tay TLS, tự động hóa trình duyệt và chế độ ẩn danh
- Bypass chống bot: Hỗ trợ tích hợp để vượt qua Cloudflare và các hệ thống chống bot khác bằng Firefox được sửa đổi và giả mạo dấu vân tay
- Hiệu suất cao: Các bài kiểm tra trích xuất văn bản cho thấy ~2ms cho 5000 phần tử lồng nhau, nhanh hơn nhiều so với nhiều lựa chọn khác
- Lựa chọn linh hoạt: CSS selectors, XPath, thao tác tìm kiếm kiểu BeautifulSoup và tìm kiếm dựa trên văn bản
- Hỗ trợ bất đồng bộ: Hỗ trợ đầy đủ async/await cho các thao tác quét đồng thời
Cài đặt
Đối với khả năng phân tích cơ bản:
bash
pip install scraplingĐối với các tính năng đầy đủ bao gồm tự động hóa trình duyệt:
bash
pip install "scrapling[fetchers]"
scrapling installĐối với tất cả các tính năng bao gồm AI:
bash
pip install "scrapling[all]"
scrapling installCách sử dụng cơ bản
Scrapling sử dụng phương thức lớp để thực hiện yêu cầu HTTP:
python
from scrapling import Fetcher
# Yêu cầu GET
response = Fetcher.get("https://example.com")
# Yêu cầu POST với dữ liệu
response = Fetcher.post("https://example.com/api", data={"key": "value"})
# Truy cập phản hồi
print(response.status) # Mã trạng thái HTTP
print(response.body) # Bytes thô
print(response.body.decode()) # Văn bản đã giải mãCapSolver là gì?
CapSolver là dịch vụ giải captcha sử dụng AI tiên tiến để tự động giải các loại captcha khác nhau. Nó cung cấp API đơn giản tích hợp liền mạch với bất kỳ ngôn ngữ lập trình nào hoặc khung quét dữ liệu.
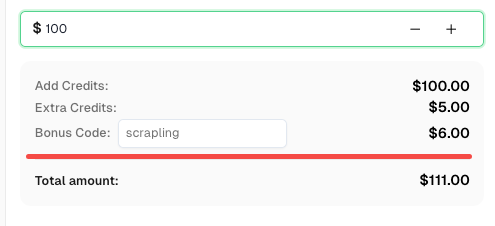
Tăng ngân sách tự động hóa ngay lập tức!
Sử dụng mã thưởng SCRAPLING khi nạp tiền cho tài khoản CapSolver để nhận thêm 6% thưởng cho mỗi lần nạp tiền — đặc biệt dành cho người dùng tích hợp Scrapling.
Nhận thưởng ngay bây giờ trong Bảng điều khiển CapSolver
Các loại captcha được hỗ trợ
- ReCaptcha v2 (hộp kiểm và vô hình)
- ReCaptcha v3 (dựa trên điểm số)
- ReCaptcha Enterprise (cả v2 và v3)
- Cloudflare Turnstile
- AWS WAF Captcha
- Và nhiều loại khác...
Lấy khóa API của bạn
- Đăng ký tại CapSolver
- Điều hướng đến bảng điều khiển của bạn
- Sao chép khóa API từ cài đặt tài khoản
- Nạp tiền vào tài khoản của bạn (giá theo lần giải)
Các điểm cuối API
CapSolver sử dụng hai điểm cuối chính:
- Tạo nhiệm vụ:
POST https://api.capsolver.com/createTask - Lấy kết quả:
POST https://api.capsolver.com/getTaskResult
Thiết lập hàm trợ giúp CapSolver
Trước khi đi vào các loại captcha cụ thể, hãy tạo một hàm trợ giúp tái sử dụng xử lý quy trình API CapSolver:
python
import requests
import time
CAPSOLVER_API_KEY = "YOUR_API_KEY"
def solve_captcha(task_type, website_url, website_key, **kwargs):
"""
Bộ giải captcha tổng quát sử dụng API CapSolver.
Args:
task_type: Loại nhiệm vụ captcha (ví dụ: "ReCaptchaV2TaskProxyLess")
website_url: URL của trang có captcha
website_key: Khóa trang cho captcha
**kwargs: Tham số bổ sung cụ thể cho loại captcha
Returns:
dict: Giải pháp chứa token và các dữ liệu khác
"""
payload = {
"clientKey": CAPSOLVER_API_KEY,
"task": {
"type": task_type,
"websiteURL": website_url,
"websiteKey": website_key,
**kwargs
}
}
# Tạo nhiệm vụ
response = requests.post(
"https://api.capsolver.com/createTask",
json=payload
)
result = response.json()
if result.get("errorId") != 0:
raise Exception(f"Không thể tạo nhiệm vụ: {result.get('errorDescription')}")
task_id = result.get("taskId")
print(f"Đã tạo nhiệm vụ: {task_id}")
# Kiểm tra kết quả
max_attempts = 60 # Tối đa 2 phút kiểm tra
for attempt in range(max_attempts):
time.sleep(2)
response = requests.post(
"https://api.capsolver.com/getTaskResult",
json={
"clientKey": CAPSOLVER_API_KEY,
"taskId": task_id
}
)
result = response.json()
if result.get("status") == "ready":
print(f"Captcha đã được giải trong {(attempt + 1) * 2} giây")
return result.get("solution")
if result.get("errorId") != 0:
raise Exception(f"Lỗi: {result.get('errorDescription')}")
print(f"Đang chờ... (lần thử {attempt + 1})")
raise Exception("Hết thời gian: Việc giải captcha mất quá lâu")Hàm này xử lý toàn bộ quy trình: tạo nhiệm vụ, kiểm tra kết quả và trả về giải pháp. Chúng tôi sẽ sử dụng nó trong phần còn lại của hướng dẫn này.
Giải ReCaptcha v2 với Scrapling + CapSolver
ReCaptcha v2 là captcha hộp kiểm "Tôi không phải là bot" cổ điển. Khi được kích hoạt, nó có thể yêu cầu người dùng xác định các đối tượng trong hình ảnh (đèn giao thông, vạch sang đường, v.v.). Đối với người quét, chúng ta cần giải nó một cách tự động.
Cách hoạt động của ReCaptcha v2
- Trang web tải script ReCaptcha với khóa trang duy nhất
- Khi gửi, script tạo ra g-recaptcha-response token
- Trang web gửi token này đến Google để xác minh
- Google xác nhận xem captcha có được giải đúng hay không
Tìm khóa trang
Khóa trang thường được tìm thấy trong mã HTML của trang:
html
<div class="g-recaptcha" data-sitekey="6LcxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxABCD"></div>Hoặc trong thẻ script:
html
<script src="https://www.google.com/recaptcha/api.js?render=6LcxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxABCD"></script>Triển khai
python
from scrapling import Fetcher
def scrape_with_recaptcha_v2(target_url, site_key, form_url=None):
"""
Quét trang được bảo vệ bởi ReCaptcha v2.
Args:
target_url: URL của trang có captcha
site_key: Khóa trang ReCaptcha
form_url: URL để gửi biểu mẫu (mặc định là target_url)
Returns:
Phản hồi từ trang được bảo vệ
"""
# Giải captcha bằng CapSolver
print("Đang giải ReCaptcha v2...")
solution = solve_captcha(
task_type="ReCaptchaV2TaskProxyLess",
website_url=target_url,
website_key=site_key
)
captcha_token = solution["gRecaptchaResponse"]
print(f"Đã nhận token: {captcha_token[:50]}...")
# Gửi biểu mẫu với token captcha bằng Scrapling
# Lưu ý: Sử dụng Fetcher.post() như một phương thức lớp (không phải phương thức đối tượng)
submit_url = form_url or target_url
response = Fetcher.post(
submit_url,
data={
"g-recaptcha-response": captcha_token,
# Thêm bất kỳ trường biểu mẫu nào cần thiết của trang web
}
)
return response
# Ví dụ sử dụng
if __name__ == "__main__":
url = "https://example.com/protected-page"
site_key = "6LcxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxABCD"
result = scrape_with_recaptcha_v2(url, site_key)
print(f"Trạng thái: {result.status}")
print(f"Độ dài nội dung: {len(result.body)}") # Sử dụng .body để nhận dữ liệu thôReCaptcha v2 Ẩn
Đối với ReCaptcha v2 ẩn (không có hộp kiểm, được kích hoạt khi gửi biểu mẫu), thêm tham số isInvisible:
python
solution = solve_captcha(
task_type="ReCaptchaV2TaskProxyLess",
website_url=target_url,
website_key=site_key,
isInvisible=True
)Phiên bản Doanh nghiệp
Đối với ReCaptcha v2 Doanh nghiệp, sử dụng loại nhiệm vụ khác:
python
solution = solve_captcha(
task_type="ReCaptchaV2EnterpriseTaskProxyLess",
website_url=target_url,
website_key=site_key,
enterprisePayload={
"s": "giá trị s nếu cần"
}
)Giải ReCaptcha v3 với Scrapling + CapSolver
ReCaptcha v3 khác với v2 - nó chạy ẩn trong nền và gán một điểm số (0.0 đến 1.0) dựa trên hành vi người dùng. Điểm số gần 1.0 cho thấy hành vi có thể là người thật.
Sự khác biệt chính so với v2
| Yếu tố | ReCaptcha v2 | ReCaptcha v3 |
|---|---|---|
| Tương tác người dùng | Hộp kiểm/đối tượng hình ảnh | Không có (ẩn) |
| Đầu ra | Thành công/thất bại | Điểm số (0.0-1.0) |
| Tham số hành động | Không bắt buộc | Bắt buộc |
| Khi nào sử dụng | Biểu mẫu, đăng nhập | Mọi lần tải trang |
Tìm tham số hành động
Hành động được chỉ định trong JavaScript của trang web:
javascript
grecaptcha.execute('6LcxxxxxxxxxxxxxxxxABCD', {action: 'submit'})Các hành động phổ biến bao gồm: submit, login, register, homepage, contact.
Triển khai
python
from scrapling import Fetcher
def scrape_with_recaptcha_v3(target_url, site_key, page_action="submit", min_score=0.7):
"""
Quét trang được bảo vệ bởi ReCaptcha v3.
Args:
target_url: URL của trang có captcha
site_key: Khóa trang ReCaptcha
page_action: Tham số hành động (được tìm thấy trong grecaptcha.execute)
min_score: Điểm số tối thiểu để yêu cầu (0.1-0.9)
Returns:
Phản hồi từ trang được bảo vệ
"""
print(f"Đang giải ReCaptcha v3 (hành động: {page_action})...")
solution = solve_captcha(
task_type="ReCaptchaV3TaskProxyLess",
website_url=target_url,
website_key=site_key,
pageAction=page_action
)
captcha_token = solution["gRecaptchaResponse"]
print(f"Đã nhận token với điểm số: {solution.get('score', 'Không có')}")
# Gửi yêu cầu với token bằng phương thức lớp Scrapling
response = Fetcher.post(
target_url,
data={
"g-recaptcha-response": captcha_token,
},
headers={
"User-Agent": solution.get("userAgent", "Mozilla/5.0")
}
)
return response
# Ví dụ sử dụng
if __name__ == "__main__":
url = "https://example.com/api/data"
site_key = "6LcxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxABCD"
result = scrape_with_recaptcha_v3(url, site_key, page_action="getData")
print(f"Phản hồi: {result.body.decode()[:200]}") # Sử dụng .body để nhận nội dungReCaptcha v3 Doanh nghiệp
python
solution = solve_captcha(
task_type="ReCaptchaV3EnterpriseTaskProxyLess",
website_url=target_url,
website_key=site_key,
pageAction=page_action,
enterprisePayload={
"s": "tham số s tùy chọn"
}
)Giải Cloudflare Turnstile với Scrapling + CapSolver
Cloudflare Turnstile là một lựa chọn captcha mới, được thiết kế như một "thay thế thân thiện với người dùng, bảo vệ quyền riêng tư" cho các captcha truyền thống. Nó ngày càng phổ biến trên các trang web sử dụng Cloudflare.
Hiểu Turnstile
Turnstile có ba chế độ:
- Quản lý: Hiển thị widget chỉ khi cần
- Không tương tác: Chạy mà không cần tương tác người dùng
- Vô hình: Hoàn toàn vô hình với người dùng
Tin tốt là CapSolver xử lý tất cả ba chế độ tự động.
Tìm khóa trang
Tìm Turnstile trong mã HTML của trang:
html
<div class="cf-turnstile" data-sitekey="0x4xxxxxxxxxxxxxxxxxxxxxxxxxx"></div>Hoặc trong JavaScript:
javascript
turnstile.render('#container', {
sitekey: '0x4xxxxxxxxxxxxxxxxxxxxxxxxxx',
callback: function(token) { ... }
});Triển khai
python
from scrapling import Fetcher
def scrape_with_turnstile(target_url, site_key, action=None, cdata=None):
"""
Quét trang được bảo vệ bởi Cloudflare Turnstile.
Args:
target_url: URL của trang có captcha
site_key: Khóa trang Turnstile (bắt đầu bằng 0x4...)
action: Tham số hành động tùy chọn
cdata: Tham số cdata tùy chọn
Returns:
Phản hồi từ trang được bảo vệ
"""
print("Đang giải Cloudflare Turnstile...")
# Xây dựng dữ liệu nếu có
metadata = {}
if action:
metadata["action"] = action
if cdata:
metadata["cdata"] = cdata
task_params = {
"task_type": "AntiTurnstileTaskProxyLess",
"website_url": target_url,
"website_key": site_key,
}
if metadata:
task_params["metadata"] = metadata
solution = solve_captcha(**task_params)
turnstile_token = solution["token"]
user_agent = solution.get("userAgent", "")
print(f"Đã nhận token Turnstile: {turnstile_token[:50]}...")
# Gửi với token bằng phương thức lớp Scrapling
headers = {}
if user_agent:
headers["User-Agent"] = user_agent
response = Fetcher.post(
target_url,
data={
"cf-turnstile-response": turnstile_token,
},
headers=headers
)
return response
# Ví dụ sử dụng
if __name__ == "__main__":
url = "https://example.com/protected"
site_key = "0x4AAAAAAAxxxxxxxxxxxxxx"
result = scrape_with_turnstile(url, site_key)
print(f"Thành công! Đã nhận được {len(result.body)} byte") # Sử dụng .body để lấy nội dungTurnstile với Hành động và CData
Một số triển khai yêu cầu các tham số bổ sung:
python
solution = solve_captcha(
task_type="AntiTurnstileTaskProxyLess",
website_url=target_url,
website_key=site_key,
metadata={
"action": "login",
"cdata": "session_id_or_custom_data"
}
)Sử dụng StealthyFetcher để Bảo vệ Chống Bot Nâng Cao
Đôi khi các yêu cầu HTTP cơ bản không đủ. Các trang web có thể sử dụng phát hiện bot tinh vi kiểm tra:
- Vết sinh học trình duyệt
- Thực thi JavaScript
- Chuyển động chuột và thời gian
- Vết sinh học TLS
- Tiêu đề yêu cầu
Scrapling's StealthyFetcher cung cấp khả năng chống bot ở cấp độ trình duyệt bằng cách sử dụng động cơ trình duyệt thực tế với các thay đổi bảo vệ.
StealthyFetcher là gì?
StealthyFetcher sử dụng trình duyệt Firefox đã được sửa đổi với:
- Vết sinh học trình duyệt thực tế
- Khả năng thực thi JavaScript
- Xử lý tự động các thách thức Cloudflare
- Giả mạo vết sinh học TLS
- Quản lý cookie và phiên
Khi nào nên sử dụng StealthyFetcher
| Tình huống | Sử dụng Fetcher | Sử dụng StealthyFetcher |
|---|---|---|
| Các biểu mẫu đơn giản với captcha | Có | Không |
| Trang web có JavaScript nặng | Không | Có |
| Nhiều lớp bảo vệ bot | Không | Có |
| Tốc độ quan trọng | Có | Không |
| Chế độ "Under Attack" của Cloudflare | Không | Có |
Kết hợp StealthyFetcher với CapSolver
Dưới đây là cách sử dụng cả hai cùng nhau để tối đa hóa hiệu quả:
python
from scrapling import StealthyFetcher
import asyncio
async def scrape_with_stealth_and_recaptcha(target_url, site_key, captcha_type="v2"):
"""
Kết hợp các tính năng chống bot của StealthyFetcher với CapSolver để giải ReCaptcha.
Args:
target_url: URL để quét
site_key: Khóa site của captcha
captcha_type: "v2" hoặc "v3"
Returns:
Nội dung trang sau khi giải captcha
"""
# Trước tiên, giải captcha bằng CapSolver
print(f"Đang giải ReCaptcha {captcha_type}...")
if captcha_type == "v2":
solution = solve_captcha(
task_type="ReCaptchaV2TaskProxyLess",
website_url=target_url,
website_key=site_key
)
token = solution["gRecaptchaResponse"]
elif captcha_type == "v3":
solution = solve_captcha(
task_type="ReCaptchaV3TaskProxyLess",
website_url=target_url,
website_key=site_key,
pageAction="submit"
)
token = solution["gRecaptchaResponse"]
else:
raise ValueError(f"Loại captcha không biết: {captcha_type}")
print(f"Đã nhận token: {token[:50]}...")
# Sử dụng StealthyFetcher để có hành vi giống trình duyệt
fetcher = StealthyFetcher()
# Điều hướng đến trang
page = await fetcher.async_fetch(target_url)
# Chèn giải pháp ReCaptcha bằng JavaScript
await page.page.evaluate(f'''() => {{
// Tìm trường g-recaptcha-response và thiết lập giá trị của nó
let field = document.querySelector('textarea[name="g-recaptcha-response"]');
if (!field) {{
field = document.createElement('textarea');
field.name = "g-recaptcha-response";
field.style.display = "none";
document.body.appendChild(field);
}}
field.value = "{token}";
}}''')
# Tìm và nhấp vào nút gửi
submit_button = page.css('button[type="submit"], input[type="submit"]')
if submit_button:
await submit_button[0].click()
# Chờ cho tải trang
await page.page.wait_for_load_state('networkidle')
# Lấy nội dung trang cuối cùng
content = await page.page.content()
return content
# Bao bọc đồng bộ để dễ sử dụng
def scrape_stealth(target_url, site_key, captcha_type="v2"):
"""Bao bọc đồng bộ cho trình quét stealth asyn."""
return asyncio.run(
scrape_with_stealth_and_recaptcha(target_url, site_key, captcha_type)
)
# Ví dụ sử dụng
if __name__ == "__main__":
url = "https://example.com/highly-protected-page"
site_key = "6LcxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxABCD"
content = scrape_stealth(url, site_key, captcha_type="v2")
print(f"Đã nhận được {len(content)} byte nội dung")Ví dụ đầy đủ: Quét trang nhiều lần với phiên
python
from scrapling import StealthyFetcher
import asyncio
class StealthScraper:
"""Một trình quét duy trì phiên giữa các trang."""
def __init__(self, api_key):
self.api_key = api_key
self.fetcher = None
async def __aenter__(self):
self.fetcher = StealthyFetcher()
return self
async def __aexit__(self, *args):
if self.fetcher:
await self.fetcher.close()
async def solve_and_access(self, url, site_key, captcha_type="v2"):
"""Giải ReCaptcha và truy cập trang."""
global CAPSOLVER_API_KEY
CAPSOLVER_API_KEY = self.api_key
# Giải ReCaptcha
task_type = f"ReCaptcha{captcha_type.upper()}TaskProxyLess"
solution = solve_captcha(
task_type=task_type,
website_url=url,
website_key=site_key
)
token = solution["gRecaptchaResponse"]
# Điều hướng và chèn token
page = await self.fetcher.async_fetch(url)
# ... tiếp tục với tương tác trang
return page
# Cách sử dụng
async def main():
async with StealthScraper("your_api_key") as scraper:
page1 = await scraper.solve_and_access(
"https://example.com/login",
"site_key_here",
"v2"
)
# Phiên được duy trì cho các yêu cầu tiếp theo
page2 = await scraper.solve_and_access(
"https://example.com/dashboard",
"another_site_key",
"v3"
)
asyncio.run(main())Các Nguyên Tắc Tốt & Mẹo
1. Giới hạn tốc độ
Đừng gửi quá nhiều yêu cầu đến trang web. Thực hiện độ trễ giữa các yêu cầu:
python
import time
import random
def polite_scrape(urls, min_delay=2, max_delay=5):
"""Quét với độ trễ ngẫu nhiên để giống người dùng hơn."""
results = []
for url in urls:
result = scrape_page(url)
results.append(result)
# Độ trễ ngẫu nhiên giữa các yêu cầu
delay = random.uniform(min_delay, max_delay)
time.sleep(delay)
return results2. Xử lý lỗi
Luôn xử lý các sự cố một cách trơn tru:
python
def robust_solve_captcha(task_type, website_url, website_key, max_retries=3, **kwargs):
"""Giải captcha với thử lại tự động."""
for attempt in range(max_retries):
try:
return solve_captcha(task_type, website_url, website_key, **kwargs)
except Exception as e:
print(f"Thử {attempt + 1} thất bại: {e}")
if attempt < max_retries - 1:
time.sleep(5) # Chờ trước khi thử lại
else:
raise3. Tôn trọng robots.txt
Kiểm tra robots.txt của trang web trước khi quét:
python
from urllib.robotparser import RobotFileParser
def can_scrape(url):
"""Kiểm tra xem quét có được phép bởi robots.txt."""
rp = RobotFileParser()
rp.set_url(f"{url}/robots.txt")
rp.read()
return rp.can_fetch("*", url)4. Sử dụng proxy để mở rộng quy mô
Khi quét ở quy mô lớn, xoay proxy để tránh bị chặn IP:
python
# CapSolver hỗ trợ các nhiệm vụ có proxy
solution = solve_captcha(
task_type="ReCaptchaV2Task", # Lưu ý: không có "ProxyLess"
website_url=target_url,
website_key=site_key,
proxy="http://user:pass@proxy.example.com:8080"
)5. Lưu trữ giải pháp khi có thể
Các token captcha thường có hiệu lực trong 1-2 phút. Nếu bạn cần thực hiện nhiều yêu cầu, sử dụng lại token:
python
import time
class CaptchaCache:
def __init__(self, ttl=120): # TTL mặc định 2 phút
self.cache = {}
self.ttl = ttl
def get_or_solve(self, key, solve_func):
"""Lấy token đã lưu hoặc giải mới."""
if key in self.cache:
token, timestamp = self.cache[key]
if time.time() - timestamp < self.ttl:
return token
token = solve_func()
self.cache[key] = (token, time.time())
return tokenBảng So Sánh
Bảng So Sánh Loại Captcha
| Tính năng | ReCaptcha v2 | ReCaptcha v3 | Cloudflare Turnstile |
|---|---|---|---|
| Tương tác người dùng | Hộp kiểm + có thể thách thức | Không | Tối thiểu hoặc không |
| Định dạng khóa site | 6L... |
6L... |
0x4... |
| Trường phản hồi | g-recaptcha-response |
g-recaptcha-response |
cf-turnstile-response |
| Tham số Hành động | Không | Có (bắt buộc) | Tùy chọn |
| Thời gian giải | 1-10 giây | 1-10 giây | 1-20 giây |
| Nhiệm vụ CapSolver | ReCaptchaV2TaskProxyLess |
ReCaptchaV3TaskProxyLess |
AntiTurnstileTaskProxyLess |
Bảng So Sánh Fetcher của Scrapling
| Tính năng | Fetcher | StealthyFetcher |
|---|---|---|
| Tốc độ | Rất nhanh | Chậm hơn |
| Hỗ trợ JavaScript | Không | Có |
| Vết sinh học trình duyệt | Không | Firefox thực tế |
| Sử dụng bộ nhớ | Thấp | Cao hơn |
| Bypass Cloudflare | Không | Có |
| Tốt nhất cho | Yêu cầu đơn giản | Anti-bot phức tạp |
Câu Hỏi Thường Gặp
Câu hỏi: Chi phí của CapSolver là bao nhiêu?
Xem trang giá cả CapSolver để biết mức giá hiện tại.
Câu hỏi: Làm thế nào để tìm khóa site trên trang web?
Tìm trong mã nguồn trang (Ctrl+U) cho:
- Thuộc tính
data-sitekey - Gọi JavaScript
grecaptcha.execute - Tham số
render=trong URL script ReCaptcha class="cf-turnstile"cho Turnstile
Câu hỏi: Nếu token captcha hết hạn trước khi bạn sử dụng nó?
Các token thường hết hạn sau 1-2 phút. Giải captcha gần thời điểm gửi biểu mẫu nhất có thể. Nếu bạn nhận được lỗi xác minh, giải lại với token mới.
Câu hỏi: Bạn có thể sử dụng CapSolver với mã async không?
Có! Bao bọc hàm giải trong executor async:
python
import asyncio
async def async_solve_captcha(*args, **kwargs):
loop = asyncio.get_event_loop()
return await loop.run_in_executor(
None,
lambda: solve_captcha(*args, **kwargs)
)Câu hỏi: Làm thế nào để xử lý nhiều ReCaptchas trên một trang?
Giải từng captcha riêng biệt và bao gồm tất cả các token trong việc gửi:
python
# Giải nhiều ReCaptchas
solution_v2 = solve_captcha("ReCaptchaV2TaskProxyLess", url, key1)
solution_v3 = solve_captcha("ReCaptchaV3TaskProxyLess", url, key2, pageAction="submit")
# Gửi các token bằng phương thức của lớp Scrapling
response = Fetcher.post(url, data={
"g-recaptcha-response": solution_v2["gRecaptchaResponse"],
"g-recaptcha-response-v3": solution_v3["gRecaptchaResponse"],
})Kết Luận
Kết hợp Scrapling và CapSolver cung cấp giải pháp mạnh mẽ để quét các trang web có captcha. Dưới đây là tóm tắt nhanh:
- Sử dụng Fetcher của Scrapling cho các yêu cầu đơn giản khi tốc độ quan trọng
- Sử dụng StealthyFetcher khi đối mặt với hệ thống chống bot phức tạp
- Sử dụng CapSolver để giải ReCaptcha v2, v3 và Cloudflare Turnstile
- Thực hiện các nguyên tắc tốt như giới hạn tốc độ, xử lý lỗi và xoay proxy
Hãy luôn quét một cách có trách nhiệm:
- Tôn trọng điều khoản sử dụng trang web
- Không làm quá tải máy chủ bằng yêu cầu
- Sử dụng dữ liệu một cách có đạo đức
- Xem xét liên hệ với chủ sở hữu trang web để truy cập API
Sẵn sàng bắt đầu quét? Nhận khóa API CapSolver tại capsolver.com và cài đặt Scrapling với pip install "scrapling[all]".