Gỡ mã nguồn trang web với Selenium và Python | Giải Captcha khi gỡ mã nguồn trang web

Aloísio Vítor
Image Processing Expert
Hãy tưởng tượng bạn có thể dễ dàng thu thập tất cả dữ liệu bạn cần từ Internet mà không cần phải duyệt web thủ công hay sao chép và dán. Đó chính là lợi ích của việc quét dữ liệu web. Dù bạn là nhà phân tích dữ liệu, nhà nghiên cứu thị trường hay lập trình viên, quét dữ liệu web mở ra một thế giới mới về thu thập dữ liệu tự động.
Trong thời đại dữ liệu, thông tin là sức mạnh. Tuy nhiên, việc trích xuất thông tin thủ công từ hàng trăm đến hàng nghìn trang web không chỉ tốn thời gian mà còn dễ xảy ra sai sót. May mắn thay, quét dữ liệu web cung cấp một giải pháp hiệu quả và chính xác, cho phép bạn tự động hóa quy trình trích xuất dữ liệu từ Internet, từ đó nâng cao đáng kể hiệu suất và chất lượng dữ liệu.
Mục lục
Web scraping là gì?
Web scraping là kỹ thuật trích xuất thông tin tự động từ các trang web bằng cách viết chương trình. Công nghệ này có nhiều ứng dụng trong các lĩnh vực như phân tích dữ liệu, nghiên cứu thị trường, thông tin cạnh tranh, tổng hợp nội dung, v.v. Với web scraping, bạn có thể thu thập và tập trung dữ liệu từ nhiều trang web trong thời gian ngắn, thay vì dựa vào thao tác thủ công.
Quy trình của web scraping thường bao gồm các bước sau:
- Gửi yêu cầu HTTP: Gửi yêu cầu chương trình đến trang web mục tiêu để lấy mã HTML của trang. Các công cụ phổ biến như thư viện requests của Python có thể thực hiện điều này một cách dễ dàng.
- Phân tích nội dung HTML: Sau khi nhận được mã HTML, bạn cần phân tích để trích xuất dữ liệu cần thiết. Các thư viện phân tích HTML như BeautifulSoup hoặc lxml có thể được sử dụng để xử lý cấu trúc HTML.
- Trích xuất dữ liệu: Dựa trên cấu trúc HTML đã phân tích, tìm và trích xuất nội dung cụ thể, ví dụ như tiêu đề bài viết, thông tin giá cả, liên kết hình ảnh, v.v. Các phương pháp phổ biến bao gồm sử dụng XPath hoặc CSS selectors.
- Lưu trữ dữ liệu: Lưu dữ liệu đã trích xuất vào phương tiện lưu trữ phù hợp, như cơ sở dữ liệu, tệp CSV hoặc tệp JSON, để phân tích và xử lý sau này.
Và bằng cách sử dụng các công cụ như Selenium, bạn có thể mô phỏng thao tác trình duyệt của người dùng, vượt qua một số cơ chế chống quét, từ đó hoàn thành công việc quét dữ liệu web hiệu quả hơn.
Nhận mã thưởng CapSolver của bạn
Tăng ngân sách tự động hóa của bạn ngay lập tức!
Sử dụng mã thưởng CAPN khi nạp tiền vào tài khoản CapSolver để nhận thêm 5% thưởng cho mỗi lần nạp — không giới hạn.
Nhận ngay tại Bảng điều khiển CapSolver
.
Bắt đầu với Selenium
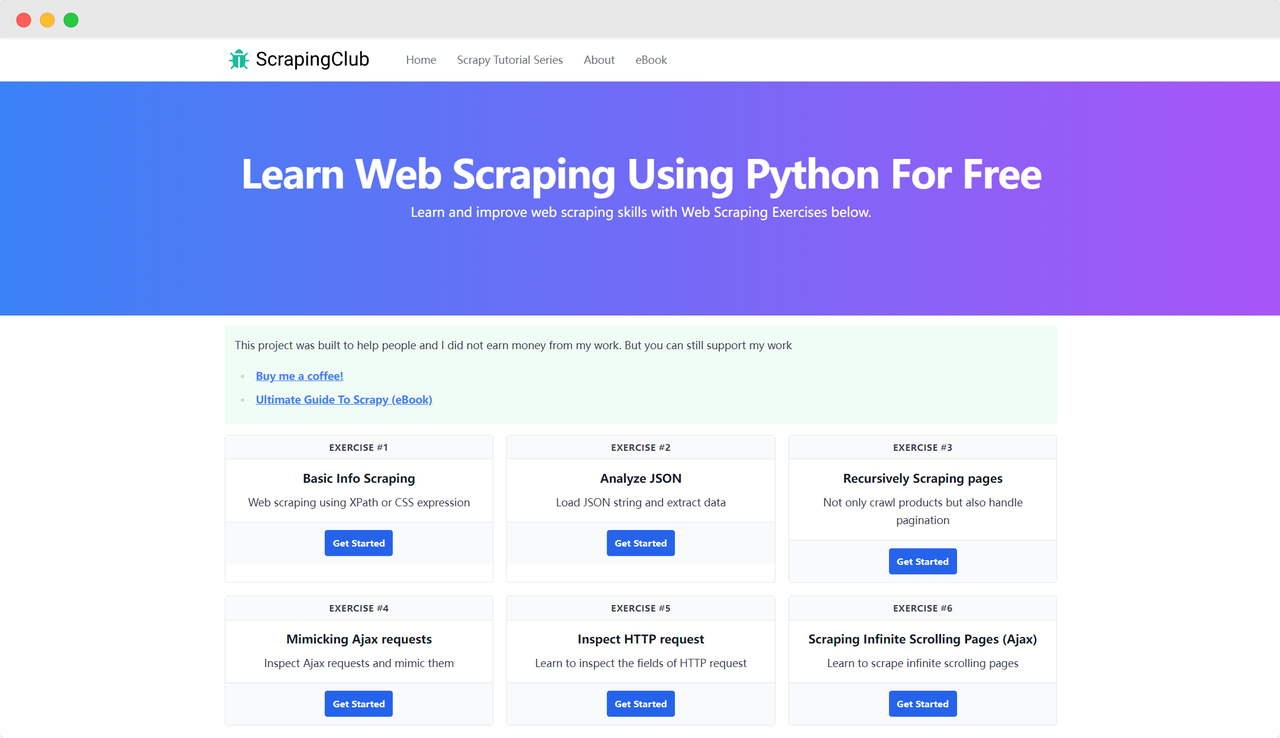
Hãy lấy ScrapingClub làm ví dụ và sử dụng selenium để hoàn thành bài tập đầu tiên.
Chuẩn bị
Trước tiên, bạn cần đảm bảo rằng Python đã được cài đặt trên máy tính của mình. Bạn có thể kiểm tra phiên bản Python bằng cách nhập lệnh sau vào terminal:
bash
python --versionĐảm bảo phiên bản Python lớn hơn 3. Nếu chưa cài đặt hoặc phiên bản quá thấp, hãy tải phiên bản mới nhất từ trang web chính thức của Python. Tiếp theo, bạn cần cài đặt thư viện selenium bằng lệnh sau:
bash
pip install seleniumNhập thư viện
python
from selenium import webdriverTruy cập trang web
Việc điều khiển Google Chrome bằng Selenium để truy cập trang web không quá phức tạp. Sau khi khởi tạo đối tượng Chrome Options, bạn có thể sử dụng phương thức get() để truy cập trang mục tiêu:
python
import time
from selenium import webdriver
chrome_options = webdriver.ChromeOptions()
driver = webdriver.Chrome(options=chrome_options)
driver.get('https://scrapingclub.com/')
time.sleep(5)
driver.quit()Tham số khởi động
Chrome Options có thể thêm nhiều tham số khởi động giúp cải thiện hiệu quả truy xuất dữ liệu. Bạn có thể xem danh sách đầy đủ tham số trên trang web chính thức: Danh sách các tham số dòng lệnh của Chromium. Dưới đây là một số tham số thường được sử dụng:
| Tham số | Mục đích |
|---|---|
| --user-agent="" | Thiết lập User-Agent trong tiêu đề yêu cầu |
| --window-size=xxx,xxx | Thiết lập độ phân giải trình duyệt |
| --start-maximized | Chạy với độ phân giải được mở rộng tối đa |
| --headless | Chạy ở chế độ không giao diện |
| --incognito | Chạy ở chế độ ẩn danh |
| --disable-gpu | Tắt gia tốc phần cứng GPU |
Ví dụ: Chạy ở chế độ không giao diện
python
import time
from selenium import webdriver
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--headless')
driver = webdriver.Chrome(options=chrome_options)
driver.get('https://scrapingclub.com/')
time.sleep(5)
driver.quit()Tìm kiếm các phần tử trang web
Bước cần thiết trong việc quét dữ liệu là tìm các phần tử HTML tương ứng trong DOM. Selenium cung cấp hai phương pháp chính để tìm phần tử trên trang:
find_element: Tìm một phần tử đáp ứng tiêu chí.find_elements: Tìm tất cả các phần tử đáp ứng tiêu chí.
Cả hai phương pháp đều hỗ trợ tám cách khác nhau để tìm phần tử HTML:
| Phương pháp | Ý nghĩa | Ví dụ HTML | Ví dụ Selenium |
|---|---|---|---|
| By.ID | Tìm theo ID của phần tử | <form id="loginForm">...</form> |
driver.find_element(By.ID, 'loginForm') |
| By.NAME | Tìm theo tên của phần tử | <input name="username" type="text" /> |
driver.find_element(By.NAME, 'username') |
| By.XPATH | Tìm theo XPath | <p><code>My code</code></p> |
driver.find_element(By.XPATH, "//p/code") |
| By.LINK_TEXT | Tìm theo văn bản của liên kết | <a href="continue.html">Continue</a> |
driver.find_element(By.LINK_TEXT, 'Continue') |
| By.PARTIAL_LINK_TEXT | Tìm theo văn bản liên kết một phần | <a href="continue.html">Continue</a> |
driver.find_element(By.PARTIAL_LINK_TEXT, 'Conti') |
| By.TAG_NAME | Tìm theo tên thẻ | <h1>Welcome</h1> |
driver.find_element(By.TAG_NAME, 'h1') |
| By.CLASS_NAME | Tìm theo tên lớp | <p class="content">Welcome</p> |
driver.find_element(By.CLASS_NAME, 'content') |
| By.CSS_SELECTOR | Tìm theo CSS selector | <p class="content">Welcome</p> |
driver.find_element(By.CSS_SELECTOR, 'p.content') |
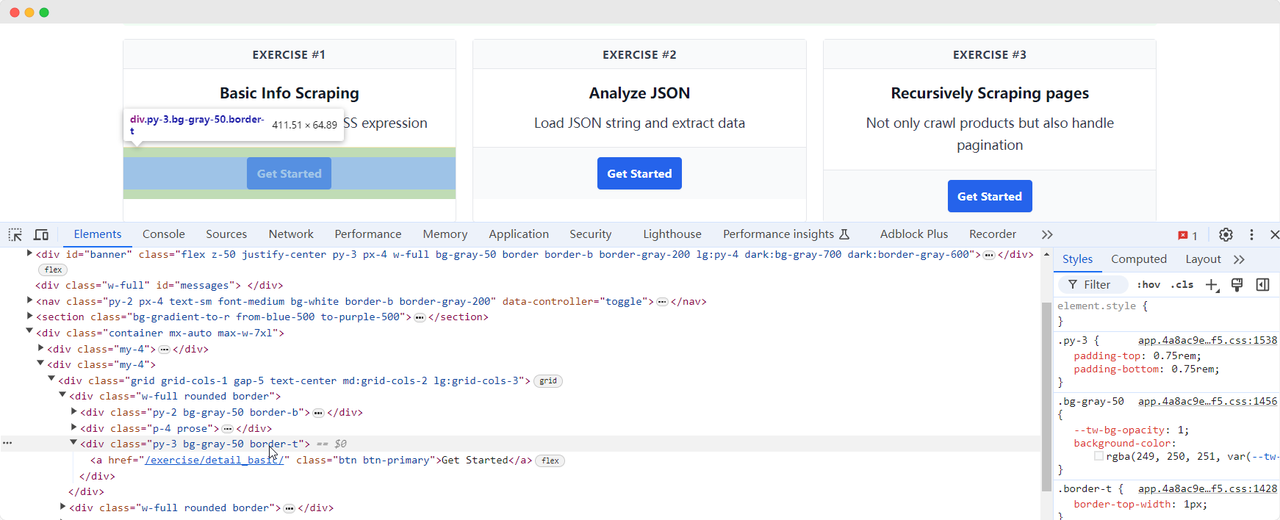
Hãy quay lại trang ScrapingClub và viết đoạn mã sau để tìm phần tử nút "Get Started" cho bài tập một:
python
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
chrome_options = webdriver.ChromeOptions()
driver = webdriver.Chrome(options=chrome_options)
driver.get('https://scrapingclub.com/')
get_started_button = driver.find_element(By.XPATH, "//div[@class='w-full rounded border'][1]/div[3]")
time.sleep(5)
driver.quit()Tương tác với phần tử
Khi chúng ta đã tìm thấy phần tử nút "Get Started", chúng ta cần nhấp vào nút để truy cập trang tiếp theo. Điều này liên quan đến tương tác với phần tử. Selenium cung cấp một số phương thức để mô phỏng hành động:
click(): Nhấp vào phần tử;clear(): Xóa nội dung của phần tử;send_keys(*value: str): Mô phỏng nhập bàn phím;submit(): Gửi biểu mẫu;screenshot(filename): Lưu ảnh màn hình.
Để biết thêm về các tương tác, tham khảo tài liệu chính thức: WebDriver API. Hãy tiếp tục cải thiện đoạn mã bài tập ScrapingClub bằng cách thêm thao tác nhấp:
python
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
chrome_options = webdriver.ChromeOptions()
driver = webdriver.Chrome(options=chrome_options)
driver.get('https://scrapingclub.com/')
get_started_button = driver.find_element(By.XPATH, "//div[@class='w-full rounded border'][1]/div[3]")
get_started_button.click()
time.sleep(5)
driver.quit()Trích xuất dữ liệu
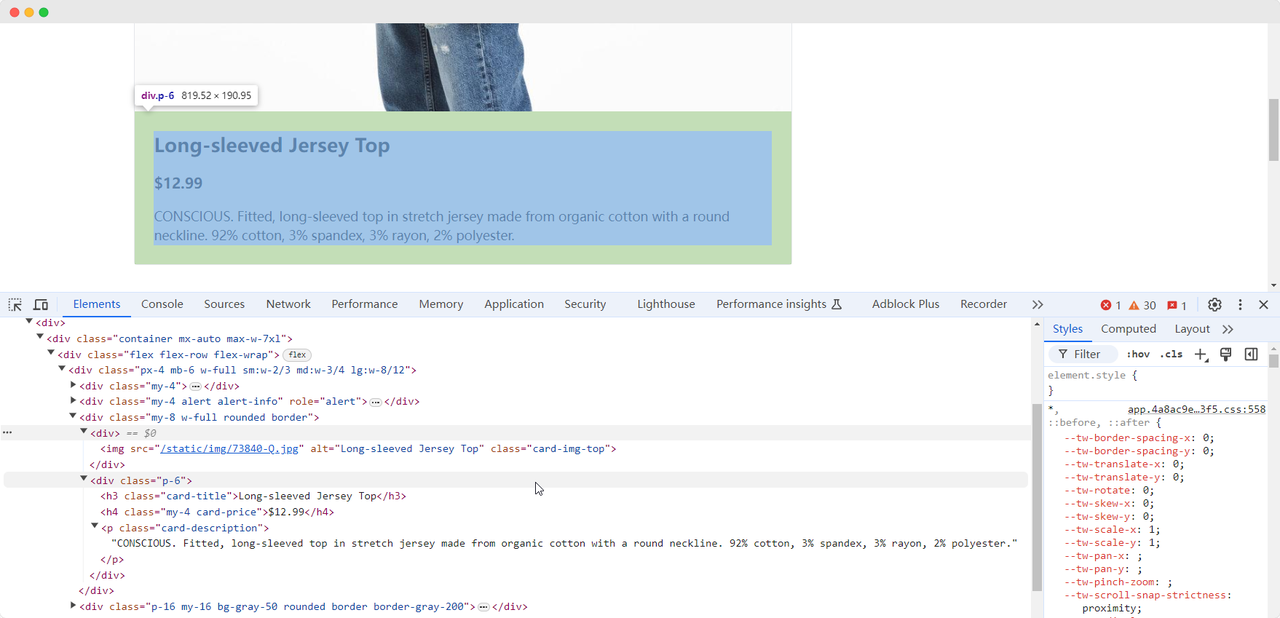
Khi chúng ta đến trang đầu tiên của bài tập, chúng ta cần thu thập thông tin về hình ảnh, tên, giá và mô tả sản phẩm. Chúng ta có thể sử dụng các phương pháp khác nhau để tìm các phần tử này và trích xuất chúng:
python
from selenium import webdriver
from selenium.webdriver.common.by import By
chrome_options = webdriver.ChromeOptions()
driver = webdriver.Chrome(options=chrome_options)
driver.get('https://scrapingclub.com/')
get_started_button = driver.find_element(By.XPATH, "//div[@class='w-full rounded border'][1]/div[3]")
get_started_button.click()
product_name = driver.find_element(By.CLASS_NAME, 'card-title').text
product_image = driver.find_element(By.CSS_SELECTOR, '.card-img-top').get_attribute('src')
product_price = driver.find_element(By.XPATH, '//h4').text
product_description = driver.find_element(By.CSS_SELECTOR, '.card-description').text
print(f'Tên sản phẩm: {product_name}')
print(f'Hình ảnh sản phẩm: {product_image}')
print(f'Giá sản phẩm: {product_price}')
print(f'Mô tả sản phẩm: {product_description}')
driver.quit()Đoạn mã sẽ xuất ra nội dung sau:
Tên sản phẩm: Long-sleeved Jersey Top
Hình ảnh sản phẩm: https://scrapingclub.com/static/img/73840-Q.jpg
Giá sản phẩm: $12.99
Mô tả sản phẩm: CONSCIOUS. Áo phông ôm, tay dài làm từ vải jersey hữu cơ, có cổ tròn. 92% cotton, 3% spandex, 3% rayon, 2% polyester.Chờ phần tử tải xong
Đôi khi, do vấn đề mạng hoặc các lý do khác, phần tử có thể chưa được tải xong khi Selenium kết thúc, điều này có thể gây ra việc thu thập dữ liệu thất bại. Để giải quyết vấn đề này, chúng ta có thể thiết lập để chờ cho đến khi một phần tử nhất định được tải xong trước khi tiếp tục trích xuất dữ liệu. Dưới đây là đoạn mã ví dụ:
python
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
chrome_options = webdriver.ChromeOptions()
driver = webdriver.Chrome(options=chrome_options)
driver.get('https://scrapingclub.com/')
get_started_button = driver.find_element(By.XPATH, "//div[@class='w-full rounded border'][1]/div[3]")
get_started_button.click()
# Chờ cho các phần tử hình ảnh sản phẩm tải xong
wait = WebDriverWait(driver, 10)
wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '.card-img-top')))
product_name = driver.find_element(By.CLASS_NAME, 'card-title').text
product_image = driver.find_element(By.CSS_SELECTOR, '.card-img-top').get_attribute('src')
product_price = driver.find_element(By.XPATH, '//h4').text
product_description = driver.find_element(By.CSS_SELECTOR, '.card-description').text
print(f'Tên sản phẩm: {product_name}')
print(f'Hình ảnh sản phẩm: {product_image}')
print(f'Giá sản phẩm: {product_price}')
print(f'Mô tả sản phẩm: {product_description}')
driver.quit()Bypass các biện pháp chống quét dữ liệu
Bài tập của ScrapingClub dễ thực hiện. Tuy nhiên, trong các tình huống thu thập dữ liệu thực tế, việc lấy dữ liệu không dễ dàng như vậy vì một số trang web sử dụng các kỹ thuật chống quét dữ liệu có thể phát hiện script của bạn là bot và chặn việc thu thập. Tình huống phổ biến nhất là thách thức CAPTCHA
Việc giải quyết các thách thức CAPTCHA này đòi hỏi kinh nghiệm rộng về học máy, kỹ thuật đảo ngược và các biện pháp chống nhận diện dấu vân tay trình duyệt, điều này có thể tốn rất nhiều thời gian. May mắn thay, giờ đây bạn không cần phải tự làm tất cả công việc này. CapSolver cung cấp giải pháp toàn diện giúp bạn dễ dàng vượt qua mọi thách thức. CapSolver cung cấp các tiện ích mở rộng trình duyệt có thể tự động giải CAPTCHA khi sử dụng Selenium để thu thập dữ liệu. Ngoài ra, họ cung cấp các phương pháp API để giải CAPTCHA và nhận token, tất cả đều có thể hoàn thành chỉ trong vài giây. Tham khảo Tài liệu CapSolver để biết thêm thông tin.
Kết luận
Từ việc trích xuất chi tiết sản phẩm đến việc di chuyển qua các biện pháp chống quét phức tạp, quét dữ liệu web với Selenium mở ra cánh cửa cho một thế giới rộng lớn về thu thập dữ liệu tự động. Khi chúng ta di chuyển qua môi trường web không ngừng thay đổi, các công cụ như CapSolver tạo điều kiện cho việc trích xuất dữ liệu mượt mà hơn, biến những thách thức từng là khó khăn thành quá khứ. Vì vậy, dù bạn là người đam mê dữ liệu hay lập trình viên có kinh nghiệm, khai thác các công nghệ này không chỉ nâng cao hiệu suất mà còn mở ra thế giới nơi những insight dựa trên dữ liệu chỉ cần một lần ghi dữ liệu.
Câu hỏi thường gặp
1. Web scraping được sử dụng để làm gì?
Xem thêm
Web ScrapingApr 22, 2026
Kiến trúc Trích xuất Dữ liệu Từ Web bằng Rust cho Trích xuất Dữ liệu Có Thể Mở Rộng
Học kiến trúc gỡ mã web Rust có thể mở rộng với reqwest, scraper, gỡ mã bất đồng bộ, gỡ mã trình duyệt không đầu, xoay proxy và xử lý CAPTCHA tuân thủ.

Web ScrapingFeb 17, 2026
Cách giải CAPTCHA trên Nanobot bằng CapSolver
Tự động hóa việc giải CAPTCHA với Nanobot và CapSolver. Sử dụng Playwright để giải reCAPTCHA và Cloudflare tự động.

