Tích hợp Crawlab với CapSolver: Giải CAPTCHA tự động cho việc quét dữ liệu phân tán

Anh Tuan
Data Science Expert

Quản lý các bot thu thập dữ liệu quy mô lớn đòi hỏi cơ sở hạ tầng mạnh mẽ có thể xử lý các thách thức chống bot hiện đại. Crawlab là nền tảng quản lý bot thu thập dữ liệu phân tán mạnh mẽ, và CapSolver là dịch vụ giải CAPTCHA dựa trên AI. Cùng nhau, chúng tạo ra các hệ thống thu thập dữ liệu cấp doanh nghiệp có thể tự động vượt qua các thách thức CAPTCHA.
Hướng dẫn này cung cấp các ví dụ mã hoàn chỉnh, có thể sử dụng ngay để tích hợp CapSolver vào các spider của bạn trên Crawlab.
Bạn sẽ học được gì
- Giải quyết reCAPTCHA v2 với Selenium
- Giải quyết Cloudflare Turnstile
- Tích hợp middleware Scrapy
- Tích hợp Node.js/Puppeteer
- Các phương pháp tốt nhất để xử lý CAPTCHA quy mô lớn
Crawlab là gì?
Crawlab là nền tảng quản lý bot thu thập dữ liệu phân tán được thiết kế để quản lý các spider trên nhiều ngôn ngữ lập trình khác nhau.
Tính năng chính
- Không phụ thuộc vào ngôn ngữ: Hỗ trợ Python, Node.js, Go, Java và PHP
- Linh hoạt về framework: Hoạt động với Scrapy, Selenium, Puppeteer, Playwright
- Kiến trúc phân tán: Mở rộng theo chiều ngang với các nút chủ/đồng bộ
- Giao diện quản lý: Giao diện web để quản lý và lập lịch spider
Cài đặt
bash
# Sử dụng Docker Compose
git clone https://github.com/crawlab-team/crawlab.git
cd crawlab
docker-compose up -dTruy cập giao diện tại http://localhost:8080 (mặc định: admin/admin).
CapSolver là gì?
CapSolver là dịch vụ giải CAPTCHA dựa trên AI cung cấp các giải pháp nhanh và đáng tin cậy cho nhiều loại CAPTCHA.
Các loại CAPTCHA được hỗ trợ
- reCAPTCHA: v2, v3 và Enterprise
- Cloudflare: Turnstile và Challenge
- AWS WAF: Bypass bảo vệ
- Và Nhiều hơn nữa
Quy trình API
- Gửi tham số CAPTCHA (loại, siteKey, URL)
- Nhận ID nhiệm vụ
- Kiểm tra kết quả
- Chèn token vào trang
Yêu cầu tiên quyết
- Python 3.8+ hoặc Node.js 16+
- Khóa API CapSolver - Đăng ký tại đây
- Trình duyệt Chrome/Chromium
bash
# Thư viện Python
pip install selenium requestsGiải quyết reCAPTCHA v2 với Selenium
Mã Python đầy đủ để giải quyết reCAPTCHA v2:
python
"""
Crawlab + CapSolver: Trình giải reCAPTCHA v2
Mã đầy đủ để giải các thách thức reCAPTCHA v2 với Selenium
"""
import os
import time
import json
import requests
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
# Cấu hình
CAPSOLVER_API_KEY = os.getenv('CAPSOLVER_API_KEY', 'YOUR_CAPSOLVER_API_KEY')
CAPSOLVER_API = 'https://api.capsolver.com'
class CapsolverClient:
"""Khách hàng API CapSolver cho reCAPTCHA v2"""
def __init__(self, api_key: str):
self.api_key = api_key
self.session = requests.Session()
def create_task(self, task: dict) -> str:
"""Tạo nhiệm vụ giải CAPTCHA"""
payload = {
"clientKey": self.api_key,
"task": task
}
response = self.session.post(
f"{CAPSOLVER_API}/createTask",
json=payload
)
result = response.json()
if result.get('errorId', 0) != 0:
raise Exception(f"Lỗi CapSolver: {result.get('errorDescription')}")
return result['taskId']
def get_task_result(self, task_id: str, timeout: int = 120) -> dict:
"""Kiểm tra kết quả nhiệm vụ"""
for _ in range(timeout):
payload = {
"clientKey": self.api_key,
"taskId": task_id
}
response = self.session.post(
f"{CAPSOLVER_API}/getTaskResult",
json=payload
)
result = response.json()
if result.get('status') == 'ready':
return result['solution']
if result.get('status') == 'failed':
raise Exception("Giải CAPTCHA thất bại")
time.sleep(1)
raise Exception("Hết thời gian chờ kết quả")
def solve_recaptcha_v2(self, website_url: str, site_key: str) -> str:
"""Giải reCAPTCHA v2 và trả về token"""
task = {
"type": "ReCaptchaV2TaskProxyLess",
"websiteURL": website_url,
"websiteKey": site_key
}
print(f"Tạo nhiệm vụ cho {website_url}...")
task_id = self.create_task(task)
print(f"Nhiệm vụ được tạo: {task_id}")
print("Đang chờ kết quả...")
solution = self.get_task_result(task_id)
return solution['gRecaptchaResponse']
def get_balance(self) -> float:
"""Lấy số dư tài khoản"""
response = self.session.post(
f"{CAPSOLVER_API}/getBalance",
json={"clientKey": self.api_key}
)
return response.json().get('balance', 0)
class RecaptchaV2Crawler:
"""Bot thu thập dữ liệu với hỗ trợ reCAPTCHA v2"""
def __init__(self, headless: bool = True):
self.headless = headless
self.driver = None
self.capsolver = CapsolverClient(CAPSOLVER_API_KEY)
def start(self):
"""Khởi tạo trình duyệt"""
options = Options()
if self.headless:
options.add_argument("--headless=new")
options.add_argument("--no-sandbox")
options.add_argument("--disable-dev-shm-usage")
options.add_argument("--window-size=1920,1080")
self.driver = webdriver.Chrome(options=options)
print("Trình duyệt đã khởi động")
def stop(self):
"""Đóng trình duyệt"""
if self.driver:
self.driver.quit()
print("Trình duyệt đã đóng")
def detect_recaptcha(self) -> str:
"""Phát hiện reCAPTCHA và trả về site key"""
try:
element = self.driver.find_element(By.CLASS_NAME, "g-recaptcha")
return element.get_attribute("data-sitekey")
except:
return None
def inject_token(self, token: str):
"""Chèn token đã giải vào trang"""
self.driver.execute_script(f"""
// Thiết lập trường g-recaptcha-response
var responseField = document.getElementById('g-recaptcha-response');
if (responseField) {{
responseField.style.display = 'block';
responseField.value = '{token}';
}}
// Thiết lập tất cả các trường ẩn
var textareas = document.querySelectorAll('textarea[name="g-recaptcha-response"]');
for (var i = 0; i < textareas.length; i++) {{
textareas[i].value = '{token}';
}}
""")
print("Token đã được chèn")
def submit_form(self):
"""Gửi biểu mẫu"""
try:
submit = self.driver.find_element(
By.CSS_SELECTOR,
'button[type="submit"], input[type="submit"]'
)
submit.click()
print("Biểu mẫu đã được gửi")
except Exception as e:
print(f"Không thể gửi biểu mẫu: {e}")
def crawl(self, url: str) -> dict:
"""Thu thập dữ liệu URL với xử lý reCAPTCHA v2"""
result = {
'url': url,
'success': False,
'captcha_solved': False
}
try:
print(f"Đang truy cập: {url}")
self.driver.get(url)
time.sleep(2)
# Phát hiện reCAPTCHA
site_key = self.detect_recaptcha()
if site_key:
print(f"Phát hiện reCAPTCHA v2! Site key: {site_key}")
# Giải CAPTCHA
token = self.capsolver.solve_recaptcha_v2(url, site_key)
print(f"Token nhận được: {token[:50]}...")
# Chèn token
self.inject_token(token)
result['captcha_solved'] = True
# Gửi biểu mẫu
self.submit_form()
time.sleep(2)
result['success'] = True
result['title'] = self.driver.title
except Exception as e:
result['error'] = str(e)
print(f"Lỗi: {e}")
return result
def main():
"""Điểm vào chính"""
# Kiểm tra số dư
client = CapsolverClient(CAPSOLVER_API_KEY)
print(f"Số dư CapSolver: ${client.get_balance():.2f}")
# Tạo bot
crawler = RecaptchaV2Crawler(headless=True)
try:
crawler.start()
# Thu thập URL đích (thay thế bằng URL của bạn)
result = crawler.crawl("https://example.com/protected-page")
print("\n" + "=" * 50)
print("KẾT QUẢ:")
print(json.dumps(result, indent=2))
finally:
crawler.stop()
if __name__ == "__main__":
main()Giải quyết Cloudflare Turnstile
Mã Python đầy đủ để giải Cloudflare Turnstile:
python
"""
Crawlab + CapSolver: Trình giải Cloudflare Turnstile
Mã đầy đủ để giải các thách thức Turnstile
"""
import os
import time
import json
import requests
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
from selenium.common.exceptions import NoSuchElementException
# Cấu hình
CAPSOLVER_API_KEY = os.getenv('CAPSOLVER_API_KEY', 'YOUR_CAPSOLVER_API_KEY')
CAPSOLVER_API = 'https://api.capsolver.com'
class TurnstileSolver:
"""Khách hàng CapSolver cho Turnstile"""
def __init__(self, api_key: str):
self.api_key = api_key
self.session = requests.Session()
def solve(self, website_url: str, site_key: str) -> str:
"""Giải CAPTCHA Turnstile"""
print(f"Giải Turnstile cho {website_url}")
print(f"Site key: {site_key}")
# Tạo nhiệm vụ
task_data = {
"clientKey": self.api_key,
"task": {
"type": "AntiTurnstileTaskProxyLess",
"websiteURL": website_url,
"websiteKey": site_key
}
}
response = self.session.post(f"{CAPSOLVER_API}/createTask", json=task_data)
result = response.json()
if result.get('errorId', 0) != 0:
raise Exception(f"Lỗi CapSolver: {result.get('errorDescription')}")
task_id = result['taskId']
print(f"Nhiệm vụ được tạo: {task_id}")
# Kiểm tra kết quả
for i in range(120):
result_data = {
"clientKey": self.api_key,
"taskId": task_id
}
response = self.session.post(f"{CAPSOLVER_API}/getTaskResult", json=result_data)
result = response.json()
if result.get('status') == 'ready':
token = result['solution']['token']
print(f"Turnstile đã được giải!")
return token
if result.get('status') == 'failed':
raise Exception("Giải Turnstile thất bại")
time.sleep(1)
raise Exception("Hết thời gian chờ kết quả")
class TurnstileCrawler:
"""Bot thu thập dữ liệu với hỗ trợ Turnstile"""
def __init__(self, headless: bool = True):
self.headless = headless
self.driver = None
self.solver = TurnstileSolver(CAPSOLVER_API_KEY)
def start(self):
"""Khởi tạo trình duyệt"""
options = Options()
if self.headless:
options.add_argument("--headless=new")
options.add_argument("--no-sandbox")
options.add_argument("--disable-dev-shm-usage")
self.driver = webdriver.Chrome(options=options)
def stop(self):
"""Đóng trình duyệt"""
if self.driver:
self.driver.quit()
def detect_turnstile(self) -> str:
"""Phát hiện Turnstile và trả về site key"""
try:
turnstile = self.driver.find_element(By.CLASS_NAME, "cf-turnstile")
return turnstile.get_attribute("data-sitekey")
except NoSuchElementException:
return None
def inject_token(self, token: str):
"""Chèn token Turnstile"""
self.driver.execute_script(f"""
var token = '{token}';
// Tìm trường cf-turnstile-response
var field = document.querySelector('[name="cf-turnstile-response"]');
if (field) {{
field.value = token;
}}
// Tìm tất cả các trường input liên quan đến turnstile
var inputs = document.querySelectorAll('input[name*="turnstile"]');
for (var i = 0; i < inputs.length; i++) {{
inputs[i].value = token;
}}
""")
print("Token đã được chèn!")
def crawl(self, url: str) -> dict:
"""Thu thập dữ liệu URL với xử lý Turnstile"""
result = {
'url': url,
'success': False,
'captcha_solved': False,
'captcha_type': None
}
try:
print(f"Đang truy cập: {url}")
self.driver.get(url)
time.sleep(3)
# Phát hiện Turnstile
site_key = self.detect_turnstile()
if site_key:
result['captcha_type'] = 'turnstile'
print(f"Phát hiện Turnstile! Site key: {site_key}")
# Giải
token = self.solver.solve(url, site_key)
# Chèn
self.inject_token(token)
result['captcha_solved'] = True
time.sleep(2)
result['success'] = True
result['title'] = self.driver.title
except Exception as e:
print(f"Lỗi: {e}")
result['error'] = str(e)
return result
def main():
"""Điểm vào chính"""
crawler = TurnstileCrawler(headless=True)
try:
crawler.start()
# Thu thập URL đích (thay thế bằng URL của bạn)
result = crawler.crawl("https://example.com/turnstile-protected")
print("\n" + "=" * 50)
print("KẾT QUẢ:")
print(json.dumps(result, indent=2))
finally:
crawler.stop()
if __name__ == "__main__":
main()Tích hợp Scrapy
Spider Scrapy đầy đủ với middleware CapSolver:
python
"""
Crawlab + CapSolver: Spider Scrapy
Spider Scrapy với middleware giải CAPTCHA
"""
import scrapy
import requests
import time
import os
CAPSOLVER_API_KEY = os.getenv('CAPSOLVER_API_KEY', 'YOUR_CAPSOLVER_API_KEY')
CAPSOLVER_API = 'https://api.capsolver.com'
class CapsolverMiddleware:
"""Middleware Scrapy cho giải CAPTCHA"""
def __init__(self):
self.api_key = CAPSOLVER_API_KEY
def solve_recaptcha_v2(self, url: str, site_key: str) -> str:
"""Giải reCAPTCHA v2"""
# Tạo nhiệm vụ
response = requests.post(
f"{CAPSOLVER_API}/createTask",
json={
"clientKey": self.api_key,
"task": {
"type": "ReCaptchaV2TaskProxyLess",
"websiteURL": url,
"websiteKey": site_key
}
}
)
task_id = response.json()['taskId']
# Kiểm tra kết quả
for _ in range(120):
result = requests.post(
f"{CAPSOLVER_API}/getTaskResult",
json={"clientKey": self.api_key, "taskId": task_id}
).json()
if result.get('status') == 'ready':
return result['solution']['gRecaptchaResponse']
time.sleep(1)
raise Exception("Hết thời gian")
class CaptchaSpider(scrapy.Spider):
"""Spider với xử lý CAPTCHA"""
name = "captcha_spider"
start_urls = ["https://example.com/protected"]
custom_settings = {
'DOWNLOAD_DELAY': 2,
'CONCURRENT_REQUESTS': 1,
}
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
self.capsolver = CapsolverMiddleware()
def parse(self, response):
# Kiểm tra reCAPTCHA
site_key = response.css('.g-recaptcha::attr(data-sitekey)').get()
if site_key:
self.logger.info(f"Phát hiện reCAPTCHA: {site_key}")
# Giải CAPTCHA
token = self.capsolver.solve_recaptcha_v2(response.url, site_key)
# Gửi biểu mẫu với token
yield scrapy.FormRequest.from_response(
response,
formdata={'g-recaptcha-response': token},
callback=self.after_captcha
)
else:
yield from self.extract_data(response)
def after_captcha(self, response):
"""Xử lý trang sau CAPTCHA"""
yield from self.extract_data(response)
def extract_data(self, response):
"""Trích xuất dữ liệu từ trang"""
yield {
'title': response.css('title::text').get(),
'url': response.url,
}
# Cài đặt Scrapy (settings.py)
"""
BOT_NAME = 'captcha_crawler'
SPIDER_MODULES = ['spiders']
# Capsolver
CAPSOLVER_API_KEY = 'YOUR_CAPSOLVER_API_KEY'
# Giới hạn tốc độ
DOWNLOAD_DELAY = 2
CONCURRENT_REQUESTS = 1
ROBOTSTXT_OBEY = True
"""Tích hợp Node.js/Puppeteer
Script Node.js hoàn chỉnh với Puppeteer:
javascript
/**
* Crawlab + Capsolver: Puppeteer Spider
* Script Node.js hoàn chỉnh để giải CAPTCHA
*/
const puppeteer = require('puppeteer');
const CAPSOLVER_API_KEY = process.env.CAPSOLVER_API_KEY || 'YOUR_CAPSOLVER_API_KEY';
const CAPSOLVER_API = 'https://api.capsolver.com';
/**
* Client Capsolver
*/
class Capsolver {
constructor(apiKey) {
this.apiKey = apiKey;
}
async createTask(task) {
const response = await fetch(`${CAPSOLVER_API}/createTask`, {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({
clientKey: this.apiKey,
task: task
})
});
const result = await response.json();
if (result.errorId !== 0) {
throw new Error(result.errorDescription);
}
return result.taskId;
}
async getTaskResult(taskId, timeout = 120) {
for (let i = 0; i < timeout; i++) {
const response = await fetch(`${CAPSOLVER_API}/getTaskResult`, {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({
clientKey: this.apiKey,
taskId: taskId
})
});
const result = await response.json();
if (result.status === 'ready') {
return result.solution;
}
if (result.status === 'failed') {
throw new Error('Nhiệm vụ thất bại');
}
await new Promise(r => setTimeout(r, 1000));
}
throw new Error('Hết thời gian');
}
async solveRecaptchaV2(url, siteKey) {
const taskId = await this.createTask({
type: 'ReCaptchaV2TaskProxyLess',
websiteURL: url,
websiteKey: siteKey
});
const solution = await this.getTaskResult(taskId);
return solution.gRecaptchaResponse;
}
async solveTurnstile(url, siteKey) {
const taskId = await this.createTask({
type: 'AntiTurnstileTaskProxyLess',
websiteURL: url,
websiteKey: siteKey
});
const solution = await this.getTaskResult(taskId);
return solution.token;
}
}
/**
* Hàm chính để quét
*/
async function crawlWithCaptcha(url) {
const capsolver = new Capsolver(CAPSOLVER_API_KEY);
const browser = await puppeteer.launch({
headless: true,
args: ['--no-sandbox', '--disable-setuid-sandbox']
});
const page = await browser.newPage();
try {
console.log(`Đang quét: ${url}`);
await page.goto(url, { waitUntil: 'networkidle2' });
// Phát hiện loại CAPTCHA
const captchaInfo = await page.evaluate(() => {
const recaptcha = document.querySelector('.g-recaptcha');
if (recaptcha) {
return {
type: 'recaptcha',
siteKey: recaptcha.dataset.sitekey
};
}
const turnstile = document.querySelector('.cf-turnstile');
if (turnstile) {
return {
type: 'turnstile',
siteKey: turnstile.dataset.sitekey
};
}
return null;
});
if (captchaInfo) {
console.log(`${captchaInfo.type} được phát hiện!`);
let token;
if (captchaInfo.type === 'recaptcha') {
token = await capsolver.solveRecaptchaV2(url, captchaInfo.siteKey);
// Chèn token
await page.evaluate((t) => {
const field = document.getElementById('g-recaptcha-response');
if (field) field.value = t;
document.querySelectorAll('textarea[name="g-recaptcha-response"]')
.forEach(el => el.value = t);
}, token);
} else if (captchaInfo.type === 'turnstile') {
token = await capsolver.solveTurnstile(url, captchaInfo.siteKey);
// Chèn token
await page.evaluate((t) => {
const field = document.querySelector('[name="cf-turnstile-response"]');
if (field) field.value = t;
}, token);
}
console.log('CAPTCHA đã được giải và chèn!');
}
// Trích xuất dữ liệu
const data = await page.evaluate(() => ({
title: document.title,
url: window.location.href
}));
return data;
} finally {
await browser.close();
}
}
// Thực thi chính
const targetUrl = process.argv[2] || 'https://example.com';
crawlWithCaptcha(targetUrl)
.then(result => {
console.log('\nKết quả:');
console.log(JSON.stringify(result, null, 2));
})
.catch(console.error);Các nguyên tắc tốt
1. Xử lý lỗi với thử lại
python
def solve_with_retry(solver, url, site_key, max_retries=3):
"""Giải CAPTCHA với logic thử lại"""
for attempt in range(max_retries):
try:
return solver.solve(url, site_key)
except Exception as e:
if attempt == max_retries - 1:
raise
print(f"Thử {attempt + 1} thất bại: {e}")
time.sleep(2 ** attempt) # Backoff theo cấp số nhân2. Quản lý chi phí
- Phát hiện trước khi giải: Chỉ gọi Capsolver khi CAPTCHA hiện diện
- Lưu trữ token: Token reCAPTCHA có hiệu lực khoảng 2 phút
- Theo dõi số dư: Kiểm tra số dư trước các công việc hàng loạt
3. Giới hạn tốc độ
python
# Cài đặt Scrapy
DOWNLOAD_DELAY = 3
CONCURRENT_REQUESTS_PER_DOMAIN = 14. Biến môi trường
bash
export CAPSOLVER_API_KEY="your-api-key-here"Xử lý sự cố
| Lỗi | Nguyên nhân | Giải pháp |
|---|---|---|
ERROR_ZERO_BALANCE |
Không đủ số dư | Nạp tiền vào tài khoản Capsolver |
ERROR_CAPTCHA_UNSOLVABLE |
Tham số không hợp lệ | Kiểm tra trích xuất site key |
TimeoutError |
Vấn đề mạng | Tăng thời gian chờ, thêm thử lại |
WebDriverException |
Trình duyệt bị treo | Thêm cờ --no-sandbox |
Câu hỏi thường gặp
Câu hỏi: Token CAPTCHA có hiệu lực bao lâu?
Trả lời: Token reCAPTCHA: khoảng 2 phút. Turnstile: tùy theo trang.
Câu hỏi: Thời gian giải trung bình là bao nhiêu?
Trả lời: reCAPTCHA v2: 5-15 giây, Turnstile: 1-10 giây.
Câu hỏi: Tôi có thể sử dụng proxy riêng không?
Trả lời: Có, sử dụng loại nhiệm vụ không có hậu tố "ProxyLess" và cung cấp cấu hình proxy.
Kết luận
Việc tích hợp Capsolver với Crawlab cho phép xử lý CAPTCHA hiệu quả trong cơ sở hạ tầng quét phân tán của bạn. Các script hoàn chỉnh ở trên có thể được sao chép trực tiếp vào spider của bạn.
Sẵn sàng bắt đầu? Đăng ký Capsolver và tăng tốc các robot quét của bạn!
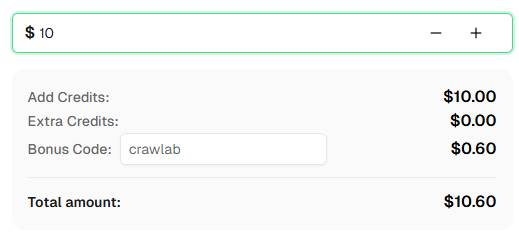
💡 Quà tặng đặc biệt cho người dùng Crawlab:
Để kỷ niệm sự tích hợp này, chúng tôi đang cung cấp mã giảm giá 6% — Crawlab cho tất cả người dùng Capsolver đăng ký qua hướng dẫn này.
Chỉ cần nhập mã trong phần nạp tiền trên Dashboard để nhận thêm 6% số dư ngay lập tức.
13. Tài liệu tham khảo
- 13.1. Tài liệu Crawlab
- 13.2. GitHub Crawlab
- 13.3. Tài liệu Capsolver
- 13.4. Tham khảo API Capsolver
Xem thêm
Web ScrapingApr 22, 2026
Kiến trúc Trích xuất Dữ liệu Từ Web bằng Rust cho Trích xuất Dữ liệu Có Thể Mở Rộng
Học kiến trúc gỡ mã web Rust có thể mở rộng với reqwest, scraper, gỡ mã bất đồng bộ, gỡ mã trình duyệt không đầu, xoay proxy và xử lý CAPTCHA tuân thủ.
Web ScrapingFeb 17, 2026
Cách giải CAPTCHA trên Nanobot bằng CapSolver
Tự động hóa việc giải CAPTCHA với Nanobot và CapSolver. Sử dụng Playwright để giải reCAPTCHA và Cloudflare tự động.

