Cách xử lý các rào cản khi quét web: Các phương pháp thực tế hiệu quả

Ethan Collins
Pattern Recognition Specialist

TL;Dr:
- Hiểu Cơ chế: Các trang web sử dụng theo dõi IP, phân tích dấu vân tay trình duyệt và phân tích hành vi để xác định và chặn các tập lệnh tự động.
- Thực hiện Quay Vòng: Sử dụng proxy nhà ở luân chuyển và chuỗi User-Agent đa dạng để mô phỏng các mẫu giao thông giống người dùng.
- Xử lý Thách thức: Tích hợp các công cụ chuyên dụng để giải CAPTCHA và quản lý các hệ thống phát hiện bot phức tạp một cách hiệu quả.
- Duy trì Đạo đức: Luôn tuân thủ hướng dẫn robots.txt và triển khai giới hạn tốc độ yêu cầu để duy trì tác động thấp đối với máy chủ mục tiêu.
Giới thiệu
Việc thu thập dữ liệu từ web đã trở thành thành phần thiết yếu trong việc ra quyết định dựa trên dữ liệu hiện đại, tuy nhiên, bối cảnh thu thập dữ liệu tự động đang ngày càng thách thức. Khi các trang web triển khai các biện pháp bảo mật phức tạp hơn, việc học cách xử lý các rào cản thu thập dữ liệu không còn chỉ là lợi thế — mà là điều cần thiết cho bất kỳ dự án trích xuất thành công nào. Hướng dẫn này cung cấp cái nhìn tổng quan về lý do các rào cản xảy ra, công nghệ đằng sau cơ chế phát hiện và các chiến lược hiệu quả, đạo đức để đảm bảo các công cụ trích xuất của bạn hoạt động. Dù bạn là nhà phát triển xây dựng một trình thu thập tùy chỉnh hay một nhà phân tích dữ liệu giám sát một hoạt động quy mô lớn, việc hiểu các phương pháp thực tế này sẽ giúp bạn duy trì truy cập liên tục vào thông tin bạn cần.
Hiểu Bản Chất của Rào Cản Thu Thập Dữ Liệu
Để quản lý hiệu quả các rào cản, trước tiên bạn cần hiểu chúng là gì và tại sao chúng tồn tại. Một rào cản thu thập dữ liệu là biện pháp phòng thủ được triển khai bởi một trang web để ngăn các tập lệnh tự động truy cập nội dung của nó. Các biện pháp này thường là một phần của chiến lược bảo mật rộng hơn được thiết kế để bảo vệ tài nguyên máy chủ, ngăn chặn việc đánh cắp tài sản trí tuệ hoặc duy trì tính toàn vẹn của dữ liệu người dùng.
Theo dữ liệu ngành gần đây, lưu lượng tự động chiếm một phần đáng kể trong tất cả các yêu cầu web, khiến nhiều nền tảng phải áp dụng lọc nghiêm ngặt. Bạn có thể tìm thấy thêm thông tin về xu hướng toàn cầu trong báo cáo Thống kê Lưu lượng Bot của Statista. Khi máy chủ phát hiện các mẫu khác biệt với hành vi của con người, nó có thể phản hồi bằng cách hiển thị CAPTCHA, làm chậm kết nối hoặc ban IP hoàn toàn. Việc học cách xử lý các rào cản thu thập dữ liệu trong các tình huống này là điều thiết yếu để duy trì dữ liệu.
Bối cảnh Kỹ thuật: Cách Cơ Chế Phát Hiện Hoạt Động
Các hệ thống bảo mật hiện đại không dựa vào một yếu tố duy nhất để xác định bot. Thay vào đó, chúng sử dụng một loạt kỹ thuật để xây dựng hồ sơ rủi ro cho mỗi yêu cầu đến.
1. Theo dõi Dựa trên IP
Đây là lớp phòng thủ cơ bản nhất. Máy chủ theo dõi số lượng yêu cầu đến từ một địa chỉ IP cụ thể trong một khoảng thời gian nhất định. Nếu tần suất vượt quá ngưỡng được định trước, IP sẽ bị đánh dấu. Đây là lý do tại sao việc biết cách xử lý các rào cản thu thập dữ liệu ở cấp độ mạng là rất quan trọng. Các trung tâm dữ liệu thường bị chặn trước vì chúng hiếm khi được sử dụng bởi người dùng hợp lệ.
2. Phân tích Dấu vân tay Trình duyệt
Ngoài địa chỉ IP, các trang web có thể thu thập một lượng lớn thông tin từ môi trường trình duyệt của bạn. Điều này bao gồm độ phân giải màn hình, phông chữ được cài đặt, múi giờ và thông số phần cứng. Nếu các chi tiết này xuất hiện không nhất quán hoặc quá "sạch sẽ" (đặc trưng của trình duyệt không giao diện), hệ thống sẽ nhận diện yêu cầu là tự động.
3. Phân tích Hành vi
Các nền tảng phức tạp theo dõi cách người dùng tương tác với trang. Người dùng di chuyển chuột theo các mẫu phi tuyến tính, dành thời gian đọc nội dung và nhấp vào các phần tử với nhịp điệu khác nhau. Ngược lại, một tập lệnh có thể nhảy trực tiếp đến URL và trích xuất dữ liệu trong vài mili giây. Bất kỳ sự sai lệch nào so với hành vi người dùng được kỳ vọng sẽ kích hoạt cảnh báo đỏ. Phát hiện dựa trên hành vi là một trong những thách thức khó khăn nhất khi tìm cách xử lý các rào cản thu thập dữ liệu.
Các Loại CAPTCHA Thông Thường
Khi hệ thống không chắc chắn nhưng nghi ngờ, nó thường sẽ hiển thị một CAPTCHA. Việc hiểu các loại này là điều thiết yếu để biết cách xử lý các rào cản thu thập dữ liệu một cách hiệu quả.
| Loại CAPTCHA | Mô tả | Logic Phát hiện Chính |
|---|---|---|
| Nhận dạng Hình ảnh | Người dùng phải chọn các đối tượng cụ thể (ví dụ: đèn giao thông) từ lưới. | Kiểm tra khả năng xử lý dữ liệu hình ảnh và nhận diện các mẫu nhấp tương tự người dùng. |
| CAPTCHA Ẩn | Chạy ở nền mà không cần tương tác của người dùng. | Phân tích môi trường trình duyệt và hành vi lịch sử để gán điểm rủi ro. |
| Thách thức Văn bản/Toán học | Yêu cầu giải một phương trình đơn giản hoặc gõ văn bản bị biến dạng. | Dựa vào độ khó của OCR (Nhận dạng chữ quang học) cho các bot cũ. |
| Bài toán/Xoay trượt | Người dùng phải kéo một mảnh để hoàn thành hình ảnh. | Tập trung vào chuyển động vật lý của con trỏ và thời gian thực hiện hành động. |
Các Phương Pháp Thực Tế để Xử Lý Rào Cản Thu Thập Dữ Liệu
Thực hiện các chiến lược kỹ thuật đúng đắn có thể giảm đáng kể khả năng bị phát hiện. Dưới đây là các phương pháp hiệu quả nhất được các chuyên gia sử dụng ngày nay.
Sử dụng Proxy Nhà ở Luân Chuyển
Vì việc cấm IP là phổ biến, sử dụng một nhóm proxy nhà ở là một trong những cách tốt nhất để tránh bị cấm IP và đảm bảo tỷ lệ thành công cao. Các proxy này là nền tảng của các thực hành tốt nhất trong thu thập dữ liệu. Khác với các IP trung tâm dữ liệu, các IP nhà ở liên quan đến kết nối internet thực tế, khiến chúng khó phân biệt hơn với người dùng hợp lệ. Bằng cách luân chuyển các IP này cho mỗi vài yêu cầu, bạn có thể phân phối lưu lượng và tránh bị phát hiện.
Quản lý Tiêu đề Yêu cầu và Chuỗi User-Agent
Mỗi yêu cầu HTTP bao gồm các tiêu đề nói với máy chủ về khách hàng. Một sai lầm phổ biến là sử dụng tiêu đề thư viện mặc định như "python-requests/2.25.1". Thay vào đó, bạn nên sử dụng một loạt chuỗi User-Agent thực tế. Tham khảo Tài liệu User-Agent của MDN để hiểu cách cấu trúc chúng đúng. Đảm bảo tiêu đề của bạn bao gồm các trường như "Accept-Language" và "Referer" để mô phỏng phiên duyệt web thực tế.
Triển khai Giới hạn Tốc độ Yêu cầu
Tốc độ thường là yếu tố tiết lộ bot lớn nhất. Bằng cách thêm khoảng thời gian ngẫu nhiên giữa các yêu cầu của bạn, bạn có thể mô phỏng hành vi duyệt web của người dùng. Kỹ thuật này, được gọi là giới hạn tốc độ, ngăn bạn làm quá tải máy chủ mục tiêu và giảm khả năng kích hoạt báo động giới hạn tốc độ. Việc triển khai các thực hành tốt nhất trong thu thập dữ liệu này sẽ giúp bạn duy trì truy cập vào dữ liệu nhạy cảm đồng thời giúp bạn tránh bị cấm IP trong các hoạt động quy mô lớn.
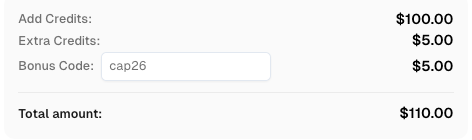
Sử dụng mã
CAP26khi đăng ký tại CapSolver để nhận thêm tín dụng!
Giải CAPTCHA Tự động
Ngay cả với tiêu đề và proxy hoàn hảo, bạn sẽ sớm gặp phải một thách thức. Đây là lúc các dịch vụ chuyên dụng trở nên quý giá. Ví dụ, CapSolver cung cấp API mạnh mẽ để giải các loại thách thức khác nhau, chẳng hạn như ReCaptcha và FriendlyCaptcha, đảm bảo quy trình tự động của bạn không bị gián đoạn. Các công cụ này là cốt lõi trong việc xử lý các rào cản thu thập dữ liệu trong môi trường hiện đại.
Nếu bạn đang sử dụng các công cụ như cURL hoặc Python cho tự động hóa, bạn có thể tích hợp một giải pháp theo quy trình chung sau:
- Gửi Nhiệm vụ: Gửi chi tiết CAPTCHA (key trang web, URL) đến dịch vụ.
- Nhận Giải pháp: Lấy API bằng ID Nhiệm vụ cho đến khi giải pháp sẵn sàng.
- Gửi Token: Sử dụng token được trả về để vượt qua thách thức trên trang mục tiêu.
Dưới đây là ví dụ đơn giản dựa trên tài liệu CapSolver để gửi một nhiệm vụ:
json
{
"clientKey": "YOUR_API_KEY",
"task": {
"type": "ReCaptchaV2TaskProxyLess",
"websiteURL": "https://www.example.com",
"websiteKey": "6LcR_okUAAAAAPYrPe-z_bx1oYxq6zz_S0vO49zV"
}
}Tóm tắt So sánh: Phương pháp Thu Thập Dữ Liệu
Để giúp bạn chọn phương pháp phù hợp, dưới đây là so sánh các phương pháp phổ biến.
| Phương pháp | Hiệu quả | Độ phức tạp Triển khai | Chi phí |
|---|---|---|---|
| Tiêu đề Cơ bản | Thấp | Thấp | Miễn phí |
| Proxy Trung tâm Dữ liệu | Trung bình | Trung bình | Thấp |
| Proxy Nhà ở | Cao | Trung bình | Trung bình |
| Trình duyệt Không giao diện | Cao | Cao | Cao (Nguồn lực) |
| Giải CAPTCHA | Thiết yếu | Thấp | Thấp |
Xem xét Đạo đức và Tuân thủ
Khi học cách xử lý các rào cản thu thập dữ liệu, điều rất quan trọng là nhấn mạnh các thực hành đạo đức. Việc thu thập dữ liệu tự động nên luôn được thực hiện theo cách tôn trọng các điều khoản của trang web mục tiêu và sức khỏe máy chủ. Luôn kiểm tra tệp robots.txt của một miền để xem các khu vực nào bị hạn chế. Tuân thủ các thực hành tốt nhất trong thu thập dữ liệu không chỉ bảo vệ bạn về mặt pháp lý mà còn đảm bảo sự tồn tại lâu dài của nguồn dữ liệu của bạn.
Đối với những người tìm kiếm các công cụ nâng cao hơn, khám phá các công cụ trích xuất dữ liệu tốt nhất có thể cung cấp thêm thông tin về việc xây dựng các hệ thống bền vững.
Chuyển tiếp Tự nhiên đến Giải pháp
Khi công nghệ phát hiện bot phát triển, độ phức tạp của việc duy trì một trình thu thập dữ liệu ngày càng tăng. Nhiều nhà phát triển phát hiện rằng tại sao tự động hóa web vẫn thất bại với CAPTCHA thường do thiếu chiến lược xử lý chuyên dụng. Sử dụng người giải CAPTCHA tốt nhất cho phép bạn tập trung vào phân tích dữ liệu thay vì liên tục sửa các tập lệnh bị hỏng. Bằng cách tích hợp các dịch vụ chuyên nghiệp này vào stack của bạn, bạn có thể đảm bảo tỷ lệ thành công cao ngay cả trên các nền tảng được bảo vệ nhất.
Kết luận
Thành thạo cách xử lý các rào cản thu thập dữ liệu đòi hỏi một cách tiếp cận đa lớp kết hợp giữa độ chính xác kỹ thuật và trách nhiệm đạo đức. Bằng cách hiểu logic phát hiện, triển khai quản lý proxy mạnh mẽ và sử dụng các dịch vụ giải quyết chuyên dụng, bạn có thể xây dựng các luồng dữ liệu đáng tin cậy. Hãy nhớ rằng mục tiêu không chỉ là vượt qua một rào cản duy nhất, mà là tạo ra một hệ thống bền vững tôn trọng hệ sinh thái kỹ thuật số đồng thời cung cấp các thông tin mà doanh nghiệp của bạn phụ thuộc vào.
Câu hỏi Thường Gặp
1. Tại sao tôi vẫn bị chặn ngay cả với proxy?
Các rào cản có thể xảy ra do theo dõi dấu vân tay trình duyệt hoặc tiêu đề không nhất quán. Đảm bảo rằng User-Agent của bạn khớp với vị trí được nhận của proxy và bạn không để lộ IP thực của mình qua WebRTC.
2. Việc vượt qua các rào cản thu thập dữ liệu có hợp pháp không?
Tính hợp pháp phụ thuộc vào khu vực của bạn và loại dữ liệu bạn đang thu thập. Nói chung, việc thu thập dữ liệu công khai là hợp pháp, nhưng bạn phải tuân thủ luật bản quyền và bảo vệ dữ liệu cá nhân.
3. Bạn nên thay đổi User-Agent bao nhiêu lần?
Tốt nhất là sử dụng một chuỗi User-Agent mới cho mỗi phiên hoặc mỗi vài trăm yêu cầu, đặc biệt nếu bạn cũng đang luân chuyển IP của mình.
4. Trình duyệt không giao diện có thể ngăn tất cả các rào cản không?
Mặc dù hữu ích, các trình duyệt không giao diện như Puppeteer hoặc Playwright vẫn có thể bị phát hiện thông qua các thuộc tính cụ thể. Bạn phải sử dụng các plugin "stealth" để che giấu bản chất tự động của chúng.
5. Cách hiệu quả nhất để xử lý CAPTCHA là gì?
Sử dụng dịch vụ giải CAPTCHA dựa trên API như CapSolver thường hiệu quả hơn so với việc xây dựng các mô hình ML của riêng bạn hoặc sử dụng lao động thủ công, vì nó cung cấp tốc độ và độ chính xác cao với chi phí thấp cho mỗi nhiệm vụ.
Xem thêm
The Other CAPTCHAMay 15, 2026
API giải CAPTCHA nhanh cho quy trình tự động hóa
API giải CAPTCHA nhanh chóng dành cho tự động hóa: so sánh quy trình token, các thách thức được hỗ trợ, kiểm tra độ trễ và tích hợp CapSolver có trách nhiệm.

The Other CAPTCHAApr 03, 2026
Giải Thích Thời Gian Phản Hồi API Giải CAPTCHA: Yếu Tố Tốc Độ & Hiệu Suất
Hiểu rõ thời gian phản hồi của API giải CAPTCHA, tác động của nó đến tự động hóa và các yếu tố chính ảnh hưởng đến tốc độ. Học cách tối ưu hóa hiệu suất và tận dụng các giải pháp hiệu quả như CapSolver để giải CAPTCHA nhanh chóng.

