Lấy dữ liệu web với SeleniumBase và Python năm 2024

Rajinder Singh
Deep Learning Researcher

Web scraping là một công cụ mạnh mẽ để trích xuất dữ liệu, nghiên cứu thị trường và tự động hóa. Tuy nhiên, CAPTCHA có thể cản trở nỗ lực tự động hóa scraping. Trong hướng dẫn này, chúng ta sẽ khám phá cách sử dụng SeleniumBase để web scraping và tích hợp CapSolver để giải quyết CAPTCHA một cách hiệu quả, sử dụng quotes.toscrape.com làm trang web ví dụ của chúng tôi.
Giới thiệu về SeleniumBase
SeleniumBase là một framework Python giúp đơn giản hóa tự động hóa web và kiểm thử. Nó mở rộng khả năng của Selenium WebDriver với một API thân thiện với người dùng hơn, các trình chọn nâng cao, chờ đợi tự động và các công cụ kiểm thử bổ sung.
Cài đặt SeleniumBase
Trước khi bắt đầu, hãy đảm bảo rằng bạn đã cài đặt Python 3 trên hệ thống của mình. Làm theo các bước sau để cài đặt SeleniumBase:
-
Cài đặt SeleniumBase:
bashpip install seleniumbase -
Xác minh cài đặt:
bashsbase --help
Bộ scraping cơ bản với SeleniumBase
Hãy bắt đầu bằng cách tạo một script đơn giản điều hướng đến quotes.toscrape.com và trích xuất trích dẫn và tác giả.
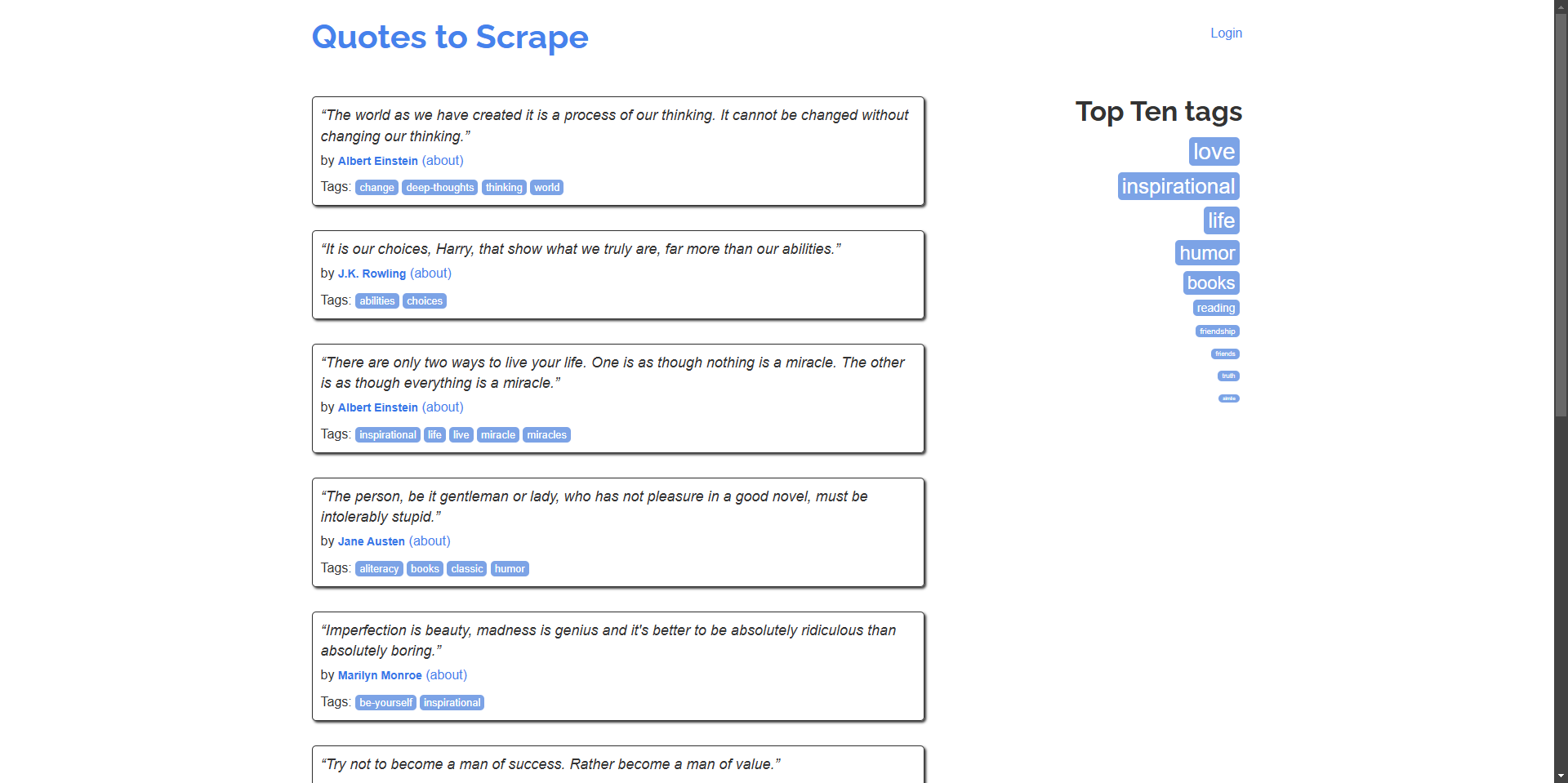
Ví dụ: Scraping trích dẫn và tác giả của chúng từ trang chủ.
python
# scrape_quotes.py
from seleniumbase import BaseCase
class QuotesScraper(BaseCase):
def test_scrape_quotes(self):
self.open("https://quotes.toscrape.com/")
quotes = self.find_elements("div.quote")
for quote in quotes:
text = quote.find_element("span.text").text
author = quote.find_element("small.author").text
print(f"\"{text}\" - {author}")
if __name__ == "__main__":
QuotesScraper().main()Chạy script:
bash
python scrape_quotes.pyKết quả:
“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.” - Albert Einstein
...Các ví dụ web scraping nâng cao hơn
Để nâng cao kỹ năng web scraping của bạn, hãy khám phá các ví dụ nâng cao hơn bằng cách sử dụng SeleniumBase.
Scraping nhiều trang (Phân trang)
Nhiều trang web hiển thị nội dung trên nhiều trang. Hãy sửa đổi script của chúng ta để điều hướng qua tất cả các trang và scraping trích dẫn.
python
# scrape_quotes_pagination.py
from seleniumbase import BaseCase
class QuotesPaginationScraper(BaseCase):
def test_scrape_all_quotes(self):
self.open("https://quotes.toscrape.com/")
while True:
quotes = self.find_elements("div.quote")
for quote in quotes:
text = quote.find_element("span.text").text
author = quote.find_element("small.author").text
print(f"\"{text}\" - {author}")
# Kiểm tra xem có trang tiếp theo không
if self.is_element_visible('li.next > a'):
self.click('li.next > a')
else:
break
if __name__ == "__main__":
QuotesPaginationScraper().main()Giải thích:
- Chúng ta lặp qua các trang bằng cách kiểm tra xem nút "Next" có sẵn hay không.
- Chúng ta sử dụng
is_element_visibleđể kiểm tra nút "Next". - Chúng ta nhấp vào nút "Next" để điều hướng đến trang tiếp theo.
Xử lý nội dung động với AJAX
Một số trang web tải nội dung động bằng cách sử dụng AJAX. SeleniumBase có thể xử lý các trường hợp như vậy bằng cách chờ đợi các phần tử được tải.
Ví dụ: Scraping thẻ từ trang web, được tải động.
python
# scrape_dynamic_content.py
from seleniumbase import BaseCase
class TagsScraper(BaseCase):
def test_scrape_tags(self):
self.open("https://quotes.toscrape.com/")
# Nhấp vào liên kết 'Top Ten tags' để tải thẻ động
self.click('a[href="/tag/"]')
self.wait_for_element("div.tags-box")
tags = self.find_elements("span.tag-item > a")
for tag in tags:
tag_name = tag.text
print(f"Tag: {tag_name}")
if __name__ == "__main__":
TagsScraper().main()Giải thích:
- Chúng ta chờ đợi phần tử
div.tags-boxđể đảm bảo nội dung động được tải. wait_for_elementđảm bảo rằng script không tiến hành cho đến khi phần tử có sẵn.
Gửi biểu mẫu và đăng nhập
Đôi khi, bạn cần đăng nhập vào một trang web trước khi scraping nội dung. Dưới đây là cách bạn có thể xử lý việc gửi biểu mẫu.
Ví dụ: Đăng nhập vào trang web và scraping trích dẫn từ trang của người dùng đã xác thực.
python
# scrape_with_login.py
from seleniumbase import BaseCase
class LoginScraper(BaseCase):
def test_login_and_scrape(self):
self.open("https://quotes.toscrape.com/login")
# Điền vào biểu mẫu đăng nhập
self.type("input#username", "testuser")
self.type("input#password", "testpass")
self.click("input[type='submit']")
# Xác minh đăng nhập bằng cách kiểm tra liên kết đăng xuất
if self.is_element_visible('a[href="/logout"]'):
print("Logged in successfully!")
# Bây giờ scraping các trích dẫn
self.open("https://quotes.toscrape.com/")
quotes = self.find_elements("div.quote")
for quote in quotes:
text = quote.find_element("span.text").text
author = quote.find_element("small.author").text
print(f"\"{text}\" - {author}")
else:
print("Login failed.")
if __name__ == "__main__":
LoginScraper().main()Giải thích:
- Chúng ta điều hướng đến trang đăng nhập và điền vào thông tin xác thực.
- Sau khi gửi biểu mẫu, chúng ta xác minh đăng nhập bằng cách kiểm tra sự hiện diện của liên kết đăng xuất.
- Sau đó, chúng ta tiến hành scraping nội dung có sẵn cho người dùng đã đăng nhập.
Lưu ý: Vì quotes.toscrape.com cho phép bất kỳ tên người dùng và mật khẩu nào để trình diễn, chúng ta có thể sử dụng thông tin xác thực giả.
Trích xuất dữ liệu từ bảng
Các trang web thường hiển thị dữ liệu trong bảng. Dưới đây là cách để trích xuất dữ liệu bảng.
Ví dụ: Scraping dữ liệu từ một bảng (ví dụ giả định vì trang web không có bảng).
python
# scrape_table.py
from seleniumbase import BaseCase
class TableScraper(BaseCase):
def test_scrape_table(self):
self.open("https://www.example.com/table-page")
# Chờ đợi bảng được tải
self.wait_for_element("table#data-table")
rows = self.find_elements("table#data-table > tbody > tr")
for row in rows:
cells = row.find_elements("td")
row_data = [cell.text for cell in cells]
print(row_data)
if __name__ == "__main__":
TableScraper().main()Giải thích:
- Chúng ta xác định vị trí của bảng bằng ID hoặc lớp của nó.
- Chúng ta lặp qua từng hàng và sau đó lặp qua từng ô để trích xuất dữ liệu.
- Vì
quotes.toscrape.comkhông có bảng, hãy thay thế URL bằng một trang web thực tế có chứa bảng.
Tích hợp CapSolver vào SeleniumBase
Mặc dù quotes.toscrape.com không có CAPTCHA, nhưng nhiều trang web trong thế giới thực lại có. Để chuẩn bị cho những trường hợp như vậy, chúng ta sẽ chứng minh cách tích hợp CapSolver vào script SeleniumBase của chúng ta bằng cách sử dụng phần mở rộng trình duyệt CapSolver.
Cách giải quyết captcha với SeleniumBase sử dụng Capsolver
-
Tải xuống phần mở rộng CapSolver:
- Truy cập trang phát hành CapSolver GitHub.
- Tải xuống phiên bản mới nhất của phần mở rộng trình duyệt CapSolver.
- Giải nén phần mở rộng vào một thư mục ở gốc dự án của bạn, ví dụ:
./capsolver_extension.
Cấu hình phần mở rộng CapSolver
-
Xác định vị trí tệp cấu hình:
- Tìm tệp
config.jsonnằm trong thư mụccapsolver_extension/assets.
- Tìm tệp
-
Cập nhật cấu hình:
- Đặt
enabledForcaptchavà/hoặcenabledForRecaptchaV2thànhtruetùy thuộc vào loại CAPTCHA bạn muốn giải quyết. - Đặt
captchaModehoặcreCaptchaV2Modethành"token"để tự động giải quyết.
Ví dụ
config.json:json{ "apiKey": "YOUR_CAPSOLVER_API_KEY", "enabledForcaptcha": true, "captchaMode": "token", "enabledForRecaptchaV2": true, "reCaptchaV2Mode": "token", "solveInvisibleRecaptcha": true, "verbose": false }- Thay thế
"YOUR_CAPSOLVER_API_KEY"bằng khóa API CapSolver thực tế của bạn.
- Đặt
Tải phần mở rộng CapSolver trong SeleniumBase
Để sử dụng phần mở rộng CapSolver trong SeleniumBase, chúng ta cần cấu hình trình duyệt để tải phần mở rộng khi nó khởi động.
-
Sửa đổi script SeleniumBase của bạn:
- Nhập
ChromeOptionstừselenium.webdriver.chrome.options. - Cài đặt các tùy chọn để tải phần mở rộng CapSolver.
Ví dụ:
pythonfrom seleniumbase import BaseCase from selenium.webdriver.chrome.options import Options as ChromeOptions import os class QuotesScraper(BaseCase): def setUp(self): super().setUp() # Đường dẫn đến phần mở rộng CapSolver extension_path = os.path.abspath('capsolver_extension') # Cấu hình tùy chọn Chrome options = ChromeOptions() options.add_argument(f"--load-extension={extension_path}") options.add_argument("--disable-gpu") options.add_argument("--no-sandbox") # Cập nhật trình điều khiển bằng các tùy chọn mới self.driver.quit() self.driver = self.get_new_driver(browser_name="chrome", options=options) - Nhập
-
Đảm bảo đường dẫn phần mở rộng là chính xác:
- Hãy đảm bảo rằng
extension_pathtrỏ đến thư mục nơi bạn đã giải nén phần mở rộng CapSolver.
- Hãy đảm bảo rằng
Ví dụ script tích hợp CapSolver
Dưới đây là một script đầy đủ tích hợp CapSolver vào SeleniumBase để tự động giải quyết CAPTCHA. Chúng ta sẽ tiếp tục sử dụng https://recaptcha-demo.appspot.com/recaptcha-v2-checkbox.php làm trang web ví dụ của chúng ta.
python
# scrape_quotes_with_capsolver.py
from seleniumbase import BaseCase
from selenium.webdriver.chrome.options import Options as ChromeOptions
import os
class QuotesScraper(BaseCase):
def setUp(self):
super().setUp()
# Đường dẫn đến thư mục phần mở rộng CapSolver
# Đảm bảo đường dẫn này trỏ đến thư mục phần mở rộng Chrome CapSolver một cách chính xác
extension_path = os.path.abspath('capsolver_extension')
# Cấu hình tùy chọn Chrome
options = ChromeOptions()
options.add_argument(f"--load-extension={extension_path}")
options.add_argument("--disable-gpu")
options.add_argument("--no-sandbox")
# Cập nhật trình điều khiển bằng các tùy chọn mới
self.driver.quit() # Đóng bất kỳ phiên bản trình điều khiển hiện có nào
self.driver = self.get_new_driver(browser_name="chrome", options=options)
def test_scrape_quotes(self):
# Điều hướng đến trang web mục tiêu với reCAPTCHA
self.open("https://recaptcha-demo.appspot.com/recaptcha-v2-checkbox.php")
# Kiểm tra xem CAPTCHA có mặt và giải quyết nếu cần
if self.is_element_visible("iframe[src*='recaptcha']"):
# Phần mở rộng CapSolver sẽ tự động xử lý CAPTCHA
print("CAPTCHA detected, waiting for CapSolver extension to solve it...")
# Chờ đợi CAPTCHA được giải quyết
self.sleep(10) # Điều chỉnh thời gian dựa trên thời gian giải quyết trung bình
# Tiến hành các hành động scraping sau khi CAPTCHA được giải quyết
# Hành động ví dụ: nhấp vào nút hoặc trích xuất văn bản
self.assert_text("reCAPTCHA demo", "h1") # Xác nhận nội dung trang
def tearDown(self):
# Dọn dẹp và đóng trình duyệt sau khi kiểm tra
self.driver.quit()
super().tearDown()
if __name__ == "__main__":
QuotesScraper().main()Giải thích:
-
Phương thức setUp:
- Chúng ta ghi đè phương thức
setUpđể cấu hình trình duyệt Chrome với phần mở rộng CapSolver trước mỗi kiểm tra. - Chúng ta chỉ định đường dẫn đến phần mở rộng CapSolver và thêm nó vào các tùy chọn Chrome.
- Chúng ta đóng trình điều khiển hiện có và tạo một trình điều khiển mới với các tùy chọn đã cập nhật.
- Chúng ta ghi đè phương thức
-
Phương thức test_scrape_quotes:
- Chúng ta điều hướng đến trang web mục tiêu.
- Phần mở rộng CapSolver sẽ tự động phát hiện và giải quyết bất kỳ CAPTCHA nào.
- Chúng ta thực hiện các tác vụ scraping như bình thường.
-
Phương thức tearDown:
- Chúng ta đảm bảo rằng trình duyệt được đóng sau khi kiểm tra để giải phóng tài nguyên.
Chạy script:
bash
python scrape_quotes_with_capsolver.pyLưu ý: Mặc dù quotes.toscrape.com không có CAPTCHA, nhưng việc tích hợp CapSolver sẽ chuẩn bị cho bộ scraping của bạn cho các trang có CAPTCHA.
Mã bổ sung
Nhận Mã bổ sung của bạn cho các giải pháp captcha hàng đầu tại CapSolver: scrape. Sau khi đổi mã, bạn sẽ nhận được thêm 5% tiền thưởng sau mỗi lần nạp tiền, không giới hạn lần.

Kết luận
Trong hướng dẫn này, chúng ta đã khám phá cách thực hiện web scraping bằng SeleniumBase, bao gồm các kỹ thuật scraping cơ bản và các ví dụ nâng cao hơn như xử lý phân trang, nội dung động và gửi biểu mẫu. Chúng ta cũng đã chứng minh cách tích hợp CapSolver vào các script SeleniumBase của bạn để tự động giải quyết CAPTCHA, đảm bảo các phiên scraping không bị gián đoạn.
Xem thêm
AIJun 18, 2026
Lựa chọn Người giải CAPTCHA cho Hệ thống Người agent của Bạn
Một khung quyết định để lựa chọn một trình giải CAPTCHA cho cơ sở hạ tầng tác nhân, tập trung vào bản đồ hóa thách thức, liên kết phiên, khả năng quan sát, kiểm soát tỷ lệ và sử dụng có trách nhiệm.

AIJun 18, 2026
API CAPTCHA tốt nhất dành cho các tác nhân AI vào năm 2026
Hướng dẫn đánh giá thực tế để lựa chọn API CAPTCHA cho các tác nhân AI vào năm 2026, tập trung vào phạm vi nhiệm vụ được tài liệu hóa, hợp đồng kiểm tra, xác thực token và kiểm soát hoạt động.