API Tìm kiếm so với Chuỗi cung ứng tri thức: Hướng dẫn cơ sở hạ tầng dữ liệu AI

Anh Tuan
Data Science Expert
Tóm tắt
- Các công cụ API tìm kiếm hữu ích để khám phá nhanh, nhưng không đáp ứng đầy đủ nhu cầu của hệ thống AI sản xuất.
- Chuỗi cung ứng tri thức bao gồm khám phá, trích xuất, kiểm tra, lưu trữ, điều phối và giám sát.
- API SERP giúp thu thập kết quả tìm kiếm được xếp hạng, trong khi API quét trang web giúp thu thập nội dung cấp trang.
- Cơ sở dữ liệu web mạnh phụ thuộc vào tính mới nhất, chất lượng nguồn, khả năng kiểm toán và thu thập có nhận thức về chính sách.
- Một luồng dữ liệu AI nên kết nối việc truy xuất với phân tích, bổ sung, quản trị và sử dụng mô hình đầu ra.
- Đối với tự động hóa được phê duyệt, các nhóm có thể cần lớp độ tin cậy khi các bước kiểm tra làm gián đoạn luồng thu thập.
Giới thiệu
Câu trả lời ngắn gọn rất đơn giản. Một API tìm kiếm là giao diện truy xuất, trong khi chuỗi cung ứng tri thức là mô hình hoạt động cho cơ sở hạ tầng dữ liệu AI. Bài viết này dành cho các kỹ sư AI, các nhà sáng lập kỹ thuật, các nhóm SEO và các nhà xây dựng nền tảng dữ liệu cần dữ liệu web hiện tại mà không mất kiểm soát chất lượng hoặc tuân thủ. Nếu bạn đang chọn giữa giao diện tìm kiếm, API SERP và một bộ công cụ cơ sở hạ tầng dữ liệu web rộng hơn, quyết định đúng đắn phụ thuộc vào rủi ro, tính mới nhất và việc sử dụng đầu ra. Giá trị cốt lõi là sự rõ ràng thực tế. Bạn sẽ thấy mỗi tùy chọn phù hợp ở đâu, nơi nó gặp vấn đề và cách thiết kế một luồng dữ liệu AI đáng tin cậy hơn.
Giới thiệu về API tìm kiếm và chuỗi cung ứng tri thức
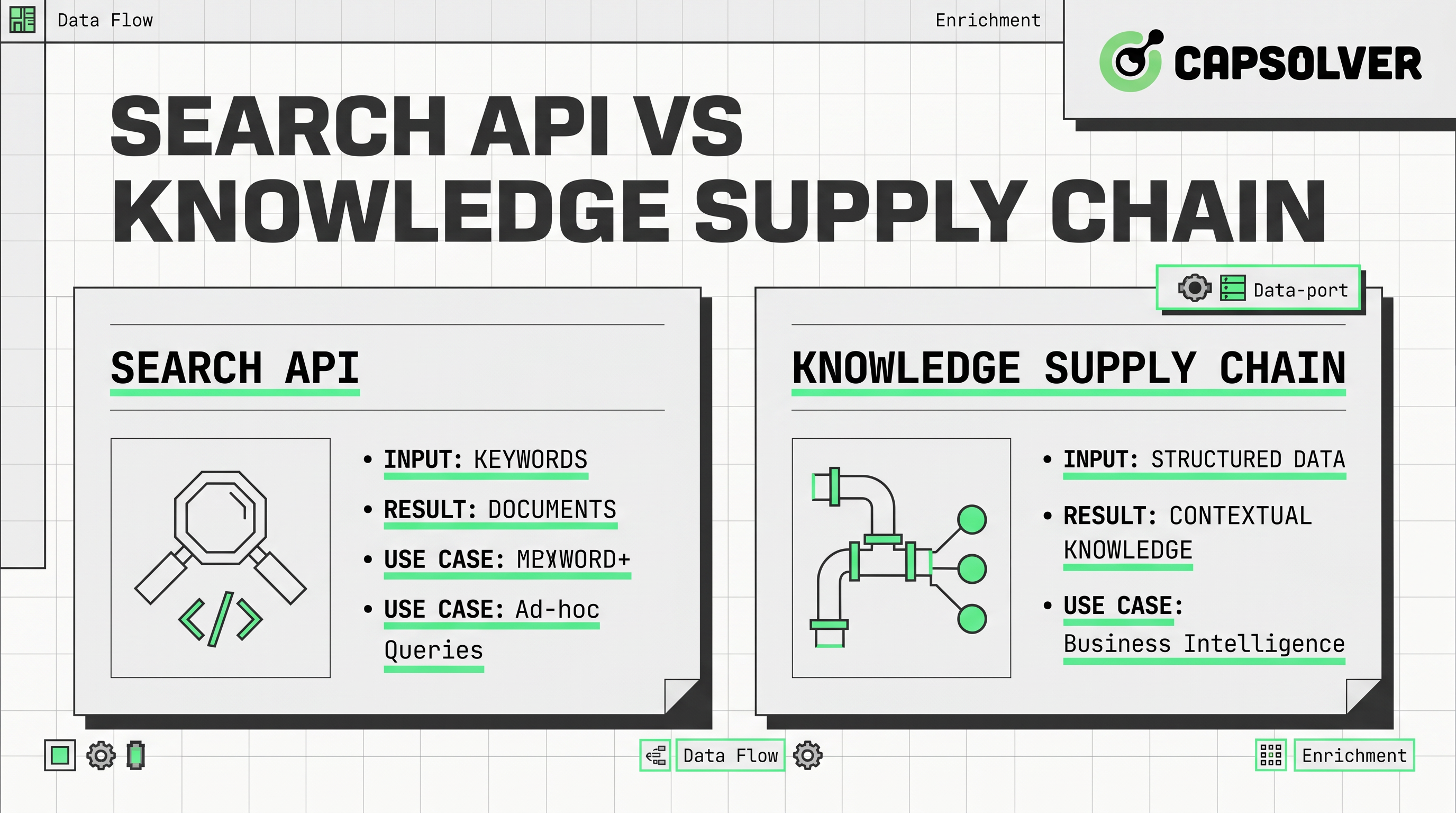
Sự khác biệt chính là kiến trúc. Một API tìm kiếm thường nhận một truy vấn và trả về các liên kết được xếp hạng, đoạn trích hoặc kết quả tóm tắt từ một chỉ mục. Điều này khiến các công cụ này hấp dẫn khi các nhóm cần câu trả lời nhanh, bổ sung nhẹ nhàng hoặc các giai đoạn đầu của dự án.
Chuỗi cung ứng tri thức rộng hơn về mặt thiết kế. Nó coi việc thu thập dữ liệu cho AI là luồng liên tục từ khám phá nguồn đến thu thập, kiểm tra, lưu trữ, chuyển đổi và phân phối. Mô hình này phù hợp tốt hơn với các hệ thống đại lý, công cụ thông tin thị trường và lớp truy xuất phải hỗ trợ các quyết định lặp lại.
Sự khác biệt này quan trọng vì các hệ thống AI hành động dựa trên những gì chúng nhận được. Khung quản lý rủi ro AI của NIST giải thích rằng AI đáng tin cậy phụ thuộc vào các thực hành thiết kế, phát triển, sử dụng và đánh giá, không chỉ là đầu ra của mô hình. Trên thực tế, điều này có nghĩa là lớp truy xuất là một phần của bề mặt rủi ro.
Lý do thứ hai là chính sách. Google Search Central cho biết rằng robots.txt chủ yếu được sử dụng để quản lý lưu lượng crawler và không phải là phương pháp phổ quát để ẩn nội dung. Lưu ý này quan trọng đối với bất kỳ nhóm nào xây dựng cơ sở hạ tầng dữ liệu web. Tuân thủ bắt đầu trước khi gửi yêu cầu đầu tiên.
Cách API tìm kiếm hoạt động trong hệ thống truy xuất dữ liệu
Mô tả đơn giản nhất là vậy. Một API tìm kiếm nằm ở lớp khám phá. Nó chuyển đổi truy vấn văn bản thành kết quả được xếp hạng có thể cấp cho chatbot, copilot hoặc trợ lý nghiên cứu.
Hầu hết các công cụ tìm kiếm tối ưu hóa tốc độ và tiện lợi cho nhà phát triển. Điều này thường có nghĩa là dữ liệu đã được chỉ mục, kết quả được lưu trữ hoặc lớp liên quan được xây dựng sẵn. Đối với các nhiệm vụ ít rủi ro, điều này là đủ. Một bot hỗ trợ, công cụ đề xuất SEO hoặc một đại lý thử nghiệm thường được hưởng lợi từ loại điểm cuối truy xuất này vì hệ thống cần định hướng trước khi cần bằng chứng sâu sắc.
API SERP hẹp hơn. Nó tập trung vào các trang kết quả tìm kiếm và các yếu tố kết quả liên quan. Điều này có thể hữu ích cho việc theo dõi thứ hạng, giám sát truy vấn và nghiên cứu SEO cạnh tranh. Tuy nhiên, API SERP vẫn phản ánh lớp tìm kiếm, không phải lớp nội dung đầy đủ. Nếu hệ thống của bạn cần văn bản trang thực tế, trường được cấu trúc hoặc so sánh lịch sử, bạn thường cần bước tiếp theo.
Đây là nơi mọi người nhầm lẫn giữa khám phá và tri thức. Khám phá cho bạn biết nơi cần xem. Tri thức yêu cầu tải xuống, phân tích và kiểm tra những gì thực sự có đó. Một điểm cuối tìm kiếm giúp phần đầu tiên. Nó không hoàn thành toàn bộ luồng dữ liệu AI.
Chuỗi cung ứng tri thức trong kiến trúc AI là gì
Cách tốt hơn để định nghĩa là theo cách vận hành. Chuỗi cung ứng tri thức là hệ thống chuyển dữ liệu từ web mở vào bối cảnh sẵn sàng cho quyết định cho mô hình, đại lý và nhà phân tích.
Ý tưởng chuỗi cung ứng xuất hiện trong nhiều bài viết gần đây, nhưng nhiều bài dừng lại ở ẩn dụ. Phiên bản thực tế có sáu lớp. Đầu tiên là khám phá thông qua giao diện tìm kiếm, API SERP, nguồn cấp dữ liệu, bản đồ trang web hoặc các nguồn đã biết. Thứ hai là trích xuất thông qua API quét web, tự động hóa trình duyệt hoặc kết nối trực tiếp từ nguồn. Thứ ba là chuẩn hóa, nơi HTML, JSON, PDF và dữ liệu phụ được chuyển đổi thành các bản ghi nhất quán. Thứ tư là kiểm tra, kiểm tra tính mới nhất, trùng lặp, quyền sở hữu và chất lượng nguồn. Thứ năm là lưu trữ và phân chỉ mục để truy xuất. Thứ sáu là điều phối, nơi luồng dữ liệu AI gửi kết quả vào hệ thống RAG, người đánh giá hoặc công cụ đại lý.
Mô hình ngữ cảnh (Model Context Protocol) cung cấp một manh mối hữu ích. Tài liệu MCP định nghĩa nó là tiêu chuẩn mở để kết nối các ứng dụng AI với nguồn dữ liệu, công cụ và quy trình. Nó không thay thế lớp tìm kiếm, nhưng cho thấy lý do tại sao chuỗi cung ứng tri thức phải bao gồm các giao diện ngoài việc truy xuất.
Tóm lại, API tìm kiếm là công cụ. Chuỗi cung ứng tri thức là hệ thống.
Sự khác biệt chính giữa API tìm kiếm và chuỗi cung ứng tri thức
Câu trả lời rõ ràng nhất nằm ở các ràng buộc hoạt động. Một API tìm kiếm thường tối ưu hóa cho tra cứu nhanh. Một chuỗi cung ứng tri thức tối ưu hóa cho chất lượng dữ liệu dưới tải công việc thực tế.
Tóm tắt so sánh
| Kích thước | API tìm kiếm | API SERP | Chuỗi cung ứng tri thức |
|---|---|---|---|
| Nhiệm vụ chính | Khám phá dựa trên truy vấn | Thu thập kết quả SERP | Thu thập dữ liệu toàn diện cho AI |
| Kết quả thông thường | Liên kết, đoạn trích, tóm tắt | Các yếu tố SERP được xếp hạng | Nội dung đầy đủ, dữ liệu phụ, lịch sử, kiểm tra |
| Phù hợp nhất cho | Giai đoạn thử nghiệm, trợ lý, nghiên cứu nhẹ | Giám sát SEO, theo dõi kết quả | Đại lý, hệ thống thông tin, AI sản xuất |
| Kiểm soát tính mới nhất | Giới hạn và phụ thuộc vào nhà cung cấp | Trung bình ở lớp tìm kiếm | Cao khi kết hợp với thu thập trực tiếp |
| Độ sâu bằng chứng | Thấp đến trung bình | Thấp đến trung bình | Cao |
| Phù hợp với quản trị | Giới hạn | Trung bình | Mạnh |
| Vai trò trong luồng dữ liệu AI | Bước đầu tiên | Bước đầu tiên với trọng tâm SERP | Mô hình hoạt động đa giai đoạn |
Khoảng cách cạnh tranh trong các bài viết hiện tại là hướng dẫn thực tế. Nhiều bài viết giải thích tại sao các công cụ tìm kiếm nhanh, hoặc tại sao chuỗi cung ứng tri thức nghe có chiến lược. Ít hơn giải thích nơi một kết thúc và cái kia bắt đầu bên trong cơ sở hạ tầng dữ liệu web thực tế. Ranh giới này xác định độ tin cậy của hệ thống.
Một sự khác biệt thứ hai là khả năng kiểm toán. Khi mô hình trả lời chỉ dựa trên đoạn trích, các nhóm thường không thể kiểm tra đường đi chuyển đổi nguồn. Khi chuỗi cung ứng tri thức lưu trữ nội dung trang, thời gian, nhật ký trích xuất và kiểm tra chất lượng, câu trả lời đó dễ xem xét và cải thiện hơn.
Một sự khác biệt thứ ba là chi phí thất bại. Nếu API khám phá trả về tóm tắt lỗi thời, ứng dụng chat thử nghiệm có thể vẫn cảm thấy chấp nhận được. Nếu cùng vấn đề ảnh hưởng đến thông tin giá cả hoặc giám sát chính sách, chi phí có thể cao hơn nhiều.
Trường hợp sử dụng trong đại lý AI và cơ sở hạ tầng dữ liệu
Sự phù hợp dễ thấy nhất qua các trường hợp sử dụng. API tìm kiếm hoạt động tốt khi hệ thống cần định hướng nhanh. Một đại lý có thể sử dụng lớp truy xuất này để tìm URL tiềm năng, các đề cập gần đây hoặc các cụm chủ đề trước khi bắt đầu truy xuất sâu hơn.
API SERP hoạt động tốt khi nhiệm vụ là hướng đến tìm kiếm. Các nhóm SEO sử dụng API SERP để theo dõi thứ hạng, phân tích kết quả trả phí và hữu cơ, và kiểm tra truy vấn khu vực. Đầu ra hữu ích, nhưng vẫn chỉ là một lớp bằng chứng.
Chuỗi cung ứng tri thức tốt hơn khi nhiệm vụ là vận hành. Theo dõi giá cả, thông tin khách hàng tiềm năng, theo dõi chính sách, tăng cường danh mục, nghiên cứu mua sắm và kiểm tra tin tức đều yêu cầu hơn kết quả được xếp hạng. Chúng cần trích xuất, thời gian, kiểm soát lược đồ và một luồng dữ liệu AI đáng tin cậy.
Đây cũng là nơi công cụ nội bộ quan trọng. Các nhóm xây dựng đại lý có thể kết hợp các khung đại lý AI, công cụ trích xuất dữ liệu tốt nhất và việc mở rộng thu thập dữ liệu cho huấn luyện mô hình ngôn ngữ lớn thành một bộ công cụ. Các thành phần này dễ đánh giá hơn khi bạn tách biệt khám phá, trích xuất và điều phối thay vì coi mọi đầu vào thượng nguồn là cùng một danh mục công cụ.
Hậu quả đối với công cụ quét web và kỹ thuật dữ liệu
Bài học lớn nhất là việc truy xuất riêng lẻ không tạo ra dữ liệu đáng tin cậy. Một API quét web quan trọng vì nó chuyển đổi liên kết thành bản ghi có thể sử dụng. Một lớp kỹ thuật dữ liệu quan trọng vì nội dung trang thô không nhất quán, ồn ào và thường bị trùng lặp.
Đó là lý do tại sao thiết kế thu thập tuân thủ rất quan trọng. Tôn trọng hướng dẫn robots, giới hạn tốc độ, chính sách truy cập và các hạn chế hợp đồng. Hướng dẫn crawler của Google làm rõ rằng quản lý lưu lượng và hành vi quét là một phần của môi trường hoạt động bình thường của web. Cơ sở hạ tầng dữ liệu web tốt nên giảm tải máy chủ, tài liệu quy tắc nguồn và bảo tồn các bản ghi kiểm toán.
Từ góc độ công cụ, bộ công cụ thường trông như sau. Một API khám phá hoặc API SERP xác định các mục tiêu. Một API quét web hoặc công cụ trình duyệt thu thập nội dung. Một luồng dữ liệu AI phân tích, bổ sung và lưu trữ bản ghi. Các công cụ đánh giá điểm số tính mới nhất và độ tin cậy nguồn. Sau đó, các khung đại lý hoặc hệ thống RAG sử dụng kết quả.
Tin cậy vận hành cũng đáng được ghi nhận thực tế. Một số luồng tự động được phê duyệt gặp các bước kiểm tra xác minh làm gián đoạn thu thập hoặc giám sát. Trong những trường hợp đó, các nhóm đôi khi thêm một dịch vụ hỗ trợ như "tại sao tự động hóa web liên tục thất bại vì CAPTCHA" hoặc "đại lý AI theo dõi giá cả" để giữ cho các quy trình được phê duyệt ổn định. Nếu đó là một phần của bộ công cụ của bạn, CapSolver liên quan vì nó cung cấp các mẫu API được tài liệu cho các tình huống này.
Cách an toàn nhất để thảo luận về CapSolver là giữ gần tài liệu chính thức của nó. Ví dụ dưới đây phản ánh định dạng yêu cầu createTask được tài liệu hóa từ hướng dẫn API của CapSolver và chỉ nên được sử dụng trong môi trường tự động hóa được phê duyệt.
json
POST https://api.capsolver.com/createTask
Host: api.capsolver.com
Content-Type: application/json
{
"clientKey": "YOUR_API_KEY",
"appId": "APP_ID",
"task": {
"type": "ImageToTextTask",
"body": "BASE64 image"
}
}Ví dụ này không phải là cốt lõi của chuỗi cung ứng tri thức. Đó là thành phần hỗ trợ độ tin cậy. Điểm chính vẫn như cũ. Khám phá, thu thập và quản trị nên được thiết kế cùng nhau.
Nhận mã ưu đãi CapSolver của bạn
Tăng ngân sách tự động hóa của bạn ngay lập tức!
Sử dụng mã ưu đãi CAP26 khi nạp tiền vào tài khoản CapSolver để nhận thêm 5% ưu đãi cho mỗi lần nạp tiền — không giới hạn.
Nhận mã ưu đãi ngay bây giờ trong Bảng điều khiển CapSolver
Kết luận
Kết luận thực tế rất đơn giản. Một API tìm kiếm giúp hệ thống tìm thông tin, nhưng chuỗi cung ứng tri thức giúp hệ thống tin tưởng, tái sử dụng và vận hành nó. Nếu khối lượng công việc của bạn là khám phá, lớp truy xuất này có thể đủ. Nếu khối lượng công việc của bạn ảnh hưởng đến sản phẩm, doanh thu hoặc tuân thủ, bạn cần cơ sở hạ tầng dữ liệu web rộng hơn với trích xuất, kiểm tra và lưu trữ được tích hợp sẵn.
Đối với hầu hết các nhóm, thiết kế chiến thắng là kết hợp. Sử dụng API khám phá hoặc API SERP để khám phá. Sử dụng API quét web để thu thập nội dung. Sau đó kết nối cả hai vào một luồng dữ liệu AI với chính sách nguồn rõ ràng, giám sát và đánh giá. Đó là con đường bền vững nhất cho việc thu thập dữ liệu cho AI.
Nếu bạn đang lên kế hoạch bước tiếp theo, kiểm tra bộ công cụ hiện tại của bạn theo từng lớp. Hỏi nơi khám phá kết thúc, nơi bằng chứng bắt đầu và nơi quản trị được ghi lại. Bài tập này thường tiết lộ xem bạn có cần giao diện nhanh hơn, luồng sâu hơn hoặc cả hai không.
Câu hỏi thường gặp
API tìm kiếm có giống với API SERP không?
Không. API tìm kiếm là giao diện truy xuất rộng, trong khi API SERP tập trung vào các trang kết quả tìm kiếm và các yếu tố kết quả liên quan.
Khi nào loại giao diện truy xuất này đủ cho các ứng dụng AI?
Nó thường đủ cho các bản mô phỏng, trợ lý nội bộ, các nhiệm vụ nghiên cứu rủi ro thấp và các bước khám phá ban đầu trong luồng.
Điều gì khiến chuỗi cung ứng tri thức tốt hơn cho AI sản xuất?
Chuỗi cung ứng tri thức thêm trích xuất, chuẩn hóa, kiểm tra, lưu trữ và điều phối. Những lớp này cải thiện tính mới nhất, khả năng kiểm toán và khả năng tái sử dụng.
API quét web phù hợp ở đâu trong mô hình này?
API quét web nằm sau khám phá. Nó chuyển đổi URL và trang nguồn thành nội dung được cấu trúc mà luồng dữ liệu AI có thể xử lý.
Tại sao lại đề cập đến CapSolver trong bài viết về cơ sở hạ tầng dữ liệu AI?
Vì một số luồng tự động được phê duyệt gặp các bước kiểm tra xác minh sau khi khám phá. Trong bối cảnh hẹp đó, CapSolver có thể hỗ trợ liên tục vận hành như một thành phần bên trong hệ thống rộng hơn, có nhận thức về chính sách.