Nâng cao Tự động hóa Doanh nghiệp: Cơ sở hạ tầng Dựa trên Mô hình Ngôn ngữ Lớn (LLM) cho Nhận dạng CAPTCHA Mượt mà & Hiệu quả Hoạt động

Anh Tuan
Data Science Expert

Trong bối cảnh chuyển đổi số đang phát triển nhanh chóng, CAPTCHA đã chuyển từ các kiểm tra bảo mật cơ bản thành các bộ lọc quy trình kinh doanh phức tạp. Mặc dù cần thiết cho bảo mật, chúng thường tạo ra sự cản trở đáng kể, gây ra "khoảng trống hiệu suất" trong các quy trình tự động hóa. Trên toàn cầu, các doanh nghiệp cùng nhau chi khoảng 500.000 giờ mỗi ngày cho việc giải CAPTCHA thủ công, làm gián đoạn việc thực hiện liền mạch các hoạt động kinh doanh quan trọng.
Việc can thiệp thủ công này dẫn đến một số thách thức:
- Chi phí vận hành cao: Việc phụ thuộc vào nhân viên con người để giải CAPTCHA không thể mở rộng hiệu quả khi khối lượng kinh doanh tăng lên.
- Ngắt quãng quy trình: Các đoạn mã tự động thường dừng lại khi gặp CAPTCHA, làm gián đoạn liên tục của các quy trình kinh doanh.
- Áp lực về quyền riêng tư và kỹ thuật: Các tiêu chuẩn quyền riêng tư đang thay đổi gây khó khăn cho các phương pháp xác minh dựa trên hành vi truyền thống, đòi hỏi các giải pháp minh bạch và hiệu quả hơn.
Tầm nhìn của chúng tôi: Chúng tôi tin rằng CAPTCHA nên hỗ trợ, không phải cản trở, sự phát triển của doanh nghiệp. Bằng cách cung cấp một Cơ sở hạ tầng Tự động hóa AI tiên tiến cho Nhận dạng CAPTCHA tự động, chúng tôi cam kết giúp các doanh nghiệp giảm đáng kể can thiệp thủ công, tối ưu chi phí vận hành và nâng cao hiệu quả hệ sinh thái của các quy trình kinh doanh cốt lõi.
📈 I. Sự phát triển của xác minh: Từ quy tắc tĩnh đến sự kết hợp thông minh
Hành trình của công nghệ xác minh trong 25 năm qua phản ánh một nỗ lực liên tục để cân bằng giữa bảo mật và trải nghiệm người dùng. Sự ra đời của các Mô hình Ngôn ngữ lớn (LLM) đánh dấu một bước chuyển quan trọng, mở ra một kỷ nguyên mới về xử lý thông minh và kết hợp.
| Giai đoạn | Công nghệ cốt lõi | Logic xử lý | Tác động kinh doanh |
|---|---|---|---|
| V1 (thế kỷ 2000s) | Ký tự bị biến dạng | Nhận dạng OCR cơ bản | Dễ bị tự động hóa cơ bản, hiệu suất ban đầu cao |
| V2 (thế kỷ 2010s) | Chọn hình ảnh | Phát hiện và phân loại đối tượng | Yêu cầu gán nhãn thủ công nhiều, chi phí vận hành tăng |
| V3 (thế kỷ 2020s) | Phân tích hành vi | Đánh giá rủi ro và định danh thiết bị | Gặp lo ngại về quyền riêng tư, khó khăn cho tự động hóa hiệu quả |
| V4 (2026+) | Tổng hợp LLM | Hiểu ngữ nghĩa và tạo ra | Độ tin cậy cao, Hiệu suất được cải thiện, Tự động hóa toàn diện |
Nhận định chính: Khi CAPTCHA tiến tới hướng ngữ nghĩa và đa phương tiện, các giải pháp dựa trên quy tắc truyền thống đang trở nên không đủ. Các doanh nghiệp cần một cơ sở hạ tầng thông minh với khả năng hiểu ngữ nghĩa tiên tiến để đáp ứng nhu cầu tự động hóa của họ. Đây chính là lúc LLM cho CAPTCHA trở nên không thể thiếu.
🧠 II. Nâng cấp LLM: Khả năng cốt lõi của cơ sở hạ tầng tự động hóa
Việc tích hợp các mô hình lớn vào hệ sinh thái xử lý xác minh biến chúng thành động cơ thông minh thúc đẩy hiệu quả quy trình kinh doanh.
Trong xu hướng này, một số nền tảng cơ sở hạ tầng tự động hóa hướng doanh nghiệp đã bắt đầu phát triển khả năng LLM. Ví dụ, CapSolver cung cấp dịch vụ xử lý CAPTCHA tự động ổn định bằng cách tích hợp nhận dạng đa phương tiện với khả năng suy luận mô hình lớn, giúp doanh nghiệp cải thiện tính liên tục và hiệu quả thực thi quy trình kinh doanh mà không làm tăng can thiệp thủ công.
Giá trị cốt lõi của các giải pháp này không nằm ở các khả năng điểm lẻ, mà ở việc phục vụ như cơ sở hạ tầng nền tảng giúp doanh nghiệp duy trì khả năng tự động hóa ổn định và kiểm soát chi phí trong môi trường xác minh đang thay đổi.
2.1 Khả năng cốt lõi 1: Động cơ ra quyết định rủi ro thông minh
Tự động hóa truyền thống thường dựa trên các quy tắc if-else cứng nhắc để xử lý CAPTCHA, dẫn đến các hệ thống phân mảnh, khó bảo trì và dễ bị lách. Cơ sở hạ tầng được hỗ trợ bởi LLM hoạt động như một động cơ ra quyết định rủi ro thông minh, tích hợp nhiều tín hiệu để xử lý thống nhất, thích ứng và dễ giải thích.
Cách tiếp cận truyền thống (dựa trên quy tắc):
python
# Cách truyền thống
if rủi ro_ip > 0.8 và thiết bị_mới == True:
loại_captcha = "khó"
elif điểm_rủi ro_hành vi < 0.5:
loại_captcha = "trung bình"
else:
loại_captcha = "không có"Cách tiếp cận dựa trên LLM (ra quyết định dựa trên ngữ cảnh):
python
# Cách LLM
bối cảnh = {
"đánh giá_rủi ro_ip": "trung bình",
"định danh_thiết bị": "thiết bị_mới",
"điểm_rủi ro_hành vi": 0.65,
"tần suất_yêu cầu": "cao",
"vị trí_địa lý": "khác thường",
"mẫu_historic": "phát hiện_bất thường"
}
# Đầu ra LLM: {"mức_rủi ro": "cao", "loại_captcha": "hình ảnh_ngữ nghĩa",
# "độ_khó": 0.8, "lý do": "Định danh thiết bị xung đột với vị trí địa lý thiết bị mới"}Giá trị mang lại:
- ✅ Giảm tỷ lệ phát hiện sai (trên 20%): Giảm gián đoạn cho người dùng hợp lệ, cải thiện trải nghiệm người dùng.
- ✅ Quyết định dễ giải thích: Cung cấp thông tin kiểm tra cho các hoạt động bảo mật và tối ưu hóa liên tục.
- Khả năng thích ứng động: Tự động điều chỉnh với các thách thức xác minh và nhu cầu kinh doanh đang thay đổi.
2.2 Khả năng cốt lõi 2: Động cơ xác minh sinh tạo
CAPTCHA truyền thống dựa trên ngân hàng câu hỏi hạn chế, dễ bị đào tạo ngoại tuyến và bẻ khóa bởi tự động hóa phức tạp. Sử dụng AI sinh tạo, bao gồm các mô hình Diffusion, tạo ra các thách thức xác minh độc đáo và động. Mỗi phiên bản là một sáng tạo mới, làm tăng đáng kể chi phí và độ phức tạp cho bất kỳ nỗ lực nào nhằm vượt qua xác minh trước.
mermaid
graph TD
A[CAPTCHA truyền thống] --> B{Ngân hàng câu hỏi hạn chế}
B --> C[Dễ bị đào tạo ngoại tuyến/bẻ khóa]
D[Động cơ xác minh sinh tạo] --> E{LLM + Mô hình Diffusion}
E --> F[Phiên bản CAPTCHA vô hạn, độc đáo]
F --> G[Chi phí quá cao cho tự động hóa không được phép]Nguyên tắc cốt lõi: Đảm bảo chi phí tổng quát hóa cho tự động hóa không được phép vượt quá lợi nhuận tiềm năng từ việc vượt qua xác minh.
2.3 Khả năng cốt lõi 3: Phân tích chuỗi hành vi sâu
Mặc dù phân tích hành vi truyền thống có thể phát hiện các mẫu đơn giản (ví dụ: chuyển động chuột thẳng được coi là tự động), LLM có thể thực hiện phân tích chuỗi hành vi sâu. Bằng cách vector hóa các chuỗi thao tác người dùng và xử lý chúng qua các mô hình Transformer, hệ thống có thể phân biệt các chi tiết tinh tế mang tính người với các đoạn mã tự động quá hoàn hảo.
Luồng phân tích chuỗi hành vi:
mermaid
graph LR
A[Chuỗi thao tác người dùng] --> B[Vector hóa nhúng]
B --> C[Đ mã hóa Transformer]
C --> D[Đánh giá rủi ro]
subgraph Các hành động người dùng
E[Chuyển động chuột]
F[Vị trí nhấp]
G[Thời gian dừng]
H[Cuộn trang]
I[Rhythm bàn phím]
end
E --> A
F --> A
G --> A
H --> A
I --> A
D --> J{Quyết định LLM: "Người dùng thật do dự" so với "Đoạn mã tự động hoàn hảo"}Điều này cho phép hệ thống phân biệt giữa "người dùng thật do dự" và "đoạn mã tự động hoàn hảo", dựa trên "sai sót của con người" trong tương tác thực tế.
🗺️ III. Ưu thế chiến lược: Tối ưu chi phí tự động hóa với LLM
Bản chất của tự động hóa hiệu quả không phải là ngăn chặn tuyệt đối, mà là khiến việc vượt qua xác minh không được phép trở nên không kinh tế. LLM gia tăng khoảng cách chi phí này, khiến tự động hóa hợp pháp hiệu quả hơn và tự động hóa không được phép trở nên quá đắt đỏ.
So sánh chi phí: Tự động hóa không được phép vs. Cơ sở hạ tầng thông minh
| Yếu tố chi phí | Tự động hóa không được phép | Cơ sở hạ tầng thông minh |
|---|---|---|
| Thu thập dữ liệu | Cao (để đào tạo) | Thấp (thu thập dữ liệu hành vi) |
| Đào tạo mô hình | Cao (đào tạo lặp lại) | Trung bình (triển khai mô hình sinh tạo) |
| Tạo mẫu đối kháng | Cao | Không có |
| Thời gian hiệu quả | Thấp (CAPTCHA trở nên lỗi thời) | Cao (cập nhật chiến lược động) |
| Rủi ro phát hiện | Cao | Thấp |
| Xử lý phát hiện sai | Không có | Trung bình (xử lý khiếu nại) |
Kết luận: Chi phí vận hành cho tự động hóa không được phép cao hơn nhiều so với chi phí bền vững để duy trì cơ sở hạ tầng được hỗ trợ bởi LLM, đảm bảo tự động hóa lâu dài và mạnh mẽ.
Cách LLM tối ưu chi phí:
- Tăng chi phí tổng quát hóa: CAPTCHA sinh tạo tạo ra không gian hình ảnh vô hạn, ngăn chặn các mô hình đã được đào tạo trước.
- Tăng chi phí suy luận: CAPTCHA ngữ nghĩa yêu cầu suy luận nhiều bước, tiêu tốn nhiều tài nguyên tính toán cho các nỗ lực không được phép.
- Giảm thời gian sống: Thời gian hiệu lực CAPTCHA ngắn hơn khiến các giải pháp bẻ khóa trở nên lỗi thời trước khi có thể được triển khai rộng rãi.
- Ô nhiễm dữ liệu: Xáo trộn lưu lượng truy cập thực tế với dữ liệu bẫy mật làm ô nhiễm tập dữ liệu đào tạo cho tự động hóa không được phép.
🚀 IV. Triển vọng tương lai: Xây dựng hệ sinh thái tự động hóa liền mạch, dựa trên niềm tin
Chúng tôi hình dung một tương lai mà xác minh là một quá trình vô hình, liên tục, được tích hợp liền mạch vào trải nghiệm người dùng.
4.1 Giai đoạn 1: LLM như "trợ lý hiệu suất" (Hiện tại - Gần tương lai)
Trong giai đoạn đầu tiên này, LLM đóng vai trò là trợ lý thông minh, nâng cao hiệu suất hoạt động bảo mật thay vì đưa ra quyết định quan trọng trực tiếp. Chúng xử lý logic xác minh phức tạp, giảm đáng kể tần suất can thiệp thủ công và cung cấp thông tin hành động cho các chuyên gia con người.
mermaid
graph TD
A[Yêu cầu người dùng] --> B{Hệ thống xác minh truyền thống}
B --> C{Gặp CAPTCHA}
C --> D[Trợ lý LLM: Phân tích CAPTCHA và ngữ cảnh]
D --> E{Chuyên gia bảo mật con người: Xem xét và ra quyết định}
E --> F[Kết quả xác minh]
D -- "Đề xuất giải pháp" --> E
E -- "Cung cấp phản hồi" --> DNguyên tắc chính: LLM đóng vai trò trợ lý, bổ trợ cho chuyên môn con người để cải thiện hiệu suất vận hành.
4.2 Giai đoạn 2: Xác minh sinh tạo động (Gần tương lai - Trung hạn)
Giai đoạn này kết hợp LLM với các mô hình sinh tạo (như mô hình Diffusion) để tạo ra CAPTCHA không thể đào tạo trước. Mỗi phiên bản xác minh là duy nhất, đảm bảo rằng việc vượt qua một phiên bản không mang lại lợi thế cho các lần sau. Xác minh chuyển từ mô hình "trích xuất ngân hàng câu hỏi" sang "tạo ra theo thời gian thực".
mermaid
graph TD
A[Người dùng truy cập] --> B[LLM: Hiểu ngữ cảnh trang]
B --> C["AI sinh tạo (Diffusion): Tạo CAPTCHA ngữ nghĩa"]
C --> D[Người dùng: Giải CAPTCHA duy nhất]
D --> E[Kết quả xác minh thành công/thất bại]
subgraph Ví dụ CAPTCHA
F["Bài viết này đề cập đến 3 thành phố, vui lòng đánh dấu vị trí của chúng trên bản đồ."]
end
C --> FVí dụ về CAPTCHA tương lai:
Người dùng truy cập trang → LLM hiểu nội dung trang → Tạo câu hỏi xác minh mang tính ngữ nghĩa.
- "Bài viết này đề cập đến 3 thành phố; vui lòng đánh dấu vị trí của chúng trên bản đồ."
Điều này yêu cầu hiểu nội dung bài viết, kiến thức địa lý và tương tác hình ảnh, khiến việc vượt qua tự động trở nên cực kỳ tốn kém, trong khi vẫn dễ dàng cho người dùng thực tế.
4.3 Giai đoạn 3: Động cơ tin cậy liên tục (Trung hạn - Tương lai xa)
Mục tiêu cuối cùng là "biến mất" của các CAPTCHA rõ ràng, thay thế bằng một đánh giá tin cậy liên tục, nền tảng. Người dùng không còn nhận thấy bước xác minh, vì hệ thống liên tục đánh giá tin cậy dựa trên tín hiệu hành vi thời gian thực.
mermaid
graph TD
A[Người dùng mở ứng dụng] --> B[Phía sau: Thu thập tín hiệu hành vi]
B --> C[LLM: Tính toán điểm tin cậy thời gian thực]
C --> D{Điểm tin cậy > ngưỡng?}
D -- Có --> E[Hoạt động liền mạch]
D -- Không (giảm chức năng âm thầm) --> F[Chức năng bị giới hạn]
D -- Không (xác minh rõ ràng) --> G[Kích hoạt CAPTCHA/Can thiệp]Trải nghiệm xác minh giả định năm 2030:
Người dùng mở ứng dụng → Phía sau liên tục thu thập tín hiệu hành vi → LLM tính toán điểm tin cậy thời gian thực.
- Điểm tin cậy > ngưỡng: Tất cả các hoạt động diễn ra liền mạch.
- Điểm tin cậy < ngưỡng: Một số chức năng bị giảm âm thầm.
- Điểm tin cậy << ngưỡng: Kích hoạt xác minh rõ ràng hoặc can thiệp.
Người dùng sẽ không bao giờ cần nhấp vào "Tôi không phải là robot", đạt được trải nghiệm liền mạch và hiệu quả thực sự.
4.4 Vượt ra ngoài: Khám phá tương lai của xác minh AI-native
Chúng tôi cũng đang khám phá các khái niệm tiên tiến, như "CAPTCHA đặc thù AI" – được thiết kế để phân biệt giữa AI hỗ trợ con người (ví dụ: người dùng sử dụng trợ lý AI) và các đoạn mã tự động thuần túy. Khi các trợ lý AI trở nên phổ biến, sự phân biệt này sẽ trở nên thiết yếu để duy trì tương tác số công bằng và an toàn.
⚠️ V. Đạo đức và triển khai AI có trách nhiệm
Mặc dù LLM mang lại cơ hội chưa từng có về hiệu suất, chúng tôi nhấn mạnh cách tiếp cận có trách nhiệm trong triển khai AI, ưu tiên minh bạch và các yếu tố đạo đức:
mermaid
graph TD
A[Tự động hóa dựa trên LLM] --> B{Minh bạch trước tiên}
A --> C{Kiểm soát chi phí}
A --> D["Lưới an toàn: Cơ chế con người trong vòng lặp"]
B --> B1["Bảo vệ quyền riêng tư dữ liệu"]
B --> B2[Giảm thiểu thiên lệch]
B --> B3[Phân tích minh bạch]
C --> C1[Tối ưu hóa suy luận mô hình]
C --> C2[ROI cao so với xử lý thủ công]
D --> D1[Giám sát con người]
D --> D2[Đánh giá thủ công cho các tình huống phức tạp]Yếu tố quan trọng:
- Quyền riêng tư dữ liệu: Đảm bảo mọi thu thập và xử lý dữ liệu tuân thủ các tiêu chuẩn bảo vệ quyền riêng tư toàn cầu.
- Giảm thiểu thiên lệch: Liên tục giám sát và giảm thiểu thiên lệch tiềm ẩn trong ra quyết định dựa trên LLM để đảm bảo công bằng.
- Minh bạch và dễ giải thích: Cung cấp cái nhìn rõ ràng về cách LLM đưa ra quyết định xác minh, đặc biệt là trong các trường hợp gây khó chịu cho người dùng.
- Cơ chế con người trong vòng lặp: Duy trì các cơ chế giám sát và can thiệp của con người trong các tình huống phức tạp hoặc mơ hồ.
Nguyên tắc cốt lõi: Quyết định dựa trên AI là chính, với các phương án dự phòng dựa trên quy tắc và hợp tác giữa con người và AI đảm bảo hoạt động mạnh mẽ và có đạo đức.
💡 VI. Chiến lược hành động cho doanh nghiệp: Chấp nhận tự động hóa thông minh
Để tận dụng sức mạnh của tự động hóa dựa trên LLM, doanh nghiệp có thể áp dụng các chiến lược sau:
- 📊 Đánh giá hiện trạng: Đánh giá hệ thống xác minh hiện tại về độ dễ bị tổn thương trước các mô hình OCR/mô hình phát hiện mã nguồn mở và phân tích các chỉ số quan trọng như tỷ lệ phát hiện sai, tỷ lệ khiếu nại của người dùng và tỷ lệ thành công của tự động hóa.
- 🧪 Thử nghiệm và cải tiến: Bắt đầu với các tuyến kinh doanh ít rủi ro để thử nghiệm các giải pháp "xác minh liền mạch" hoặc "khó khăn động". Thiết lập khung A/B để đo lường tác động của chiến lược mới.
- 📚 Đi trước xu hướng: Giám sát các tiến bộ trong AI sinh tạo (ví dụ: mô hình Diffusion) và các LLM đa phương tiện cho ứng dụng trong xác minh và tự động hóa. Tham gia các hội nghị an ninh ngành (ví dụ: BlackHat, DEF CON, RSA) để cập nhật thông tin.
- 🗄️ Tiếp cận lấy dữ liệu làm trung tâm: Bắt đầu xây dựng các tập dữ liệu chất lượng cao ghi lại "sự khác biệt trong hành vi giữa con người và máy móc." Khám phá học liên minh để trí tuệ dữ liệu hợp tác trong khi bảo vệ quyền riêng tư.
- 👥 Hợp tác đa chức năng: Khuyến khích các nhóm bao gồm kỹ sư AI, nhà nghiên cứu an ninh, quản lý sản phẩm và chuyên gia. Thực hiện các bài kiểm tra red-teaming nội bộ định kỳ và thiết lập cơ chế chia sẻ kiến thức.
🎯 Kết luận: Tương lai của xác minh là hiệu quả liền mạch
Lịch sử 25 năm của CAPTCHA cho thấy một vòng lặp: Tạo AI → CAPTCHA để phòng thủ AI → AI vượt qua CAPTCHA → CAPTCHA được nâng cấp, gây khó khăn cho con người → Con người huấn luyện AI miễn phí → AI trở nên mạnh mẽ hơn... Sự xuất hiện của các mô hình ngôn ngữ lớn (LLMs), tuy nhiên, mang lại một sự chuyển dịch mô hình.
Với cơ sở hạ tầng tự động hóa AI thông minh, xác minh vượt qua trở thành một rào cản đơn thuần. Nó biến thành một "màng bảo vệ niềm tin" bao bọc liền mạch các hoạt động kinh doanh, nhận diện rủi ro một cách im lặng, điều chỉnh cường độ một cách động và tạo ra sự cân bằng tối ưu giữa bảo mật và trải nghiệm người dùng.
Dạng xác minh cuối cùng là "Hiệu quả liền mạch." Đó không phải là sự biến mất của nhu cầu bảo mật, mà là tích hợp vô hình của xác minh. Mục tiêu của chúng tôi là đảm bảo rằng 90% người dùng hợp lệ sẽ không bao giờ nhận thấy bước xác minh, trong khi 100% tự động hóa không được phép phải đối mặt với chi phí không kinh tế.
Là nhà cung cấp hàng đầu toàn cầu về giải pháp nhận diện CAPTCHA tự động, chúng tôi cam kết đổi mới để loại bỏ sự cản trở trong quy trình kinh doanh. Chúng tôi hướng đến việc xây dựng hệ sinh thái tự động hóa thông minh và hiệu quả hơn, giúp doanh nghiệp tập trung vào tăng trưởng cốt lõi, không bị gánh nặng bởi các thách thức xác minh.
Bắt đầu xây dựng hệ thống tự động hóa hiệu quả hơn
Nếu bạn đang tìm cách đạt được quy trình tự động hóa ổn định và hiệu quả hơn trong môi trường xác minh phức tạp, một cơ sở hạ tầng tự động hóa AI đáng tin cậy sẽ là chìa khóa.
👉 Thông qua CapSolver, bạn có thể:
- Đạt được nhận diện và xử lý tự động các loại CAPTCHA phổ biến
- Giảm chi phí can thiệp thủ công và cải thiện tính liên tục của quy trình
- Duy trì tỷ lệ thành công ổn định trong môi trường xác minh động
- Tích hợp nhanh chóng với các hệ thống kinh doanh hiện có
Dù là thu thập dữ liệu, tự động hóa tăng trưởng hay tối ưu hóa quy trình kinh doanh phức tạp, CapSolver có thể là năng lực nền tảng giúp bạn xây dựng hệ thống tự động hóa hiệu quả hơn.
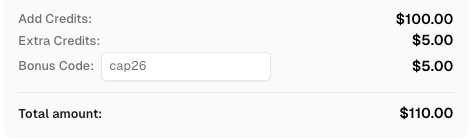
🎁 Ưu đãi đặc biệt
Sử dụng mã
CAP26khi đăng ký tại CapSolver để nhận thêm tín dụng!
Xem thêm
AIMar 27, 2026
Mở rộng thu thập dữ liệu cho huấn luyện LLM: Giải quyết CAPTCHAs ở quy mô lớn
Hãy học cách mở rộng thu thập dữ liệu cho việc huấn luyện mô hình LLM bằng cách giải CAPTCHAs quy mô lớn. Khám phá các chiến lược tự động để xây dựng các bộ dữ liệu chất lượng cao cho các mô hình AI.

AIMar 24, 2026
Làm thế nào để giải CAPTCHA trong OpenBrowser bằng cách sử dụng CapSolver (Hướng dẫn tự động hóa AI Agent)
Giải CAPTCHA trong OpenBrowser bằng CapSolver. Tự động hóa reCAPTCHA, Turnstile và hơn thế nữa cho các tác nhân AI một cách dễ dàng.
