Web Scraping no Linux: Ferramentas, Configuração & Guia Prático

Adélia Cruz
Neural Network Developer
TL;DR
- Linux é a plataforma dominante para raspagem de dados em produção devido à sua estabilidade, agendamento com cron e baixo custo de recursos.
- Ferramentas Python para raspagem — Requests, BeautifulSoup, Scrapy e Playwright — atendem a diferentes casos de uso.
- Rotação de proxies é essencial para extração de dados em larga escala para evitar limitação de IP.
- Desafios de CAPTCHA são um bloqueio comum em pipelines automatizados; a API da CapSolver resolve-os de forma programática em 1–5 segundos.
- Uma pipeline completa de extração de dados no Linux combina agendamento (cron), armazenamento (SQLite/PostgreSQL), gerenciamento de proxy e tratamento de CAPTCHA.
- Sempre raspagem de forma responsável: respeite
robots.txt, limite as requisições e cumpra as leis de proteção de dados aplicáveis.
Introdução
Linux é a plataforma escolhida por desenvolvedores que executam raspagem de dados em larga escala. Sua agendamento nativo com cron, baixo consumo de recursos e ecossistema Python maduro tornam-no muito mais prático do que Windows ou macOS para pipelines de extração de dados automatizados e de longa duração. Este guia percorre a configuração do ambiente, seleção de ferramentas, configuração de proxy, tratamento de CAPTCHA e arquitetura de pipeline — uma referência prática para desenvolvedores construindo raspagem de dados no Linux em 2025.
Por que o Linux é a plataforma preferida para raspagem de dados
Linux impulsiona mais de 80% dos servidores da web no mundo, segundo as estatísticas da W3Techs sobre sistemas operacionais de servidores. Essa dominância não é acidental — o Linux oferece um conjunto de capacidades nativas que o tornam o ambiente mais prático para raspagem de dados no Linux em qualquer escala.
Principais vantagens para cargas de trabalho de raspagem:
- Agendamento com cron — automatize scripts de raspagem em qualquer intervalo sem ferramentas de terceiros.
- Baixo consumo de memória — execute navegadores headless e múltiplos trabalhadores simultaneamente em hardware modesto.
- Gerenciamento de pacotes —
apt,pipecondamantêm a gestão de dependências limpa e reprodutível. - Acesso SSH — gerencie servidores de raspagem remotos sem interface gráfica.
- Estabilidade — tarefas de longa duração são muito menos propensas a serem interrompidas por eventos do sistema operacional.
- Ferramentas CLI nativas —
wget,curl,grep,sedeawklidam com tarefas leves de raspagem diretamente do terminal, conforme documentado pelo guia de raspagem de dados da Linux.com.
A maioria dos provedores de VPS em nuvem — AWS EC2, DigitalOcean, Linode — padrão para Ubuntu ou Debian, tornando o Linux o alvo natural para qualquer pipeline de extração de dados sério.
Configurando o Ambiente de Raspagem no Linux
Antes de escrever uma linha de código de raspagem, configure um ambiente limpo e isolado.
Passo 1 — Instalar Python e pip
A maioria das distribuições modernas do Linux vem com Python 3. Verifique sua versão:
bash
python3 --version
pip3 --versionSe o pip estiver faltando:
bash
sudo apt update && sudo apt install python3-pip -yPasso 2 — Criar um Ambiente Virtual
Isolar dependências evita conflitos de versão entre projetos:
bash
python3 -m venv scraper-env
source scraper-env/bin/activatePasso 3 — Instalar Bibliotecas de Raspagem Principais
bash
pip install requests beautifulsoup4 scrapy playwright lxml
playwright install chromiumPasso 4 — Instalar Ferramentas Complementares
bash
pip install pandas sqlalchemy psycopg2-binary fake-useragentEste conjunto básico cobre raspagem de páginas estáticas, renderização de JavaScript e armazenamento de dados — os três pilares de qualquer fluxo de trabalho de raspagem de dados no Linux.
Ferramentas de Raspagem Python: Escolhendo a Certa
A escolha da ferramenta certa depende da complexidade do site alvo e das exigências de throughput. A tabela abaixo resume as principais ferramentas de raspagem Python usadas em ambientes Linux.
Resumo da Comparação
| Ferramenta | Melhor Para | Renderização de JS | Velocidade | Curva de Aprendizado |
|---|---|---|---|---|
| Requests | Requisições HTTP simples, páginas estáticas | ✗ | Rápido | Baixo |
| BeautifulSoup | Análise de HTML/XML (emparelhado com Requests) | ✗ | Rápido | Baixo |
| Scrapy | Crawlings em larga escala, recorrentes | ✗ (via plugin) | Muito Rápido | Médio |
| Playwright | Páginas dinâmicas, com muito JS | ✓ | Médio | Médio |
| Selenium | Automação legada, páginas com JS | ✓ | Lento | Médio |
Requests + BeautifulSoup é o ponto de entrada padrão para raspagem de dados no Linux. Ele lida com a maioria das páginas estáticas com configuração mínima e é o caminho mais rápido de zero a um raspador funcional.
Scrapy é a escolha certa para pipelines de extração de dados de produção. Ele lida com cookies, sessões, compressão, autenticação, cache e robots.txt de forma nativa, e sua arquitetura de middleware suporta rotação de proxy personalizada e tratamento de CAPTCHA. Scrapy é um dos frameworks de raspagem Python mais adotados, com mais de 52.000 estrelas no GitHub em 2025 (Scrapy no GitHub). Para uma visão mais ampla de como essas ferramentas se comparam em cenários do mundo real, consulte ferramentas de raspagem explicadas.
Playwright é a substituição moderna do Selenium quando a renderização de JavaScript é necessária. Ele executa o Chromium headless nativamente no Linux, suporta execução assíncrona e é significativamente mais rápido para conteúdo dinâmico. Para uma comparação detalhada dos métodos de automação de navegadores, nodriver vs ferramentas tradicionais de automação de navegadores aborda as trade-offs em profundidade.
Uso de Proxies na Raspagem de Dados no Linux
A rotação de proxies é essencial para qualquer configuração de raspagem de dados no Linux séria. Sem ela, o IP do seu raspador será limitado ou bloqueado após um número relativamente pequeno de requisições. Proxies residenciais estáticos — endereços IP atribuídos por provedores de internet — são particularmente eficazes porque simulam comportamento de usuário real, reduzindo a probabilidade de detecção, conforme notado pelo guia da Linux Security sobre práticas de raspagem ética.
Tipos de Proxies
| Tipo | Risco de Detecção | Custo | Melhor Para |
|---|---|---|---|
| Datacenter | Alto | Baixo | Alvos sensíveis à velocidade, com proteção mínima |
| Residencial | Baixo | Médio | Sites com detecção de bots moderada |
| Residencial em Rotação | Muito Baixo | Mais Alto | Pipelines de alta volume, contínuos |
Configurando Proxies no Python Requests
python
import requests
proxies = {
"http": "http://username:password@proxy-host:port",
"https": "http://username:password@proxy-host:port",
}
response = requests.get("https://example.com", proxies=proxies)
print(response.status_code)Configurando Proxies no Scrapy
Em settings.py:
python
ROTATING_PROXY_LIST = [
"http://proxy1:port",
"http://proxy2:port",
]Use o middleware scrapy-rotating-proxies para gerenciamento automático do pool.
Boas Práticas
- Roteie strings de user-agent junto com a rotação de IP usando
fake-useragent. - Adicione atrasos aleatórios entre requisições:
time.sleep(random.uniform(1, 3)). - Monitore a saúde do proxy e remova IPs defeituosos do seu pool automaticamente.
- Use proxies HTTPS para sites que exigem inspeção TLS.
Para uma lista curada de provedores de proxy que funcionam bem com raspagem de dados no Linux, melhores serviços de proxy para raspagem de dados é um bom ponto de partida.
Tratamento de CAPTCHA em Seu Pipeline de Extração de Dados
Desafios de CAPTCHA são o bloqueio mais comum em raspagem de dados em produção no Linux. Sites implementam reCAPTCHA v2/v3, hCaptcha, Cloudflare Turnstile e outros desafios especificamente para interromper pipelines de extração automatizados. O reCAPTCHA v2 é usado por mais de 5 milhões de sites globalmente, segundo o guia de integração do reCAPTCHA v2 da CapSolver.
Resolver CAPTCHAS manualmente não é escalável. A solução prática é integrar uma API de resolução de CAPTCHA programática diretamente no seu fluxo de raspagem. CapSolver é um serviço impulsionado por IA que resolve reCAPTCHA, hCaptcha, Cloudflare Turnstile, GeeTest, AWS WAF e outros tipos de desafio via API REST, normalmente retornando um token válido em 1–5 segundos — sem intervenção humana.
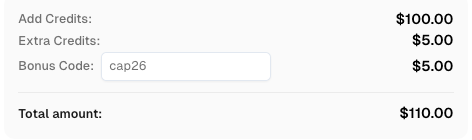
Resgate seu Código de Bônus da CapSolver
Aumente seu orçamento de automação instantaneamente!
Use o código de bônus CAP26 ao recarregar sua conta na CapSolver para obter um bônus extra de 5% em cada recarga — sem limites.
Resgate-o agora em seu Painel da CapSolver
Como a CapSolver Funciona
- Seu raspador detecta um CAPTCHA na página alvo.
- Você envia a URL do site e a chave do site para o endpoint
createTaskda CapSolver. - O modelo de IA da CapSolver resolve o desafio e retorna um token.
- Você injeta o token no campo de submissão do formulário ou no cabeçalho da requisição.
- O raspador continua sem interrupção.
Exemplo de Integração com Python (reCAPTCHA v2 — Sem Proxy)
O exemplo a seguir é baseado na documentação oficial da API da CapSolver:
python
import requests
import time
# Sua chave de API da CapSolver
API_KEY = "SUA_CHAVE_DE_API_DA_CAPSOLVER"
WEBSITE_URL = "https://example.com"
WEBSITE_KEY = "SUA_CHAVE_DE_SITE_DO_RECAPTCHA"
def create_task():
payload = {
"clientKey": API_KEY,
"task": {
"type": "ReCaptchaV2TaskProxyLess",
"websiteURL": WEBSITE_URL,
"websiteKey": WEBSITE_KEY,
}
}
response = requests.post(
"https://api.capsolver.com/createTask",
json=payload
)
return response.json().get("taskId")
def get_task_result(task_id):
payload = {
"clientKey": API_KEY,
"taskId": task_id,
}
while True:
response = requests.post(
"https://api.capsolver.com/getTaskResult",
json=payload
)
result = response.json()
if result.get("status") == "ready":
return result["solution"]["gRecaptchaResponse"]
time.sleep(2)
task_id = create_task()
token = get_task_result(task_id)
print("Token CAPTCHA:", token)Este token é então injetado no campo g-recaptcha-response do formulário, permitindo que seu raspador continue após o gate de CAPTCHA. Para tarefas com proxy, altere o tipo de tarefa para ReCaptchaV2Task e adicione seus detalhes de proxy ao payload.
A CapSolver suporta dois modos de tarefa:
ReCaptchaV2TaskProxyLess— usa a própria infraestrutura da CapSolver; configuração mais simples.ReCaptchaV2Task— usa seu próprio proxy; melhor para sites com restrições geográficas rigorosas.
Para a lista completa de tipos de tarefa suportados — incluindo reCAPTCHA v3, Cloudflare Turnstile e AWS WAF — consulte a documentação de tipos de tarefa da CapSolver.
Construindo um Pipeline Completo de Extração de Dados no Linux
Uma configuração de raspagem de dados no Linux pronta para produção é mais do que um único script. É um pipeline com estágios distintos e componíveis.
Arquitetura do Pipeline
[Agendador: cron]
→ [Raspador: Scrapy / Playwright]
→ [Camada de Proxy: residencial em rotação]
→ [Tratador de CAPTCHA: API da CapSolver]
→ [Parser: BeautifulSoup / lxml]
→ [Armazenamento: SQLite / PostgreSQL]
→ [Exportação: CSV / JSON / API REST]Agendamento com Cron
Edite seu crontab para executar uma tarefa de raspagem a cada hora:
bash
crontab -eAdicione a seguinte linha:
0 * * * * /home/user/scraper-env/bin/python /home/user/scraper/run.py >> /home/user/scraper/logs/scrape.log 2>&1Armazenamento dos Dados Raspados
Para projetos pequenos, o SQLite é suficiente:
python
import sqlite3
conn = sqlite3.connect("data.db")
cursor = conn.cursor()
cursor.execute(
"CREATE TABLE IF NOT EXISTS products (name TEXT, price TEXT, url TEXT)"
)
cursor.execute(
"INSERT INTO products VALUES (?, ?, ?)", (name, price, url)
)
conn.commit()
conn.close()Para pipelines maiores, o PostgreSQL com SQLAlchemy oferece melhor concorrência e desempenho de consulta.
Registro e Tratamento de Erros
Sempre registre a atividade de raspagem. Use o módulo logging integrado do Python:
python
import logging
logging.basicConfig(
filename="scrape.log",
level=logging.INFO,
format="%(asctime)s %(levelname)s %(message)s"
)
logging.info("Raspagem iniciada")O registro estruturado torna muito mais fácil depurar falhas em tarefas de raspagem de dados no Linux de longa duração — especialmente quando erros de proxy e tempos esgotados de CAPTCHA estão envolvidos.
Conformidade e Raspagem Responsável
A raspagem de dados no Linux é uma capacidade poderosa, mas deve ser usada de forma responsável.
- Verifique
robots.txt— sempre revisehttps://example.com/robots.txtantes de raspar. Respeite as diretrizes deDisallow. - Limitação de taxa — não ataque os servidores. Adicione atrasos entre as requisições para evitar prejudicar o desempenho do site.
- Termos de Serviço — revise os Termos de Serviço do site alvo. Alguns sites proíbem explicitamente a coleta de dados automatizada.
- Dados Pessoais — evite coletar informações pessoalmente identificáveis (PII) sem base legal sob regulamentações aplicáveis, como GDPR.
- Direitos Autorais — o conteúdo raspado pode estar protegido por direitos autorais. Use os dados para análise, não para republicação.
A raspagem responsável não é apenas uma consideração ética — é cada vez mais uma legal. Os frameworks em torno da coleta de dados automatizada continuam evoluindo, e construir conformidade no seu pipeline desde o início é muito mais barato do que adaptá-lo posteriormente.
Conclusão
A raspagem de dados no Linux oferece aos desenvolvedores uma base estável, scriptável e de baixo custo para extração de dados em qualquer escala. A combinação de ferramentas de raspagem Python como Scrapy e Playwright, uma camada de proxy bem configurada e um serviço de resolução de CAPTCHA programática cobre a gama completa de desafios que você encontrará em produção. Comece com um ambiente virtual limpo, escolha suas ferramentas com base na complexidade do site alvo e construa seu pipeline gradualmente — incluindo agendamento, armazenamento e tratamento de erros.
Se os desafios CAPTCHA estão bloqueando seu fluxo de raspagem, comece com o CapSolver e integre a resolução de CAPTCHA com inteligência artificial ao seu pipeline em minutos.
Perguntas frequentes
Q1: Qual é a melhor biblioteca Python para raspagem de web em Linux?
Depende do caso de uso. Para páginas estáticas, Requests combinado com BeautifulSoup é a opção mais rápida e simples. Para varreduras em larga escala e recorrentes, Scrapy é o padrão da indústria. Para páginas com JavaScript pesado, Playwright é a escolha recomendada no Linux.
Q2: Como executar um raspador de web automaticamente no Linux?
Use jobs de cron. Edite seu crontab com crontab -e e adicione uma linha especificando o horário e o caminho para seu script Python. Isso executa seu raspador em qualquer intervalo sem intervenção manual.
Q3: Como lidar com CAPTCHAs em uma pipeline de raspagem de web?
Integre uma API de resolução de CAPTCHA, como o CapSolver. Seu raspador envia a URL do site e a chave do site para a API, recebe um token resolvido e o insere na solicitação. Este processo é totalmente automatizado e adiciona apenas alguns segundos de latência por CAPTCHA encontrado.
Q4: Proxies são necessários para raspagem de web no Linux?
Para tarefas pequenas e esporádicas de raspagem, proxies podem não ser necessários. Para pipelines de extração de dados em larga escala ou contínuos, proxies rotativos são essenciais para evitar limitação de taxa baseada em IP e bloqueios.
Q5: A raspagem de web no Linux é legal?
A raspagem de web em si é geralmente legal quando aplicada a dados acessíveis publicamente. No entanto, você deve respeitar o robots.txt do site alvo, seus termos de serviço e as leis de proteção de dados aplicáveis. A raspagem de dados pessoais ou conteúdo com direitos autorais sem autorização traz risco legal.