Como resolver Captcha no Maxun com Integração do CapSolver

Adélia Cruz
Neural Network Developer

Na extração de dados da web, o Maxun está ganhando atenção como uma plataforma de código aberto e sem código que simplifica como as equipes coletam dados da web. Suas workflows baseadas em robôs e SDK permitem que desenvolvedores e usuários não técnicos construam e mantenham pipelines de raspagem sem esforço de engenharia pesado.
Dito isso, muitos sites reais são protegidos por CAPTCHAs, que frequentemente se tornam o principal gargalo durante a extração de dados. CapSolver funciona bem junto com o Maxun ao lidar com esses desafios no nível da infraestrutura. Com o CapSolver em vigor, os robôs do Maxun podem continuar operando em páginas protegidas por CAPTCHA de forma mais confiável, combinando facilidade de uso com capacidades de raspagem práticas e prontas para produção.
O que é o Maxun?
Maxun é uma plataforma de extração de dados da web de código aberto e sem código que permite aos usuários treinar robôs para raspar sites sem escrever código. Ele oferece uma interface visual para construir robôs, um SDK poderoso para controle programático e suporta implantações em nuvem e auto-hospedadas.
Principais Funcionalidades do Maxun
- Construtor de Robôs sem Código: Interface visual para treinar robôs de extração sem programação
- SDK Poderoso: SDK TypeScript/Node.js para execução programática de robôs
- Múltiplos Modos de Extração: Capacidades de Extração, raspagem, navegação e busca
- Seletores Inteligentes: Detecção automática de elementos e geração de seletores inteligentes
- Nuvem e Auto-Hospedado: Implante na Nuvem Maxun ou em sua própria infraestrutura
- Suporte a Proxy: Rotação e gerenciamento de proxy integrados
- Execuções Agendadas: Automatize a execução de robôs com agendamento baseado em cron
Classes Principais do SDK
| Classe | Descrição |
|---|---|
| Extração | Construa fluxos de trabalho de extração de dados estruturados com LLM ou seletores CSS |
| Raspagem | Converta páginas da web em Markdown, HTML ou capturas de tela limpas |
| Navegação | Descubra e raspe múltiplas páginas automaticamente usando sitemaps e links |
| Busca | Execute buscas na web e extraia conteúdo dos resultados (DuckDuckGo) |
O que Torna o Maxun Diferente
O Maxun pontua entre a simplicidade sem código e a flexibilidade do desenvolvedor:
- Visual + Código: Treine robôs visualmente, depois os controle programaticamente via SDK
- Arquitetura Baseada em Robôs: Modelos de extração reutilizáveis e compartilháveis
- TipoScript Nativo: Construído para aplicações Node.js modernas
- Código Aberto: Transparência total e desenvolvimento comunitário
O que é o CapSolver?
CapSolver é um serviço líder de resolução de CAPTCHA que fornece soluções com inteligência artificial para contornar vários desafios de CAPTCHA. Com suporte para vários tipos de CAPTCHA e tempos de resposta rápidos, o CapSolver se integra perfeitamente em fluxos de trabalho automatizados.
Tipos de CAPTCHA Suportados
O CapSolver ajuda fluxos de automação a lidar com a maioria dos principais desafios de CAPTCHA e verificações comumente encontrados durante a raspagem da web e automação de navegadores, incluindo:
- reCAPTCHA v2 (baseado em imagem e invisível)
- reCAPTCHA v3 & v3 Enterprise
- Cloudflare Turnstile
- Cloudflare 5-second Challenge
- AWS WAF CAPTCHA
- Outros mecanismos de anti-bot e CAPTCHA amplamente utilizados
Por que Integrar o CapSolver com o Maxun?
Ao construir robôs do Maxun que interagem com sites protegidos — seja para extração de dados, monitoramento de preços ou pesquisas de mercado — os desafios de CAPTCHA tornam-se um obstáculo significativo. Aqui está por que a integração importa:
- Extração de Dados Ininterrupta: Os robôs podem completar suas missões sem intervenção manual
- Operações Escaláveis: Lidar com desafios de CAPTCHA em múltiplas execuções simultâneas de robôs
- Fluxo de Trabalho Sem Preocupações: Resolver CAPTCHAs como parte de seu pipeline de extração
- Custo-Efetivo: Pague apenas pelos CAPTCHAs resolvidos com sucesso
- Alta Taxa de Sucesso: Precisão líder da indústria para todos os tipos de CAPTCHA suportados
Instalação
Pré-requisitos
- Node.js 18 ou superior
- npm ou yarn
- Uma chave de API do CapSolver

Instalando o SDK do Maxun
bash
# Instale o SDK do Maxun
npm install maxun-sdk
# Instale dependências adicionais para integração com o CapSolver
npm install axiosInstalação com Docker (Maxun Auto-Hospedado)
bash
# Clone o repositório do Maxun
git clone https://github.com/getmaxun/maxun.git
cd maxun
# Inicie com Docker Compose
docker-compose up -dConfiguração do Ambiente
Crie um arquivo .env com sua configuração:
env
CAPSOLVER_API_KEY=seu_capsolver_api_key
MAXUN_API_KEY=seu_maxun_api_key
# Para a Nuvem Maxun (app.maxun.dev)
MAXUN_BASE_URL=https://app.maxun.dev/api/sdk
# Para o Maxun Auto-Hospedado (padrão)
# MAXUN_BASE_URL=http://localhost:8080/api/sdkNota: A configuração do
baseUrlé necessária ao usar a Nuvem Maxun. Instalações auto-hospedadas usam por padrãohttp://localhost:8080/api/sdk.
Criando um Serviço do CapSolver para o Maxun
Aqui está um serviço TypeScript reutilizável que integra o CapSolver ao Maxun:
Serviço Básico do CapSolver
typescript
import axios, { AxiosInstance } from 'axios';
interface TaskResult {
gRecaptchaResponse?: string;
token?: string;
cookies?: Array<{ name: string; value: string }>;
userAgent?: string;
}
interface CapSolverConfig {
apiKey: string;
timeout?: number;
maxAttempts?: number;
}
class CapSolverService {
private client: AxiosInstance;
private apiKey: string;
private maxAttempts: number;
constructor(config: CapSolverConfig) {
this.apiKey = config.apiKey;
this.maxAttempts = config.maxAttempts || 60;
this.client = axios.create({
baseURL: 'https://api.capsolver.com',
timeout: config.timeout || 30000,
headers: { 'Content-Type': 'application/json' },
});
}
private async createTask(taskData: Record<string, unknown>): Promise<string> {
const response = await this.client.post('/createTask', {
clientKey: this.apiKey,
task: taskData,
});
if (response.data.errorId !== 0) {
throw new Error(`Erro do CapSolver: ${response.data.errorDescription}`);
}
return response.data.taskId;
}
private async getTaskResult(taskId: string): Promise<TaskResult> {
for (let attempt = 0; attempt < this.maxAttempts; attempt++) {
await this.delay(2000);
const response = await this.client.post('/getTaskResult', {
clientKey: this.apiKey,
taskId,
});
const { status, solution, errorDescription } = response.data;
if (status === 'ready') {
return solution as TaskResult;
}
if (status === 'failed') {
throw new Error(`Tarefa falhou: ${errorDescription}`);
}
}
throw new Error('Tempo esgotado esperando pela solução do CAPTCHA');
}
private delay(ms: number): Promise<void> {
return new Promise((resolve) => setTimeout(resolve, ms));
}
async solveReCaptchaV2(websiteUrl: string, websiteKey: string): Promise<string> {
const taskId = await this.createTask({
type: 'ReCaptchaV2TaskProxyLess',
websiteURL: websiteUrl,
websiteKey,
});
const solution = await this.getTaskResult(taskId);
return solution.gRecaptchaResponse || '';
}
async solveReCaptchaV3(
websiteUrl: string,
websiteKey: string,
pageAction: string = 'submit'
): Promise<string> {
const taskId = await this.createTask({
type: 'ReCaptchaV3TaskProxyLess',
websiteURL: websiteUrl,
websiteKey,
pageAction,
});
const solution = await this.getTaskResult(taskId);
return solution.gRecaptchaResponse || '';
}
async solveTurnstile(
websiteUrl: string,
websiteKey: string,
action?: string,
cdata?: string
): Promise<string> {
const taskData: Record<string, unknown> = {
type: 'AntiTurnstileTaskProxyLess',
websiteURL: websiteUrl,
websiteKey,
};
// Adicione metadados opcionais
if (action || cdata) {
taskData.metadata = {};
if (action) (taskData.metadata as Record<string, string>).action = action;
if (cdata) (taskData.metadata as Record<string, string>).cdata = cdata;
}
const taskId = await this.createTask(taskData);
const solution = await this.getTaskResult(taskId);
return solution.token || '';
}
async checkBalance(): Promise<number> {
const response = await this.client.post('/getBalance', {
clientKey: this.apiKey,
});
return response.data.balance || 0;
}
}
export { CapSolverService, CapSolverConfig, TaskResult };★ Dica ─────────────────────────────────────
O serviço do CapSolver usa um padrão de sondagem (getTaskResult) porque a resolução de CAPTCHA é assíncrona — a API aceita uma tarefa, processa-a em seus servidores e retorna um resultado quando pronto. A pausa de 2 segundos entre as sondagens equilibra a responsividade com os limites de taxa da API.
─────────────────────────────────────────────────
Resolvendo Diferentes Tipos de CAPTCHA
reCAPTCHA v2 com o Maxun
Como o Maxun opera em um nível mais alto do que a automação de navegador bruta, a abordagem de integração se concentra em resolver CAPTCHAs antes ou durante a execução do robô:
typescript
import { Extract } from 'maxun-sdk';
import { CapSolverService } from './capsolver-service';
const CAPSOLVER_API_KEY = process.env.CAPSOLVER_API_KEY!;
const MAXUN_API_KEY = process.env.MAXUN_API_KEY!;
const MAXUN_BASE_URL = process.env.MAXUN_BASE_URL || 'https://app.maxun.dev/api/sdk';
const capSolver = new CapSolverService({ apiKey: CAPSOLVER_API_KEY });
const extractor = new Extract({
apiKey: MAXUN_API_KEY,
baseUrl: MAXUN_BASE_URL,
});
async function extractWithRecaptchaV2() {
const targetUrl = 'https://example.com/protected-page';
const recaptchaSiteKey = '6LcxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxABC';
console.log('Resolvendo reCAPTCHA v2...');
// Resolva o CAPTCHA primeiro
const token = await capSolver.solveReCaptchaV2(targetUrl, recaptchaSiteKey);
console.log('CAPTCHA resolvido, criando robô de extração...');
// Crie um robô usando encadeamento de métodos
const robot = await extractor
.create('Extrator de Produtos')
.navigate(targetUrl)
.type('#g-recaptcha-response', token)
.click('button[type="submit"]')
.wait(2000)
.captureList({ selector: '.product-item' });
// Execute o robô
const result = await robot.run({ timeout: 30000 });
console.log('Extração concluída:', result.data);
return result.data;
}
extractWithRecaptchaV2().catch(console.error);reCAPTCHA v3 com o Maxun
typescript
import { Extract } from 'maxun-sdk';
import { CapSolverService } from './capsolver-service';
const CAPSOLVER_API_KEY = process.env.CAPSOLVER_API_KEY!;
const MAXUN_API_KEY = process.env.MAXUN_API_KEY!;
const MAXUN_BASE_URL = process.env.MAXUN_BASE_URL || 'https://app.maxun.dev/api/sdk';
const capSolver = new CapSolverService({ apiKey: CAPSOLVER_API_KEY });
const extractor = new Extract({
apiKey: MAXUN_API_KEY,
baseUrl: MAXUN_BASE_URL,
});
async function extractWithRecaptchaV3() {
const targetUrl = 'https://example.com/v3-protected';
const recaptchaSiteKey = '6LcxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxDEF';
console.log('Resolvendo reCAPTCHA v3 com alto score...');
// Resolva com ação de página personalizada
const token = await capSolver.solveReCaptchaV3(
targetUrl,
recaptchaSiteKey,
'submit' // pageAction
);
console.log('Token obtido com alto score, criando robô...');
// Crie um robô de extração usando encadeamento de métodos
const robot = await extractor
.create('Extrator Protegido por V3')
.navigate(targetUrl)
.type('input[name="g-recaptcha-response"]', token)
.click('#submit-btn')
.wait(2000)
.captureText({ resultData: '.result-data' });
const result = await robot.run({ timeout: 30000 });
console.log('Dados extraídos:', result.data);
return result.data;
}
extractWithRecaptchaV3().catch(console.error);Cloudflare Turnstile com o Maxun
typescript
import { Scrape } from 'maxun-sdk';
import { CapSolverService } from './capsolver-service';
const CAPSOLVER_API_KEY = process.env.CAPSOLVER_API_KEY!;
const MAXUN_API_KEY = process.env.MAXUN_API_KEY!;
const MAXUN_BASE_URL = process.env.MAXUN_BASE_URL || 'https://app.maxun.dev/api/sdk';
const capSolver = new CapSolverService({ apiKey: CAPSOLVER_API_KEY });
const scraper = new Scrape({
apiKey: MAXUN_API_KEY,
baseUrl: MAXUN_BASE_URL,
});
async function extractWithTurnstile() {
const targetUrl = 'https://example.com/turnstile-protected';
const turnstileSiteKey = '0x4xxxxxxxxxxxxxxxxxxxxxxxxxxxxGHI';
console.log('Resolvendo Cloudflare Turnstile...');
// Resolva com metadados opcionais (ação e cdata)
const token = await capSolver.solveTurnstile(
targetUrl,
turnstileSiteKey,
'login', // ação opcional
'0000-1111-2222-3333-exemplo-cdata' // cdata opcional
);
console.log('Turnstile resolvido, criando robô de raspagem...');
// Crie um robô de raspagem - para Turnstile, geralmente precisamos
// enviar o token via solicitação POST primeiro, depois raspagem
const robot = await scraper.create('turnstile-scraper', targetUrl, {
formats: ['markdown', 'html'],
});
const result = await robot.run({ timeout: 30000 });
console.log('Extração concluída');
console.log('Markdown:', result.data.markdown?.substring(0, 500));
return result.data;
}
extractWithTurnstile().catch(console.error);Integração com Fluxos do Maxun
Usando com a Classe Extract
A classe Extract é usada para extrair dados estruturados de elementos específicos de uma página. Ela suporta extração com LLM (usando prompts de linguagem natural) e extração sem LLM (usando seletores CSS):
typescript
import { Extract } from 'maxun-sdk';
import { CapSolverService } from './capsolver-service';
const capSolver = new CapSolverService({ apiKey: process.env.CAPSOLVER_API_KEY! });
const extractor = new Extract({
apiKey: process.env.MAXUN_API_KEY!,
baseUrl: process.env.MAXUN_BASE_URL || 'https://app.maxun.dev/api/sdk',
});
interface ProductData {
name: string;
price: string;
rating: string;
}
async function extractProductsWithCaptcha(): Promise<ProductData[]> {
const targetUrl = 'https://example.com/products';
const siteKey = '6LcxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxABC';
// Pré-solução de CAPTCHA
const captchaToken = await capSolver.solveReCaptchaV2(targetUrl, siteKey);
console.log('CAPTCHA resolvido, criando robô de extração...');
// Crie um robô de extração usando encadeamento de métodos
const robot = await extractor
.create('Extrator de Produtos')
.navigate(targetUrl)
.type('#g-recaptcha-response', captchaToken)
.click('button[type="submit"]')
.wait(3000)
.captureList({
selector: '.product-card',
paginação: { tipo: 'clickNext', selector: '.next-page' },
maxItems: 50,
});
// Execute a extração
const result = await robot.run({ timeout: 60000 });
return result.data.listData as ProductData[];
}
extractProductsWithCaptcha()
.then((products) => {
products.forEach((product) => {
console.log(`${product.name}: ${product.price}`);
});
})
.catch(console.error);★ Insight ─────────────────────────────────────
O método captureList na classe Extract do Maxun detecta automaticamente os campos nos itens da lista e gerencia a paginação. Quando você especifica um tipo de paginação (scrollDown, clickNext ou clickLoadMore), o robô continuará extraindo até atingir seu limite ou esgotar as páginas.
─────────────────────────────────────────────────
Usando com a Classe Scrape
A classe Scrape converte páginas da web em HTML limpo, Markdown pronto para LLM ou capturas de tela:
typescript
import { Scrape } from 'maxun-sdk';
import { CapSolverService } from './capsolver-service';
import axios from 'axios';
const capSolver = new CapSolverService({ apiKey: process.env.CAPSOLVER_API_KEY! });
const scraper = new Scrape({
apiKey: process.env.MAXUN_API_KEY!,
baseUrl: process.env.MAXUN_BASE_URL || 'https://app.maxun.dev/api/sdk',
});
interface ScrapeResult {
url: string;
markdown?: string;
html?: string;
captchaSolved: boolean;
}
async function scrapeWithCaptchaHandling(): Promise<ScrapeResult[]> {
const urls = [
'https://example.com/page1',
'https://example.com/page2',
'https://example.com/page3',
];
const results: ScrapeResult[] = [];
for (const url of urls) {
try {
// Para páginas protegidas por CAPTCHA, resolva primeiro e estabeleça a sessão
const siteKey = '6LcxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxABC'; // Obtenha dinamicamente se necessário
console.log(`Resolvendo CAPTCHA para ${url}...`);
const captchaToken = await capSolver.solveReCaptchaV2(url, siteKey);
// Envie o CAPTCHA para obter cookies de sessão
const verifyResponse = await axios.post(`${url}/verify`, {
'g-recaptcha-response': captchaToken,
});
// Crie um robô de scrape para a página autenticada
const robot = await scraper.create(`scraper-${Date.now()}`, url, {
formats: ['markdown', 'html'],
});
const result = await robot.run({ timeout: 30000 });
results.push({
url,
markdown: result.data.markdown,
html: result.data.html,
captchaSolved: true,
});
// Limpeza - exclua o robô após o uso
await robot.delete();
} catch (error) {
console.error(`Falha ao scrape ${url}:`, error);
results.push({ url, captchaSolved: false });
}
}
return results;
}
scrapeWithCaptchaHandling().then(console.log).catch(console.error);Usando com a Classe Crawl
A classe Crawl descobre e scrape múltiplas páginas automaticamente usando sitemaps e seguindo links:
typescript
import { Crawl } from 'maxun-sdk';
import { CapSolverService } from './capsolver-service';
import axios from 'axios';
const capSolver = new CapSolverService({ apiKey: process.env.CAPSOLVER_API_KEY! });
const crawler = new Crawl({
apiKey: process.env.MAXUN_API_KEY!,
baseUrl: process.env.MAXUN_BASE_URL || 'https://app.maxun.dev/api/sdk',
});
interface PageResult {
url: string;
title: string;
text: string;
wordCount: number;
}
async function crawlWithCaptchaProtection(): Promise<PageResult[]> {
const startUrl = 'https://example.com';
const siteKey = '6LcxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxABC';
// Pré-solucione o CAPTCHA para o domínio
console.log('Resolvendo CAPTCHA para acesso ao domínio...');
const captchaToken = await capSolver.solveReCaptchaV2(startUrl, siteKey);
// Envie o CAPTCHA para estabelecer a sessão (específico do site)
await axios.post(`${startUrl}/verify`, {
'g-recaptcha-response': captchaToken,
});
// Crie um robô de crawl com configuração de escopo de domínio
const robot = await crawler.create('site-crawler', startUrl, {
modo: 'domínio', // Escopo de crawl: 'domínio', 'subdomínio' ou 'caminho'
limite: 50, // Máximo de páginas a crawl
maxDepth: 3, // Quão profundo seguir links
useSitemap: true, // Analise sitemap.xml para URLs
followLinks: true, // Extraia e siga links das páginas
includePaths: ['/blog/', '/docs/'], // Padrões regex para incluir
excludePaths: ['/admin/', '/login/'], // Padrões regex para excluir
respectRobots: true, // Honre o robots.txt
});
// Execute o crawl
const result = await robot.run({ timeout: 120000 });
// Cada página em result contém: metadata, html, text, wordCount, links
return result.data.crawlData.map((page: any) => ({
url: page.metadata.url,
title: page.metadata.title,
text: page.text,
wordCount: page.wordCount,
}));
}
crawlWithCaptchaProtection()
.then((pages) => {
console.log(`Crawleou ${pages.length} páginas`);
pages.forEach((page) => {
console.log(`- ${page.title}: ${page.url} (${page.wordCount} palavras)`);
});
})
.catch(console.error);Padrão de Pré-Authenticação
Para sites que exigem CAPTCHA antes de acessar o conteúdo, use um fluxo de pré-autenticação:
typescript
import axios from 'axios';
import { Extract } from 'maxun-sdk';
import { CapSolverService } from './capsolver-service';
const capSolver = new CapSolverService({ apiKey: process.env.CAPSOLVER_API_KEY! });
const extractor = new Extract({
apiKey: process.env.MAXUN_API_KEY!,
baseUrl: process.env.MAXUN_BASE_URL || 'https://app.maxun.dev/api/sdk',
});
interface SessionCookies {
name: string;
value: string;
domain: string;
}
async function preAuthenticateWithCaptcha(
loginUrl: string,
siteKey: string
): Promise<SessionCookies[]> {
// Passo 1: Resolva o CAPTCHA
const captchaToken = await capSolver.solveReCaptchaV2(loginUrl, siteKey);
// Passo 2: Envie o token do CAPTCHA para obter cookies de sessão
const response = await axios.post(
loginUrl,
{
'g-recaptcha-response': captchaToken,
},
{
withCredentials: true,
maxRedirects: 0,
validateStatus: (status) => status < 400,
}
);
// Passo 3: Extraia cookies da resposta
const setCookies = response.headers['set-cookie'] || [];
const cookies: SessionCookies[] = setCookies.map((cookie: string) => {
const [nameValue] = cookie.split(';');
const [name, value] = nameValue.split('=');
return {
name: name.trim(),
value: value.trim(),
domain: new URL(loginUrl).hostname,
};
});
return cookies;
}
async function extractWithPreAuth() {
const loginUrl = 'https://example.com/verify';
const targetUrl = 'https://example.com/protected-data';
const siteKey = '6LcxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxABC';
// Pré-autentique para obter cookies de sessão
const sessionCookies = await preAuthenticateWithCaptcha(loginUrl, siteKey);
console.log('Sessão estabelecida, criando robô de extração...');
// Crie um robô de extração usando encadeamento de métodos
// Observe: Use setCookies() para passar cookies de sessão autenticada
const robot = await extractor
.create('Extrator Autenticado')
.setCookies(sessionCookies)
.navigate(targetUrl)
.wait(2000)
.captureText({ content: '.protected-content' });
// Execute a extração
const result = await robot.run({ timeout: 30000 });
return result.data;
}
extractWithPreAuth().then(console.log).catch(console.error);★ Insight ─────────────────────────────────────
O padrão de pré-autenticação separa a resolução do CAPTCHA da extração de dados. Isso é especialmente útil para o Maxun, pois opera em um nível de abstração mais alto — em vez de injetar tokens no DOM, você estabelece uma sessão autenticada primeiro, e depois deixa os robôs do Maxun trabalharem dentro dessa sessão.
─────────────────────────────────────────────────
Execução Paralela de Robôs com Tratamento de CAPTCHA
Gerencie CAPTCHAs em múltiplas execuções concorrentes de robôs:
typescript
import { Scrape } from 'maxun-sdk';
import { CapSolverService } from './capsolver-service';
const capSolver = new CapSolverService({ apiKey: process.env.CAPSOLVER_API_KEY! });
const scraper = new Scrape({
apiKey: process.env.MAXUN_API_KEY!,
baseUrl: process.env.MAXUN_BASE_URL || 'https://app.maxun.dev/api/sdk',
});
interface ExtractionJob {
url: string;
siteKey?: string;
}
interface ExtractionResult {
url: string;
data: { markdown?: string; html?: string };
captchaSolved: boolean;
duration: number;
}
async function processJob(job: ExtractionJob): Promise<ExtractionResult> {
const startTime = Date.now();
let captchaSolved = false;
// Resolva CAPTCHA se siteKey for fornecido
if (job.siteKey) {
console.log(`Resolvendo CAPTCHA para ${job.url}...`);
const token = await capSolver.solveReCaptchaV2(job.url, job.siteKey);
captchaSolved = true;
// O token seria enviado para estabelecer a sessão antes do scrape
}
// Crie e execute um robô de scrape
const robot = await scraper.create(`scraper-${Date.now()}`, job.url, {
formats: ['markdown', 'html'],
});
const result = await robot.run({ timeout: 30000 });
// Limpeza - exclua o robô após o uso
await robot.delete();
return {
url: job.url,
data: {
markdown: result.data.markdown,
html: result.data.html,
},
captchaSolved,
duration: Date.now() - startTime,
};
}
async function runParallelExtractions(
jobs: ExtractionJob[],
concurrency: number = 5
): Promise<ExtractionResult[]> {
const results: ExtractionResult[] = [];
const chunks: ExtractionJob[][] = [];
// Divida os jobs em chunks para controle de concorrência
for (let i = 0; i < jobs.length; i += concurrency) {
chunks.push(jobs.slice(i, i + concurrency));
}
for (const chunk of chunks) {
const chunkResults = await Promise.all(chunk.map(processJob));
results.push(...chunkResults);
}
return results;
}
// Exemplo de uso
const jobs: ExtractionJob[] = [
{ url: 'https://site1.com/data', siteKey: '6Lc...' },
{ url: 'https://site2.com/data' },
{ url: 'https://site3.com/data', siteKey: '6Lc...' },
// ... mais jobs
];
runParallelExtractions(jobs, 5)
.then((results) => {
const solved = results.filter((r) => r.captchaSolved).length;
console.log(`Concluído ${results.length} extrações, resolvidos ${solved} CAPTCHAs`);
results.forEach((r) => {
console.log(`${r.url}: ${r.duration}ms`);
});
})
.catch(console.error);Boas Práticas
1. Tratamento de Erros com Retentativas
typescript
async function solveWithRetry<T>(
solverFn: () => Promise<T>,
maxRetries: number = 3
): Promise<T> {
let lastError: Error | undefined;
for (let attempt = 0; attempt < maxRetries; attempt++) {
try {
return await solverFn();
} catch (error) {
lastError = error as Error;
console.warn(`Tentativa ${attempt + 1} falhou: ${lastError.message}`);
// Backoff exponencial
await new Promise((resolve) =>
setTimeout(resolve, Math.pow(2, attempt) * 1000)
);
}
}
throw new Error(`Máximo de tentativas excedido: ${lastError?.message}`);
}
// Uso
const token = await solveWithRetry(() =>
capSolver.solveReCaptchaV2(url, siteKey)
);2. Gerenciamento de Saldo
typescript
async function garantirSaldoSuficiente(minBalance: number = 1.0): Promise<void> {
const balance = await capSolver.checkBalance();
if (balance < minBalance) {
throw new Error(
`Saldo insuficiente do CapSolver: $${balance.toFixed(2)}. Por favor, recarregue.`
);
}
console.log(`Saldo do CapSolver: $${balance.toFixed(2)}`);
}
// Verifique o saldo antes de iniciar os jobs de extração
await garantirSaldoSuficiente(5.0);3. Cache de Token
typescript
interface TokenCache {
token: string;
timestamp: number;
}
class TokenCache {
private cache = new Map<string, TokenCache>();
private ttlMs: number;
constructor(ttlSeconds: number = 90) {
this.ttlMs = ttlSeconds * 1000;
}
private getKey(domain: string, siteKey: string): string {
return `${domain}:${siteKey}`;
}
get(domain: string, siteKey: string): string | null {
const key = this.getKey(domain, siteKey);
const cached = this.cache.get(key);
if (!cached) return null;
if (Date.now() - cached.timestamp > this.ttlMs) {
this.cache.delete(key);
return null;
}
return cached.token;
}
set(domain: string, siteKey: string, token: string): void {
const key = this.getKey(domain, siteKey);
this.cache.set(key, { token, timestamp: Date.now() });
}
}
const tokenCache = new TokenCache(90);
async function getOuCacheToken(
url: string,
siteKey: string
): Promise<string> {
const domain = new URL(url).hostname;
const cached = tokenCache.get(domain, siteKey);
if (cached) {
console.log('Usando token em cache');
return cached;
}
const token = await capSolver.solveReCaptchaV2(url, siteKey);
tokenCache.set(domain, siteKey, token);
return token;
}Opções de Configuração
O Maxun suporta configuração por meio de variáveis de ambiente e opções do SDK:
| Configuração | Descrição | Padrão |
|---|---|---|
MAXUN_API_KEY |
Sua chave de API do Maxun | - |
MAXUN_BASE_URL |
URL base da API do Maxun | http://localhost:8080/api/sdk (auto-hospedado) ou https://app.maxun.dev/api/sdk (nuvem) |
CAPSOLVER_API_KEY |
Sua chave de API do CapSolver | - |
CAPSOLVER_TIMEOUT |
Tempo limite da requisição em ms | 30000 |
CAPSOLVER_MAX_ATTEMPTS |
Máximo de tentativas de polling | 60 |
Configuração do SDK
typescript
import { Extract, Scrape, Crawl, Search } from 'maxun-sdk';
import { CapSolverService } from './capsolver-service';
// Para o Maxun Cloud (app.maxun.dev)
const MAXUN_BASE_URL = 'https://app.maxun.dev/api/sdk';
// Para o Maxun auto-hospedado (padrão)
// const MAXUN_BASE_URL = 'http://localhost:8080/api/sdk';
// Configure os módulos do SDK Maxun
const extractor = new Extract({
apiKey: process.env.MAXUN_API_KEY!,
baseUrl: MAXUN_BASE_URL,
});
const scraper = new Scrape({
apiKey: process.env.MAXUN_API_KEY!,
baseUrl: MAXUN_BASE_URL,
});
const crawler = new Crawl({
apiKey: process.env.MAXUN_API_KEY!,
baseUrl: MAXUN_BASE_URL,
});
const searcher = new Search({
apiKey: process.env.MAXUN_API_KEY!,
baseUrl: MAXUN_BASE_URL,
});
// Configure o CapSolver
const capSolver = new CapSolverService({
apiKey: process.env.CAPSOLVER_API_KEY!,
timeout: 30000,
maxAttempts: 60,
});Conclusão
Integrar o CapSolver com o Maxun cria uma combinação poderosa para extração de dados de web em larga escala. Enquanto a arquitetura baseada em robôs do Maxun abstrai a automação de navegador de baixo nível, o CapSolver fornece a capacidade essencial de burlar desafios de CAPTCHA que, de outra forma, bloqueariam seus fluxos de extração.
A chave para uma integração bem-sucedida é entender que o Maxun opera em um nível mais alto de abstração do que ferramentas tradicionais de automação de navegador. Em vez de manipulação direta do DOM para injeção de tokens de CAPTCHA, a integração se concentra em:
- Pré-autenticação: Resolver CAPTCHAs antes da execução do robô para estabelecer sessões
- Bypass baseado em cookies: Passar tokens resolvidos e cookies para os robôs do Maxun
- Processamento paralelo: Lidar com CAPTCHAs em extrações concorrentes de forma eficiente
Seja para construir sistemas de monitoramento de preços, pipelines de pesquisa de mercado ou plataformas de agregação de dados, a combinação Maxun + CapSolver fornece a confiabilidade e a escalabilidade necessárias para ambientes de produção.
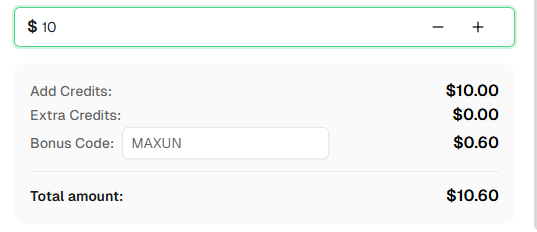
Pronto para começar? Registre-se no CapSolver e use o código de bônus MAXUN para obter um bônus adicional de 6% na primeira recarga!
Perguntas Frequentes
O que é o Maxun?
O Maxun é uma plataforma de extração de dados da web de código aberto e sem código que permite aos usuários treinar robôs para raspagem de sites sem escrever código. Ele possui um construtor visual de robôs, um SDK poderoso em TypeScript/Node.js e suporta implantações em nuvem e auto-hospedadas.
Como o CapSolver se integra ao Maxun?
O CapSolver se integra ao Maxun por meio de um padrão de pré-autenticação. Você resolve CAPTCHAs por meio da API do CapSolver antes de executar os robôs do Maxun, depois passa os tokens resolvidos ou cookies de sessão para seus fluxos de extração. Esse abordagem funciona bem com a abstração de nível mais alto do Maxun.
Quais tipos de CAPTCHAs o CapSolver pode resolver?
O CapSolver suporta uma ampla gama de tipos de CAPTCHA, incluindo reCAPTCHA v2, reCAPTCHA v3, Cloudflare Turnstile, Cloudflare Challenge (5s), AWS WAF, GeeTest v3/v4 e muitos outros.
Quanto custa o CapSolver?
O CapSolver oferece preços competitivos com base no tipo e volume de CAPTCHAs resolvidos. Visite capsolver.com para detalhes sobre os preços atuais. Use o código MAXUN para obter um bônus de 6% na primeira recarga.
Quais linguagens de programação o Maxun suporta?
O SDK do Maxun é construído em TypeScript e roda no Node.js 18+. Ele fornece uma API moderna e segura em tipos para controle programático de robôs e pode ser integrado a qualquer aplicação Node.js.
O Maxun é gratuito para uso?
O Maxun é de código aberto e gratuito para auto-hospedagem. O Maxun também oferece um serviço em nuvem com recursos adicionais e infraestrutura gerenciada. Consulte sua página de preços para detalhes.
Como encontrar a chave do CAPTCHA?
A chave do site é normalmente encontrada na fonte HTML da página. Procure por:
- reCAPTCHA: atributo
data-sitekeyno elemento.g-recaptcha - Turnstile: atributo
data-sitekeyno elemento.cf-turnstile - Ou verifique as requisições de rede para a chave em chamadas de API
O Maxun pode lidar com sessões autenticadas?
Sim, o Maxun suporta cookies e cabeçalhos personalizados nas configurações dos robôs. Você pode passar cookies de sessão obtidos pela resolução de CAPTCHA para autenticar seus robôs de extração.
Qual a diferença entre o Maxun e o Playwright/Puppeteer?
O Maxun opera em um nível mais alto de abstração. Enquanto o Playwright e o Puppeteer fornecem controle de navegador de baixo nível, o Maxun se concentra em fluxos de trabalho reutilizáveis baseados em robôs que podem ser criados visualmente ou programaticamente. Isso torna mais fácil construir e manter pipelines de extração em larga escala.
Mais guias de integração para ler:
Playwright & Puppeteer
Como lidar com CAPTCHAs que aparecem durante a extração?
Para CAPTCHAs que aparecem durante a extração (não na carga inicial da página), você pode precisar implementar um mecanismo de detecção em seu fluxo de robô e disparar a resolução de CAPTCHA quando detectado. Considere usar os recursos de webhook ou callback do Maxun para pausar e retomar a extração.
Ver mais
Web ScrapingApr 22, 2026
Arquitetura de Web Scraping em Rust para Extração de Dados Escalável
Aprenda arquitetura de raspagem web escalável em Rust com reqwest, scraper, raspagem assíncrona, raspagem de navegador headless, rotação de proxies e tratamento de CAPTCHA compatível.
Web ScrapingApr 08, 2026
Selenium vs Puppeteer para Resolução de CAPTCHA: Comparação de Desempenho e Caso de Uso
Compare o Selenium vs Puppeteer para resolver CAPTCHA. Descubra benchmarks de desempenho, notas de estabilidade e como integrar o CapSolver para o máximo de sucesso.

