Técnicas de Anti-Deteção para Web Scraping: Extração de Dados Estável

Anh Tuan
Data Science Expert
TL;Dr
- Rotação de IPs e Proxies: Distribuir as solicitações por proxies residenciais ou móveis evita o bloqueio baseado em IPs e limitação de taxa.
- Otimização de Cabeçalhos: Imitar cabeçalhos de navegador reais, especialmente User-Agent e Referer, ajuda a evitar filtragem HTTP básica.
- Mitigação do Fingerprint do Navegador: Gerenciar os fingerprints de Canvas, WebGL e TLS é essencial para evitar detecção comportamental avançada.
- Manuseio de Desafios JavaScript: Navegadores headless podem executar JavaScript, mas exigem configuração cuidadosa para evitar detecção.
- Resolução de CAPTCHA: Integrar serviços de resolução automática de CAPTCHA, como CapSolver, garante fluxos de extração de dados ininterruptos.
Introdução
A extração de dados é um componente crítico da inteligência de negócios moderna, mas os sites estão cada vez mais implementando defesas sofisticadas para bloquear o acesso automatizado. Compreender as técnicas de anti-deteção de web scraping não é mais opcional para desenvolvedores; é uma exigência fundamental para manter pipelines de dados estáveis e confiáveis. Este guia explora os mecanismos principais por trás da detecção de bots, desde limitação de taxa de IP até fingerprinting de navegador avançado. Ao analisar essas estratégias defensivas, engenheiros de dados e profissionais de scraping podem implementar metodologias robustas para garantir acesso consistente a informações públicas. O foco aqui é em abordagens práticas e estruturadas para contornar a detecção, mantendo práticas éticas e compatíveis com regulamentações.
O que é Anti-Deteção no Web Scraping?
As técnicas de anti-deteção no web scraping referem-se às metodologias e ferramentas usadas pelos desenvolvedores para impedir que seus scripts automatizados sejam identificados e bloqueados pelos sites-alvo. Quando um scraper acessa um site, deixa uma pegada digital. Se essa pegada se desviar do comportamento típico de um usuário humano, os sistemas de segurança do site sinalizarão a atividade como automatizada.
O objetivo principal da anti-deteção é imitar o interação humana o mais próximo possível. Isso envolve gerenciar identificadores de nível de rede, como endereços IP, e características de nível de aplicação, como cabeçalhos HTTP e fingerprints de navegador. Sem essas técnicas, os scrapers enfrentam bloqueios imediatos de IP, desafios CAPTCHA ou respostas enganosas, como armadilhas de mel. Compreender a tecnologia subjacente à detecção de bots é o primeiro passo para construir sistemas de extração de dados resistentes.
Como os Sites Detectam Scrapers
Administradores de sites empregam uma abordagem multicamadas para identificar e mitigar o tráfego automatizado. Essas defesas variam de filtros baseados em regras simples a algoritmos de machine learning complexos que analisam o comportamento do usuário em tempo real.
Endereço IP e Limitação de Taxa
O método mais fundamental de detecção envolve monitorar a frequência e a origem das solicitações recebidas. Se um único endereço IP gerar um volume inusualmente alto de tráfego em um curto período, o servidor provavelmente o bloqueará. Isso é conhecido como limitação de taxa. Além disso, os sites frequentemente mantêm listas negras de faixas de IP de datacenters, sinalizando imediatamente o tráfego originado dessas fontes como suspeito.
Análise de Cabeçalhos HTTP
Toda solicitação HTTP contém cabeçalhos que fornecem informações sobre o cliente. Sistemas de segurança analisam esses cabeçalhos, especialmente o User-Agent, que identifica o navegador e o sistema operacional. Scrapers que usam bibliotecas padrão frequentemente enviam cabeçalhos ausentes ou anômalos. Por exemplo, uma solicitação que falta o cabeçalho Accept-Language ou apresenta uma string User-Agent desatualizada é um forte indicador de atividade automatizada.
Fingerprinting de Navegador
Sistemas de detecção avançados vão além dos cabeçalhos para analisar as características únicas do navegador do cliente. Essa técnica, conhecida como fingerprinting de navegador, coleta dados sobre resolução de tela, fontes instaladas, plug-ins compatíveis e concorrência de hardware. Métodos ainda mais sofisticados envolvem fingerprinting de Canvas e WebGL, que instruem o navegador a renderizar uma imagem oculta e analisar as pequenas diferenças em como o hardware processa os gráficos. Essas variações sutis criam um identificador altamente preciso para o dispositivo.
Análise de Comportamento e Armadilhas de Mel
Soluções de segurança modernas avaliam como um usuário interage com a página. Elas rastreiam movimentos do mouse, padrões de rolagem e o tempo entre cliques. Bots geralmente exibem comportamento linear e previsível, enquanto humanos são imprevisíveis. Além disso, os sites implementam armadilhas de mel — links ou campos de formulário ocultos que são invisíveis para usuários humanos, mas descobertos por scrapers que analisam o HTML. Interagir com uma armadilha de mel revela imediatamente a presença de um bot.
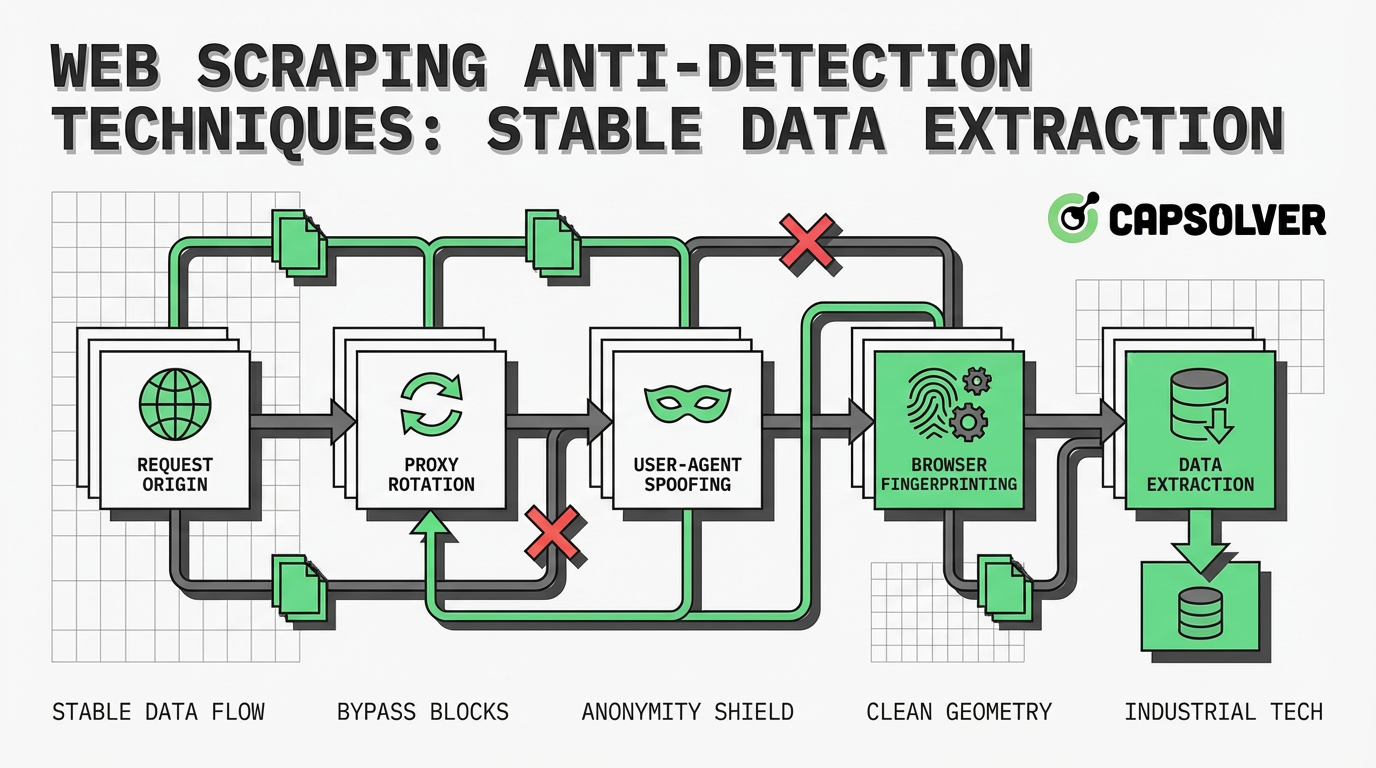
Técnicas Principais de Anti-Deteção no Web Scraping
Para manter a extração de dados estável, os desenvolvedores devem implementar estratégias que contrariem cada camada de defesa do site. Os seguintes métodos formam a base da anti-deteção eficaz.
Implementando Rotação de IPs e Proxies
Depender de um único endereço IP é um caminho garantido para ser bloqueado. Para contornar a limitação de taxa e bloqueios de IP, os scrapers devem usar redes de proxies. Ao rotear as solicitações por diferentes endereços IP, o scraper distribui seu tráfego, fazendo parecer que múltiplos usuários estão acessando o site.
Embora os proxies de datacenter sejam rápidos e econômicos, são facilmente identificados. Para alvos de alta segurança, proxies residenciais são necessários. Esses proxies roteiam o tráfego por dispositivos reais fornecidos por provedores de internet (ISPs), oferecendo um nível muito maior de legitimidade. Para aprender mais sobre gerenciar endereços IP efetivamente, revise este guia sobre como evitar bloqueios de IP.
Otimizando Cabeçalhos HTTP
Criar cabeçalhos HTTP realistas é crucial para evitar filtragem básica. A string User-Agent deve corresponder a um navegador moderno e amplamente usado. No entanto, simplesmente alterar o User-Agent não é suficiente; o perfil completo dos cabeçalhos deve ser consistente.
Por exemplo, se o User-Agent indicar uma máquina Windows, o cabeçalho Sec-Ch-Ua-Platform também deve refletir Windows. Incluir cabeçalhos como Accept, Accept-Encoding e Referer adiciona autenticidade à solicitação. O cabeçalho Referer, que indica a página anterior visitada, pode ser definido como um motor de busca popular para simular tráfego orgânico. Para recomendações detalhadas, consulte este recurso sobre seleção do melhor User-Agent.
Utilizando Navegadores Headless
Muitos sites modernos dependem fortemente do JavaScript para renderizar conteúdo dinamicamente. Clientes HTTP tradicionais não podem executar JavaScript, resultando em extração de dados incompleta. Navegadores headless, como Puppeteer, Playwright ou Selenium, resolvem esse problema ao executar um ambiente de navegador completo sem uma interface gráfica.
Navegadores headless podem executar JavaScript, lidar com conteúdo dinâmico e interagir com a página como um usuário real. No entanto, configurações padrão de headless revelam variáveis identificáveis, como navigator.webdriver = true. Os desenvolvedores devem usar plugins de stealth ou frameworks especializados para mascarar esses indicadores e evitar que o navegador headless seja detectado.
Gerenciando a Frequência das Solicitações
Para vencer a análise de comportamento, os scrapers devem abandonar padrões previsíveis de solicitação. Implementar atrasos aleatórios entre solicitações simula as pausas naturais que um humano faz ao ler ou navegar em um site. Além disso, adicionar movimentos aleatórios do mouse e ações de rolagem dentro de um ambiente de navegador headless pode ajudar a evitar sistemas que monitoram a interação do usuário.
Resumo Comparativo: Detecção vs. Mitigação
| Método de Detecção | Descrição | Estratégia de Mitigação |
|---|---|---|
| Limitação de Taxa de IP | Bloqueio de IPs que ultrapassam um limite de solicitação específico. | Use redes de proxy residenciais ou móveis com rotação. |
| Filtragem de Cabeçalhos | Análise de cabeçalhos HTTP em busca de anomalias ou dados ausentes. | Crie cabeçalhos consistentes e modernos (User-Agent, Referer, Accept). |
| Fingerprinting de Navegador | Identificação de dispositivos com base em traços de hardware e software. | Use navegadores anti-deteção ou plugins de stealth para falsificar fingerprints. |
| Desafios de JavaScript | Requer execução de JS para acessar conteúdo ou verificar o cliente. | Implemente navegadores headless (Playwright, Puppeteer) com configurações de stealth. |
| Armadilhas de Mel | Elementos HTML ocultos projetados para capturar parsers automatizados. | Analise propriedades de visibilidade CSS antes de interagir com elementos. |
Desafios Avançados: CAPTCHAs e Sistemas de Segurança
Mesmo com rotação perfeita de IPs e otimização de cabeçalhos, os scrapers frequentemente encontram CAPTCHAs. Esses desafios são especificamente projetados para diferenciar humanos de bots, exigindo que o usuário resolva enigmas visuais ou analise dados comportamentais complexos.
Sistemas de segurança como Cloudflare Turnstile e DataDome utilizam análise avançada de risco, avaliando a reputação do IP do cliente, o fingerprint TLS e o histórico de interação antes de decidir se apresentar um CAPTCHA. Quando um scraper encontra essas barreiras, a intervenção manual é impossível em escala. É aí que os serviços de resolução automatizada se tornam essenciais para manter o fluxo de dados. Para insights sobre tendências atuais, leia sobre resolver CAPTCHA durante o web scraping 2025.
Automatizando a Resolução de CAPTCHA com CapSolver
Quando as técnicas de anti-deteção de web scraping atingem seus limites, CapSolver oferece uma solução robusta para lidar com CAPTCHAs complexos. O CapSolver é um serviço alimentado por IA que automatiza a resolução de diversos desafios, incluindo reCAPTCHA, Cloudflare Turnstile e quebra de imagens.
Ao integrar o CapSolver à sua arquitetura de scraping, você pode contornar essas interrupções de forma programática. O serviço utiliza modelos avançados de machine learning para analisar e resolver desafios rapidamente e com precisão, garantindo que seus processos de extração de dados permaneçam eficientes e ininterruptos. Essa abordagem é particularmente valiosa ao lidar com tarefas de scraping de alto volume, onde encontrar CAPTCHAs é inevitável.
Use o código
CAP26ao se cadastrar no CapSolver para receber créditos extras!
Exemplo de Integração: Resolvendo reCAPTCHA v2
Integrar o CapSolver a um script de scraping baseado em Python é simples. O exemplo a seguir demonstra como usar a API do CapSolver para resolver um desafio reCAPTCHA v2. Este método utiliza o tipo de tarefa ReCaptchaV2TaskProxyLess, que aproveita a infraestrutura de proxy integrada do CapSolver.
python
import requests
import time
# Configuração
API_KEY = "SUA_CHAVE_API_DO_CAPSOLVER"
SITE_KEY = "6Le-wvkSAAAAAPBMRTvw0Q4Muexq9bi0DJwx_mJ-"
SITE_URL = "https://www.google.com/recaptcha/api2/demo"
def solve_recaptcha():
# Passo 1: Criar a tarefa
payload = {
"clientKey": API_KEY,
"task": {
"type": "ReCaptchaV2TaskProxyLess",
"websiteKey": SITE_KEY,
"websiteURL": SITE_URL
}
}
response = requests.post("https://api.capsolver.com/createTask", json=payload)
task_data = response.json()
task_id = task_data.get("taskId")
if not task_id:
print("Falha ao criar tarefa:", response.text)
return None
print(f"Tarefa criada com sucesso. ID da tarefa: {task_id}")
# Passo 2: Verificar o resultado
while True:
time.sleep(2)
result_payload = {
"clientKey": API_KEY,
"taskId": task_id
}
result_response = requests.post("https://api.capsolver.com/getTaskResult", json=result_payload)
result_data = result_response.json()
status = result_data.get("status")
if status == "ready":
print("CAPTCHA resolvido com sucesso!")
return result_data.get("solution", {}).get("gRecaptchaResponse")
elif status == "failed" or result_data.get("errorId"):
print("Falha ao resolver CAPTCHA:", result_response.text)
return None
# Executar o solucionador
token = solve_recaptcha()
if token:
print(f"Token recebido: {token[:50]}...")
# Proceder para enviar o token ao site alvoPara mais estratégias de implementação detalhadas, explore este guia completo sobre como resolver reCAPTCHA no web scraping usando Python.
Considerações Éticas e Conformidade
Enquanto dominar as técnicas de anti-deteção de web scraping é crucial para o sucesso técnico, deve ser equilibrado com considerações éticas. A extração de dados deve sempre respeitar a infraestrutura do site-alvo e seus termos de serviço.
Os desenvolvedores devem seguir as diretrizes especificadas no arquivo robots.txt, que descreve as áreas permitidas e proibidas para rastreamento. Além disso, implementar limites de taxa razoáveis garante que a atividade de scraping não prejudique o desempenho do site para usuários legítimos. O scraping responsável se concentra em extrair dados públicos sem causar danos ou violar regulamentações de privacidade.
Conclusão
Navegar com sucesso pelos complexos desafios da extração de dados requer compreensão profunda das técnicas de anti-deteção de web scraping. Ao implementar rotação de IPs robusta, otimizar cabeçalhos HTTP e gerenciar fingerprints de navegador, os desenvolvedores podem reduzir significativamente a probabilidade de serem bloqueados. No entanto, à medida que os sistemas de segurança evoluem, enfrentar CAPTCHAs permanece um desafio constante. Integrar soluções automatizadas como CapSolver garante que sua infraestrutura de scraping permaneça resiliente, permitindo coleta de dados estável e contínua em um ambiente digital cada vez mais restritivo.
Perguntas Frequentes
Quais são as técnicas mais comuns de anti-deteção no web scraping?
As técnicas mais comuns incluem a rotação de IPs usando redes de proxy, falsificação de cabeçalhos HTTP (especialmente o User-Agent), uso de navegadores headless com plugins de stealth e implementação de atrasos aleatórios entre solicitações para imitar o comportamento humano.
Os sites bloqueiam raspadores para proteger seus recursos do servidor contra sobrecarga causada por tráfego automatizado, para proteger dados proprietários ou protegidos por direitos autorais e para impedir que concorrentes monitorem seus preços ou estratégias de conteúdo. De acordo com Cloudflare, bots maliciosos podem consumir largura de banda significativa e degradar a experiência do usuário.
Como a fingerprinting de navegador funciona na detecção de bots?
A fingerprinting de navegador coleta detalhes específicos sobre o dispositivo do usuário, como resolução da tela, sistema operacional, fontes instaladas e capacidades do hardware. Ao combinar esses pontos de dados, os sistemas de segurança criam um identificador único que pode rastrear e bloquear raspadores mesmo se eles mudarem seu endereço IP ou limparem seus cookies.
Os navegadores headless podem contornar todos os sistemas de detecção?
Não. Embora navegadores headless possam executar JavaScript e lidar com conteúdo dinâmico, configurações padrão são facilmente detectadas por sistemas avançados de segurança como a DataDome, que analisam técnicas de detecção de bots, incluindo variáveis WebDriver. Os desenvolvedores devem usar modificações stealth para ocultar a natureza automatizada do navegador.
Como devo lidar com CAPTCHAs durante a extração de dados?
Ao encontrar CAPTCHAs, a abordagem mais eficiente para raspagem em larga escala é integrar uma API de resolução automatizada, como a CapSolver. Esses serviços usam aprendizado de máquina para resolver desafios de forma programática, permitindo que o script de raspagem continue sua operação sem intervenção manual.
Ver mais
Web ScrapingApr 22, 2026
Arquitetura de Web Scraping em Rust para Extração de Dados Escalável
Aprenda arquitetura de raspagem web escalável em Rust com reqwest, scraper, raspagem assíncrona, raspagem de navegador headless, rotação de proxies e tratamento de CAPTCHA compatível.

Web ScrapingApr 08, 2026
Selenium vs Puppeteer para Resolução de CAPTCHA: Comparação de Desempenho e Caso de Uso
Compare o Selenium vs Puppeteer para resolver CAPTCHA. Descubra benchmarks de desempenho, notas de estabilidade e como integrar o CapSolver para o máximo de sucesso.

