Como a Extração de Dados por IA Funciona: Resolução de CAPTCHA, Análise de Modelos de Linguagem de Grande Escala e Pipelines de Dados Estruturados da Web

Adélia Cruz
Neural Network Developer
Introdução: Além da Parsagem, Trata-se da Aquisição
A extração de dados da web tradicional depende de métodos de correspondência mecânica, como seletores CSS, XPath e expressões regulares, que se fixam em posições fixas na árvore DOM para recuperar valores. Diante de redesigns frequentes das páginas, adoção generalizada de renderização dinâmica e atualizações de anti-scraping em camadas, esse paradigma expôs fraquezas estruturais, como altos custos de manutenção e "cegueira" ao conteúdo assíncrono. A maturidade dos modelos de linguagem grandes (LLMs) traz uma virada: a extração de dados já não pergunta "em qual tag os dados estão localizados?", mas sim "qual pergunta o conteúdo da página responde?", entrando em um novo paradigma impulsionado pelo entendimento de linguagem natural. Essa mudança não é puramente teórica; frameworks como AXE, ao podar nós DOM irrelevantes e combinar com modelos menores para gerar saída estruturada, superaram modelos maiores com uma pontuação F1 de 88,1% no conjunto de dados SWDE, validando a viabilidade e eficiência da extração semântica. Este artigo, do ponto de vista da implementação técnica, deconstrói os princípios técnicos e os principais trade-offs de cada etapa de acordo com a sequência do fluxo de dados, desde a camada de aquisição de dados lidando com anti-crawlers e CAPTCHAs, até a camada de processamento de limpeza de conteúdo e extração semântica de LLM, finalmente chegando ao armazenamento e consumo de dados estruturados.
I. Mudança de Paradigma: Da Parsagem Baseada em Regras para o Processamento de Linguagem Natural
Antes de mergulhar nos detalhes técnicos da extração de dados com IA, é necessário compreender por que o paradigma antigo que substituiu atingiu seus limites e em que dimensão o novo paradigma alcançou uma ruptura.
1.1 Três Dilemas da Era da Parsagem Baseada em Regras
O método central da extração de dados da web tradicional é "posicionamento por caminho": os desenvolvedores inspecionam o nó DOM onde os dados alvo estão localizados usando ferramentas de desenvolvedor do navegador e, em seguida, escrevem manualmente seletores CSS ou expressões XPath para apontar esse nó. Esse paradigma suportou a maioria das necessidades de coleta de dados da web nas últimas décadas, mas possui três falhas estruturais que continuamente se ampliaram com a evolução da tecnologia da web.
1.1.1 Âncoras Frágeis: Regras Estáticas Incapazes de se Adaptar a um Mundo Dinâmico
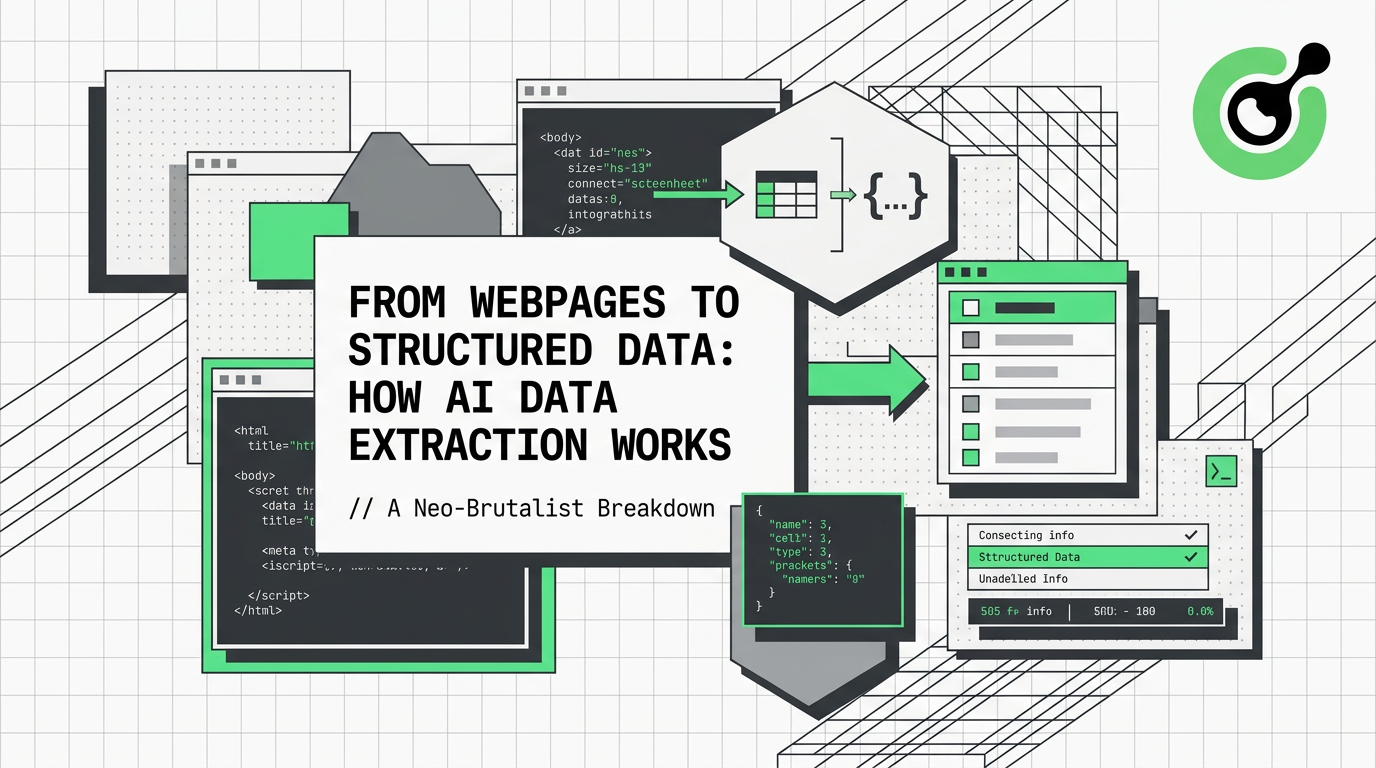
Sites modernos sofrem mudanças significativas na estrutura DOM a cada 3 a 6 meses, em média. Cada redesign significa que as regras de crawlers baseadas em caminhos fixos tornam-se inválidas. Para equipes que mantêm centenas de nós alvo simultaneamente, isso constitui um ciclo contínuo de "whack-a-mole" de manutenção. A Figura 1-1 ilustra o fluxo completo de crawlers tradicionais ao enfrentar sites modernos, mostrando cada etapa desde a requisição até a extração de dados e os problemas encontrados:
Este processo revela a lógica central do primeiro dilema: a incompatibilidade entre capacidades de análise estáticas e conteúdo renderizado dinamicamente. Segundo estatísticas do W3Techs, até o final de 2025, aproximadamente X% dos sites globais usarão serviços de anti-scraping como Cloudflare. Com base na detecção simultânea da Netcraft do número total de sites, isso envolve mais de 290 milhões de sites, e o tamanho médio de JS das páginas da web ultrapassa 500KB. Crawler tradicionais só conseguem obter o esqueleto não renderizado, não apenas "não vendo dados", mas também, assim que o site for redesenhado, os seletores cuidadosamente escritos tornam-se imediatamente inválidos. Essa "incapacidade técnica" e "fragilidade de manutenção" se sobrepõem, continuamente reduzindo o escopo da parsagem baseada em regras.
1.1.2 Olhos Cegos: Correspondência Sintática que Falha Completamente em Compreender a Semântica
Métodos tradicionais só podem responder "os dados estão nessa posição", não "o que são os dados nessa posição?". Em mesma página de listagem de produtos, podem haver preços promocionais, preços recomendados e preços de produtos simultaneamente – eles têm tags idênticas na DOM, tornando impossível para regras tradicionais distingui-los. Diante de três formatos heterogêneos de data, como "2026-04-28", "April 28, 2026" e "28/04/2026", os parsers tradicionais precisam escrever expressões regulares separadas para cada formato e não conseguem lidar com mudanças dinâmicas no formato. A Figura 1-2 usa um gráfico de radar para comparar visualmente as diferenças entre a parsagem baseada em regras tradicional e a extração semântica de IA em seis dimensões centrais:
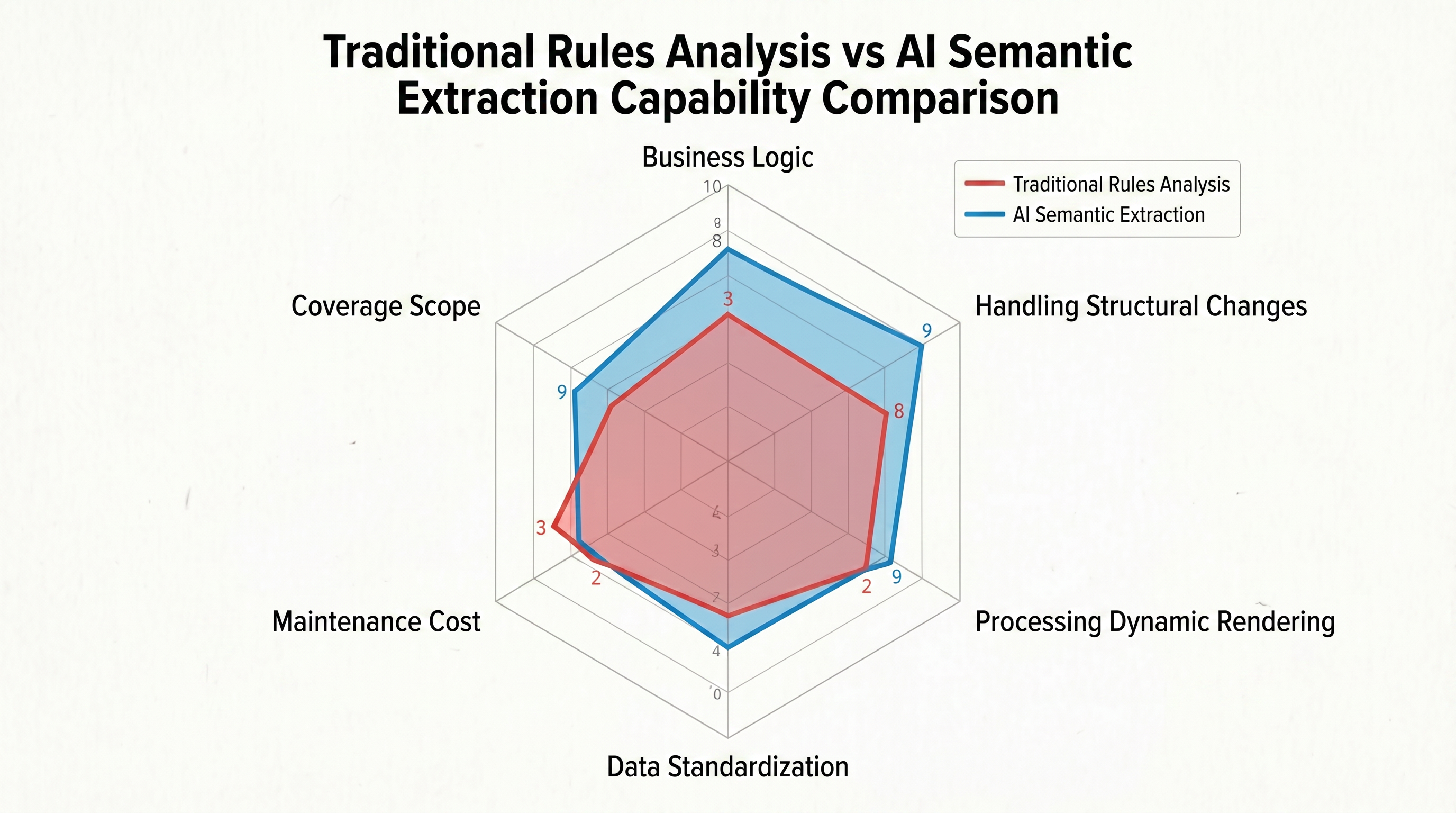
A forma do gráfico de radar revela claramente que a parsagem baseada em regras tradicional depende do posicionamento preciso de caminhos DOM na dimensão "lógica de trabalho", que é sua única estratégia executável. No entanto, em outras cinco dimensões, seu desempenho é restrito de forma abrangente – sua capacidade de se adaptar a mudanças estruturais é extremamente fraca, o processamento de renderização dinâmica depende totalmente de ferramentas externas, a padronização de dados requer a escrita manual de expressões regulares, os custos de manutenção aumentam linearmente com o número de sites e sua cobertura é limitada a um conjunto de regras por site. Cinco dos seis eixos estão profundamente retraídos, e o gráfico parece um polígono irregular "comprimido".
Em contraste, o gráfico de radar para a extração semântica de IA expande-se uniformemente interna e externamente: ela se adapta automaticamente às mudanças estruturais com base no entendimento semântico, processa totalmente a renderização dinâmica com o navegador, alcança padronização sem regras por meio das capacidades internas de conversão de formato dos LLMs, os custos de manutenção diminuem com o aumento das capacidades do modelo e um único Schema pode cobrir páginas semelhantes em toda uma site.
Cada uma dessas seis limitações de capacidade não é um gargalo técnico isolado, mas uma consequência natural da lógica subjacente de "correspondência mecânica" – enquanto a extração de dados permanecer no nível sintático, não importa quão bem projetadas as regras sejam, essa limitação estrutural não pode ser superada. Portanto, para resolver esses problemas de forma abrangente, o que é necessário não é consertar as regras, mas mudar o paradigma.
1.1.3 O Teto Tangível: Por Que Esse Paradigma é Destinado a Ser Substituído
Todos os dilemas do paradigma de parsagem baseada em regras surgem de uma fonte: ele sempre realiza "correspondência mecânica" no "nível sintático". Essa lógica de trabalho determina sua capacidade de "posicionamento preciso" – encontrar com precisão o caminho DOM dos dados – mas ao custo de "adaptação passiva" a cada mudança na estrutura da página. Se o site for redesenhado, as regras se tornam inválidas; se os tipos de dados forem heterogêneos, novas expressões regulares precisam ser escritas manualmente. Esse modo de ser guiado pelo site alvo constitui um "teto estrutural" que a parsagem baseada em regras não pode superar. A Figura 1-3 antecipa a direção fundamental da evolução desse paradigma em forma de evolução comparativa.
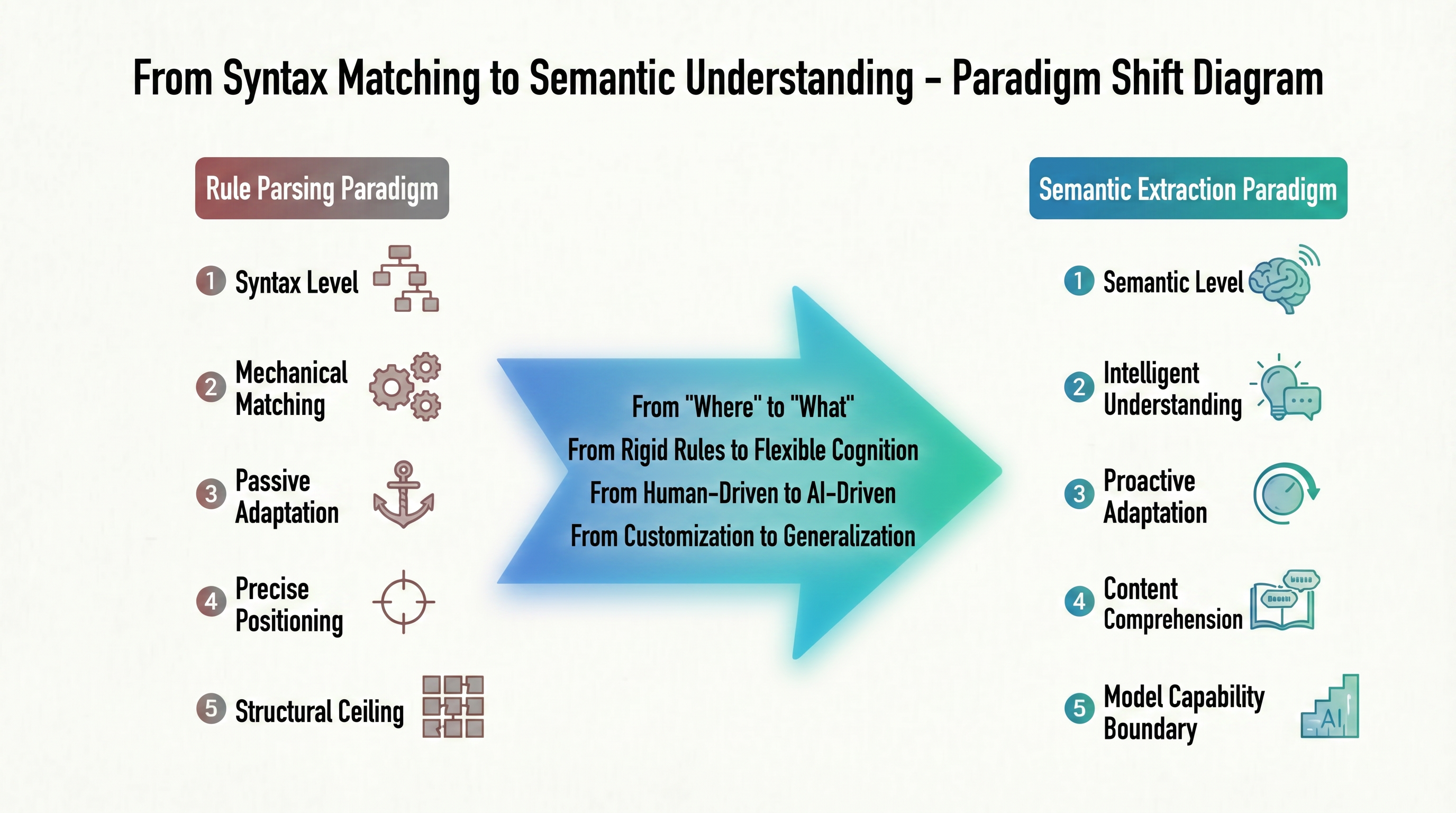
Da figura acima, fica claro que não se trata de uma melhoria técnica ao longo do mesmo caminho, mas de dois caminhos fundamentalmente diferentes. O paradigma de parsagem baseada em regras à esquerda é construído no "nível sintático", visando "posicionamento preciso", adaptando-se passivamente às mudanças estruturais e rapidamente atingindo um "teto estrutural" – é como uma pessoa que sabe que um trecho em um livro está na página 3, linha 5, mas não tem ideia do que o trecho significa. O paradigma de extração semântica à direita muda fundamentalmente o nível de trabalho: do "sintaxe" para "semântica", da "correspondência mecânica" para "entendimento inteligente". Seu objetivo já não é localizar coordenadas de nó, mas compreender diretamente o conteúdo da página, e seus limites de capacidade já não são determinados pelas mudanças DOM.
Isso também explica por que os três dilemas da era da parsagem baseada em regras não são problemas independentes, mas manifestações diferentes da lógica subjacente de "correspondência sintática". Enquanto a tecnologia de extração de dados permanecer no nível sintático, não importa quão elaboradas as regras sejam, não será possível superar o paradoxo estrutural de "posicionamento preciso" e "pontos cegos semânticos". Portanto, o surgimento do paradigma de extração semântica de IA não é uma aceleração no velho caminho, mas uma revolução no nível cognitivo, da "busca por posições" para "compreensão de conteúdo". Os mecanismos específicos e vantagens desse deslocamento de paradigma serão explicados na Seção 1.2.
1.2 Paradigma de IA: Da Correspondência Sintática para o Entendimento Semântico
Métodos impulsionados por IA redefinem completamente como os problemas são abordados. A Figura 1-4 compara as diferenças fundamentais entre os paradigmas de parsagem baseada em regras e semântica de IA em quatro dimensões: problema central, fatores dependentes, adaptação às mudanças e modo de expansão:
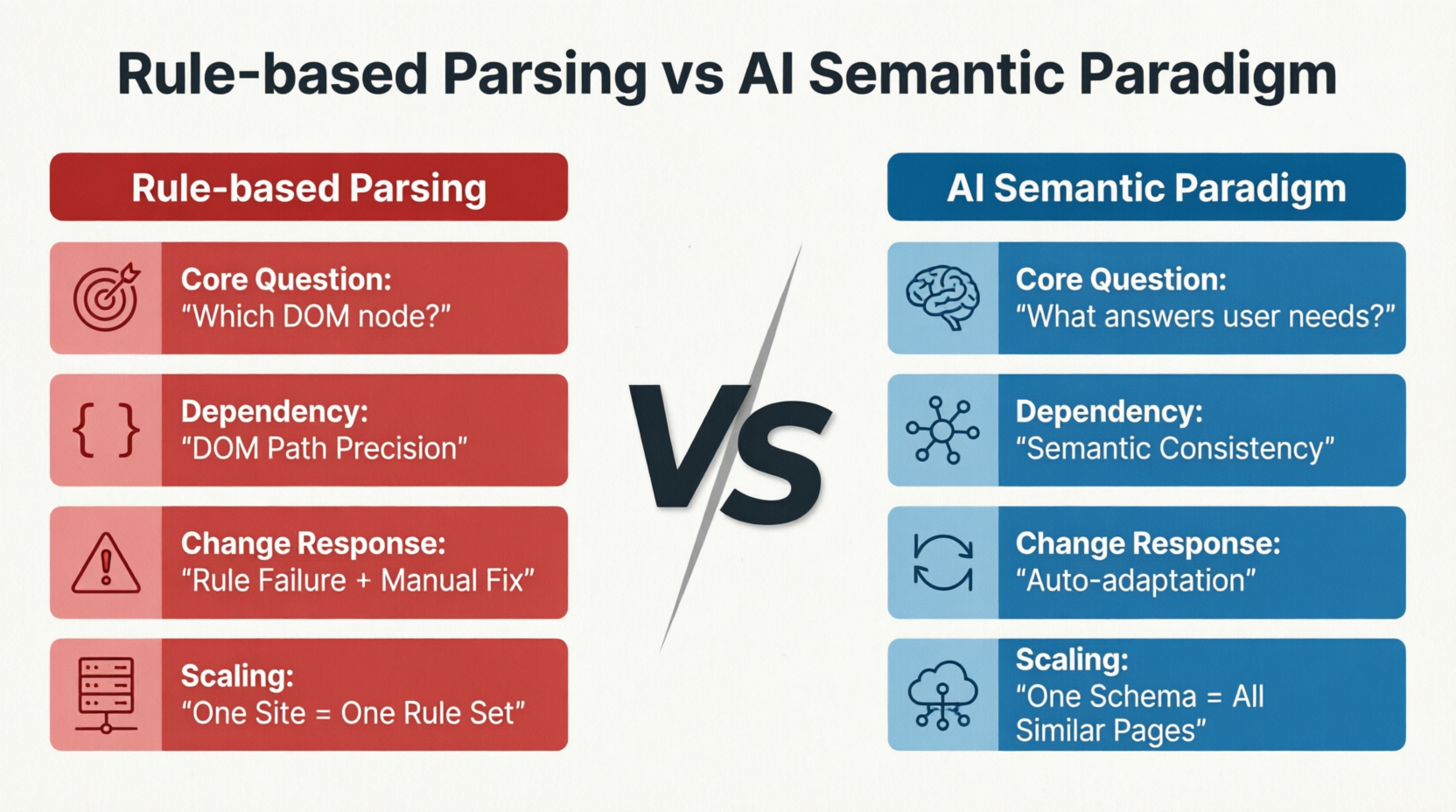
Métodos tradicionais perguntam "onde estão os dados no nó DOM?", enquanto métodos de IA perguntam "qual conteúdo na página é a informação central de interesse do usuário?". Essa diferença na pergunta determina a divergência de todas as rotas técnicas subsequentes: o primeiro depende da precisão dos caminhos DOM, e assim que a página for redesenhada ou os nós se moverem, as regras tornam-se inválidas e precisam ser reparadas manualmente; o segundo depende da consistência da semântica da página. As estruturas DOM podem mudar e as posições dos dados podem se mover, mas desde que o conteúdo semântico permaneça inalterado, o modelo ainda pode identificar e extrair corretamente. Em termos de modo de expansão, a parsagem baseada em regras requer a reescrita de um conjunto de regras para cada novo site, enquanto o paradigma semântico de IA pode cobrir horizontalmente páginas semelhantes em toda uma site com o mesmo Schema.
É essa mudança do "posicionamento sintático preciso" para o "entendimento semântico difuso" que dá aos métodos de IA a robustez que as regras tradicionais carecem. O framework AXE proposto pela academia fornece o exemplo mais claro de engenharia dessa mudança de paradigma. A Figura 1-5 resume seu fluxo de processamento central:
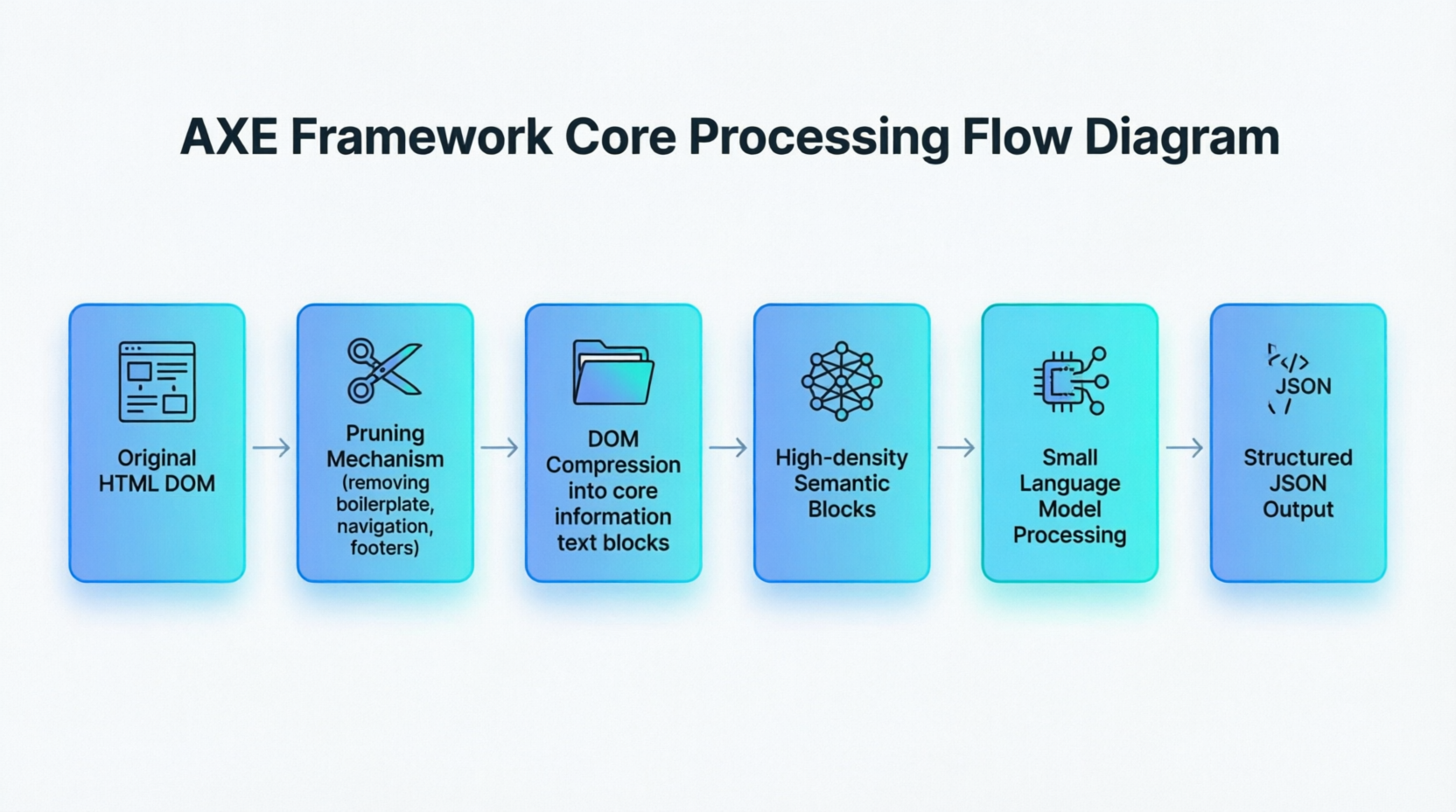
A Figura 1-5 mostra uma cadeia completa do HTML bruto até a saída estruturada: o AXE trata a árvore DOM HTML como uma árvore que precisa ser podada, removendo nós irrelevantes, como barras de navegação, rodapés e código de boilerplate, por meio de um mecanismo especializado de poda; em seguida, a DOM é comprimida em alguns blocos semânticos de alta densidade contendo informações principais; finalmente, um pequeno modelo leve lê esses blocos semânticos para gerar saída JSON estruturada. O processo inteiro evita o posicionamento de caminhos DOM que os métodos tradicionais precisam depender, atuando diretamente no conteúdo semântico da página.
No conjunto de dados SWDE, que abrange 8 domínios verticais e mais de 80 sites reais, o AXE alcançou uma pontuação F1 de 88,1%, superando múltiplos modelos muito maiores do que ele. Esse resultado prova um fato contraintuitivo, mas crucial: a capacidade de extração semântica não depende de modelos gigantes; um modelo miniatura bem projetado e treinado especificamente também pode alcançar precisão de produção. Este é o evidência central de que o paradigma semântico de IA é competitivo em termos de custo e viabilidade de engenharia.
Outra obra representativa, Dripper, toma uma rota técnica diferente, redefinindo a extração de conteúdo principal como uma tarefa de "classificação de sequência de blocos semânticos". A Figura 1-6 usa uma comparação de cartões para juxtapor as diferenças nos métodos entre AXE e Dripper, bem como a evolução dos modos de operação e manutenção entre a era das regras e a era da IA:
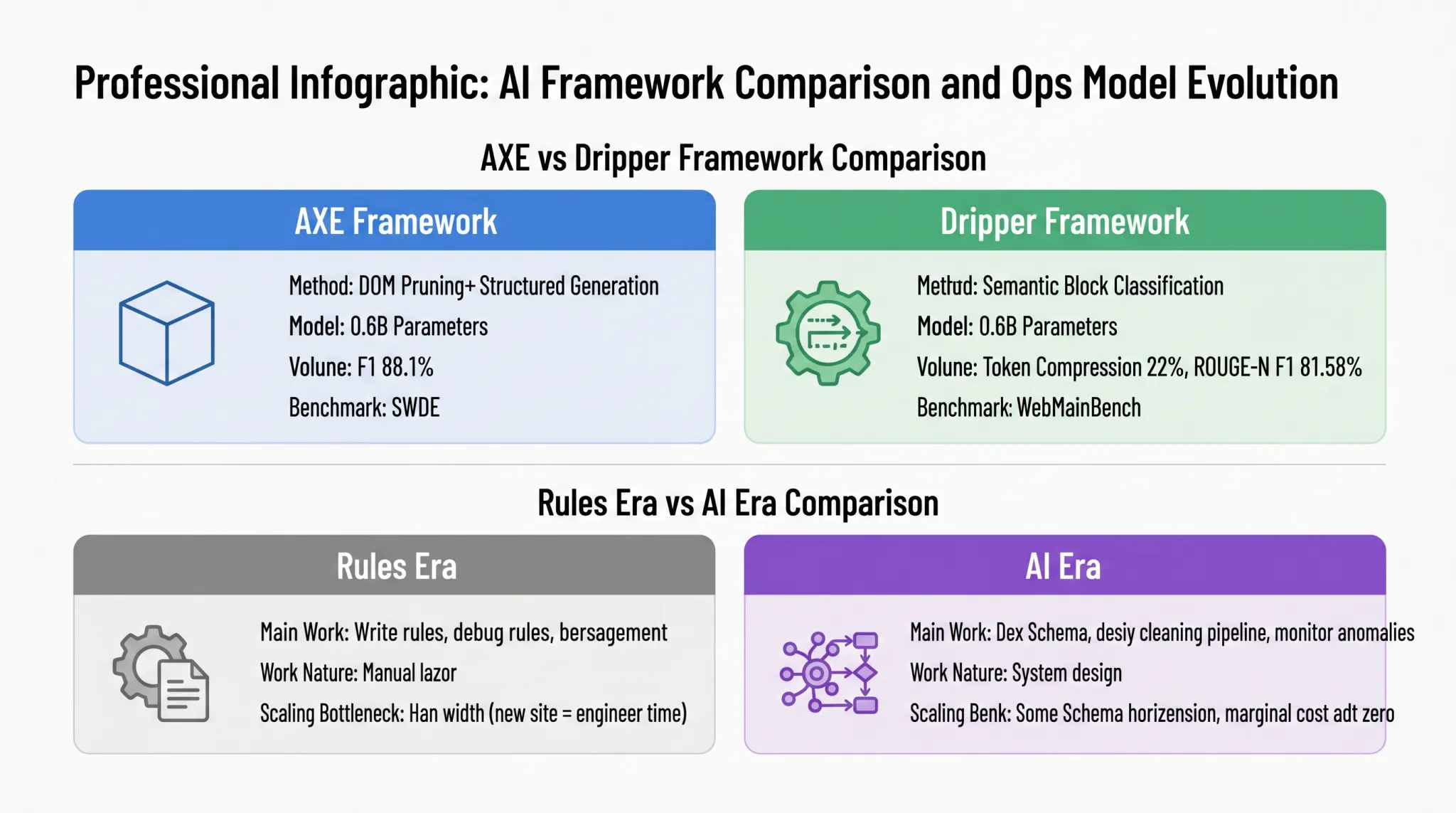
O AXE adota o caminho "podagem da DOM + geração estruturada", comprimindo a DOM HTML em blocos semânticos de alta densidade e, em seguida, gerando saída JSON diretamente por meio de um pequeno modelo; o Dripper adota a rota "classificação binária de blocos semânticos", transformando a extração de conteúdo principal em uma tarefa de classificação que determina se cada bloco semântico pertence ao texto principal. Ambos os modelos têm uma escala semelhante de 0,6B de parâmetros e alcançaram precisão pronta para produção em seus respectivos benchmarks. O AXE alcançou uma pontuação F1 de 88,1% no conjunto de dados SWDE, enquanto o Dripper reduziu os tokens de entrada para 22% do HTML original e alcançou uma pontuação F1 ROUGE-N de 81,58% no WebMainBench. Essas duas rotas diferentes apontam para a mesma conclusão: a extração de dados de IA é competitiva em precisão e não depende de modelos gigantes; um modelo miniatura bem projetado também pode ser competente.
A metade direita revela um significado mais profundo da mudança de paradigma: não apenas muda a rota técnica, mas também reconstrói o modo diário de operação das equipes de dados. O trabalho principal na era das regras era escrever regras, corrigir regras e gerenciar versões, o que era essencialmente trabalho manual. O gargalo para a expansão estava na capacidade humana: toda vez que um novo site alvo era adicionado, o tempo dos engenheiros tinha que ser investido para reescrever e depurar as regras. Na era da IA, o foco do trabalho muda para definir Schemas, projetar pipelines de limpeza e monitorar casos anormais. A natureza muda de trabalho manual para design de sistema, e o modo de expansão também muda de "um conjunto de regras por site" para "expansão horizontal com o mesmo Schema". Adicionar sites semelhantes exige quase nenhum investimento adicional em engenharia, e o custo marginal se aproxima de zero. Essa mudança libera as capacidades de extração de dados da limitação da capacidade humana, redefinindo a economia da coleta de dados.
II. Processo Central da Extração de Dados Estruturados com IA
O pipeline completo de extração de dados de IA inclui 7 etapas, que podem ser divididas em três grupos funcionais:
- Camada de Aquisição de Dados (Fila de URLs → Web Scraping → Detecção de Anti-Scraping): Responsável por "obter" o HTML da página de destino em um ambiente de rede complexo. Esta é a zona de maior risco do Pipeline inteiro, com o gargalo principal de 14% indicado na Figura 2-2 apontando para esta camada.
- Camada de Processamento de Conteúdo (Limpeza de Conteúdo → Análise por LLM → Validação de Esquema): Responsável por transformar o HTML bruto ruidoso em dados estruturados de alta qualidade. O gargalo de precisão (18%) está principalmente concentrado na etapa de limpeza de conteúdo desta camada.
- Camada de Armazenamento de Dados (Armazenamento de Dados): A saída final para consumo posterior, representando cerca de 5% da carga total do link.
Este capítulo se concentrará nos detalhes técnicos da Camada 2, a camada de processamento de conteúdo, demonstrando como a extração semântica de IA supera fundamentalmente os motores de regras tradicionais. Para a Camada 1, o pré-requisito crítico que determina se os dados podem fluir para a camada de processamento, realizaremos uma análise dedicada e discussão de soluções práticas no Capítulo 3.
2.1 Pipeline de Extração de Dados de IA
Antes de mergulhar na camada de processamento, vamos obter uma visão geral do Pipeline inteiro por meio da Figura 2-1 para entender o caminho completo da fila de URLs ao armazenamento de dados e a distribuição real do tráfego em cada etapa. Isso serve como uma visão geral para este capítulo e estabelece a base para lidar com gargalos no Capítulo 3.

A fila de URLs é o ponto de entrada do Pipeline, gerenciando a lista de URLs a serem raspadas e controlando o ritmo das solicitações. Como mostrado na Figura 2-1, aproximadamente 32% das solicitações na fase de agendamento de URLs já são marcadas previamente com riscos de CAPTCHA, enquanto 68% podem iniciar solicitações normais diretamente. A fase de raspagem da web é responsável por iniciar solicitações HTTP ou acionar a renderização do navegador para obter o conteúdo bruto da página. Neste momento, 12% das solicitações serão diretamente interceptadas por CAPTCHAs, e 80% poderão entrar suavemente nas etapas posteriores.
Após a raspagem inicial, as solicitações entram na fase de detecção de anti-scraping. Sistemas modernos de anti-scraping analisam simultaneamente sinais de quatro dimensões: reputação de IP, impressão digital TLS, características do navegador e padrões de comportamento, realizando validação cruzada em múltiplas camadas. A Figura 2-1 mostra que aproximadamente 10% do tráfego na fase de detecção de anti-scraping serão identificados como solicitações automatizadas e interceptados, e 20% exigem dependência de pools de IPs e falsificação de impressão digital TLS para evitar a detecção. Este é o nó mais incerto do Pipeline inteiro. Se um CAPTCHA for acionado e não for tratado, todos os recursos computacionais das etapas subsequentes ficarão ociosos.
Após passar pela detecção de anti-scraping, o conteúdo HTML bruto é obtido. O HTML bruto de uma página de notícias típica pode ultrapassar 2MB, atingindo 300.000 a 500.000 tokens após o processamento com o tokenizer tiktoken da OpenAI, repleto de menus de navegação, CSS embutido, pixels de rastreamento codificados em Base64 e JavaScript comprimido. Portanto, a limpeza de conteúdo é um passo essencial. A Figura 2-1 mostra que a conversão de HTML para Markdown representa 50% do trabalho nesta etapa, e a simplificação do DOM e a remoção de ruídos representam 30%. Esses dois juntos comprimem o HTML bruto em texto semântico de alta densidade, garantindo que a potência computacional eficaz do LLM esteja focada em informações, não em ruídos.
O texto limpo entra na fase de análise por LLM, onde o modelo extrai campos estruturados do texto de acordo com um Esquema pré-definido. A Figura 2-1 combina esta etapa com a validação de Esquema subsequente, mostrando uma taxa de precisão de 94,7%. Isso significa que aproximadamente 1 em cada 20 extrações falhará em passar por verificações de completude de campo ou consistência de formato. As saídas bem-sucedidas se tornam dados JSON estruturados, que são finalmente armazenados em sistemas como PostgreSQL ou MongoDB para consumo por negócios downstream.
Para decompor mais claramente os meios técnicos, indicadores de desempenho e gargalos de engenharia de cada etapa, a Figura 2-2 apresenta uma visão panorâmica na forma de um painel:
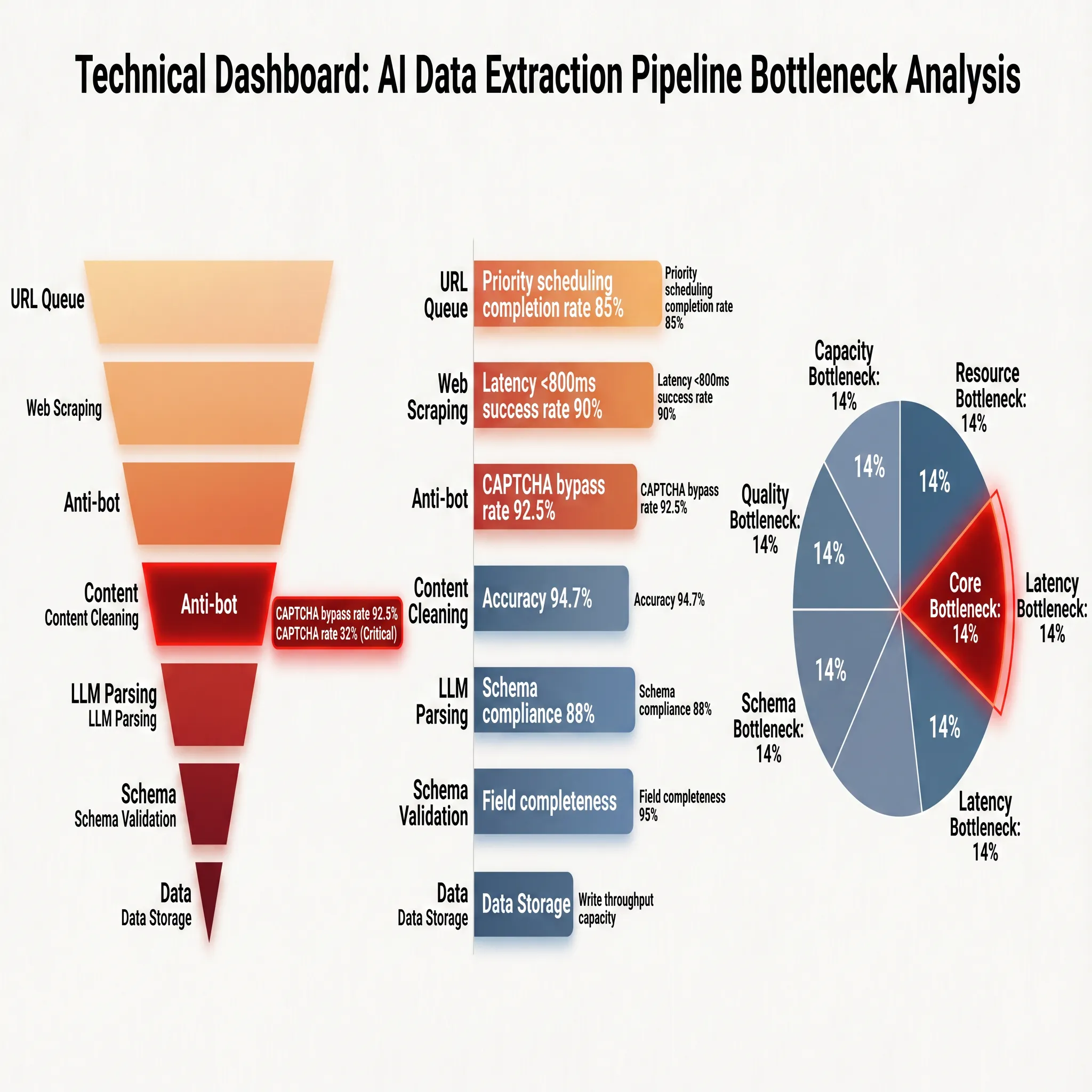
Os indicadores de desempenho do lado direito da figura revelam os limites operacionais reais de cada etapa: a taxa de realização da priorização de agendamento da fila de URLs é de 85%, significando que aproximadamente 15% das tarefas são atrasadas ou degradadas devido a contenção de agendamento; a raspagem da web alcança uma taxa de sucesso de 90% sob uma restrição de latência inferior a 800ms, claramente mostrando os limites dos recursos de rede e renderização; o mecanismo de anti-scraping tem uma taxa de precisão de 94,7%, significando que aproximadamente 5 em cada 100 solicitações são interceptadas ou acionam verificação; após a limpeza de conteúdo, a taxa de conformidade com o Esquema é de 88% e a completude de campo é de 95%. Esses dois indicadores definem o ponto de partida da qualidade dos dados, com aproximadamente 12% das páginas tendo desvios na identificação do conteúdo principal e 5% dos campos exigidos ausentes.
A parte inferior da Figura 2-2 indica diretamente a distribuição dos gargalos: o gargalo principal aponta para o mecanismo de anti-scraping (14%), o gargalo de precisão aponta para a limpeza de conteúdo (18%), os gargalos de capacidade apontam respectivamente para as etapas de agendamento de URLs e raspagem da web, e o gargalo de custo recai sobre a sobrecarga de inspeção de qualidade da validação de Esquema. Esses dados estão altamente alinhados com a análise acima. A detecção de anti-scraping é o "gargalo" da cadeia inteira; uma vez que uma estratégia de anti-scraping seja acionada e não possa ser efetivamente contornada, independentemente da alta precisão das etapas subsequentes, todas falharão devido à falta de dados de entrada. Isso é consistente com o problema central dos roteadores baseados em regras tradicionais: na era da extração semântica de IA, o teto de precisão foi significativamente elevado, mas o "qualificador de entrada" para aquisição de dados permanece o primeiro obstáculo para a implementação de engenharia. Por esse motivo, o Capítulo 3 discutirá especificamente a evolução da tecnologia de confronto de anti-scraping e medidas de contramedida.
2.2 Limpeza de Conteúdo: Do HTML Ruidoso ao Texto Legível pelo LLM
Alimentar diretamente o HTML bruto aos LLMs para extração estruturada é extremamente ineficiente em engenharia. O mecanismo de atenção dos LLMs pode ser distraído pelo código de boilerplate do DOM, como o aninhamento profundo de tags <div>, estilos embutidos CSS, scripts de rastreamento, menus de navegação e links de rodapé. Esses elementos não fornecem nenhum valor semântico e drasticamente aumentam o consumo de tokens. Em cenários de grande escala que processam milhares de páginas por dia, esse desperdício rapidamente se torna financeiramente insustentável. A composição do HTML de uma página de notícias típica ilustra intuitivamente a gravidade do problema. A Figura 2-3 apresenta a proporção da informação efetiva em relação aos diversos ruídos no HTML bruto em um gráfico circular:
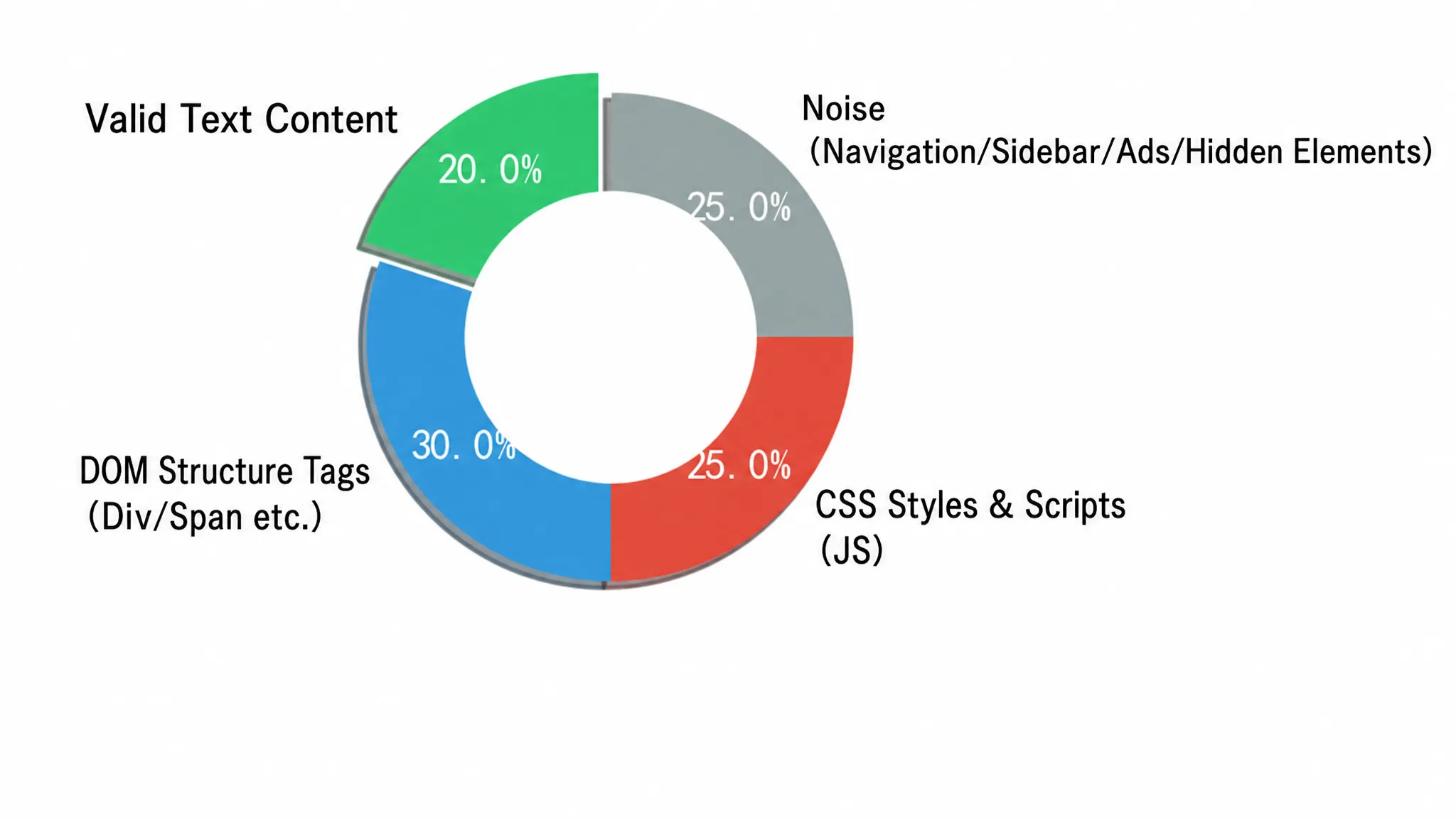
O gráfico circular divide o HTML bruto em quatro áreas. A parte verde (45%) é o conteúdo efetivo da seção principal, incluindo texto e imagens—este é o sinal que o LLM realmente precisa. A parte amarela (20%) é ruído estrutural e de estilo, ou seja, tags <script>, <style>, <svg>; a parte azul (20%) são navegação e barras laterais; a parte vermelha (15%) são anúncios e rastreadores. As três partes de ruído combinadas ultrapassam 55%, significando que mais da metade dos tokens enviados ao LLM são cobrados sem contribuir com nenhum valor semântico.
Essa realidade de "sinal submerso no ruído" deu origem a uma estratégia progressiva de limpeza em três camadas. A Figura 2-4 mostra a cadeia completa de processamento do HTML bruto ao texto legível pelo LLM:
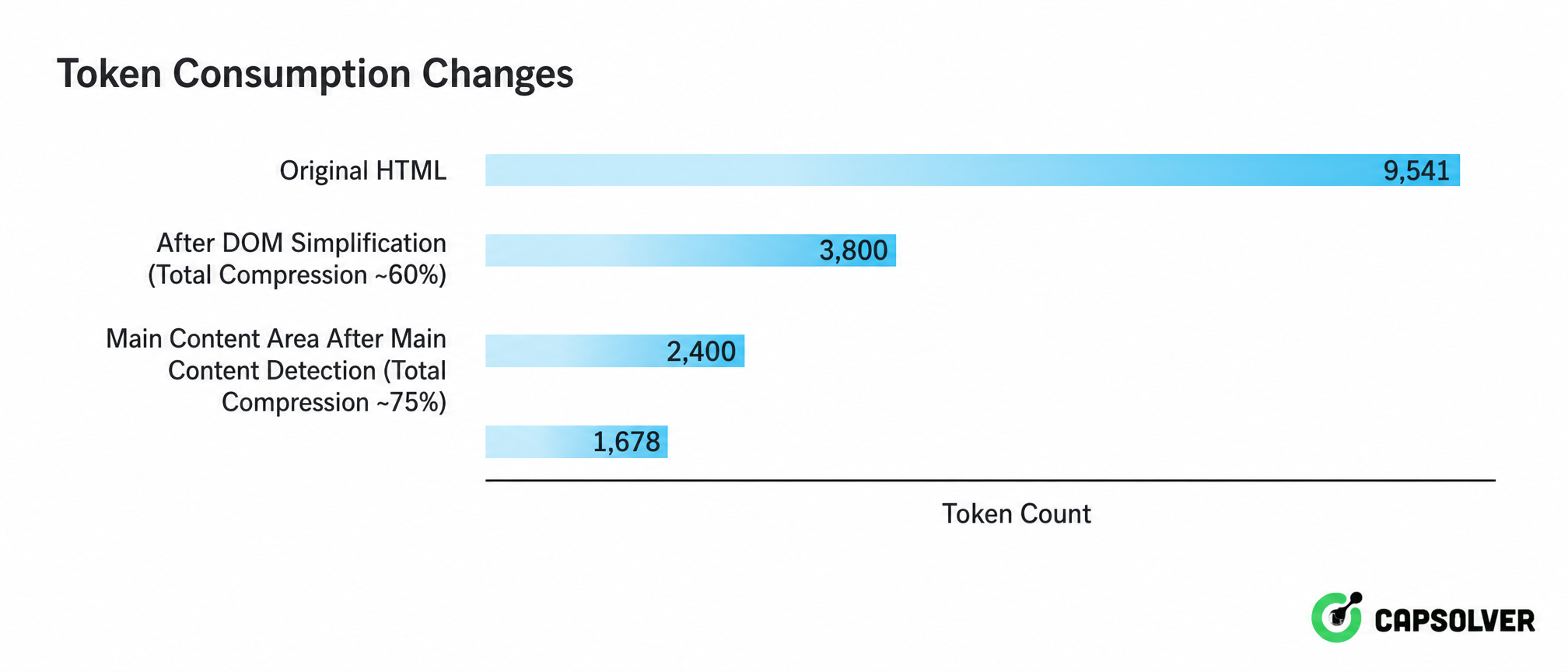
Do ponto de vista da visão, é claramente visível que as três camadas de limpeza comprimem tokens de 9.541 para 1.678, apenas 18% do HTML original. Essa taxa de compressão significa que em processamento em grande escala, os custos de chamada de API podem ser reduzidos para menos de um quinto do original, e a redução de contexto de 10-100 vezes alcançada pelo filtro de contexto semântico garante que a atenção do LLM esteja focada em sinais, não em ruídos. Isso é uma parte indispensável da implementação de engenharia da extração de dados de IA.
2.3 Análise por LLM e Validação de Esquema: Do Texto à Dados Estruturados
O texto em Markdown, limpo por meio da limpeza de conteúdo, entra na fase de análise por LLM, com o objetivo de gerar JSON estruturado que obedeça estritamente a um Esquema pré-definido. Dependendo do cenário, atualmente existem três caminhos técnicos principais disponíveis. O primeiro caminho usa modelos grandes gerais como GPT-4o, que, com uma janela de contexto de 128K, oferece a velocidade de inferência mais rápida e a pontuação de qualidade mais alta, mas com custo moderado, adequado para verificação rápida de protótipos com poucos campos e formatos simples. O segundo caminho emprega modelos especializados baseados em Esquema como Schematron-3B, executando em implantação em servidor compacto, com velocidade média-alta e pontuação de qualidade apenas ligeiramente atrás dos modelos grandes gerais por 0,12 pontos, enquanto reduz os custos para a camada mais baixa, tornando-se a escolha ideal para cenários de produção em grande escala. O terceiro caminho utiliza modelos de linguagem multimodais para construir arquiteturas híbridas, analisando simultaneamente capturas de tela e HTML, capazes de lidar com páginas altamente dinâmicas interativas, como rolagem infinita e pop-ups modais, mas com velocidade média, custo mais alto e pontuação de qualidade relativamente mais baixa, tornando-se quase a única rota viável para cenários interativos complexos. Independentemente do caminho escolhido, o JSON estruturado inicialmente gerado deve passar por três camadas de validação de Esquema—completude de campo, conformidade de tipo e consistência de formato—antes de ser emitido como dados finais. A Figura 2-5 ilustra a relação completa entre esses três caminhos e a validação de Esquema tanto do ponto de vista da cadeia de processos quanto dos principais indicadores.

A matriz claramente mostra um fato de engenharia contraintuitivo, mas crucial: o maior modelo nem sempre é a solução ideal. O Schematron-3B, com apenas 3B parâmetros, se aproxima da pontuação de qualidade dos modelos grandes como o GPT-4o, enquanto reduz significativamente os custos. Quando o processamento atinge uma escala de um milhão de páginas por dia, seu custo de inferência é apenas cerca de 1/80 do dos modelos grandes gerais, o que constitui um ponto crucial de transição de "tecnicamente viável" para "comercialmente lucrativo". Embora o Webscraper+MLLM tenha o custo mais alto e a pontuação de qualidade relativamente mais baixa, é quase a única rota viável para cenários altamente dinâmicos interativos, o que confirma um princípio: a correção da seleção de tecnologia depende das restrições do cenário, não de valores absolutos de métricas.
A validação de Esquema é o último ponto de verificação para garantir a utilidade dos dados. Entre eles, as verificações de consistência de formato são particularmente importantes para campos como datas, moedas e números de telefone. Soluções tradicionais com expressões regulares exigem a escrita manual de regras para cada variante de entrada, enquanto as capacidades internas de conversão de formato dos LLMs podem alcançar padronização com zero regras. Em termos de precisão, o framework AXE alcançou uma pontuação F1 de 88,1% no conjunto de dados SWDE. Experiências em ambientes de produção real mostram que buscar 90% de precisão de extração automatizada combinada com um caminho de revisão rápida manual é uma estratégia de engenharia mais pragmática do que perseguir obstinadamente 100% de precisão teórica a custos dezenas de vezes maiores. A posição dessa linha de compromisso depende do cálculo específico de cada equipe sobre "continuidade de dados" e "teto de orçamento", mas está claro que a precisão moderada é mais viável comercialmente.
III. Os Três Portões da Extração de Dados de IA: Anti-Scraping, Quebra de CAPTCHA e Controle de Custos
No Capítulo 2, exploramos profundamente a cadeia técnica da camada de processamento de conteúdo—da limpeza de HTML à validação de Esquema—demonstrando como a extração semântica de IA eleva significativamente o teto de precisão. No entanto, conforme revelado na Figura 2-2 da Seção 2.1, o gargalo principal (14%) do Pipeline inteiro não está na camada de processamento, mas na camada anterior de aquisição de dados. Se o HTML não puder ser obtido, todo o processamento inteligente subsequente será construído sobre areia movediça. Este capítulo abordará diretamente essa etapa crítica que determina a "qualificação de entrada".
3.1 Camada de Aquisição de Dados: O Primeiro Gargalo Fatal do Pipeline
Se a limpeza de conteúdo e a análise por LLM resolvem o problema de "como processar dados", a camada de aquisição de dados aborda uma questão mais fundamental e complexa: "os dados podem ser obtidos?" No caminho da fila de URLs ao acesso normal, o sistema de anti-scraping é a variável mais imprevisível do Pipeline inteiro.
Sistemas modernos de anti-scraping evoluíram para uma arquitetura de defesa em profundidade de quatro camadas, analisando simultaneamente cada solicitação das camadas de rede, transporte, navegador e comportamento. A Figura 3-1 expande horizontalmente essa arquitetura de detecção em camadas.
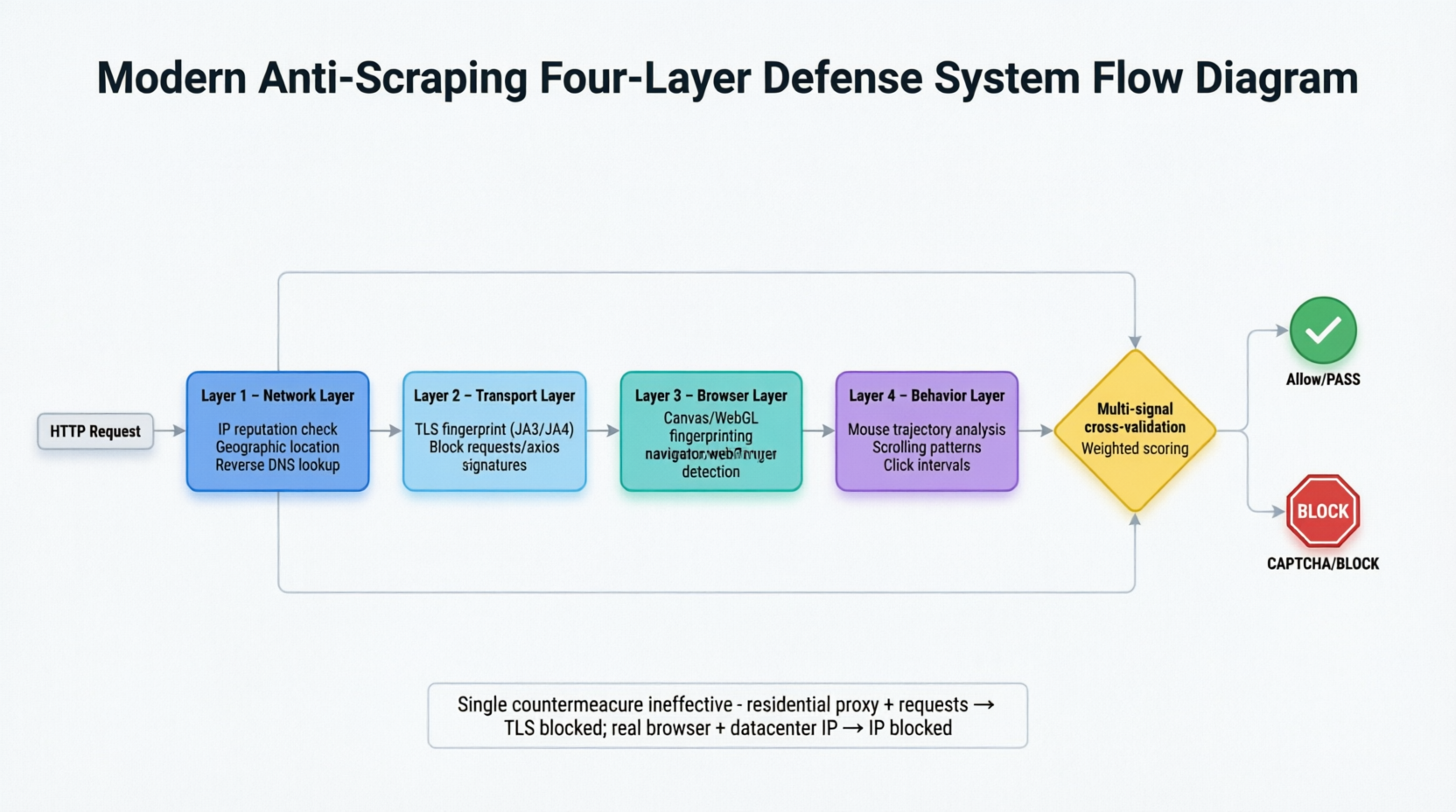
As solicitações passam por quatro camadas de filtragem sequencialmente. A camada de rede verifica sinais estáticos, como localização do IP, se pertence a um centro de dados e ausência de DNS reverso; a camada de transporte compara impressões digitais TLS; a camada de navegador captura traços de automação, como a propriedade navigator.webdriver no modo headless, impressões digitais do Canvas e informações do renderizador WebGL; a camada de comportamento analisa características de comportamento humano difíceis de simular com precisão, como trajetórias do mouse, padrões de rolagem e intervalos de cliques. Os quatro sinais das camadas são validados cruzadamente para formar uma pontuação ponderada, tornando difícil que qualquer camada de disfarce passe. Quando o sistema não consegue tomar uma decisão clara, a última linha de defesa—CAPTCHA—é acionada.
Quando todos os métodos passivos de detecção não conseguem determinar claramente a natureza do tráfego, o sistema exibe um CAPTCHA, que é a última linha de defesa dos sistemas de anti-scraping. CAPTCHAs modernos não são mais reconhecimento de caracteres distorcidos simples, mas sistemas de desafio inteligentes baseados em pontuações de risco. A Tabela 3-1 compara os quatro sistemas de CAPTCHA principais disponíveis atualmente.
| Sistema CAPTCHA | Formulário de Interação | Mecanismo de Julgamento | Capacidade/Recursos de Decodificação por IA | Ameaça aos Crawlers |
|---|---|---|---|---|
| reCAPTCHA v2 | Clicar no checkbox / Reconhecimento de imagem | Interação do usuário + pontuação de comportamento da IA | Precisão de 85%–100% | Alta, mas quebrável |
| reCAPTCHA v3 | Completamente invisível, sem desafio visível | Pontuação contínua de comportamento em segundo plano | Não pode ser "quebrado" diretamente, depende da simulação de comportamento | Extremamente alta, pontuação invisível |
| Cloudflare Turnstile | Verificação de consistência do ambiente do navegador | Verificação não interativa | Verifica a integridade do navegador | Alta, alternativa ao reCAPTCHA |
| AWS WAF CAPTCHA | Desafios baseados em risco, configuráveis | Julgamento do ambiente integrado da AWS | Específico do ambiente em nuvem | Média, ecossistema específico |
O CAPTCHA está localizado no final da cadeia de defesa. Uma vez acionado e não resolvido, todas as etapas subsequentes de limpeza de conteúdo e análise por LLM tornam-se completamente ineficazes. Esta é a razão fundamental pela qual a camada de aquisição de dados é chamada de "primeiro gargalo fatal da Cadeia": o mecanismo de anti-scraping determina se os dados podem fluir para o sistema, e ele mesmo é uma variável profundamente controlada pelo site-alvo. Em uma era em que a extração semântica de IA melhorou significativamente a eficiência do processamento de dados, o confronto no lado de aquisição permanece o ponto crítico para o sucesso da engenharia.
3.2 Completando o Quebra-Cabeça: Caminhos Técnicos para a Quebra de CAPTCHA Moderna
No sistema de defesa em profundidade de quatro camadas, o CAPTCHA é o obstáculo mais difícil e último de resolver automaticamente. Soluções de reconhecimento de CAPTCHA, representadas pelo CapSolver, desempenham um papel "semelhante a um fusível" na Cadeia — está integrado entre "detecção de anti-scraping" e "acesso normal". Quando um crawler enfrenta desafios como reCAPTCHA v2/v3, Cloudflare Turnstile ou AWS WAF CAPTCHA, ele completa o reconhecimento em segundos e retorna um Token válido, retomando o fluxo de dados. A Figura 3-2 usa o CapSolver como exemplo para ilustrar a posição de intervenção e a lógica de processamento dessa classe de solução:
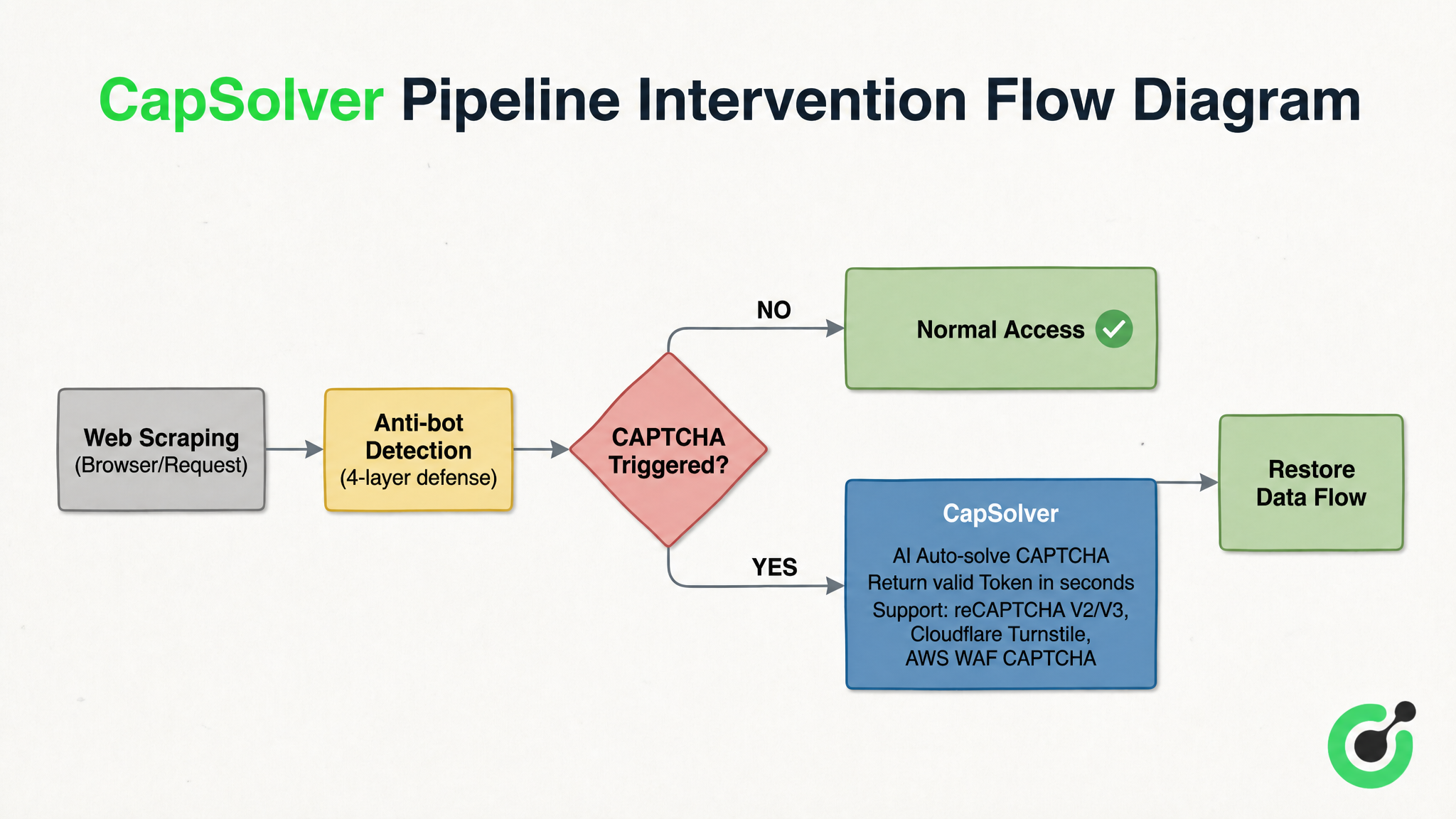
Da Figura 3-2, o mecanismo de funcionamento dessa classe de solução é claro: após o pedido de raspagem ser detectado pelo sistema de defesa em profundidade de quatro camadas, se o CAPTCHA não for acionado, ele é liberado diretamente para acesso normal; assim que um desafio de CAPTCHA for acionado, o serviço de reconhecimento interviene imediatamente e envia o tipo de CAPTCHA e os parâmetros. A IA completa o reconhecimento em segundos e retorna um Token válido, e o fluxo de dados é reconectado no ponto de interrupção. Ele não substitui nenhum componente existente, mas atua como um fusível em um sistema elétrico, evitando que todo o sistema falhe no momento em que ocorre uma anomalia.
CapSolver é uma das soluções representativas nesse campo. Serviços semelhantes como 2Captcha e Anti-Captcha também oferecem capacidades semelhantes, e os desenvolvedores podem escolher o fornecedor mais adequado com base em requisitos de latência, tipos suportados e modelos de preços. Essa integração muda diretamente o modelo de confiabilidade da camada de aquisição de dados. A Figura 3-3 usa o CapSolver como estudo de caso para quantificar as mudanças nos indicadores-chave antes e depois da introdução do reconhecimento de CAPTCHA:
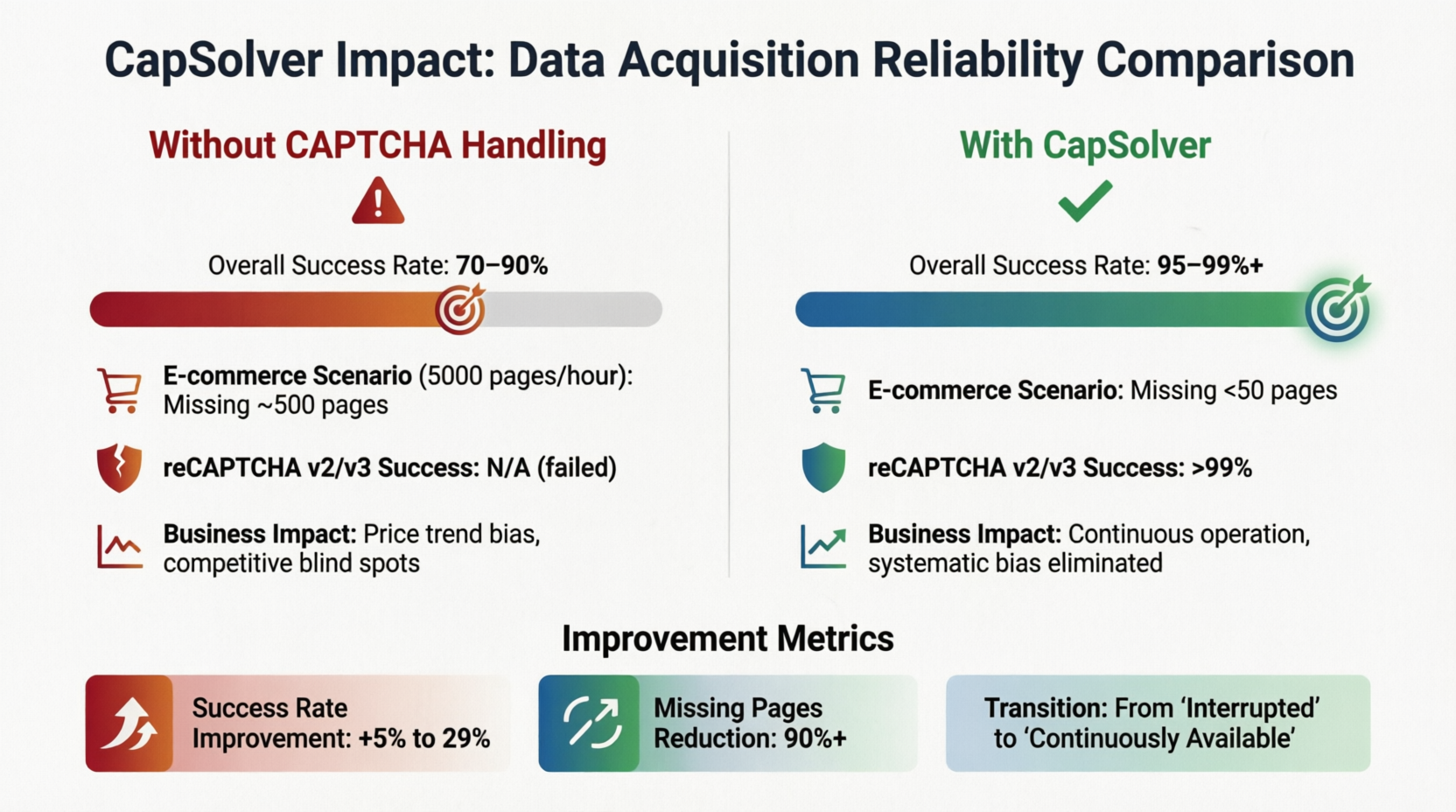
Sem um mecanismo de tratamento de CAPTCHA, a taxa de sucesso geral oscila entre 70%–90%. Desde que o site-alvo implante CAPTCHA, há uma probabilidade de 10%–30% de que o fluxo de dados seja bloqueado. Em um sistema de monitoramento de preços de e-commerce que raspa 5.000 páginas de produtos por hora, mesmo com uma taxa de sucesso básica de 90%, cerca de 500 páginas de dados serão perdidas por hora, o que é suficiente para causar desvios direcionais na análise de tendências de preços e pontos cegos sistêmicos nas estratégias de concorrentes. No entanto, após a introdução de uma solução de reconhecimento de CAPTCHA, a taxa de sucesso salta para mais de 95%–99%, e as páginas perdidas diminuem para dentro de 50. A taxa de sucesso no reconhecimento do reCAPTCHA v2/v3 excede 99% quando os parâmetros estão corretamente configurados. O rodapé do cartão resume os melhoramentos: taxa de sucesso aumentou em 5%–29%, e páginas perdidas reduzidas em mais de 90%. "Continuidade é valor comercial" não é apenas um slogan em cenários de grande escala, mas uma prática de engenharia confirmada por esses números.
Plataformas de testes de benchmark de IA e cenários de coleta de dados para treinamento de LLM também enfrentam esse desafio: os pesquisadores precisam adquirir continuamente dados diversos, e os sites que hospedam esses dados frequentemente usam reCAPTCHA para impedir o acesso automatizado, criando um paradoxo em que "equipes de pesquisa de IA são obstaculizadas pela própria tecnologia que estudam". Serviços de reconhecimento de CAPTCHA fornecem uma forma programática de lidar com esses desafios, garantindo coleta de dados ininterrupta e resultados completos de testes de benchmark.
No nível de integração, essas soluções podem trabalhar em colaboração com frameworks de automação de navegador, serviços de rede de proxies e plataformas de automação de baixo código. Os desenvolvedores precisam apenas enviar o tipo de CAPTCHA e os parâmetros para a API, e o sistema retorna um Token em segundos. Plataformas como n8n fornecem nós dedicados, permitindo que profissionais de negócios configurem o reconhecimento de CAPTCHA diretamente em fluxos de trabalho sem escrever código. Os desenvolvedores podem se concentrar na lógica de negócios e no design de Schema, deixando o confronto contra scraping para ferramentas profissionais.
Do ponto de vista arquitetural, as soluções de reconhecimento de CAPTCHA não substituem nenhum componente existente, mas fornecem uma camada de "garantia de disponibilidade" para o ponto de entrada da Cadeia. Quando o reconhecimento de CAPTCHA pode ser concluído automaticamente em segundos, a aquisição de dados muda de "pontos cegos intermitentes" para "fornecimento contínuo de dados", que é o pré-requisito para a operação estável da cadeia completa de extração estruturada de dados de IA.
3.3 Precisão e Custo: A Última Compromisso na Implementação de Engenharia
Ao levar a extração de dados estruturados de IA para um ambiente de produção, a variável decisiva final frequentemente não é "a precisão é boa o suficiente?" mas "o custo pode ser suportado?" O consumo de tokens está no núcleo desse problema: uma página de produto moderadamente complexa, mesmo após a limpeza, pode consumir 8.000 a 15.000 tokens. Com base nos preços atuais das APIs de modelos principais, o custo por extração varia de $0,001 a $0,01. Isso é quase insignificante na fase de protótipo, mas quando a escala de extração expande para milhões de páginas por dia, o custo mensal atinge dezenas de milhares de dólares, e nesse ponto o controle de custos não é mais uma otimização, mas um requisito de entrada. Atualmente, existem três caminhos paralelos na indústria para reduzir custos. A Figura 3-4 mostra sua posição e relação sinérgica na cadeia de análise completa:
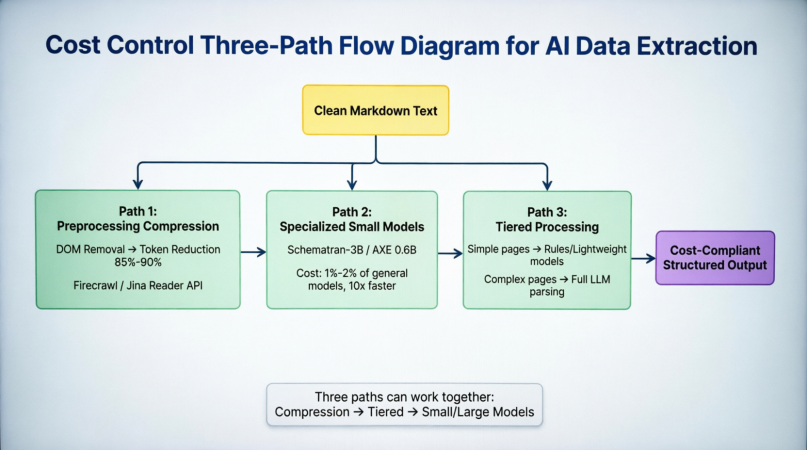
Antes que o Markdown limpo entre na etapa de análise, o primeiro caminho reduz tokens em 85%–90% através da eliminação do DOM e detecção de conteúdo principal na extremidade. Firecrawl e Jina Reader encapsularam isso em uma API, eliminando a necessidade de os desenvolvedores construírem seus próprios pipelines de limpeza. O segundo caminho substitui modelos grandes gerais por modelos específicos de tarefas, como Schematron-3B e AXE 0.6B, mantendo a precisão enquanto comprime os custos de inferência para 1%–2% e acelera em mais de 10 vezes. O terceiro caminho usa regras ou modelos leves para páginas estruturalmente simples na etapa de agendamento, entregando páginas complexas apenas ao modelo grande completo para análise. Isso é particularmente eficaz em cenários como monitoramento de categorias de e-commerce, onde a maioria das páginas dentro do mesmo site tem estruturas altamente consistentes, e apenas algumas páginas anômalas exigem intervenção completa do modelo. Os três caminhos não são mutuamente exclusivos, mas podem ser superpostos sinergicamente: primeiro comprima tokens, depois classifique por complexidade e, finalmente, processe com um modelo correspondente à tarefa. A Figura 3-5 quantifica ainda mais as três estratégias a partir dos princípios básicos, redução de tokens, soluções representativas e magnitude da redução de custos, e inclui três verificações de qualidade de dados:

A compressão pré-processamento reduz diretamente o volume de entrada removendo o ruído do DOM, alcançando uma redução de tokens de 85%–90%, correspondendo a uma economia de custos de 80%–90%. Modelos pequenos especializados reduzem o custo de inferência única reduzindo o tamanho do modelo, com parâmetros diminuindo de dezenas de bilhões para a faixa de 0,6B–3B, economizando cerca de 98% nos custos de inferência. O processamento em níveis otimiza a eficiência geral alocando recursos computacionais de forma diferenciada, com economias dependendo da proporção de páginas simples. Essas três abordagens, de "enviar menos", "computar menos" e "computar de forma inteligente", formam um sistema completo de redução de custos que abrange a camada de entrada, modelo e agendamento.
A segunda metade se volta para a garantia de qualidade. A inspeção de qualidade dos dados é um aspecto frequentemente ignorado, mas igualmente crucial para o controle de custos. O custo de corrigir dados de baixa qualidade que fluem para negócios downstream frequentemente excede muito o investimento em verificações na etapa de extração. Em um ambiente de produção, pelo menos três verificações automatizadas devem ser implementadas: verificações de taxa de preenchimento de campos garantem que os campos exigidos no Schema não estejam vazios, marcando registros anormais para revisão manual em vez de descartá-los diretamente; verificações de faixa numérica validam regras de negócios como preços não sendo negativos e estoque dentro de uma faixa razoável, rejeitando entradas que ultrapassem os limites; verificações de consistência de formato padronizam campos como datas, moedas e números de telefone, com expressões regulares e capacidades internas de conversão de formato da LLM se complementando, processando automaticamente o que pode ser convertido e marcando o que não pode para intervenção manual. As três verificações mantêm um equilíbrio dinâmico entre custo e qualidade, direcionando registros anormais em vez de descartá-los, garantindo completude enquanto evitando pontos cegos de dados.
Essa estratégia equilibrada também é aplicável em uma escala maior. Na prática de engenharia real, buscar 90% de precisão de extração automatizada combinada com um processo formal de revisão manual é frequentemente mais viável comercialmente do que tentar alcançar 100% de precisão teórica, mas com custos de implementação dezenas de vezes maiores. A seleção do armazenamento de dados de destino também depende do uso posterior: se for usado para consultas de API em tempo real e exibição no front-end, PostgreSQL ou MongoDB são escolhas adequadas; se for usado para pesquisa de texto completo e análise de logs, Elasticsearch é uma melhor opção; se for usado como corpus de treinamento de LLM, JSON estruturado geralmente precisa ser reserializado no formato exigido pelo framework de treinamento e armazenado em armazenamento de objetos. O objetivo não é perseguir uma solução de armazenamento "única para todos", mas corresponder ao motor mais adequado com base nos métodos de consumo de dados e padrões de consulta. Essa princípio percorre todas as decisões de engenharia, desde o custo de tokens até a seleção de armazenamento.
Resgate do Código de Bônus do CapSolver
Aumente instantaneamente seu orçamento de automação!
Use o código de bônus CAP26 ao recarregar sua conta do CapSolver para obter um bônus adicional de 5% em cada recarga — sem limites.
Resgate-o agora em seu Painel do CapSolver
Conclusão
Do HTML bruto ao JSON estruturado, a cadeia completa de extração de dados de IA pode ser resumida em cinco etapas sequenciais: aquisição, limpeza, análise, validação e armazenamento. Cada etapa resolve um problema específico, e a eficácia de cada etapa depende da conclusão bem-sucedida da etapa anterior.
Nessa cadeia, a camada de aquisição de dados desempenha o papel de "ponto de entrada", determinando se toda a Cadeia opera normalmente ou fica completamente inativa. A defesa em profundidade de quatro camadas dos sistemas modernos de anti-scraping e mecanismos de CAPTCHA continuamente atualizados tornam a aquisição de dados a etapa mais imprevisível e de maior risco em toda a cadeia. Quando a limpeza de conteúdo pode comprimir o HTML em mais de 80%, modelos pequenos especializados podem realizar extração estruturada precisa em segundos e a validação de Schema pode garantir a conformidade dos formatos de saída, "se os dados podem ser obtidos de forma estável" torna-se o problema principal que determina o sucesso do projeto.
Essa é exatamente a posição onde o valor infraestrutural do CapSolver reside na pilha de tecnologia de extração de dados de IA. Ele não substitui nenhuma etapa de limpeza, análise ou validação, mas fornece uma camada de garantia contínua de disponibilidade no ponto de entrada de toda a Cadeia. Quando o reconhecimento de CAPTCHA pode ser concluído automaticamente em segundos, com uma taxa de sucesso consistentemente acima de 99%, a aquisição de dados muda de interrupções intermitentes para saída contínua, e os recursos computacionais e investimentos em engenharia de todas as etapas subsequentes produzem retornos significativos. Para empresas que dependem de fornecimento estável de dados, a continuidade da Cadeia em si é valor comercial, e garantir essa continuidade é o último obstáculo que a extração de dados de IA deve superar em sua jornada da experimentação para a implantação em larga escala.