Melhores Bibliotecas Java de Raspagem de Web para Extração Confiável de Dados

Adélia Cruz
Neural Network Developer

TL;DR
- As bibliotecas de raspagem de web em Java devem ser escolhidas de acordo com o tipo de página, não com a popularidade.
- jsoup é o melhor para análise de HTML estático e extração baseada em seletores.
- Selenium Java scraping é adequado para páginas que exigem ações de navegador real.
- Playwright para Java é forte para fluxos modernos com JavaScript pesado.
- HtmlUnit funciona para tarefas leves semelhantes a um navegador.
- Apache Nutch é adequado para raspagem e indexação empresarial.
- Um API de raspagem de web é melhor quando CAPTCHA, escala e operações dominam.
Introdução
As melhores bibliotecas de raspagem de web em Java dependem de como a página de destino entrega os dados. Páginas estáticas precisam de análise rápida. Páginas dinâmicas precisam de automação de navegador. Programas de raspagem grandes precisam de filas, indexação e monitoramento. Fluxos de CAPTCHA precisam de um serviço documentado, não de lógica frágil. Este guia ajuda os desenvolvedores a escolher entre jsoup, Selenium Java scraping, Playwright para Java, HtmlUnit, Apache Nutch, opções de framework de raspagem Java e um API de raspagem de web. Use a ferramenta mais simples e confiável, siga as regras do site e mantenha os fluxos mantíveis.
Por que Java é usado para raspagem de web
Java é uma linguagem forte para raspagem quando os projetos devem rodar por meses, não minutos. Ele suporta código tipado, gerenciamento estável de dependências, clientes HTTP maduros e observabilidade amigável para produção. A Oracle descreve o Java como uma plataforma de desenvolvimento principal para reduzir o tempo de desenvolvimento e executar aplicações em ambientes diferentes por meio do modelo Java Java Oracle.
As bibliotecas de raspagem de web em Java também se encaixam nos hábitos empresariais. As equipes podem adicionar tentativas, logs, limites de taxa, testes e controles de acesso. Java pode não ser o mais rápido para protótipos. Torna-se atraente quando confiabilidade e manutenção importam.
A chave é alinhar as ferramentas ao conteúdo. Um parser não pode renderizar uma página React. Um navegador pode ser desperdiçado para HTML estático. Um framework de raspagem pode ser muito pesado para uma única página de produto. As melhores bibliotecas de raspagem de web em Java resolvem um problema definido.
Resumo da Comparação
| Ferramenta | Melhor para | Tratamento de JavaScript | Adequação de Escala | Principais Limitações |
|---|---|---|---|---|
| jsoup | Análise de HTML estático | Não | Médio | Precisa de outras ferramentas para renderização |
| HttpClient + jsoup | Raspagem estática controlada | Não | Médio a Alto | Requer lógica de busca personalizada |
| Selenium | Automação de navegador | Forte | Baixo a Médio | Tempo de execução pesado e seletores frágeis |
| Playwright para Java | Automação de navegador moderna | Forte | Médio | Requer gerenciamento de tempo de execução do navegador |
| HtmlUnit | Fluxos leves semelhantes a um navegador | Parcial a Bom | Médio | Não é substituição completa por um navegador |
| WebMagic ou Gecco | Projetos de framework de raspagem Java | Limitado | Médio | Ecossistema menor |
| Apache Nutch | Raspagem e indexação empresarial | Limitado | Alto | Configuração e operações complexas |
| API de raspagem de web | Operações de raspagem gerenciadas | Gerenciado pelo provedor | Alto | Menor controle direto |
Bibliotecas de Raspagem de Web Estática em Java
A raspagem estática deve começar com parsers. Se a primeira resposta HTML contém os dados necessários, a automação de navegador adiciona custo sem melhorar a precisão. As bibliotecas de raspagem de web em Java nessa categoria são rápidas, testáveis e mais fáceis de operar.
jsoup para Análise de HTML
jsoup é a primeira escolha para HTML estático. O site oficial descreve-o como um parser Java para HTML e XML reais, com busca de URL, análise, métodos DOM, seletores CSS e seletores XPath documentação oficial do jsoup.
Use jsoup para páginas de artigos, páginas de categorias, páginas de produtos simples, tabelas e fragmentos HTML. Ele lida bem com marcação imperfeita. Isso importa porque muitas páginas são legíveis por navegadores, mas não limpas o suficiente para ferramentas XML rigorosas.
Um fluxo confiável com jsoup é direto. Solicite a página com cabeçalhos claros. Analise o documento. Selecione campos com seletores CSS estáveis. Valide valores vazios antes do armazenamento. Este padrão mantém as bibliotecas de raspagem de web em Java previsíveis.
jsoup não é um navegador. Ele não executa JavaScript. Se o conteúdo aparece apenas após a execução de scripts, inspecione as chamadas de rede primeiro. Se existirem endpoints permitidos, use um cliente HTTP. Se for necessário comportamento de navegador, use Selenium ou Playwright para Java.
Abordagem HttpClient + jsoup
HttpClient mais jsoup é ideal para raspagem estática controlada. O cliente Java pode gerenciar cabeçalhos, timeouts, redirecionamentos e corpos de resposta. jsoup então analisa o HTML. Esta separação mantém a busca e a análise limpas.
Este método funciona para monitoramento de preços, diretórios públicos, auditorias de conteúdo e conjuntos de dados de pesquisa. É melhor que a busca direta do jsoup quando você precisa de rastreamento, regras de tentativa, atrasos de raspagem ou configuração de proxy.
Bibliotecas de Raspagem de Web Dinâmica em Java
Páginas dinâmicas precisam de comportamento de navegador. Elas podem carregar conteúdo após rolar, clicar, autenticar ou solicitações em segundo plano. Selenium Java scraping, Playwright para Java e HtmlUnit resolvem isso de forma diferente.
Selenium para Automação de Navegador
Selenium é maduro e amplamente documentado. O projeto oficial descreve o Selenium como ferramentas e bibliotecas que permitem automação de navegador, com WebDriver como interface central para executar instruções em navegadores principais documentação do Selenium.
Selenium Java scraping funciona quando os sites exigem ações de navegador real. Ele pode clicar em botões, esperar por elementos, enviar formulários e ler o DOM renderizado. Também se encaixa em equipes que já usam Selenium para testes de QA.
A compensação é o custo. Sessões de navegador consomem CPU e memória. Seletores podem quebrar quando a interface muda. Use Selenium Java scraping quando a fidelidade do navegador importa mais do que velocidade.
Se CAPTCHA aparecer em testes autorizados ou automação permitida, não o esconda em scripts frágeis. Revise as regras do alvo primeiro. Em seguida, use um fluxo documentado, como a integração CAPTCHA do Selenium do CapSolver.
Playwright para Java
Playwright para Java é forte para automação moderna. Seu site oficial diz que o Playwright pode controlar Chromium, Firefox e WebKit por meio de uma API, com suporte a Java disponível documentação do Playwright para Java.
Playwright para Java frequentemente reduz automação instável. Auto-espera, contextos de navegador, rastreamento e localizadores resistentes ajudam a manter fluxos estáveis. Ele se encaixa em projetos de bibliotecas de raspagem de web em Java que precisam de capturas de tela, downloads, navegação entre páginas ou esperas confiáveis.
Escolha o Playwright para Java quando as páginas são pesadas em JavaScript e contextos de navegador repetíveis importam. Evite-o quando uma solicitação HTTP simples retorna os mesmos dados. Um navegador deve ser a última camada necessária, não o primeiro hábito.
Para CAPTCHA em automação aprovada, conecte o fluxo à orientação oficial. O CapSolver publica uma integração CAPTCHA do Playwright que é mais segura do que copiar trechos aleatórios.
HtmlUnit para Tratamento de JS Leve
HtmlUnit fica entre análise e automação completa de navegador. Seu site oficial o chama de "navegador sem interface gráfica para programas Java". Ele pode invocar páginas, preencher formulários, clicar em links, gerenciar cookies e fornecer suporte a JavaScript para muitos fluxos AJAX documentação do HtmlUnit.
Use HtmlUnit para sites mais antigos, fluxos de formulário simples, ferramentas internas e sistemas de teste. É mais leve que a automação completa de navegador. Isso pode reduzir o custo de infraestrutura para cargas de trabalho moderadas.
HtmlUnit não é substituição completa para Chrome, Firefox ou WebKit. Frameworks de front-end modernos podem expor lacunas. Se a renderização visual ou eventos complexos importam, o Selenium ou o Playwright para Java é mais seguro.
Frameworks de Raspagem de Web em Java para Raspagem em Grande Escala
Raspagem em grande escala é diferente da extração de página. Ela precisa de gerenciamento de fronteira, deduplicação, regras de tentativa, controles de cortesia, análise, indexação e monitoramento. Um framework de raspagem Java ajuda quando um raspador se torna um sistema.
WebMagic e Gecco
WebMagic e Gecco são opções práticas para projetos médios. Eles estruturam lógica de download, processadores de página, pipelines e modelos de dados. Isso torna o código mais fácil de dividir entre equipes.
Use-os para catálogos públicos, espelhos de documentação, descoberta de conteúdo recorrente e páginas semelhantes. Eles são menos adequados para páginas altamente dinâmicas, a menos que combinados com uma camada de renderização. Sua principal força é a manutenibilidade. Sua principal fraqueza é um ecossistema menor do que o de jsoup, Selenium ou Playwright.
Apache Nutch para Raspagem Empresarial
Apache Nutch é construído para programas de raspagem grandes. Sua página inicial descreve-o como um raspador web altamente extensível, escalável, maduro e pronto para produção projeto Apache Nutch. Ele suporta análise plugável, indexação, pontuação e integrações com sistemas de busca.
Use o Apache Nutch quando a raspagem for um requisito da plataforma. Ele se encaixa em indexação de busca, descoberta empresarial e aquisição de dados em larga escala recorrente. Não é ideal para um raspador pequeno e único. Configuração e operações exigem tempo real de engenharia.
Antes de escalar qualquer framework de raspagem Java, defina domínios permitidos, frequência de atualização, regras de armazenamento e limites de solicitação. O guia do CapSolver sobre legalidade da raspagem de web e regras-chave é útil para planejamento.
Desafios de CAPTCHA na Raspagem de Web em Java
CAPTCHA é um sinal de fluxo, não apenas um problema técnico. Pode indicar pressão de taxa, risco de login, regras de acesso ou permissão ausente. Trate-o com cuidado. Confirme que seu caso de uso é permitido, minimize o volume de solicitações e colete apenas dados necessários.
As bibliotecas de raspagem de web em Java não resolvem CAPTCHA por si mesmas. jsoup não pode interagir com um desafio. Selenium e Playwright podem exibir um, mas ainda precisam de um processo válido de tratamento. HtmlUnit raramente é a camada correta para esta tarefa.
CapSolver é relevante quando um processo de automação legítimo precisa de tratamento de CAPTCHA. Exemplos incluem testes de QA, fluxos de conta própria e raspagem permitida. A documentação oficial do API CapSolver lista createTask e getTaskResult como endpoints principais para criação de tarefa e recuperação de resultados documentação da API CapSolver. Use os documentos oficiais diretamente para detalhes de implementação.
Um processo seguro é simples. Documente o alvo, confirme a permissão, limite as taxas de solicitação e armazene apenas campos necessários. A FAQ do CapSolver sobre raspagem de web e APIs de resolução de CAPTCHA é um recurso útil para planejamento.
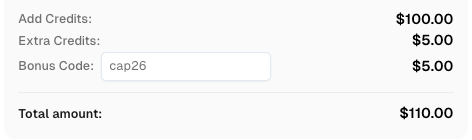
Resgate seu código de bônus do CapSolver
Aumente seu orçamento de automação instantaneamente!
Use o código de bônus CAP26 ao recarregar sua conta do CapSolver para obter um bônus extra de 5% em cada recarga — sem limites.
Resgate-o agora em seu Painel do CapSolver
Quando Usar uma API de Raspagem de Web em vez de Bibliotecas
Use uma API de raspagem de web quando as operações importam mais do que o controle do código. As bibliotecas de raspagem de web em Java são flexíveis, mas as equipes devem gerenciar tempos de execução de navegador, tentativas, monitoramento, desvio de parser e fluxos de CAPTCHA.
Uma API de raspagem de web faz sentido para coleta em grande volume, front-ends instáveis, páginas pesadas em JavaScript e equipes sem infraestrutura de raspagem. Pode também reduzir a necessidade de farmas de navegadores. A compensação é a dependência de fornecedor, então revise qualidade de dados, preços, logs e termos de conformidade.
Um modelo híbrido é frequentemente o melhor. Use jsoup para páginas estáticas estáveis. Use Selenium Java scraping ou Playwright para Java para um pequeno conjunto de fluxos dinâmicos. Use Apache Nutch quando a raspagem se tornar uma plataforma de busca. Use uma API de raspagem de web quando a infraestrutura se tornar a principal carga de trabalho. O guia do CapSolver sobre desafios comuns de raspagem de web pode ajudar as equipes a se prepararem.
Conclusão e CTA
As melhores bibliotecas de raspagem de web em Java são classificadas por adequação, não por hype. jsoup é o melhor para HTML estático. HttpClient mais jsoup adiciona controle. Selenium Java scraping e Playwright para Java lidam com páginas dinâmicas. HtmlUnit cobre fluxos leves semelhantes a um navegador. WebMagic, Gecco e Apache Nutch suportam arquitetura de raspagem. Uma API de raspagem de web ajuda quando o custo de infraestrutura cresce.
Comece pequeno e mantenha-se em conformidade. Leia as regras do site, respeite os limites de taxa, minimize a coleta e mantenha logs. Se CAPTCHA aparecer em um fluxo aprovado, use documentação oficial e um provedor dedicado, como CapSolver.
Perguntas Frequentes
Qual é a melhor biblioteca de raspagem de web em Java?
jsoup é a primeira escolha para HTML estático. Playwright para Java ou Selenium é melhor para páginas pesadas em JavaScript. Apache Nutch é melhor para raspagem empresarial.
O Selenium Java scraping é melhor que o Playwright para Java?
Selenium tem história mais longa e suporte mais amplo. O Playwright para Java frequentemente oferece recursos de automação moderna mais fortes, incluindo auto-espera e contextos de navegador.
O jsoup pode raspar sites dinâmicos?
O jsoup pode analisar HTML retornado, mas não executa JavaScript. Use automação de navegador quando o conteúdo aparece apenas após a execução de scripts.
O Apache Nutch é adequado para projetos pequenos de raspagem?
Normalmente não. O Apache Nutch é poderoso, mas é melhor para sistemas de raspagem grandes, indexação de busca e aquisição de dados empresarial.
Quando devo usar o CapSolver com a raspagem de web em Java?
Use CapSolver apenas para automação legítima e documentada onde o tratamento de CAPTCHA for permitido. Siga a documentação oficial da API do CapSolver e as regras do site alvo.
Ver mais
AIJun 23, 2026
SDKs Nativos de Resolvedor de CAPTCHA para Agentes de IA
Um guia orientado para desenvolvedores sobre SDKs nativos de solucionadores de CAPTCHA para agentes de IA, com limites de wrapper, exemplos oficiais, verificações de sessão e tratamento de falhas.
AIJun 23, 2026
Escolhendo um Serviço de Resolução de CAPTCHA para Automação de Agentes
Uma lista de verificação prática para comprador e engenharia para escolher um serviço de resolução de CAPTCHA para automação de agentes em fluxos de trabalho controlados e documentados.