Agentes de IA em Web Scraping & Inteligência Competitiva Guia

Adélia Cruz
Neural Network Developer

TL;DR
- Agentes de IA são sistemas de software autônomos que planejam, executam e adaptam tarefas de coleta de dados de múltiplas etapas sem entrada constante de humanos.
- Na indústria de agentes de IA, raspagem de web e inteligência competitiva são entre as áreas de aplicação com maior crescimento.
- Agentes de IA podem monitorar preços de concorrentes, rastrear mudanças em produtos e extrair dados estruturados em uma escala que nenhum time manual pode acompanhar.
- Sites modernos utilizam CAPTCHAs, limitação de taxa e camadas de detecção de bots que interrompem pipelines automatizados — serviços de resolução de CAPTCHA como CapSolver ajudam os agentes a manterem a continuidade.
- O uso responsável e compatível com regulamentações de agentes de IA para coleta de dados requer respeito a robots.txt, termos de serviço e regulamentações de dados aplicáveis.
Introdução
Agentes de IA estão transformando como os negócios coletam e agem sobre dados externos. Na indústria de agentes de IA, dois casos de uso passaram de experimentais para produção mais rapidamente do que quase qualquer outro: raspagem de web e inteligência competitiva. Empresas agora utilizam agentes que navegam autonomamente pela web, extraem informações estruturadas e as alimentam diretamente em motores de preços, dashboards de mercado e relatórios estratégicos — tudo sem que um humano clique em um botão. Este artigo explica o que são esses agentes, como funcionam, onde adicionam mais valor e quais obstáculos técnicos (incluindo CAPTCHAs) as equipes devem planejar ao construir pipelines compatíveis e de produção.
O que são Agentes de IA e por que eles importam para coleta de dados?
Um agente de IA é um programa de software que percebe seu ambiente, raciocina sobre um objetivo e toma uma sequência de ações para alcançá-lo — depois se ajusta com base no que observa. Ao contrário de um script simples que segue um caminho fixo, um agente pode decidir qual página visitar em seguida, como lidar com mudanças inesperadas no layout e quando repetir uma solicitação falha.
IBM define agentes de IA como sistemas que combinam percepção, raciocínio e ação em um loop contínuo. Esse loop é exatamente o que os torna poderosos para coleta de dados: a web é bagunçada, dinâmica e inconsistente, e uma camada de raciocínio lida com essa variabilidade muito melhor do que um raspador rígido.
A indústria de agentes de IA está crescendo a uma velocidade notável. Segundo MarketsandMarkets, o mercado global de agentes de IA deve crescer de 7,84 bilhões de dólares em 2025 para 52,62 bilhões até 2030, com uma CAGR de 46,3%. Pesquisa e coleta de dados são entre os três principais casos de uso já em implantação. O Relatório do Estado dos Agentes de IA da LangChain descobriu que 51% das empresas pesquisadas já tinham agentes em produção até 2024, com pesquisa e coleta de dados citados como a aplicação principal — à frente de atendimento ao cliente e produtividade pessoal.
Arquitetura Principal: Como os Agentes de IA Operam em Pipelines de Raspagem
Entender a arquitetura ajuda as equipes a construírem sistemas mais confiáveis. Um pipeline típico de raspagem na indústria de agentes de IA tem quatro camadas:
1. Camada de planejamento
O agente recebe um objetivo de alto nível — por exemplo, "coletar preços diários dos 50 principais SKUs em três sites de concorrentes." Ele o divide em subtarefas: identificar URLs, agendar solicitações, definir esquemas de extração. Em configurações mais avançadas, a camada de planejamento usa um LLM para gerar um plano de execução passo a passo que pode ser revisado durante a execução se as condições mudarem.
2. Camada de execução
O agente envia solicitações HTTP ou controla um navegador headless (Playwright, Puppeteer, Selenium). Ele analisa HTML, APIs JSON ou conteúdo JavaScript renderizado e mapeia para um formato estruturado. A camada de execução deve lidar com paginação, rolagem infinita, fluxos de login e conteúdo dinâmico renderizado no lado do cliente — todos cenários onde um raspador estático falharia.
3. Camada de observação e adaptação
Após cada ação, o agente verifica o resultado. A página carregou corretamente? Os dados esperados estavam presentes? Um CAPTCHA apareceu? Com base na observação, ele decide a próxima etapa — tentar novamente, escalonar ou seguir em frente. Essa é a camada que torna os agentes verdadeiramente diferentes de scripts: eles não apenas executam, mas avaliam.
4. Camada de memória e armazenamento
Os dados extraídos são escritos em um banco de dados, data warehouse ou pipeline de downstream. Alguns agentes mantêm memória de curto prazo (contexto de sessão) e memória de longo prazo (tendências de preços históricos, padrões conhecidos de URLs). A memória de longo prazo permite que o agente detecte anomalias — por exemplo, um preço que cai 80% durante a noite provavelmente é um erro de dados, não um desconto real.
Esse modelo de quatro camadas é o que separa um pipeline de coleta de dados moderno de um raspador tradicional. O agente não está apenas buscando páginas — ele está raciocinando sobre a tarefa, e essa distinção importa em escala de produção.
Casos de Uso Principais em Inteligência Competitiva
Inteligência competitiva é uma das aplicações de maior valor da ferramentaria da indústria de agentes de IA. Aqui estão os cenários mais comuns onde as equipes implantam agentes hoje:
Monitoramento de Preços
Equipes de comércio eletrônico utilizam agentes para rastrear preços de concorrentes em milhares de SKUs em tempo quase real. O agente visita páginas de produtos, extrai dados de preço e disponibilidade e os escreve em um motor de preços que pode acionar ajustes automáticos. Monitoramento manual nessa escala é inviável — um único analista pode acompanhar 50 produtos por dia; um agente pode acompanhar 50.000.
A camada de observação do agente é crítica aqui. Se uma página de produto retorna um status 429 (Muitas Solicitações), o agente recua e tenta novamente com atraso exponencial. Se o layout da página mudar — algo comum durante reestruturações de sites — o agente pode usar um LLM para reidentificar o elemento de preço em vez de falhar silenciosamente.
Rastreamento de Produtos e Funcionalidades
Empresas de SaaS implantam agentes para monitorar páginas de histórico de alterações, notas de lançamento e blogs de anúncios de funcionalidades. Quando um concorrente envia uma nova integração ou muda um plano de preços, o agente sinaliza isso em horas, não em dias. Gerentes de produto recebem resumos estruturados em vez de dumps de HTML bruto, porque a camada de extração do agente mapeia o conteúdo para um esquema pré-definido: nome da funcionalidade, data de lançamento, plano afetado e resumo.
Esse tipo de monitoramento contínuo costumava exigir um analista dedicado. Hoje, na indústria de agentes de IA, ele roda como um processo em segundo plano agendado.
Agregação de Revisões e Sentimento
Agentes coletam revisões de clientes em plataformas como G2, Trustpilot e lojas de aplicativos. Camadas de processamento de linguagem natural classificam sentimentos, extraem temas recorrentes e destacam lacunas de produtos — fornecendo uma sinalização contínua ao mercado para equipes de produto. Uma equipe pode identificar que os usuários de um concorrente reclamam consistentemente sobre onboarding lento, então usar essa insight para aprimorar sua própria posição.
Monitoramento de SERP e Conteúdo
Equipes de SEO e conteúdo utilizam agentes para rastrear rankings de palavras-chave, monitorar perfis de backlink e identificar novo conteúdo publicado por concorrentes. Isso alimenta diretamente calendários editoriais e estratégias de construção de links. Agentes também podem detectar quando um concorrente publica conteúdo alvo de uma palavra-chave que você atualmente classifica, acionando um alerta antes que as classificações mudem.
Inteligência de Postagens de Vagas
Monitorar postagens de vagas de concorrentes revela intenções estratégicas. Um aumento súbito em contratações de engenheiros de dados sinaliza uma reconstrução de plataforma. Um grupo de cargos de vendas empresarial sugere uma expansão de mercado. Agentes podem monitorar páginas de carreira diariamente e aglutinar esse sinal automaticamente, dando às equipes de estratégia um indicador antecipado muitas vezes mais confiável do que comunicados de imprensa.
Para uma visão mais ampla sobre como ferramentas de raspagem estão evoluindo para suportar esses fluxos de trabalho, veja Ferramentas de Raspagem de Web em 2026 e Melhores Ferramentas de Extração de Dados.
Comparação: Raspadores Tradicionais vs. Agentes de IA
| Dimensão | Raspador Tradicional | Agente de IA |
|---|---|---|
| Definição de tarefa | Seletores fixos, caminhos rígidos | Baseado em objetivos, adaptativo |
| Lidando com mudanças de layout | Quebra, requer correção manual | Detecta e se adapta |
| Navegação de múltiplas etapas | Limitado | Capacidade nativa |
| Recuperação de erros | Intervenção manual | Lógica de tentativa automática |
| Tratamento de CAPTCHA | Bloqueia o pipeline | Pode integrar serviços de resolução |
| Escalabilidade | Linear com esforço de engenharia | Escala com computação |
| Consciência de conformidade | Nenhuma integrada | Pode ser instruído a respeitar regras |
O Problema do CAPTCHA: Onde os Agentes de IA encontram um muro
Mesmo o pipeline mais sofisticado da indústria de agentes de IA eventualmente encontrará um CAPTCHA. Sites os utilizam como defesa primária contra acesso automatizado. Os tipos mais comuns incluem:
- reCAPTCHA v2 — desafios de seleção de imagem ("selecionar todos os semáforos")
- reCAPTCHA v3 — avaliação de risco baseada em pontuação, invisível
- Cloudflare Turnstile — um desafio mais novo, focado em privacidade, que substitui CAPTCHAs tradicionais
- GeeTest — desafios de slider e comportamentais comuns em plataformas asiáticas
Quando um agente encontra um CAPTCHA, o pipeline trava. O agente não pode prosseguir sem um token válido ou um desafio concluído. Isso é um problema estrutural, não um caso raro — fontes de dados de alto valor quase sempre estão protegidas.
A solução compatível é integrar uma API de resolução de CAPTCHA na camada de observação do agente. Quando o agente detecta um desafio, ele envia os parâmetros relevantes para o serviço de resolução, recebe um token e o injeta na solicitação para continuar. O agente nunca precisa parar.
CapSolver é um serviço de resolução de CAPTCHA baseado em IA construído especificamente para esse padrão de integração. Ele suporta reCAPTCHA v2/v3/Enterprise, Cloudflare Turnstile, GeeTest e CAPTCHA do AWS WAF. Soluções são retornadas em 1–5 segundos via API REST, sem envolvimento humano — todo o fluxo permanece automatizado.
Para equipes construindo pipelines da indústria de agentes de IA em Python, a integração segue o padrão documentado na documentação oficial da API do CapSolver. O agente submete uma tarefa, verifica o resultado e usa o token retornado para completar a solicitação protegida. Isso mantém o pipeline em execução sem intervenção manual.
Você também pode explorar como resolver CAPTCHAs durante a raspagem de web para um passeio prático pelos padrões de integração comuns.
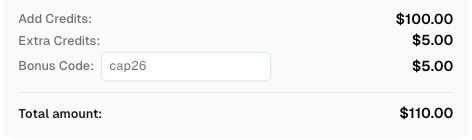
Resgate seu código promocional do CapSolver
Aumente seu orçamento de automação instantaneamente!
Use o código promocional CAP26 ao recarregar sua conta do CapSolver para obter um bônus extra de 5% em cada recarga — sem limites.
Resgate-o agora em seu Painel do CapSolver
Frameworks de Agentes de IA Usados em Fluxos de Raspagem
Vários frameworks open-source e comerciais surgiram especificamente para apoiar casos de uso da indústria de agentes de IA na coleta de dados:
- LangChain / LangGraph — popular para construir agentes de raciocínio de múltiplas etapas com uso de ferramentas
- AutoGen (Microsoft) — suporta colaboração entre agentes, útil para tarefas de raspagem paralelas
- CrewAI — orquestração de agentes baseada em papéis, adequada para fluxos de inteligência competitiva
- Crawl4AI — construído especificamente para raspagem de web amigável à IA com saída estruturada
- ScrapeGraph AI — combina LLMs com raspagem para extrair dados usando instruções em linguagem natural
Para uma análise detalhada das opções principais, veja Top 9 Frameworks de Agentes de IA em 2026.
Cada framework trata as camadas de planejamento e execução de forma diferente, mas todos enfrentam os mesmos desafios de infraestrutura: limitação de taxa, bloqueio de IP e CAPTCHAs. A escolha do framework afeta a arquitetura; a camada de resolução de CAPTCHA é um componente separável e composable.
Conformidade e Uso Responsável
A indústria de agentes de IA opera em um cenário legal e ético que as equipes devem levar a sério. A coleta automatizada de dados não é intrinsecamente ilegal, mas deve ser feita de forma responsável.
Princípios-chave:
- Respeite robots.txt — esse arquivo sinaliza quais caminhos o proprietário do site permite acesso automatizado. Agentes devem analisar e respeitá-lo.
- Revise os termos de serviço — muitos sites proíbem explicitamente a raspagem automatizada. Revisão legal é apropriada para casos de uso de alto volume ou sensíveis comercialmente.
- Limitação de taxa — agentes devem implementar atrasos e respeitar cabeçalhos Retry-After para evitar sobrecarregar servidores alvo.
- Dados pessoais — coletar informações identificáveis pessoal aciona regulamentações como GDPR, CCPA e outras. Agentes devem ser limitados a coletar apenas o necessário.
- Atualização e precisão dos dados — inteligência competitiva só é valiosa se os dados forem confiáveis. Agentes devem incluir etapas de validação para sinalizar anomalias.
Pesquisa da Deloitte sobre IA agêntica destaca que governança e supervisão são as principais preocupações para equipes empresariais que implantam agentes em produção. Construir conformidade na instrução do agente desde o início é muito mais fácil do que adaptá-la posteriormente.
Conclusão
Agentes de IA passaram de um conceito de pesquisa para uma ferramenta de produção na indústria de agentes de IA, e raspagem de web com inteligência competitiva é uma das demonstrações mais claras de seu valor. Eles lidam com páginas dinâmicas, se adaptam a mudanças de layout, executam navegação de múltiplas etapas e escalam para volumes que nenhum processo manual pode acompanhar.
Os desafios técnicos são reais — CAPTCHAs, limitações de taxa e sistemas de detecção de bots são projetados para interromper exatamente esse tipo de automação. Integrar um serviço confiável de resolução de CAPTCHA como CapSolver em seu pipeline remove um dos pontos mais comuns de falha, mantendo a coleta de dados contínua e compatível.
Se você estiver construindo ou avaliando uma pipeline de agentes de IA para inteligência competitiva, comece com um objetivo de dados claro, escolha um framework que atenda às suas necessidades de orquestração e planeje a camada de infraestrutura — incluindo tratamento de CAPTCHA — antes de ir para produção.
Perguntas frequentes
Q1: Qual é a diferença entre um raspador de web e um agente de IA para coleta de dados?
Um raspador de web tradicional segue um conjunto fixo de instruções — seletores específicos, URLs predeterminados e um caminho de execução rígido. Um agente de IA adiciona uma camada de raciocínio: ele pode interpretar um objetivo, planejar os passos necessários para alcançá-lo, adaptar-se quando uma página muda e se recuperar de erros de forma autônoma. Para inteligência competitiva em escala, a capacidade de adaptação é a diferença crítica.
Q2: Agentes de IA são legais para raspagem de web?
A coleta automatizada de dados é legal em muitas jurisdições quando se destina a informações publicamente acessíveis e cumpre os termos de serviço do site e as leis de proteção de dados aplicáveis. O cenário legal varia conforme o país e o caso de uso. As equipes devem revisar o robots.txt, os termos de serviço e as regulamentações relevantes (GDPR, CCPA) antes de implantar agentes em larga escala.
Q3: Como os agentes de IA lidam com CAPTCHAs durante a raspagem?
Quando um agente encontra um CAPTCHA, ele pode integrar-se a uma API de resolução de CAPTCHA. O agente passa os parâmetros do desafio para a API, recebe um token válido e o insere na solicitação para continuar. Serviços como CapSolver suportam esse padrão para reCAPTCHA, hCaptcha, Cloudflare Turnstile e outros tipos comuns de desafio, retornando soluções em segundos por meio de uma API REST.
Q4: Qual framework de agente de IA é o melhor para pipelines de inteligência competitiva?
A melhor escolha depende da sua stack e da complexidade do fluxo de trabalho. LangChain e LangGraph são amplamente adotados e têm forte suporte da comunidade. CrewAI é adequado para fluxos de trabalho multiagente baseados em papéis. Crawl4AI e ScrapeGraph AI são construídos especificamente para extração de dados da web. A maioria das equipes começa com um framework e adiciona componentes de infraestrutura componíveis — proxies, solucionadores de CAPTCHA, armazenamento — à medida que a pipeline amadurece.
Q5: Com que frequência os agentes de inteligência competitiva devem ser executados?
A frequência depende da volatilidade dos dados. Dados de preços para comércio eletrônico podem precisar de atualizações a cada hora. Monitoramento de funcionalidades e inteligência de vagas de emprego podem ser executados diariamente ou semanalmente. Monitoramento de SERP geralmente é executado diariamente. Os agentes devem ser agendados com base em quão rapidamente os dados subjacentes mudam, equilibrando contra a carga imposto nos servidores alvo e o custo de computação.
Ver mais
AIJun 23, 2026
SDKs Nativos de Resolvedor de CAPTCHA para Agentes de IA
Um guia orientado para desenvolvedores sobre SDKs nativos de solucionadores de CAPTCHA para agentes de IA, com limites de wrapper, exemplos oficiais, verificações de sessão e tratamento de falhas.
AIJun 23, 2026
Escolhendo um Serviço de Resolução de CAPTCHA para Automação de Agentes
Uma lista de verificação prática para comprador e engenharia para escolher um serviço de resolução de CAPTCHA para automação de agentes em fluxos de trabalho controlados e documentados.