API de Busca vs Cadeia de Suprimentos de Conhecimento: Guia da Infraestrutura de Dados de IA

Adélia Cruz
Neural Network Developer
TL;DR
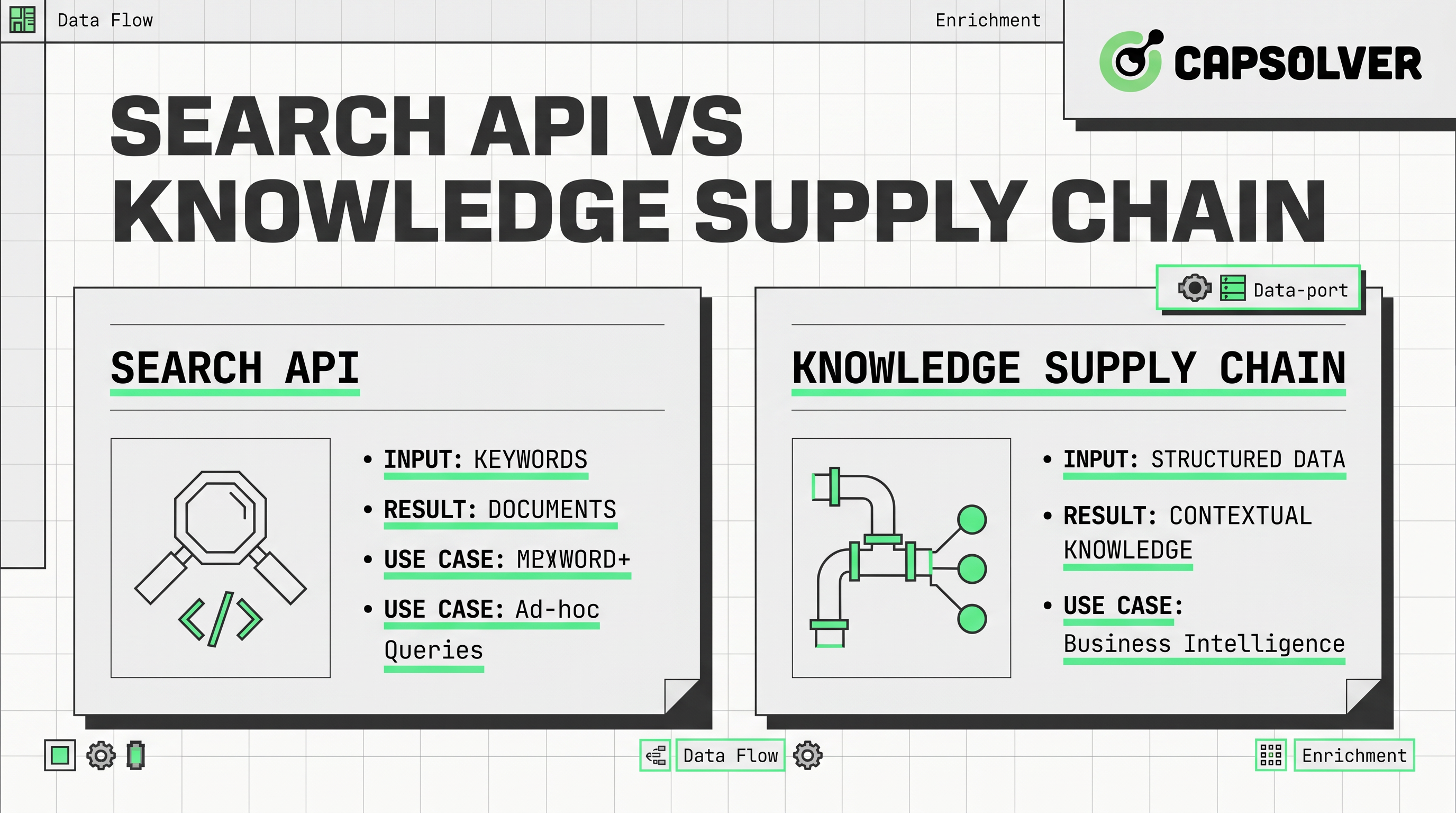
- as ferramentas de API de pesquisa são úteis para descoberta rápida, mas não cobrem todas as necessidades de sistemas de IA de produção.
- uma cadeia de suprimentos de conhecimento inclui descoberta, extração, validação, armazenamento, orquestração e monitoramento.
- uma API de SERP ajuda a coletar resultados classificados de pesquisas, enquanto uma API de raspagem de web ajuda a coletar conteúdo de página.
- uma infraestrutura sólida de dados da web depende de atualização, qualidade da fonte, auditabilidade e coleta consciente de políticas.
- uma pipeline de dados para IA deve conectar recuperação com análise, enriquecimento, governança e uso de modelos downstream.
- para automação aprovada, as equipes também podem precisar de camadas de confiabilidade quando etapas de verificação interrompem fluxos de coleta.
Introdução
A resposta curta é simples. Uma API de pesquisa é uma interface de recuperação, enquanto uma cadeia de suprimentos de conhecimento é um modelo de operação para infraestrutura de dados de IA. Este artigo é para engenheiros de IA, empreendedores técnicos, equipes de SEO e construtores de plataformas de dados que precisam de dados da web atuais sem perder o controle da qualidade ou conformidade. Se você está escolhendo entre uma interface de pesquisa, uma API de SERP e uma pilha mais ampla de infraestrutura de dados da web, a decisão correta depende de risco, atualização e uso downstream. O valor principal é clareza prática. Você verá onde cada opção se encaixa, onde quebra e como projetar uma pipeline de dados de IA mais confiável.
Introdução às APIs de Pesquisa e Cadeias de Suprimentos de Conhecimento
A principal diferença é arquitetural. Uma API de pesquisa geralmente aceita uma consulta e retorna links classificados, trechos ou resultados resumidos de um índice. Isso torna essas ferramentas atraentes quando as equipes precisam de respostas rápidas, enriquecimento leve ou protótipos iniciais.
Uma cadeia de suprimentos de conhecimento é mais abrangente por design. Ela trata a aquisição de dados para IA como um fluxo contínuo da descoberta da fonte à coleta, validação, armazenamento, transformação e entrega. Esse modelo se alinha melhor com sistemas de agentes, ferramentas de inteligência de mercado e camadas de recuperação que devem suportar decisões repetíveis.
Essa diferença importa porque sistemas de IA agem com base no que recebem. O Framework de Gestão de Risco de IA da NIST explica que a IA confiável depende de práticas de design, desenvolvimento, uso e avaliação, não apenas de saídas de modelos. Na prática, isso significa que a camada de recuperação faz parte da superfície de risco.
Outra razão é a política. Google Search Central afirma que o robots.txt é usado principalmente para gerenciar o tráfego de crawlers e não é um método universal para ocultar conteúdo. Essa lembrança importa para qualquer equipe que construa infraestrutura de dados da web. A conformidade começa antes da primeira solicitação.
Como as APIs de Pesquisa Funcionam em Sistemas de Recuperação de Dados
A descrição mais simples é esta. Uma API de pesquisa está na camada de descoberta. Ela converte uma consulta de texto em resultados classificados que podem alimentar chatbots, copilotos ou assistentes de pesquisa.
A maioria das ferramentas de pesquisa otimiza para velocidade e conveniência do desenvolvedor. Isso normalmente significa dados indexados, resultados em cache ou uma camada de relevância pré-construída. Para tarefas de baixo risco, isso é suficiente. Um bot de suporte, uma ferramenta de ideia de SEO ou um agente protótipo frequentemente se beneficiam desse tipo de ponto de extremidade de recuperação porque o sistema precisa de direção antes de precisar de evidências profundas.
Uma API de SERP é mais estreita. Ela se concentra nas páginas de resultados de mecanismos de pesquisa e elementos relacionados. Isso pode ser útil para monitoramento de classificação, monitoramento de consultas e pesquisa de SEO competitiva. No entanto, uma API de SERP ainda reflete a camada de pesquisa, não a camada completa de conteúdo. Se o seu sistema precisar de texto de página real, campos estruturados ou comparações históricas, geralmente você precisa de outro passo.
É aqui que as pessoas confundem descoberta com conhecimento. A descoberta diz onde olhar. O conhecimento exige buscar, analisar e verificar o que realmente está lá. Um ponto de extremidade de pesquisa ajuda na primeira parte. Ele não completa toda a pipeline de dados de IA.
O que é uma Cadeia de Suprimentos de Conhecimento na Arquitetura de IA
A melhor forma de defini-lo é operacional. Uma cadeia de suprimentos de conhecimento é o sistema que move dados da web aberta para contexto pronto para decisão para modelos, agentes e analistas.
A ideia da cadeia de suprimentos aparece em escritos recentes da indústria, mas muitos artigos param no metáfora. A versão prática tem seis camadas. Primeiro vem a descoberta por meio de interfaces de pesquisa, uma API de SERP, feeds, sitemaps ou fontes conhecidas. Segundo vem a extração por meio de uma API de raspagem de web, automação de navegador ou conectores diretos de fonte. Terceiro vem a normalização, onde HTML, JSON, PDFs e metadados são transformados em registros consistentes. Quarto vem a verificação, que verifica atualização, duplicação, propriedade e qualidade da fonte. Quinto vem o armazenamento e indexação para recuperação. Sexto vem a orquestração, onde uma pipeline de dados de IA envia o resultado para sistemas RAG, avaliadores ou ferramentas de agente.
O Model Context Protocol oferece uma dica útil aqui. Documentação do MCP o define como um padrão aberto para conectar aplicações de IA a fontes de dados, ferramentas e fluxos de trabalho. Ele não substitui uma camada de pesquisa, mas mostra por que uma cadeia de suprimentos de conhecimento deve incluir interfaces além da recuperação.
Em resumo, uma API de pesquisa é uma ferramenta. Uma cadeia de suprimentos de conhecimento é um sistema.
Diferenças Principais Entre APIs de Pesquisa e Cadeias de Suprimentos de Conhecimento
A resposta mais clara está nas restrições de operação. Uma API de pesquisa é normalmente otimizada para pesquisa rápida. Uma cadeia de suprimentos de conhecimento é otimizada para qualidade dos dados sob cargas de trabalho reais.
Resumo da Comparação
| Dimensão | API de pesquisa | API de SERP | Cadeia de suprimentos de conhecimento |
|---|---|---|---|
| Função principal | Descoberta baseada em consulta | Coleta de elementos de SERP classificados | Aquisição de dados completa para IA |
| Saída típica | Links, trechos, resumos | Elementos de SERP classificados | Conteúdo completo, metadados, histórico, validação |
| Ideal para | Protótipos, assistentes, pesquisas leves | Monitoramento de SEO, rastreamento de resultados | Agentes, sistemas de inteligência, IA de produção |
| Controle de atualização | Limitado e dependente do provedor | Moderado na camada de pesquisa | Alto quando combinado com coleta direta |
| Profundidade da evidência | Baixa a média | Baixa a média | Alta |
| Adequação à governança | Limitada | Moderada | Forte |
| Papel na pipeline de dados de IA | Primeiro passo | Primeiro passo com foco em SERP | Modelo de operação de múltiplas etapas |
A lacuna competitiva em artigos atuais é orientação prática. Muitos posts explicam por que as ferramentas de pesquisa são rápidas ou por que as cadeias de suprimentos de conhecimento parecem estratégicas. Poucos explicam onde uma termina e a outra começa dentro da infraestrutura real de dados da web. Essa fronteira é o que determina a confiabilidade do sistema.
Uma segunda diferença é a auditabilidade. Quando um modelo responde apenas com trechos, as equipes frequentemente não conseguem inspecionar o caminho de transformação da fonte. Quando uma cadeia de suprimentos de conhecimento armazena conteúdo de página, datas, registros de extração e verificações de qualidade, a mesma resposta é mais fácil de revisar e melhorar.
Uma terceira diferença é o custo de falha. Se uma API de descoberta retorna um resumo desatualizado, um aplicativo de chat de protótipo pode ainda parecer aceitável. Se o mesmo problema afeta inteligência de preços ou monitoramento de políticas, o custo pode ser muito maior.
Casos de Uso em Agentes de IA e Infraestrutura de Dados
O encaixe é mais fácil de ver por meio de casos de uso. Uma API de pesquisa funciona bem quando o sistema precisa de orientação rápida. Um agente pode usar essa camada de recuperação para encontrar URLs candidatas, menções recentes ou clusters de tópicos antes que a recuperação mais profunda comece.
Uma API de SERP funciona bem quando a tarefa é voltada para pesquisa. Equipes de SEO usam uma API de SERP para monitorar classificação, analisar resultados pagos e orgânicos e testar consultas regionais. A saída é útil, mas permanece uma camada de evidência.
Uma cadeia de suprimentos de conhecimento é melhor quando a tarefa é operacional. Monitoramento de preços, inteligência de leads, monitoramento de políticas, enriquecimento de catálogos, pesquisa de aquisição e verificação de notícias exigem mais do que resultados classificados. Eles precisam de extração, datas, controle de esquema e uma pipeline de dados de IA confiável.
Isso também é onde a ferramenta interna importa. Equipes que constroem agentes podem combinar frameworks de agentes de IA, melhores ferramentas de extração de dados e escalonamento de coleta de dados para treinamento de LLM em uma única pilha. Esses componentes são mais fáceis de avaliar quando você separa descoberta, extração e orquestração em vez de tratar cada entrada upstream como a mesma categoria de ferramenta.
Implicações para Ferramentas de Raspagem de Web e Engenharia de Dados
A maior lição é que recuperação sozinha não produz dados confiáveis. Uma API de raspagem de web importa porque converte links em registros úteis. Uma camada de engenharia de dados importa porque conteúdo de página bruto é inconsistente, ruidoso e frequentemente duplicado.
É por isso que o design de coleta conforme a regulamentação é importante. Respeite as diretrizes de robots, limites de taxa, políticas de acesso e restrições contratuais. As diretrizes de crawlers do Google deixam claro que gerenciamento de tráfego e comportamento de crawl são parte do ambiente operacional normal da web. Uma infraestrutura sólida de dados da web deve reduzir a carga nos servidores, documentar regras de fonte e preservar trilhas de auditoria.
Do ponto de vista de ferramentas, a pilha normalmente se parece com isso. Uma API de descoberta ou SERP identifica alvos. Uma API de raspagem de web ou ferramenta de navegador coleta conteúdo. Uma pipeline de dados de IA analisa, enriquece e armazena registros. Ferramentas de avaliação pontuam atualização e confiabilidade da fonte. Em seguida, frameworks de agente ou sistemas RAG usam o resultado.
A confiabilidade operacional também merece uma nota realista. Algumas fluxos de automação aprovados enfrentam etapas de verificação que interrompem coleta ou monitoramento. Nesses casos, as equipes às vezes adicionam um serviço de suporte como por que a automação da web falha repetidamente em captchas ou agentes de IA para monitoramento de preços para manter fluxos autorizados estáveis. Se isso faz parte da sua pilha, o CapSolver é relevante porque oferece padrões de API documentados para esses cenários.
A forma mais segura de discutir CapSolver é ficar próximo à documentação oficial. O exemplo abaixo replica o formato de solicitação createTask documentado na guia da API do CapSolver e deve ser usado apenas em ambientes de automação aprovados.
json
POST https://api.capsolver.com/createTask
Host: api.capsolver.com
Content-Type: application/json
{
"clientKey": "SUA_CHAVE_DE_API",
"appId": "ID_DO_APP",
"task": {
"type": "ImageToTextTask",
"body": "IMAGEM_EM_BASE64"
}
}Esse exemplo não é o núcleo de uma cadeia de suprimentos de conhecimento. É um componente de confiabilidade adicional. O ponto principal permanece o mesmo. Descoberta, coleta e governança devem ser projetadas juntas.
Resgate seu código promocional do CapSolver
Aumente seu orçamento de automação instantaneamente!
Use o código promocional CAP26 ao recarregar sua conta do CapSolver para obter um bônus adicional de 5% em cada recarga — sem limites.
Resgate-o agora em seu Painel do CapSolver
Conclusão
A conclusão prática é simples. Uma API de pesquisa ajuda os sistemas a encontrar informações, mas uma cadeia de suprimentos de conhecimento ajuda os sistemas a confiar, reutilizar e operacionalizar. Se sua carga de trabalho for exploratória, essa camada de recuperação pode ser suficiente. Se sua carga de trabalho afetar produto, receita ou conformidade, você precisa de uma infraestrutura de dados da web mais abrangente com extração, validação e armazenamento integrados.
Para a maioria das equipes, o design vencedor é híbrido. Use uma API de descoberta ou SERP para descoberta. Use uma API de raspagem de web para coleta de conteúdo. Em seguida, conecte ambas a uma pipeline de dados de IA com políticas claras de fonte, monitoramento e revisão. Essa é a maneira mais duradoura para aquisição de dados para IA.
Se você está planejando o próximo passo, audite sua pilha atual por camada. Pergunte onde a descoberta termina, onde a evidência começa e onde a governança é registrada. Esse exercício geralmente revela se você precisa de uma interface mais rápida, uma pipeline mais profunda ou ambas.
Perguntas Frequentes
A API de pesquisa é a mesma que a API de SERP?
Não. Uma API de pesquisa é uma interface de recuperação ampla, enquanto uma API de SERP se concentra nas páginas de resultados de mecanismos de pesquisa e elementos relacionados.
Quando esse tipo de interface de recuperação é suficiente para aplicações de IA?
Geralmente é suficiente para protótipos, assistentes internos, tarefas de pesquisa de baixo risco e etapas iniciais de descoberta em uma pipeline.
O que torna a cadeia de suprimentos de conhecimento melhor para IA de produção?
Uma cadeia de suprimentos de conhecimento adiciona extração, normalização, validação, armazenamento e orquestração. Essas camadas melhoram atualização, auditabilidade e reutilização.
Onde uma API de raspagem de web se encaixa nesse modelo?
Uma API de raspagem de web fica após a descoberta. Ela transforma URLs e páginas de fonte em conteúdo estruturado que uma pipeline de dados de IA pode processar.
Por que mencionar o CapSolver em um artigo sobre infraestrutura de dados de IA?
Porque alguns fluxos de automação aprovados enfrentam interrupções de verificação após a descoberta. Nesse contexto estreito, CapSolver pode suportar continuidade operacional como um componente dentro de um sistema mais amplo, consciente de políticas.