ウェブスクレイピング検出回避技術: 安定したデータ抽出

Anh Tuan
Data Science Expert
TL;Dr
- IPローテーションとプロキシ: リゾーデンタルまたはモバイルプロキシを通じてリクエストを配布することで、IPベースのブロックとレートリミットを防止します。
- ヘッダーオプティマイズ: 実際のブラウザヘッダーを模倣し、特にUser-AgentとRefererを変更することで、基本的なHTTPフィルタリングを回避します。
- ブラウザファイントリッピングの軽減: Canvas、WebGL、およびTLSファイントリッピングを管理することで、進んだ行動検出を回避することが不可欠です。
- JavaScriptチャレンジの処理: ヘッドレスブラウザはJavaScriptを実行できますが、検出を避けるために注意深く構成する必要があります。
- CAPTCHAの解決: CapSolverなどの自動CAPTCHA解決サービスを統合することで、データ抽出ワークフローの停止を防ぎます。
イントロダクション
データ抽出は現代のビジネスインテリジェンスにおいて重要な要素ですが、ウェブサイトはますます複雑な防御を導入して自動アクセスをブロックしています。開発者にとって、ウェブスクラピングのアンチデテクションテクニックを理解することはもはやオプションではなく、安定した信頼性のあるデータパイプラインを維持するための基本的な要件となっています。このガイドでは、ボット検出の基本的なメカニズムから、進んだブラウザファイントリッピングに至るまで、その背後にある仕組みを検討します。これらの防御戦略を理解することで、データエンジニアやスクラピング専門家は堅牢な方法論を実装し、公開情報への一貫したアクセスを確保できます。ここでの焦点は、検出を回避しながら倫理的でコンプライアンスに準じたスクラピング実践を維持するための実用的で構造的なアプローチです。
ウェブスクラピングにおけるアンチデテクションとは?
ウェブスクラピングのアンチデテクションテクニックとは、開発者が自動スクリプトがターゲットウェブサイトによって識別されブロックされないようにするための方法とツールを指します。スクリッパーがウェブサイトにアクセスすると、デジタル的な足跡を残します。この足跡が通常のユーザー行動と異なる場合、ウェブサイトのセキュリティシステムはその活動を自動化されたものとしてマークします。
アンチデテクションの主な目的は、人間の行動をできるだけ正確に模倣することです。これは、ネットワークレベルの識別子(IPアドレスなど)とアプリケーションレベルの特徴(HTTPヘッダーとブラウザファイントリッピングなど)を管理することを含みます。これらのテクニックがなければ、スクリッパーは即座にIPブロック、CAPTCHAチャレンジ、またはハニーポットのような偽の応答に直面することになります。ボット検出の背後にある技術を理解することが、信頼性の高いデータ抽出システムを構築する第一歩です。
ウェブサイトがスクリッパーを検出する方法
ウェブサイトの管理者は、自動トラフィックを識別し、軽減するための多層的なアプローチを採用しています。これらの防御は、単純なルールベースのフィルタから、リアルタイムでユーザー行動を分析する複雑な機械学習アルゴリズムに至ります。
IPアドレスとレートリミッティング
最も基本的な検出方法は、到着するリクエストの頻度と出所をモニタリングすることです。特定のIPアドレスが短時間内で異常に高い量のトラフィックを生成すると、サーバーはそのIPをブロックする可能性が高くなります。これはレートリミッティングと呼ばれます。さらに、ウェブサイトは既知のデータセンターアドレス範囲のブラックリストを保持しており、これらのソースからのトラフィックはすぐに疑いの対象とされます。
HTTPヘッダー分析
すべてのHTTPリクエストには、クライアントに関する情報を提供するヘッダーが含まれます。セキュリティシステムはこれらのヘッダーを厳しく検証し、特にUser-Agentを注目します。これはブラウザとオペレーティングシステムを識別します。デフォルトのライブラリを使用するスクリッパーは、欠損または異常なヘッダーを送信することがあります。たとえば、Accept-Languageヘッダーが欠如しているか、古いUser-Agent文字列を提示している場合、これは自動化された活動の強い兆候です。
ブラウザファイントリッピング
進んだ検出システムはヘッダーを越えて、クライアントブラウザのユニークな特徴を分析します。このテクニックはブラウザファイントリッピングと呼ばれ、画面解像度、インストールされたフォント、サポートされるプラグイン、ハードウェアの並列性などのデータを収集します。さらに高度な方法では、CanvasとWebGLファイントリッピングが使われ、ブラウザに非表示の画像をレンダリングし、ハードウェアがグラフィックスを処理する方法のわずかな違いを分析します。これらの微細な変化は、デバイスの非常に正確な識別子を作成します。
行動分析とハニーポット
現代のセキュリティソリューションは、ユーザーがページとどのように関与するかを評価します。マウスの動き、スクロールパターン、クリック間のタイミングをトラッキングします。ボットは通常、線形で予測可能な行動を示しますが、人間は予測不能です。さらに、ウェブサイトはハニーポットを配置しています。これは、人間ユーザーには見えない隠しリンクやフォームフィールドで、HTMLを解析するスクリッパーが発見します。ハニーポットと対話することは、ボットの存在を即座に明らかにします。
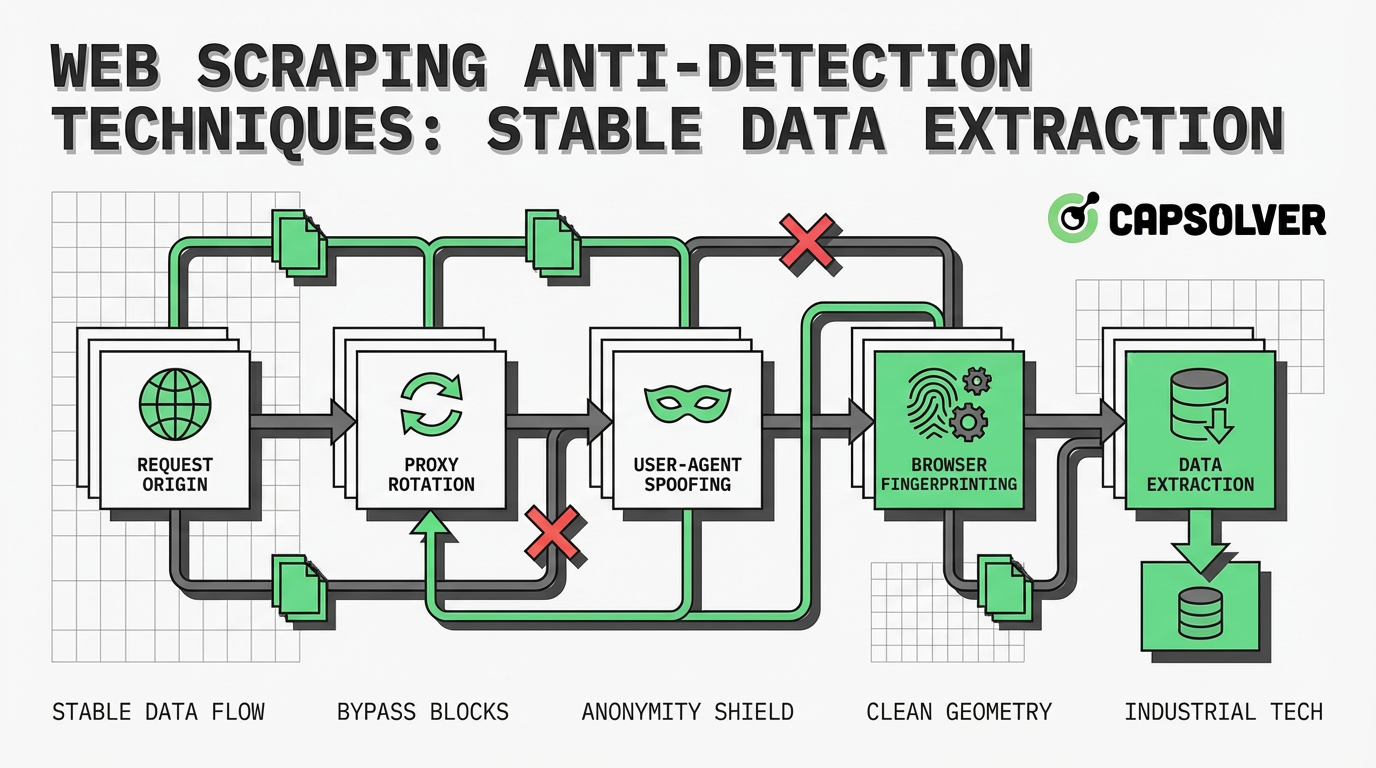
ウェブスクラピングのアンチデテクションの核心的テクニック
安定したデータ抽出を維持するため、開発者はウェブサイトの防御の各層に対抗する戦略を実装する必要があります。以下の方法が、効果的なアンチデテクションの基盤となります。
IPローテーションとプロキシの実装
単一のIPアドレスに依存することは、ブロックされる確実な道です。レートリミッティングとIPブロックを回避するため、スクリッパーはプロキシネットワークを活用する必要があります。リクエストを異なるIPアドレスを通じてルーティングすることで、スクリッパーはトラフィックを分散させ、複数のユーザーがサイトにアクセスしているように見せかけます。
データセンタープロキシは高速でコスト効果が高く、しかし簡単に識別されます。高セキュリティのターゲットでは、リゾーデンタルプロキシが必要です。これらのプロキシは、インターネットサービスプロバイダー(ISP)が提供する実際のデバイスを通じてトラフィックをルーティングし、はるかに高い信頼性を提供します。IPアドレスを効果的に管理する方法については、このガイドを参照してください: IPブロックを避ける方法。
HTTPヘッダーの最適化
現実的なHTTPヘッダーを作成することは、基本的なフィルタリングを回避するために不可欠です。User-Agent文字列は、現代で広く使用されているブラウザに一致する必要があります。しかし、単にUser-Agentを変更するだけでは不十分です。ヘッダー全体のプロファイルが一貫している必要があります。
たとえば、User-AgentがWindowsマシンを示している場合、Sec-Ch-Ua-PlatformヘッダーもWindowsを反映する必要があります。Accept、Accept-Encoding、Refererなどのヘッダーを含めることで、リクエストに信頼性を追加します。Refererヘッダーは、以前に訪れたページを示し、人間のトラフィックをシミュレートするために、人気のある検索エンジンに設定できます。詳細な推奨事項については、最適なUser-Agentの選択に関するリソースを参照してください。
ヘッドレスブラウザの活用
多くの現代のウェブサイトはJavaScriptに強く依存し、コンテンツを動的にレンダリングします。従来のHTTPクライアントはJavaScriptを実行できず、データ抽出が不完全になります。Puppeteer、Playwright、またはSeleniumなどのヘッドレスブラウザは、グラフィカルユーザーインターフェースなしで完全なブラウザ環境を実行することで、この問題を解決します。
ヘッドレスブラウザはJavaScriptを実行し、動的なコンテンツを処理し、ページとリアルユーザーと同じように対話できます。しかし、デフォルトのヘッドレス設定は識別可能な変数を漏洩するため、開発者はステルスプラグインや特別なフレームワークを使用してこれらのインジケータを隠し、ヘッドレスブラウザが検出されないようにする必要があります。
リクエストの頻度管理
行動分析を打ち勝つために、スクリッパーは予測可能なリクエストパターンを放棄する必要があります。リクエスト間のランダムな遅延を実装することで、人間が読み込みやサイト内移動中に取る自然な一時停止をシミュレートします。さらに、ヘッドレスブラウザ環境内でランダムなマウスの動きとスクロール動作を追加することで、ユーザーインタラクションを監視するシステムを回避するのに役立ちます。
検出 vs. 対策の比較要約
| 検出方法 | 説明 | 対策戦略 |
|---|---|---|
| IPレートリミッティング | 特定のリクエスト閾値を超えるIPをブロックします。 | 回転するリゾーデンタルまたはモバイルプロキシネットワークを使用します。 |
| ヘッダーフィルタリング | HTTPヘッダーに異常や欠損データがあるかを分析します。 | 一貫性があり、現代的なヘッダー(User-Agent、Referer、Accept)を作成します。 |
| ブラウザファイントリッピング | ハードウェアとソフトウェアの特徴に基づいてデバイスを識別します。 | ファイントリッピングをスプーフィングするためのアンチデテクトブラウザまたはステルスプラグインを使用します。 |
| JavaScriptチャレンジ | コンテンツへのアクセスやクライアントの検証にJS実行を要求します。 | ステルス設定を備えたヘッドレスブラウザ(Playwright、Puppeteer)を配置します。 |
| ハニーポットトラップ | 自動パーサーを捕らえるために設計された隠しHTML要素です。 | 要素と対話する前にCSSの可視性プロパティを分析します。 |
高度な課題: CAPTCHAとセキュリティシステム
IPローテーションとヘッダー最適化が完璧でも、スクリッパーは頻繁にCAPTCHAに遭遇します。これらのチャレンジは、ユーザーが視覚的なパズルを解くか、複雑な行動データを分析するように要求することで、人間とボットを区別するように設計されています。
Cloudflare TurnstileやDataDomeなどのセキュリティシステムは、クライアントのIP信頼性、TLSファイントリッピング、および行動履歴を評価して、CAPTCHAを提示するかどうかを決定します。スクリッパーがこれらの障壁に直面した場合、スケールでの手動の介入は不可能です。これは、データパイプラインを維持するために自動解決サービスが不可欠である理由です。現在のトレンドについての洞察は、2025年のウェブスクラピング時のCAPTCHA解決に関する記事を参照してください。
CapSolverによるCAPTCHA解決の自動化
ウェブスクラピングのアンチデテクションテクニックが限界に達した場合、CapSolverは複雑なCAPTCHAを処理する信頼性の高いソリューションを提供します。CapSolverはAI駆動のサービスで、reCAPTCHA、Cloudflare Turnstile、および画像ベースのパズルなどのさまざまなチャレンジを自動的に解決します。
スクラピングアーキテクチャにCapSolverを統合することで、これらの中断をプログラム的に回避できます。このサービスは、高速で正確にチャレンジを分析および解決するための高度な機械学習モデルを使用し、データ抽出プロセスが効率的で中断されずに運用されることを保証します。これは、CAPTCHAに頻繁に遭遇する高ボリュームスクラピングタスクにおいて特に価値があります。
CapSolverで登録する際、コード
CAP26を使用してボーナスクレジットを取得してください!
インテグレーション例: reCAPTCHA v2の解決
PythonベースのスクラピングスクリプトにCapSolverを統合するのは簡単です。以下の例は、CapSolver APIを使用してreCAPTCHA v2チャレンジを解決する方法を示しています。この方法では、CapSolverの内部プロキシインフラストラクチャを活用するReCaptchaV2TaskProxyLessタスクタイプを使用します。
python
import requests
import time
# 設定
API_KEY = "YOUR_CAPSOLVER_API_KEY"
SITE_KEY = "6Le-wvkSAAAAAPBMRTvw0Q4Muexq9bi0DJwx_mJ-"
SITE_URL = "https://www.google.com/recaptcha/api2/demo"
def solve_recaptcha():
# ステップ1: タスクを作成
payload = {
"clientKey": API_KEY,
"task": {
"type": "ReCaptchaV2TaskProxyLess",
"websiteKey": SITE_KEY,
"websiteURL": SITE_URL
}
}
response = requests.post("https://api.capsolver.com/createTask", json=payload)
task_data = response.json()
task_id = task_data.get("taskId")
if not task_id:
print("タスクの作成に失敗しました:", response.text)
return None
print(f"タスクが正常に作成されました。タスクID: {task_id}")
# ステップ2: 結果をポーリング
while True:
time.sleep(2)
result_payload = {
"clientKey": API_KEY,
"taskId": task_id
}
result_response = requests.post("https://api.capsolver.com/getTaskResult", json=result_payload)
result_data = result_response.json()
status = result_data.get("status")
if status == "ready":
print("CAPTCHAは正常に解決されました!")
return result_data.get("solution", {}).get("gRecaptchaResponse")
elif status == "failed" or result_data.get("errorId"):
print("CAPTCHAの解決に失敗しました:", result_response.text)
return None
# ソルバーを実行
token = solve_recaptcha()
if token:
print(f"トークンを取得しました: {token[:50]}...")
# トークンをターゲットウェブサイトに送信して処理を続行より詳細な実装戦略については、Pythonを使用したウェブスクラピングでのreCAPTCHAの解決方法に関する包括的なガイドを参照してください。
倫理的配慮とコンプライアンス
ウェブスクラピングのアンチデテクションテクニックを習得することは、技術的な成功にとって不可欠ですが、倫理的配慮とバランスを取ることが重要です。データ抽出は、ターゲットウェブサイトのインフラと利用規約を尊重することが常に必要です。
開発者はrobots.txtファイルに記載されたガイドラインに従うべきです。これは、クローリングが許可されていると許可されていない領域を明示しています。さらに、合理的なレートリミットを実装することで、スクラピング活動が正当なユーザーのウェブサイトのパフォーマンスを低下させないことを保証します。責任あるスクラピングは、プライバシーレギュレーションに違反することなく、公開されているデータを抽出することに焦点を当てています。
結論
データ抽出の複雑さを成功裏に乗り切るには、ウェブスクラピングのアンチデテクションテクニックの深い理解が不可欠です。安定したIPローテーションの実装、HTTPヘッダーの最適化、ブラウザファイントリッピングの管理を通じて、開発者はブロックされる可能性を大幅に低減できます。しかし、セキュリティシステムが進化する中、CAPTCHAに遭遇することは依然として持続的な課題です。CapSolverなどの自動化されたソリューションを統合することで、スクラピングインフラストラクチャが耐性を保ち、より制限されたデジタル環境において安定した継続的なデータ収集を可能にします。
FAQ
ウェブスクラピングで一般的なアンチデテクションテクニックはどれですか?
一般的なテクニックには、プロキシネットワークを使用してIPアドレスをローテーションすること、HTTPヘッダー(特にUser-Agent)を偽装すること、ステルスプラグインを備えたヘッドレスブラウザを使用すること、およびリクエスト間でランダムな遅延を実装して人間の行動を模倣することなどが含まれます。
なぜウェブサイトはウェブスクリッパーをブロックするのでしょうか?
ウェブサイトは、自動化されたトラフィックによってサーバーのリソースが過負荷になるのを防ぐために、独自のまたは著作権のあるデータを保護し、競合他社が価格やコンテンツ戦略を監視することを防ぐためにスカッパーをブロックします。Cloudflareによると、悪意のあるボットは大きな帯域幅を消費し、ユーザー体験を低下させる可能性があります。
ブラウザファイントプリントはボット検出でどのように機能しますか?
ブラウザファイントプリントは、ユーザーのデバイスに関する特定の詳細、例えば画面解像度、オペレーティングシステム、インストールされたフォント、ハードウェアの機能などを収集します。これらのデータポイントを組み合わせることで、セキュリティシステムはユニークな識別子を作成し、IPアドレスを変更したりクッキーを削除したりしてもスカッパーを追跡およびブロックできます。
ヘッドレスブラウザはすべての検出システムを回避できますか?
いいえ。ヘッドレスブラウザはJavaScriptを実行でき、動的なコンテンツを処理できますが、デフォルトの設定は、WebDriver変数を分析するような高度なセキュリティシステムによって簡単に検出されます。開発者は、ブラウザの自動化された性質を隠すためにステルスの修正を適用する必要があります。
データ抽出中にCAPTCHAをどう処理すればよいですか?
CAPTCHAに遭遇した場合、大規模なスクリーニングにおいて最も効率的なアプローチは、CapSolverなどの自動解決APIを統合することです。これらのサービスは機械学習を使用してチャレンジを自動的に解決し、スクリーニングスクリプトが手動の介入なしで作業を続けることができるようにします。