ReCAPTCHA と イーコマーススクレイピング: コンプライアンス第一のガイド

Sora Fujimoto
AI Solutions Architect
TL;DR
- ReCAPTCHAは、ECサイトがより強い信頼チェックを必要とするときに表示されます。
- ReCAPTCHAをパズルとしてではなく、ワークフローのシグナルとして扱いましょう。
- パーミッション、robots.txt、利用規約、データ範囲を最初に確認してください。
- スピードと安定したセッションで、無駄なチャレンジを減らしてください。
- 利用可能な場合は、公式APIまたはフィードを使用してください。
- CapSolverは、正当な自動化と許可されたデータ作業のみに使用してください。
- 各クローラーに対してロギング、レートリミット、エスカレーションルールを保持してください。
はじめに
ECサイトでのスクリーピングにおけるReCAPTCHAは、コンプライアンスを最優先にしたプロセスで処理する必要があります。より積極的なクローリングではなく、権限を尊重し、ノイズの多いトラフィックを減らし、許可された場合にのみ文書化された解決手順を使用することが正しい対応です。このガイドは、公共のECデータを責任を持って収集するデータエンジニア、SEOチーム、価格分析者、成長チーム向けです。ReCAPTCHAが表示される理由、遅くするタイミング、およびCapSolverが正当なプロセスに適合するタイミングについて説明します。
エコマースクローラーがreCAPTCHAに遭遇する理由
ReCAPTCHAが表示されるのは、ECサイトが価値ある顧客およびビジネスフローを保護するためです。製品ページ、検索ページ、カート、ログインはすべてビジネスリスクを伴います。GoogleはreCAPTCHAを、サイトがスパムや不正行為から保護するためのサービスと説明しています。これは、シグナルとスコアを使用して、人間とボットを区別する高度なリスク分析を通じて実現されます。Google reCAPTCHAドキュメンテーション。
エコマースチームは、自動化されたトラフィックが一般的になったためreCAPTCHAを追加しています。ThalesとImpervaは、2024年の自動化トラフィックがウェブトラフィックの51%に達したと報告しています。また、有害な自動化されたアクティビティはインターネットトラフィックの37%を占め、APIを介した攻撃は高度なボットトラフィックの44%を占めていると報告しています。2025年Imperva悪質ボット報告。この文脈が、サイトが通常のクローリングパターンを迅速にチャレンジする理由を説明しています。
reCAPTCHAは、支払いやアカウントフローの近くでも一般的です。Google Cloudは、reCAPTCHAのトランザクション防御が、カード詐欺や不正取引から支払いトランザクションを保護すると述べています。Google Cloudトランザクション防御。カート、チェックアウト、またはアカウントページにアクセスするクローラーは、公開された製品モニタリングよりも厳格なチェックを受けることになります。
最初のルール:データが許可されていることを確認する
コンプライアンスは技術的な変更よりも優先されます。クローラーは、公開された、許可された、そして必要なデータのみを収集する必要があります。ログイン専用ページ、プライベートな顧客データ、チェックアウトステップ、および明示的な承認なしに制限された領域を避けるべきです。
ロボット排除プロトコルも重要です。RFC 9309では、robots.txtがサービスオーナーがクローラーがURI空間にアクセスする方法を制御する手段を提供し、クローラーがこれらのルールを尊重することを求めています。RFC 9309ロボット排除プロトコル。robots.txtは唯一の法的テストではありませんが、信頼できるクローラーは実行前に解析する必要があります。
reCAPTCHAを処理する前に、4つの項目をドキュメント化してください。ビジネス目的、ソースページ、データフィールド、許可されたパス、利用規約、リクエスト制限、並行性、および保持期間を定義してください。これにより、reCAPTCHA処理が管理されたデータプロセスになります。
CapSolverのreCAPTCHAとは何かに関するガイドは、関係者がチャレンジの種類を理解するのに役立ちます。
reCAPTCHAの種類を診断する
コードの変更を行う前に診断を行う必要があります。reCAPTCHA v2は通常、チェックボックスまたは視覚的なチャレンジとして表示されます。reCAPTCHA v3は通常、ユーザーの操作なしにスコアを返します。その結果、ページが劣化したり、アクションがブロックされたり、後でより強力なチェックが求められることもあります。GoogleはreCAPTCHA v3がスコアを返すことで、サイトオーナーがユーザーにチャレンジを表示することなくアクションを選択できると述べています。Google reCAPTCHA v3の概要。
| 情況 | おそらくの意味 | 推奨される対応 |
|---|---|---|
| 複数の高速リクエストの後にチャレンジが表示される | トレーフィックパターンが異常 | 同時接続数を減らし、ペーシングを追加 |
| ログインまたはチェックアウトでのみチャレンジが表示される | ページが高リスク | 明示的な承認がない限り停止 |
| 公開製品ページでチャレンジが表示される | セッションまたはリクエストパターンを確認 | クッキーを安定させ、バーストを減らす |
| v3スコアが空または劣化したページを引き起こす | 信頼スコアが低い | ブラウザのコンテキストとリクエストの頻度を確認 |
| リダイレクト後にチャレンジが表示される | フローの状態が不一致 | セッションとページの順序を保持 |
この診断はコストを制御します。落ち着いたクローラーは、より少ないチャレンジを引き起こし、クリーンなECデータを返します。
比較要約
有効なECクローラーは、最も侵襲的なオプションから始まります。以下の表は一般的な選択肢を比較します。
| アプローチ | 最適な使用ケース | コンプライアンスの注意点 | 操作リスク | コストプロファイル |
|---|---|---|---|---|
| 公式APIまたはマーケントフィード | パートナーのデータアクセス | 利用可能な場合が最善 | 低 | 予測可能 |
| ペーシングを用いた公開ページクローリング | 公開製品および価格モニタリング | robots.txtと利用規約を尊重 | 中 | 低〜中 |
| ブラウザオートメーション | JavaScriptが豊富な製品ページ | 制限されたフローを避ける | 中 | 中 |
| ヒューマンレビュークエュー | 稀な高価値チェック | 強い監査証跡 | 低 | 高い労働コスト |
| CapSolverの統合 | 許可された自動化でreCAPTCHAに遭遇 | 法的で善意のあるワークフローにのみ使用 | 中 | 使用に基づく |
この表は実用的なポイントを示しています。reCAPTCHAは、ルールと制限を尊重するクローラー内の例外パスでなければなりません。
クリーンなECスクラピングワークフローを構築する
クリーンなワークフローは、避けられないreCAPTCHAイベントを減らします。最初にページ選択を行ってください。公開された許可されたカテゴリーや製品ページのみをクロールしてください。ビジネスがアカウントを所有し、許可がある場合に限り、カートに商品を追加したり、フォームを送信したり、アカウントページを開けたりしてください。
次に、トラフィックの形状を制御してください。適度な並行性、バックオフルール、安定したスケジューリングを使用してください。ECサイトはセール、リリース、ホリデースパイク中に敏感です。これらの時間を尊重するクローラーは、運用上の負荷を生み出す可能性が低くなります。
セッション処理も重要です。短いクロール中にクッキーを一貫して保持してください。1つのセッション内で関連のないページフローを混ぜないでください。製品発見の経路は、突然チェックアウトページを要求してはなりません。このパターンはreCAPTCHAを表示する可能性があります。
チャレンジ率、空ページ、HTTPコード、価格パースエラー、重複を追跡してください。増加するreCAPTCHA率は、早期の警告です。
あなたのチームが直接クローリングと公式データアクセスの間で選択している場合、ウェブスクリーピングとAPIに関するこのCapSolver記事は、内部的な議論のための役立つリンクです。
CapSolverが適する場面
CapSolverは、コンプライアンスチェック後に正当な自動化プロセスがreCAPTCHAに遭遇した場合に適しています。SEOの監査、広告の検証、そして許可されたデータに対して良性のクローラーで役立ちます。CapSolver自身の立場は、違法、詐欺、または悪意のある活動は禁止されており、SEO、広告検証、良性のクローラー、およびビジネス成長のシナリオが意図された使用とされています CapSolverコンプライアンス声明。
この立場は重要です。CapSolverの統合は、プライベートアカウント、支払いステップ、制限されたコンテンツ、または明らかに禁止されたデータをターゲットにすることは決してありません。
あなたのクローラーがすでに尊重的なスケジュールをすでに持っているが、許可された公開ページでreCAPTCHAに遭遇する場合、CapSolverは毎回のチャレンジに手動作業を強制することなく安定したワークフローを維持するのに役立ちます。焦点を当てたECシナリオについては、CapSolverのECサイトをスクリーピングする際のCAPTCHAの解決方法に関するガイドを参照してください。
公式CapSolverコードリファレンス
以下のコードは、CapSolverの公式ドキュメンテーションに基づいたreCAPTCHA v2のタスクを作成します。現在のドキュメンテーションを確認せずにタスクタイプやパラメータを変更しないでください。このコードは、許可されたワークフローでのみ使用し、有効なAPIキーで使用してください。
python
# pip install requests
import requests
import time
# TODO: 設定を設定してください
api_key = "YOUR_API_KEY" # CapSolverのAPIキー
site_key = "6Le-wvkSAAAAAPBMRTvw0Q4Muexq9bi0DJwx_mJ-" # ターゲットサイトのサイトキー
site_url = "https://www.google.com/recaptcha/api2/demo" # ターゲットサイトのページURL
def capsolver():
payload = {
"clientKey": api_key,
"task": {
"type": 'ReCaptchaV2TaskProxyLess',
"websiteKey": site_key,
"websiteURL": site_url
}
}
res = requests.post("https://api.capsolver.com/createTask", json=payload)
resp = res.json()
task_id = resp.get("taskId")
if not task_id:
print("タスクの作成に失敗しました:", res.text)
return
print(f"タスクID: {task_id} / 結果を取得中...")
while True:
time.sleep(1) # 待ち時間
payload = {"clientKey": api_key, "taskId": task_id}
res = requests.post("https://api.capsolver.com/getTaskResult", json=payload)
resp = res.json()
status = resp.get("status")
if status == "ready":
return resp.get("solution", {}).get('gRecaptchaResponse')
if status == "failed" or resp.get("errorId"):
print("解決に失敗しました! レスポンス:", res.text)
return
token = capsolver()
print(token)公式CapSolverドキュメンテーションは、createTaskでタスクを作成し、getTaskResultで結果を取得することを説明しています。また、websiteURLやwebsiteKeyなどのフィールドがタスクに必要なことを説明しています。より多くの実装の文脈については、CapSolverの公式スタイルのPythonを使用してウェブスクリーピングでreCAPTCHAを解決する方法に関するガイドを参照してください。
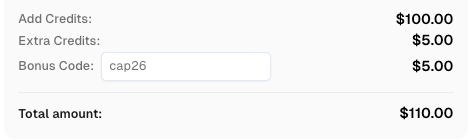
CapSolverのボーナスコードを取得する
自動化予算を即座に増やす!
CapSolverアカウントにチャージする際にボーナスコード CAP26 を使用すると、すべてのチャージに対して5%のボーナスが追加されます。制限はありません。
CapSolverダッシュボードで今すぐ利用してください
プロダクション用の実用的な制御
プロダクションでのECスクリーピングには、非エンジニアでも監査可能な制御が必要です。デプロイメント前にクローラーのポリシーを作成してください。ポリシーには、データ所有者、許可されたドメイン、許可されたパス、最大並行性、最大日間リクエスト数、保持期間、エスカレーション連絡先を記載してください。
reCAPTCHAの遭遇率を重要な指標として使用してください。この率が定義されたしきい値を上回った場合、クロール速度を減らすか、一時停止してください。制限されたフローでチャレンジが表示された場合、ジョブを停止してください。ターゲットがロボット排除プロトコルまたは利用規約を変更した場合、継続する前にクローラーを再確認してください。
データの範囲を狭く保つことが重要です。価格、在庫、タイトル、画像URL、および公開されたレビュー数は、一部のビジネスケースでは有効です。顧客名、ログイン後のプライベートレビュー、カートトークン、アカウントデータは、サイトオーナーがアクセスを許可した場合を除き、範囲外とします。
これは、フォールバックキューが役立つ場面です。クローラーは、解決できないページをレビュー用に保存するだけで、繰り返しリトライするのではなく、これにより負荷とコストが低下し、reCAPTCHA処理が説明可能になります。
さらに、エンジニアリングパターンについては、CapSolverの3つの方法でキャプチャを解決するに関する記事が実装計画をサポートします。
避けるべき一般的なミス
最初のミスは、reCAPTCHAを単なる技術的障壁と見なすことである。これは、クローラーが広範囲すぎたり、速すぎたり、意図されたフローから外れていることを示すことがよくある。ツールを追加する前にワークフローを修正してください。
2番目のミスは、ページの文脈を無視することである。ECサイトは検索、製品、カート、ログイン、チェックアウトページを別々に扱います。あなたのクローラーも同じように扱うべきです。公開製品モニタリングはアカウント自動化とは異なるリスクプロファイルを持っています。
3番目のミスは、監査ログを忘れることである。すべてのreCAPTCHAイベントは、URLグループ、タイムスタンプ、クローラーのバージョン、レスポンスコード、および取られた行動を記録する必要があります。
4番目のミスは、古くなったコードを使用することである。reCAPTCHAの実装は変化する。CapSolverのドキュメンテーションがコード構造、タスクタイプ、および必要なフィールドのソースです。
結論とCTA
ECサイトでのreCAPTCHAは、ガバナンス、診断、および注意深いツールの使用を通じて最適に処理されます。許可の確認、robots.txt、利用規約、およびデータ最小化から始めます。無駄なチャレンジを減らすために、ペーシング、安定したセッション、および制限された範囲で、回避可能なチャレンジを減らします。reCAPTCHAが許可された自動化プロセスで依然として表示される場合、CapSolverは公式ドキュメンテーションに基づいた実用的な解決層を提供します。
あなたのチームがECデータ収集中にreCAPTCHAを制御するための信頼できる方法が必要な場合、CapSolverのドキュメンテーションを確認し、コンプライアンスルールを定義し、最初に低ボリュームの公開ページでテストしてください。責任あるクローラーは、必要なものだけを収集し、ルールが変更されたら停止し、明確な監査証跡を残すべきです。
FAQ
Eコマーススクリーピング中にreCAPTCHAを処理することは法的に許可されていますか?
許可、データの種類、管轄、およびサイトの利用規約によります。より安全なワークフローは、公開された許可されたページを使用し、robots.txtを尊重し、プライベートデータを避けて、文書化された制限に従うことです。商用プロジェクトでは法的レビューが推奨されます。
なぜ製品ページでreCAPTCHAが表示されるのですか?
リクエストのボリューム、セッションの履歴、ブラウザのコンテキスト、またはトラフィックのタイミングが異常な場合、reCAPTCHAが表示されることがあります。また、価格と在庫ページに厳格な保護を適用するサイトでも表示されることがあります。
すべてのreCAPTCHAを解決する必要がありますか?
いいえ。高いreCAPTCHA率は、クローラーが見直される必要があることを示しています。速度を落とし、範囲を減らし、許可されたパスを確認し、解決は許可された例外ケースでのみ使用してください。
CapSolverはECサイトスクリーピングに役立ちますか?
はい、正当なeコマースの自動化ワークフローがreCAPTCHAに遭遇した場合、CapSolverは役立ちます。法的、良性和許可されたデータ作業のみに使用し、公式ドキュメントに従ってください。
配置後、何をモニタリングすべきですか?
reCAPTCHAのレート、ステータスコード、パースエラー、ボリューム、パスグループ、および未解決のキューをモニタリングしてください。しきい値が超過したときにはクローラーを一時停止してください。
もっと見る
AIJun 26, 2026
CAPTCHA: AIエージェントインフラの欠けている要素
なぜトラフィック検証がAIエージェントインフラストラクチャの欠かせない要素であるかを発見してください。自律型エージェント向けの堅牢なソリューションを統合する方法を学びましょう。
AIJun 26, 2026
CAPTCHA耐性をAIエージェントに組み込む
- AIエージェントは、自動化されたタスク中に継続的な運用を維持するために強力なCAPTCHAの耐性が必要です。 - 構造化されたトラフィック検証戦略を実装することで、リスク管理メカニズムによる混乱を最小限に抑えることができます。 - 信頼性の高いCAPTCHA解決APIを活用することで、複雑な課題の効率的な処理が保証されます。 - 適切なインフラ設計により、コアエージェントロジックとボット保護管理を分離することができます。