AIデータ抽出の仕組み:CAPTCHAの解決、LLMのパース、構造化ウェブデータパイプライン

Sora Fujimoto
AI Solutions Architect
はじめに:パーサーの領域を越えて、収集に焦点を当てる
従来のウェブデータ抽出は、CSSセレクターやXPath、正規表現などの機械的なマッチング手法に依存しており、DOMツリーの固定された位置にロックオンして値を取得しています。頻繁なページデザインの変更、動的レンダリングの広く普及、多段階のアンチスクラビングアップグレードに直面して、このパラダイムは高いメンテナンスコストや非同期コンテンツへの「無知さ」などの構造的な欠点を露呈しました。大規模言語モデル(LLM)の成熟が転機をもたらしました:データ抽出は「データがどのタグに位置しているか?」ではなく、「ページのコンテンツがどの質問に答えているか?」を理解することになりました。自然言語理解に駆動される新しいパラダイムへと移行しました。このシフトは純粋に理論的なものではなく、AXEなどのフレームワークは不要なDOMノードを削減し、小さなモデルと組み合わせて構造化出力を生成することで、SWDEデータセットでF1スコア88.1%を達成し、意味抽出の実現可能性と効率性を検証しました。この記事では、エンジニアリング実装の観点から、データフローの順序に従って各段階の技術的原則と重要なトレードオフを解説します。アンチクローリングやCAPTCHAに対応するデータ取得層から、コンテンツのクリーニングとLLMの意味抽出の処理層、最後に構造化データの保存と消費に至るまでをカバーします。
I. パラダイムの転換:ルールベースのパーシングから自然言語処理へ
AIデータ抽出の技術的詳細に入る前に、なぜ置き換えられる従来のパラダイムが限界に達したのか、そして新しいパラダイムがどの次元で突破を遂げたのかを理解することが必要です。
1.1 ルールベースのパーシング時代の3つのジレンマ
従来のウェブデータ抽出のコア手法は「パス位置指定」です。開発者はブラウザの開発者ツールを使用して、ターゲットデータが配置されているDOMノードを検査し、手動でCSSセレクターやXPath式を記述してそのノードを特定します。このパラダイムは過去10年間でウェブデータ収集の大部分を支えてきましたが、ウェブ技術の進化に伴い継続的に拡大する3つの構造的な欠点を抱えています。
1.1.1 脆弱なアンカー:動的な世界に適応できない静的ルール
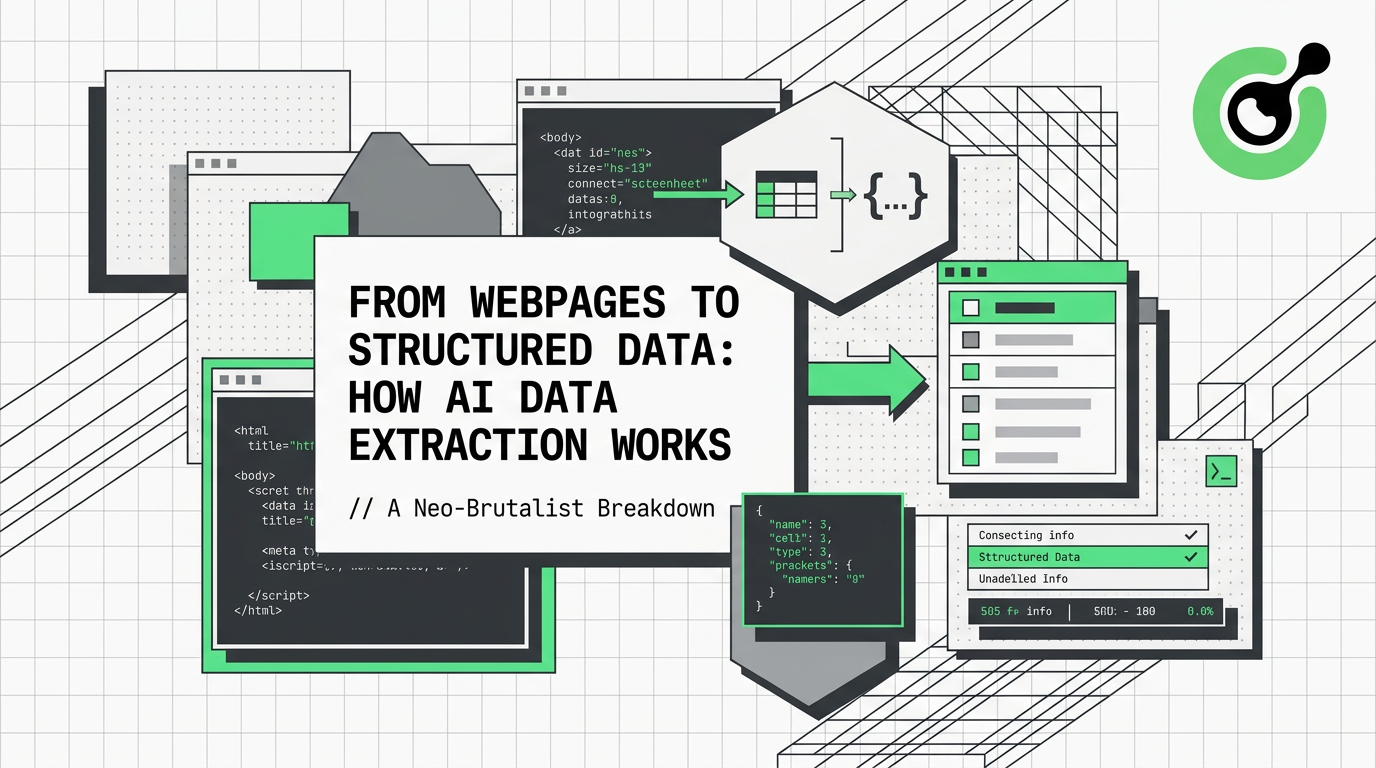
現代のウェブサイトは平均して3〜6か月ごとにDOM構造が大幅に変化します。各リデザインは、固定パスに依存するクローラーのルールを無効にします。同時に数百のターゲットノードを維持するチームにとって、これは継続的な「ホッパーマウル」なメンテナンスサイクルを構成します。図1-1は、現代のウェブサイトに直面した従来のクローラーの完全なワークフローを示し、リクエストからデータ抽出に至る各段階と遭遇する問題を示しています:
このプロセスは、静的パーシング能力と動的にレンダリングされたコンテンツの不一致という最初のジレンマのコアロジックを明らかにします。W3Techsの統計によると、2025年末までに、世界中の約X%のウェブサイトがCloudflareなどのアンチスクラビングサービスを使用する見込みです。Netcraftによる同時検出のウェブサイト総数に基づくと、これは2億9,000万サイト以上に及び、ウェブページの中央値JSサイズは500KBを超えています。従来のクローラーはレンダリングされていないスケルトンのみを取得でき、データが「見えない」だけでなく、ウェブサイトがリデザインされると、苦労して書かれたセレクターがすぐに無効になります。この「技術的無力化」と「メンテナンスの脆さ」が重なることで、ルールベースのパーシングの範囲は継続的に狭まっています。
1.1.2 目が見えない:構文マッチングは意味を捉えられない
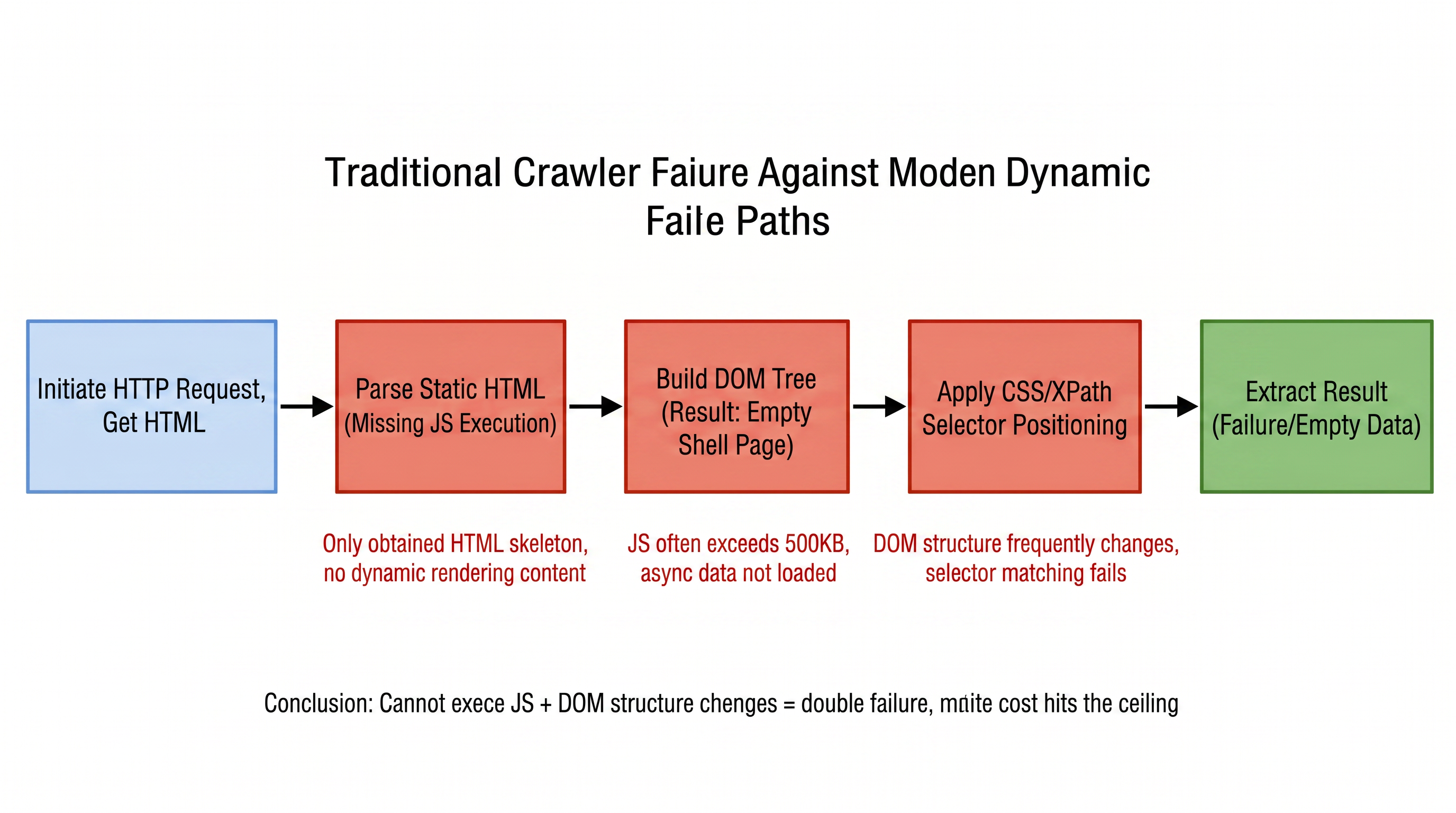
従来の方法は「データがこの位置にある」という質問には答えられますが、「この位置のデータは何ですか?」という質問には答えられません。同じ製品一覧ページで、プロモーション価格、推奨価格、製品価格が同時に存在する可能性があります。これらはDOMで同じタグを持ち、従来のルールでは区別がつかません。3つの異質な日付形式、「2026-04-28」、「April 28, 2026」、「28/04/2026」に直面した場合、従来のパーサーは各形式ごとに別個の正規表現を記述する必要があり、形式の動的な変化には対応できません。図1-2は、従来のルールベースのパーシングとAIの意味抽出の6つの主要次元における違いを視覚的に比較しています:
レーダーチャートの形状は、従来のルールベースのパーシングが「作業ロジック」次元で正確なDOMパス位置指定に依存していることを示しています。これは唯一の実行可能な戦略です。しかし、他の5つの次元では、そのパフォーマンスが全体的に制約されています。構造変化への適応能力は非常に弱く、動的レンダリング処理は外部ツールに完全に依存し、データ標準化には手動で正規表現を書く必要があります。メンテナンスコストはサイト数に比例して増加し、カバレッジは1サイトごとの1セットのルールに限定されています。6つの軸のうち5つは深刻に後退しており、グラフは「圧縮された」不規則な多角形に見えます。
一方、AIの意味抽出のレーダーチャートは内部と外部の両方で均等に拡張しています。意味理解に基づいて構造変化に自動的に適応し、ブラウザで完全に動的レンダリングを処理し、LLMの内部化された形式変換機能を通じてルールゼロの標準化を達成し、モデル能力の向上に伴ってメンテナンスコストが減少し、1つのSchemaでサイト全体の類似ページをカバーできます。
これらの6つの能力の欠点は、単なる技術的なバッフルではなく、下位のロジック「機械的なマッチング」の自然な結果です。データ抽出が文法レベルにとどまっている限り、ルールがどれだけ巧みに設計されていても、この構造的制約は克服できません。したがって、これらの問題を完全に解決するには、ルールの修補ではなく、パラダイムの変更が必要です。
1.1.3 現実的な限界:なぜこのパラダイムが置き換えられるのか
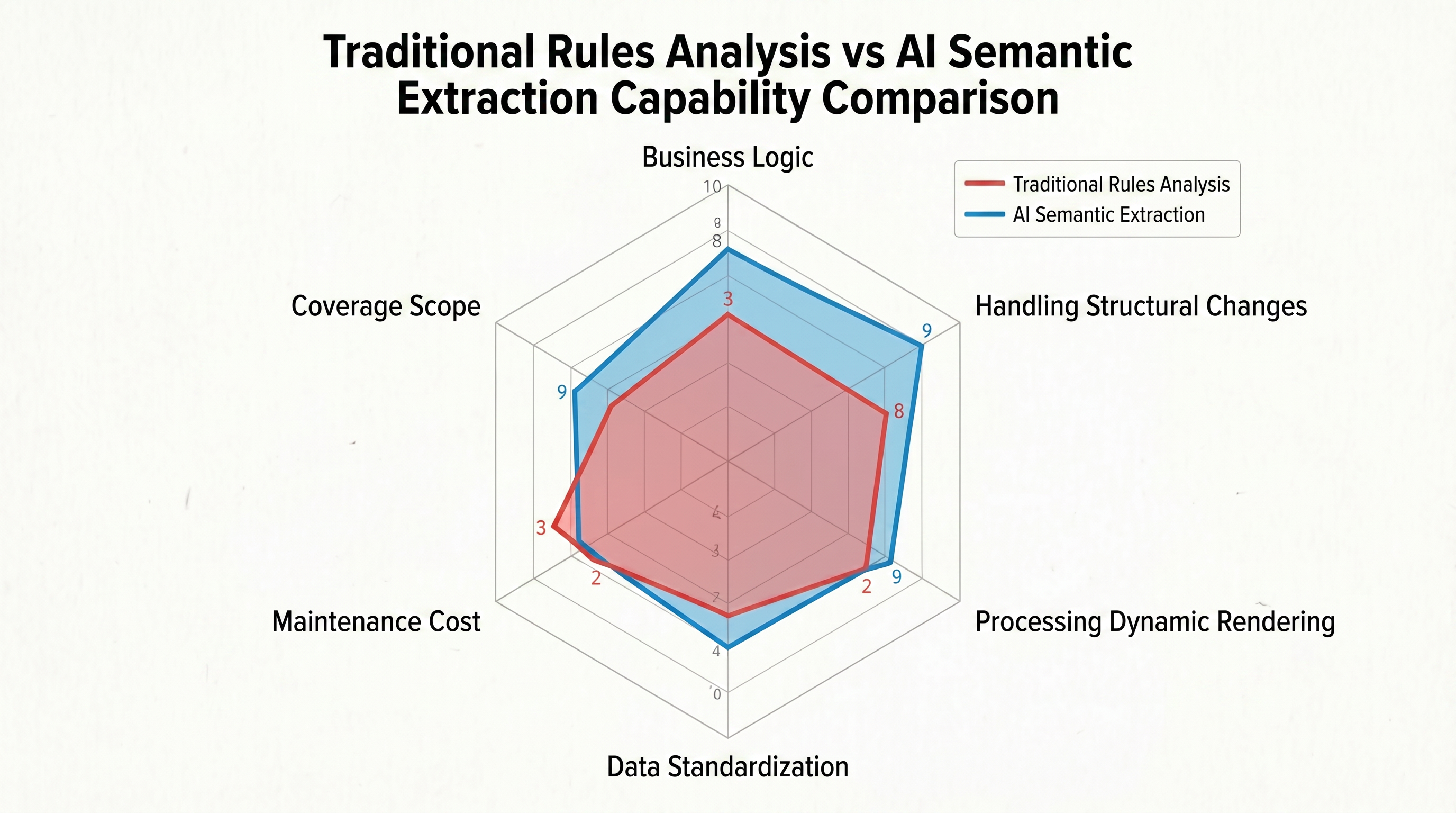
ルールベースのパーシングパラダイムのすべてのジレンマは、一つの源に起因しています。それは常に「文法レベルで機械的なマッチング」を行うという作業ロジックです。この作業ロジックは「正確な位置指定」の能力を実現するものの、ページ構造の変化に「受動的に適応」するコストを伴います。サイトがリデザインされると、ルールが無効になります。データタイプが異質になると、新しい正規表現を手動で記述する必要があります。このように、ターゲットウェブサイトに導かれるモードは、ルールベースのパーシングが克服できない「構造的限界」を構成しています。図1-3は、このパラダイムの基本的な飛躍方向を比較進化の形で予告しています。
上図から明らかなように、これは同じ道を進む技術的な改善ではなく、2つの根本的に異なる道です。左側のルールベースのパーシングパラダイムは「文法レベル」に構築され、「正確な位置指定」を目的とし、構造変化に受動的に適応し、すぐに「構造的限界」に達します。これは、本のページ3行目5行目にあるパスを知っているが、そのパスの内容が何であるか分からない人のようなものです。右側の意味抽出パラダイムは作業レベルを根本的に変える:「文法」から「意味」へ、「機械的なマッチング」から「知的な理解」へと。その目的は、ノード座標の位置指定ではなく、ページコンテンツそのものを直接理解することです。その能力の境界は、DOMの変化によって決まりません。
これはまた、ルールベースのパーシング時代の3つのジレンマが独立した問題ではなく、すべて「文法マッチング」の下位ロジックの異なる現れであることを説明しています。データ抽出技術が文法レベルにとどまっている限り、ルールの設計がどれほど詳細であっても、「正確な位置指定」と「意味の盲点」が共存する構造的パラドックスを乗り越えることはできません。したがって、AIの意味抽出パラダイムの登場は、古い道を加速するのではなく、認知レベルでの革命であり、「位置を探す」から「内容を理解する」へと移行しています。このパラダイム転換の具体的なメカニズムと利点は、1.2節で詳しく説明します。
1.2 AIパラダイム:文法マッチングから意味理解へ
AI駆動の方法は問題のアプローチを完全に再定義します。図1-4は、ルールベースのパーシングとAIの意味パラダイムの4つの次元における根本的な違いを比較しています:核心問題、依存要因、変化への適応、拡張モード:
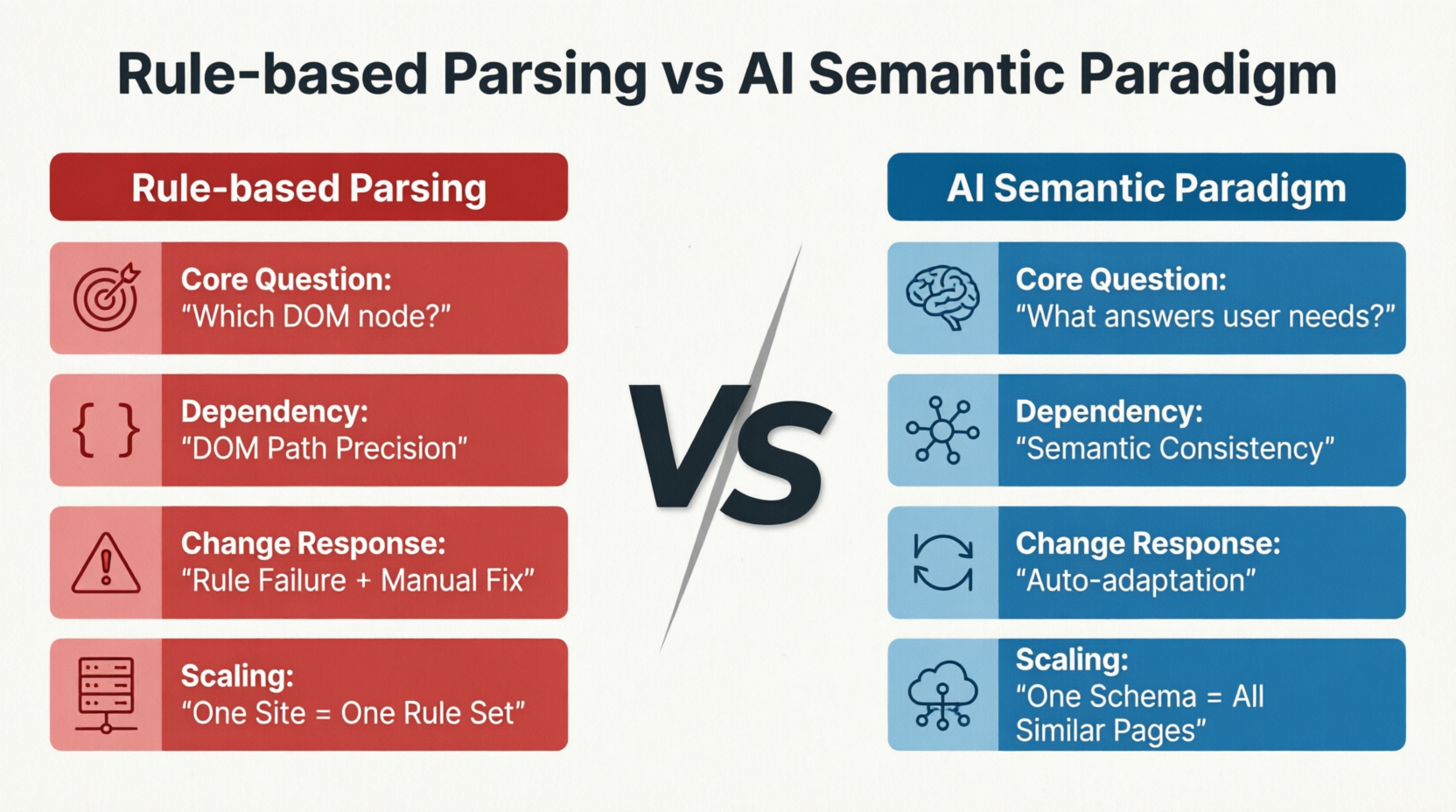
従来の方法は「DOMノードでデータはどこにありますか?」と尋ねるのに対し、AIの方法は「ページ上のユーザーにとっての関心のあるコア情報は何ですか?」と尋ねます。この質問の違いが、その後のすべての技術的ルートの分岐を決定します。前者はDOMパスの正確さに依存し、ページがリデザインされたりノードがシフトしたりするとルールが無効になり、手動で修正する必要があります。後者はページの意味の一貫性に依存します。DOM構造は変化しても、データの位置は移動しても、意味のコンテンツが変化しなければ、モデルは正しい識別と抽出が可能です。拡張モードにおいて、ルールベースのパーシングは毎回新しいサイトごとにルールを再記述する必要がありますが、AIの意味パラダイムは同じSchemaでサイト全体の類似ページを横断的にカバーできます。
この「正確な文法的位置指定」から「曖昧な意味理解」へのシフトにより、AIの方法は従来のルールにない堅牢性を備えています。学術界が提案したAXEフレームワークは、このパラダイム転換の最も明確なエンジニアリング例を提供しています。図1-5はそのコア処理フローを要約しています:
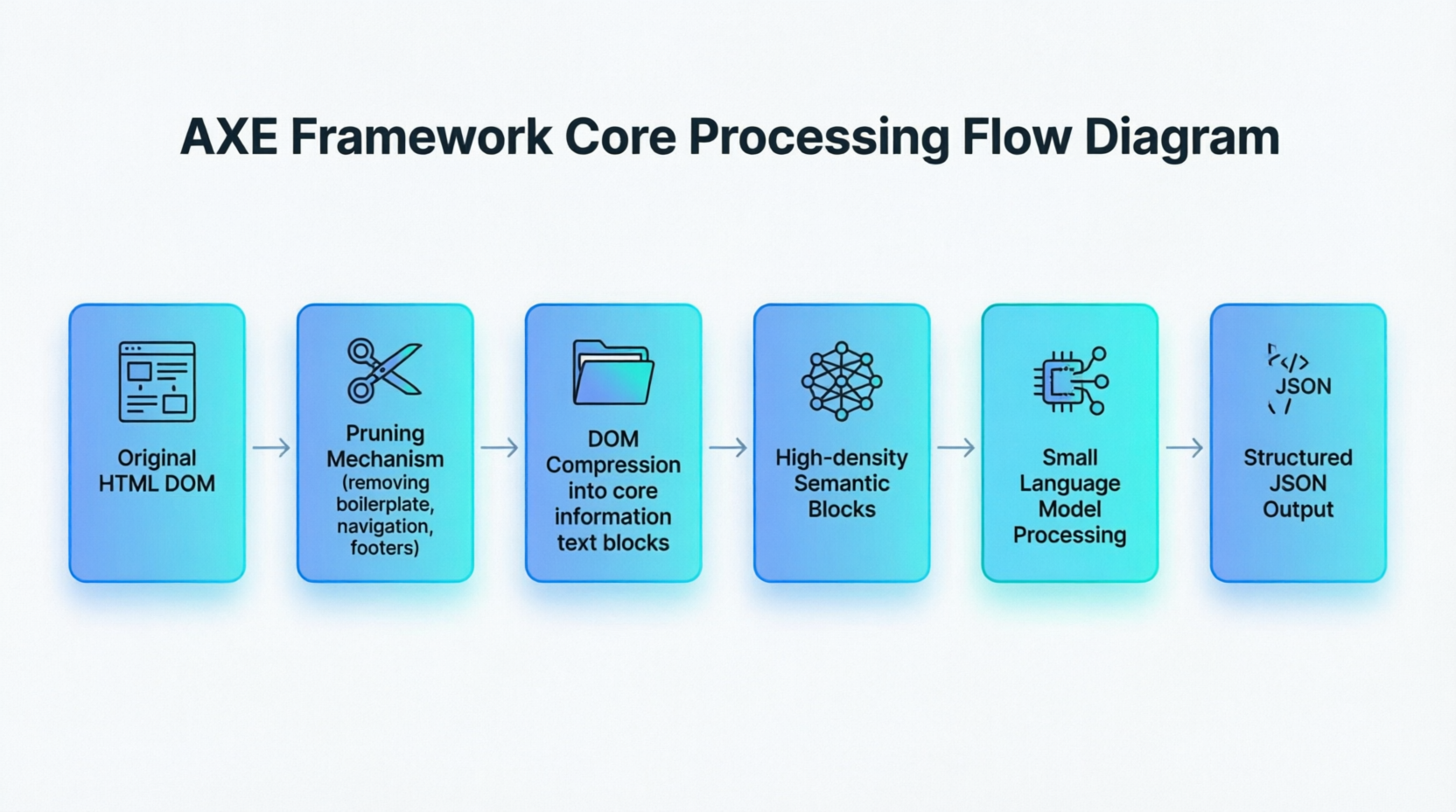
図1-5は、生のHTMLから構造化出力に至る完全なチェーンを示しています。AXEはまずHTML DOMを剪定が必要なツリーとして扱い、専用の剪定メカニズムを通じてナビゲーションバー、フッター、ボイラークレートコードなどの不要なノードを削除します。その後、DOMはコア情報を含む高密度の意味ブロックに圧縮され、最後に軽量な小さなモデルがこれらの意味ブロックを読み取り、構造化されたJSON出力を生成します。このプロセス全体は、従来の方法が常に依存するDOMパス位置指定を回避し、ページの意味コンテンツに直接作用します。
SWDEデータセット(8つの垂直ドメインと80以上の実際のウェブサイトをカバー)で、AXEは自身よりもはるかに大きな複数のモデルを上回るF1スコア88.1%を達成しました。この結果は、意味抽出能力が巨大モデルに依存しないという逆説的だが重要な事実を証明しています。適切に設計され、特化してトレーニングされたマイクロモデルでも、生産レベルの精度を達成できます。これは、AIの意味パラダイムがコストとエンジニアリングの実現可能性において競争力があるという核心的な証拠です。
もう一つの代表的な研究であるDripperは、異なる技術的ルートを取って、メインコンテンツ抽出を「意味ブロックのシーケンス分類」タスクとして再定義しています。図1-6は、AXEとDripperの方法の違いをカード比較で対比し、ルール時代とAI時代における運用保守モードの進化を示しています:
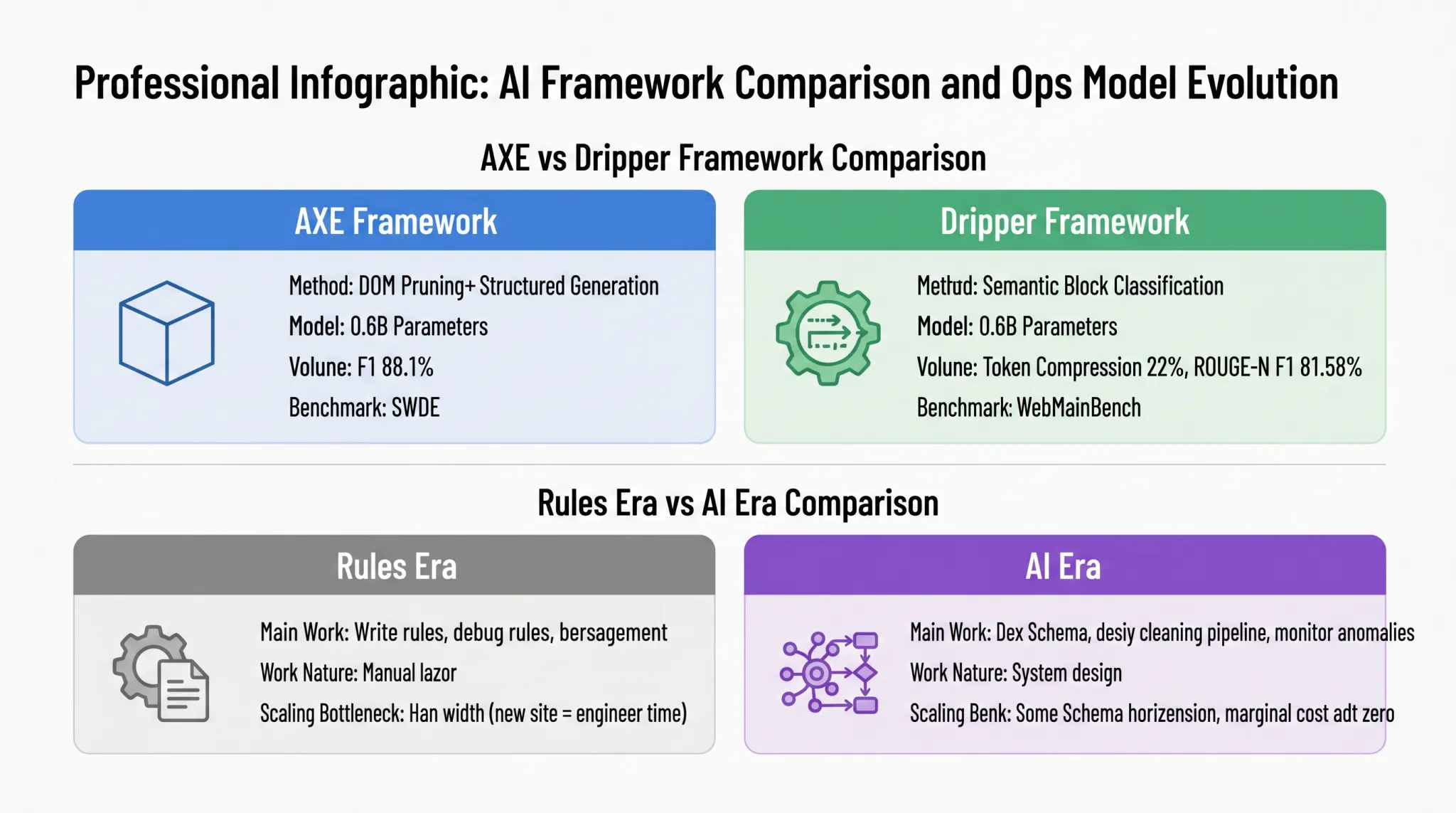
AXEは「DOM剪定+構造化生成」の経路を採用し、HTML DOMを高密度の意味ブロックに圧縮し、その後小さなモデルでJSON出力を直接生成します。Dripperは「意味ブロックのバイナリ分類」の経路を取って、メインコンテンツ抽出を各意味ブロックがメインテキストに属するかどうかを判断する分類タスクに変換します。両モデルとも0.6Bパラメータの規模で、それぞれのベンチマークで生産可能な精度を達成しています。AXEはSWDEデータセットでF1スコア88.1%を達成し、Dripperは入力トークンを元のHTMLの22%に圧縮し、WebMainBenchで81.58%のROUGE-N F1スコアを達成しました。これらの2つの異なる経路は、同じ結論に導きます:AIデータ抽出は精度で競争力があり、巨大モデルに依存していません。適切に設計されたマイクロモデルでも十分な能力を持っています。
右半分は、パラダイム転換のより深い意味を明らかにしています。それは技術的ルートだけでなく、データチームの日常的な運用モードも再構築しています。ルール時代の主な仕事はルールの記述、ルールの修正、バージョン管理であり、これは本質的に手作業です。拡張のボトルネックは人間の能力にあります:新しいターゲットサイトを追加するたびに、エンジニアの時間を使ってルールを再記述し、デバッグする必要があります。AI時代には、仕事の焦点がSchemasの定義、クリーニングパイプラインの設計、異常ケースのモニタリングにシフトします。性質は手作業からシステム設計に変わり、拡張モードも「1サイトごとの1セットのルール」から「同じSchemasでの横断的拡張」に変わります。類似サイトの追加にはほぼ追加のエンジニアリング投資が不要で、限界コストはゼロに近づきます。このシフトにより、データ抽出の能力は人間の能力の制限から解放され、データ収集の経済性が再定義されます。
II. AIデータ構造化抽出のコアプロセス
完全なAIデータ抽出パイプラインには7つのステージがあり、3つの機能グループに分けることができます。
- データ取得レイヤー(URLキュー → ウェブスクレイピング → 逆スクレイピング検出):複雑なネットワーク環境でターゲットページのHTMLを「取得」する責任があります。これは全体のパイプラインの中で最もリスクの高いゾーンであり、図2-2に示される14%のコアボトルネックはこのレイヤーに指向しています。
- コンテンツ処理レイヤー(コンテンツクリーニング → LLM解析 → スキーマ検証):ノイズの多い生のHTMLを高品質な構造化データに変換する責任があります。このレイヤーの精度ボトルネック(18%)は主にコンテンツクリーニングステージに集中しています。
- データストレージレイヤー(データストレージ):下流での利用のための最終出力であり、全体のリンクの負荷の約5%を占めています。
本章では、コンテンツ処理レイヤー(レイヤー2)の技術的詳細に焦点を当て、AIの意味抽出が従来のルールエンジンを根本的に上回ることを示します。レイヤー1は、データが処理レイヤーに流れ込むかどうかを決定する重要な前提条件であり、第3章で専門的な分解と実践的な解決策について議論します。
2.1 AIデータ抽出パイプライン
処理レイヤーに入る前に、図2-1を通じて全体のパイプラインを俯瞰し、URLキューイングからデータストレージに至る完全な経路と各ステージでの実際のトラフィック分布を理解します。これは本章の概要であり、第3章でのボトルネック対策の基礎を築きます。

URLキューはパイプラインのエントリーポイントであり、クロールするURLのリストを管理し、リクエストのリズムを制御します。図2-1に示すように、URLスケジューリングステージで約32%のリクエストはすでにCAPTCHAリスクとして事前にマークされており、残りの68%は正常なリクエストを直接発行できます。ウェブスクレイピングステージはHTTPリクエストの発行やブラウザレンダリングの駆動を通じて、ページの生コンテンツを取得する責任があります。この段階で、12%のリクエストが直接CAPTCHAによってブロックされ、80%は下流ステージにスムーズに進むことができます。
初期スクレイピング後、リクエストは逆スクレイピング検出ステージに入ります。現代の逆スクレイピングシステムは、IP信頼性、TLSファイントプリント、ブラウザの特徴、行動パターンの4つの次元の信号を同時に分析し、マルチレイヤーのクロスバリデーションを行います。図2-1では、逆スクレイピング検出ステージで約10%のトラフィックが自動リクエストとして識別され、ブロックされ、20%はIPプロキシプールやTLSファイントプリントのスプーフィングに依存して検出を回避する必要があります。これは全体のパイプラインの中で最も不確実なノードです。一度CAPTCHAが発動され、対処されなかった場合、その後のすべてのステージの計算リソースは無駄になります。
逆スクレイピング検出を通過した後、生のHTMLコンテンツが得られます。一般的なニュースページの生HTMLは2MBを超えることがあり、OpenAIのtiktokenトークナイザで処理すると300,000〜500,000トークンに達します。ナビゲーションメニュー、埋め込みCSS、Base64エンコードされたトラッキングピクセル、圧縮されたJavaScriptが含まれています。したがって、コンテンツクリーニングは必須のステップです。図2-1では、HTMLからMarkdownへの変換がこのステージの50%を占め、DOMの簡略化とノイズ除去が30%を占めています。これらの2つを組み合わせることで、生HTMLが高密度な意味テキストに圧縮され、LLMの計算能力が情報に集中するように保証されます。
クリーン化されたテキストはLLM解析ステージに入り、定義されたスキーマに従って構造化されたフィールドを抽出します。図2-1ではこのステージを後のスキーマ検証と組み合わせ、94.7%の正確性を示しています。これは約20件の抽出のうち1件がフィールドの完全性やフォーマットの一貫性チェックに失敗することを意味します。成功した出力は構造化されたJSONデータとなり、下流ビジネスの利用に適したPostgreSQLやMongoDBなどのシステムに最終的に保存されます。
各ステージの技術的キャリア、パフォーマンス指標、エンジニアリングのボトルネックをより明確に分解するため、図2-2はダッシュボード形式で全体像を提示しています:
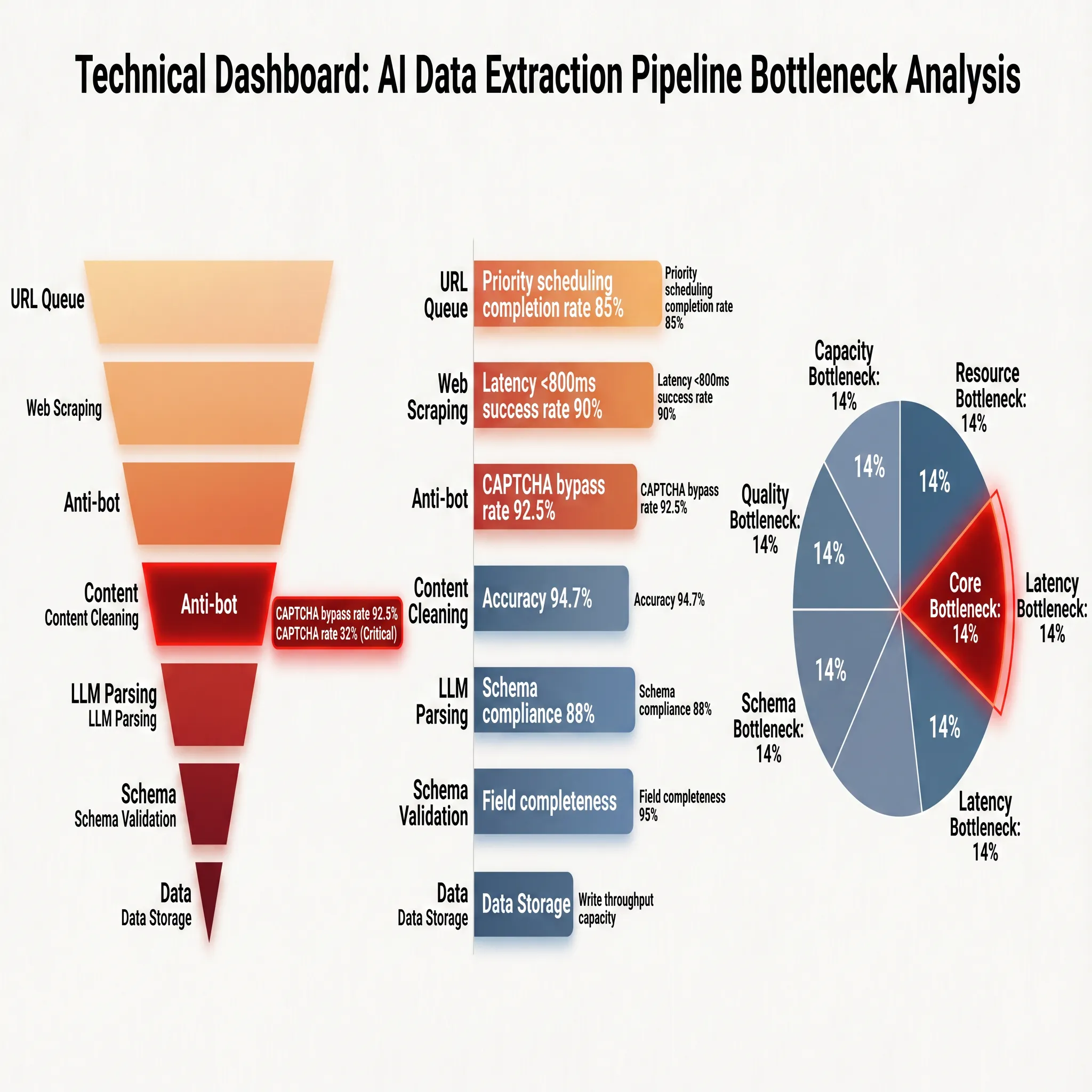
図の右側のパフォーマンス指標は各ステージの実際の運用基準を明らかにしています:URLキューの優先スケジューリング達成率は85%であり、約15%のタスクがスケジューリング競合により遅延または劣化しています;ウェブスクレイピングは800ms以下の遅延制限下で90%の成功率を達成しており、ネットワークおよびレンダリングリソースの境界を明確に示しています;逆スクレイピングメカニズムは94.7%の正確性を持ち、約100件のリクエストのうち5件がブロックされたり、検証をトリガーしたりします。コンテンツクリーニング後、スキーマ準拠率は88%、フィールド完全性は95%です。これらの2つの指標はデータ品質の出発点を定義し、約12%のページで主要コンテンツの識別にずれが生じ、5%の必須フィールドが欠落しています。
図2-2の下部はボトルネックの分布を直接示しています:コアボトルネックは逆スクレイピングメカニズム(14%)に指向し、精度ボトルネックはコンテンツクリーニング(18%)に指向し、容量ボトルネックはURLスケジューリングとウェブスクレイピングステージにそれぞれ指向し、コストボトルネックはスキーマ検証の品質検査のオーバーヘッドにあります。これらのデータは上記の分析と非常に一致しています。逆スクレイピング検出は全体のチェーンの「喉」であり、逆スクレイピング戦略が発動し、効果的に回避できない場合、後続のステージの正確性がどれほど高かろうと、入力データの欠如によりすべてが失敗します。これは従来のルールベースクローラーのコア問題と一致しています:AIの意味抽出の時代において、正確性の上限は大幅に引き上げられましたが、「データ取得のエントリーレベル」はエンジニアリング実装の最初の障壁のままです。このため、第3章では逆スクレイピング対抗技術の進化と対策について詳しく議論します。
2.2 コンテンツクリーニング:ノイズが多いHTMLからLLMが読めるテキストへ
生のHTMLをLLMに直接構造化抽出に投入することは、エンジニアリングにおいて極めて非効率的です。LLMの注目メカニズムは、深くネストされた<div>タグ、埋め込みCSSスタイル、トラッキングスクリプト、ナビゲーションメニュー、フッターリンクなどのDOMのテンプレートコードによって混乱しやすくなります。これらの要素は意味的な価値を提供せず、トークンの消費を劇的に増加させます。数千ページを1日で処理する大規模なシナリオでは、この無駄はすぐに財務的に持続不可能になります。一般的なニュースページのHTMLの構成は問題の深刻さを直感的に示しています。図2-3は、生HTML内の有効情報とさまざまなノイズの割合を円グラフで提示しています:
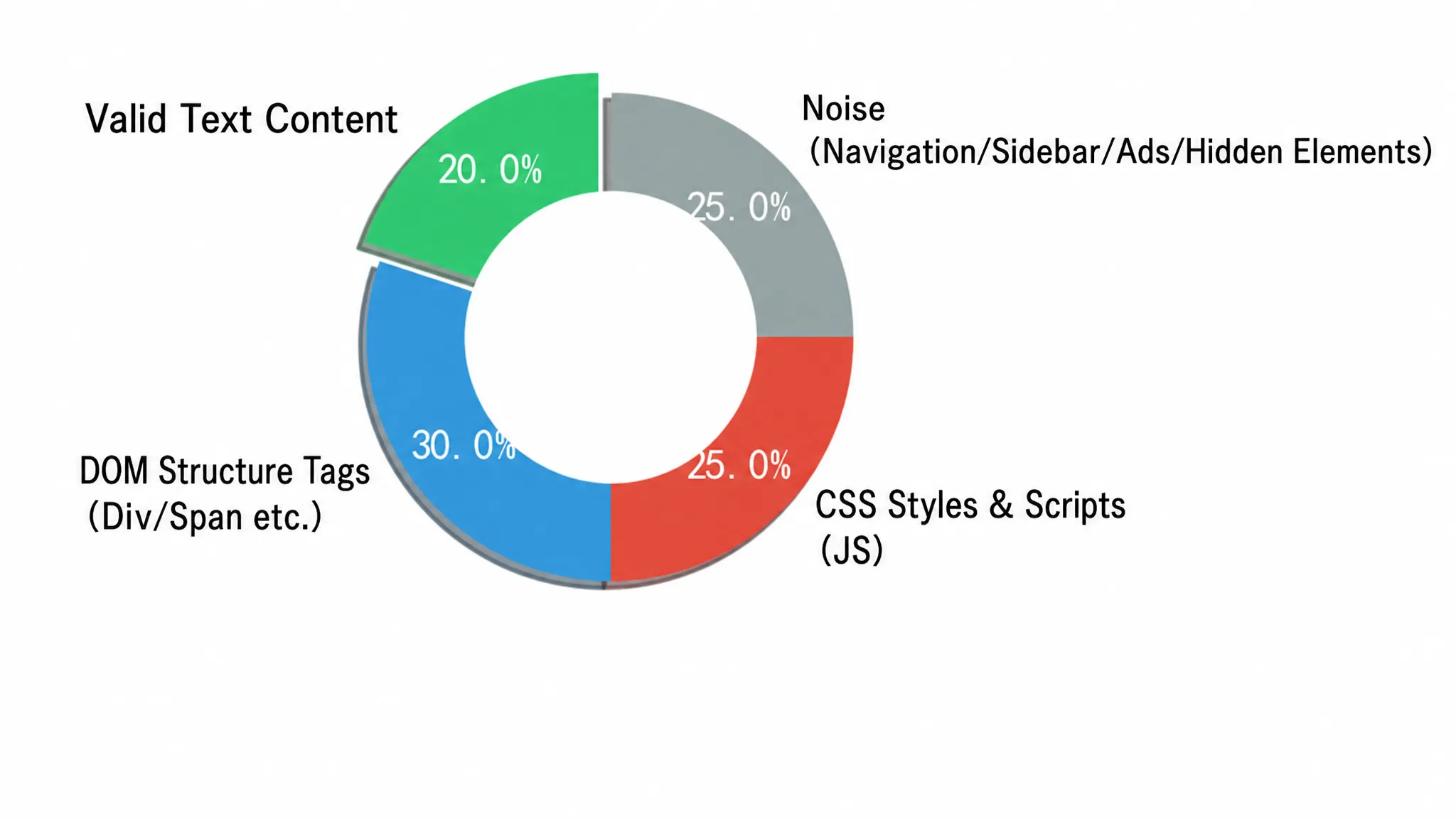
円グラフは生HTMLを4つの領域に分割しています。緑色の部分(45%)は有効な本文コンテンツであり、テキストや画像を含み、LLMが本当に必要とする信号です。黄色の部分(20%)は構造的およびスタイルノイズであり、<script>、<style>、<svg>タグです。青色の部分(20%)はナビゲーションとサイドバーであり、赤色の部分(15%)は広告とトラッカーです。これらの3つのノイズ部分は55%以上を占めており、LLMに送られるトークンの半分以上が意味的な価値を提供しないまま課金されています。
この「信号がノイズに埋もれている」現実が、3段階の段階的なクリーニング戦略を生み出しました。図2-4は、生HTMLからLLMが読めるテキストへの完全な処理チェーンを示しています:
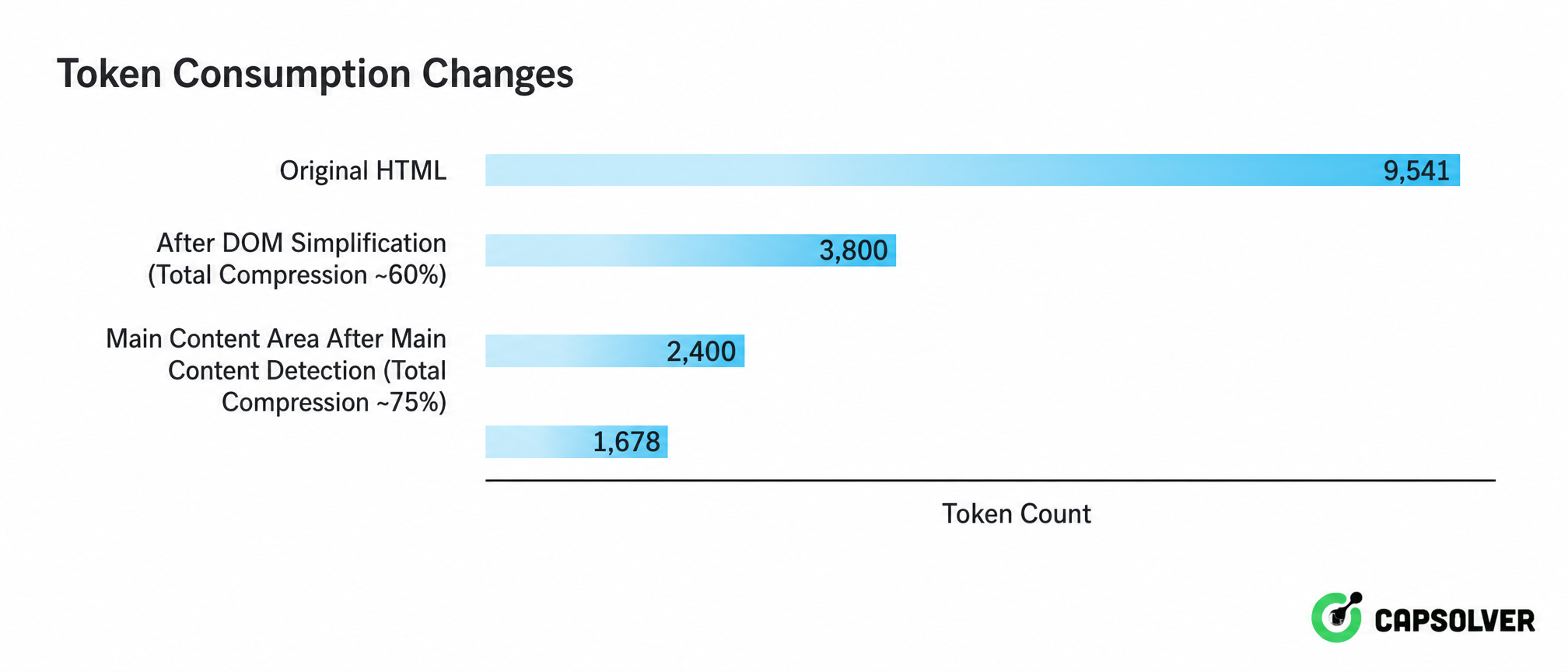
全体の視点から見ると、3段階のクリーニングがトークンを9,541から1,678に圧縮し、元のHTMLの18%にまで減少させていることが一目でわかります。この圧縮率は、大規模な処理においてAPIコールコストを元の5分の1以下に減らし、意味的文脈フィルタリングによって達成された10〜100倍の文脈削減により、LLMの注目がノイズではなく信号に集中するように保証します。これはAIデータ抽出のエンジニアリング実装において不可欠な部分です。
2.3 LLM解析とスキーマ検証:テキストから構造化データへ
コンテンツクリーニングでクリーン化されたMarkdownテキストはLLM解析ステージに入り、定義されたスキーマに厳密に従う構造化JSONを生成することを目的とします。シナリオに応じて、現在3つの主流技術経路があります。経路1はGPT-4oなどの一般的な大規模モデルを使用し、128Kのコンテキスト窓サイズにより、最も高速な推論速度と最高の品質スコアを提供しますが、コストは中程度であり、フィールド数が少なくシンプルなフォーマットでの迅速なプロトタイプ検証に適しています。経路2はSchematron-3Bなどのスキーマ優先の専門モデルを使用し、コンパクトなサーバーサイドデプロイメントで動作し、中程度〜高速な速度で、一般的な大規模モデルより品質スコアがわずかに0.12ポイント低い一方で、コストを最低限に抑えることができ、大規模な本番環境において最適な選択肢です。経路3はマルチモーダル言語モデルを活用してハイブリッドアーキテクチャを構築し、スクリーンショットとHTMLを同時に解析し、無限スクロールやモーダルポップアップなどの非常に動的なインタラクティブページを処理できますが、速度は中程度、コストは最高、品質スコアは相対的に最低であり、複雑なインタラクティブシナリオでほぼ唯一の実行可能な経路です。どの経路を選んでも、初期に生成された構造化JSONは最終データとして出力される前に、フィールド完全性、型準拠、フォーマットの一貫性の3段階のスキーマ検証を通過する必要があります。図2-5は、これらの3つの経路とスキーマ検証の関係をプロセスチェーンとコアメトリクスの観点から完全に示しています。

マトリクスは、逆説的だが重要なエンジニアリングの事実を明確に示しています:最も大きなモデルが常に最適な解決策ではありません。Schematron-3Bは3Bパラメータのみで、GPT-4oなどの大規模モデルの品質スコアに近づきながら、コストを大幅に削減します。1日100万ページを処理する規模になると、その推論コストは大規模な汎用モデルの約1/80にまでなり、これは「技術的に可能」から「商業的に利益を生む」への重要な転換点です。Webscraper+MLLMはコストが最も高く、品質スコアも相対的に低いですが、非常に動的なインタラクティブシナリオにおいてほぼ唯一の実行可能な経路であり、これは技術選択の正しさが絶対的なメトリクス値ではなく、シナリオの制約に依存することを正確に確認しています。
スキーマ検証はデータの利用可能性を確保する最後のチェックポイントです。その中でも、日付、通貨、電話番号などのフィールドのフォーマットの一貫性チェックは特に重要です。従来の正規表現ソリューションは、各入力変種ごとに手動でルールを記述する必要がありますが、LLMの内部のフォーマット変換能力はゼロルールで標準化を実現できます。精度に関しては、AXEフレームワークはSWDEデータセットでF1スコア88.1%を達成しました。実際の生産環境での経験から、数十倍のコストをかけて100%の理論的精度を追求するよりも、90%の自動抽出精度を追求し、迅速な手動レビュー経路を備えることが、より現実的なエンジニアリング戦略です。このトレードオフの位置は、各チームの「データの連続性」と「予算の上限」の具体的な計算に依存していますが、中程度の精度が商業的に実現可能であることは明らかです。
III. AIデータ抽出の3つのゲートウェイ:逆スクレイピング、CAPTCHA突破、コスト管理
第2章では、コンテンツ処理レイヤーの技術チェーン—from HTMLクリーニングからスキーマ検証—を詳しく探求し、AIの意味抽出が精度の上限を大幅に引き上げることを示しました。しかし、第2.1節の図2-2に示されるように、全体のパイプラインのコアボトルネック(14%)は処理レイヤーではなく、前のデータ取得レイヤーにあります。HTMLが取得できない場合、その後のすべての知能解析は空虚な上に築かれることになります。本章では、この「エントリーレベル」を決定する重要なステージに直接取り組みます。
3.1 データ取得レイヤー:パイプラインの最初の致命的なボトルネック
コンテンツクリーニングとLLM解析が「データをどのように処理するか」の問題を解決するなら、データ取得レイヤーは「データが取得できるか」のより根本的で困難な問題を扱います。URLキューから通常アクセスに至る経路において、逆スクレイピングシステムは全体のパイプラインの中で最も制御不能な変数です。
現代の逆スクレイピングシステムは、ネットワーク、トランスポート、ブラウザ、行動の4つのレイヤーからリクエストを同時に分析する4段階の防御インデプスアーキテクチャに進化しています。図3-1はこの階層的な検出アーキテクチャを水平方向に拡張しています。
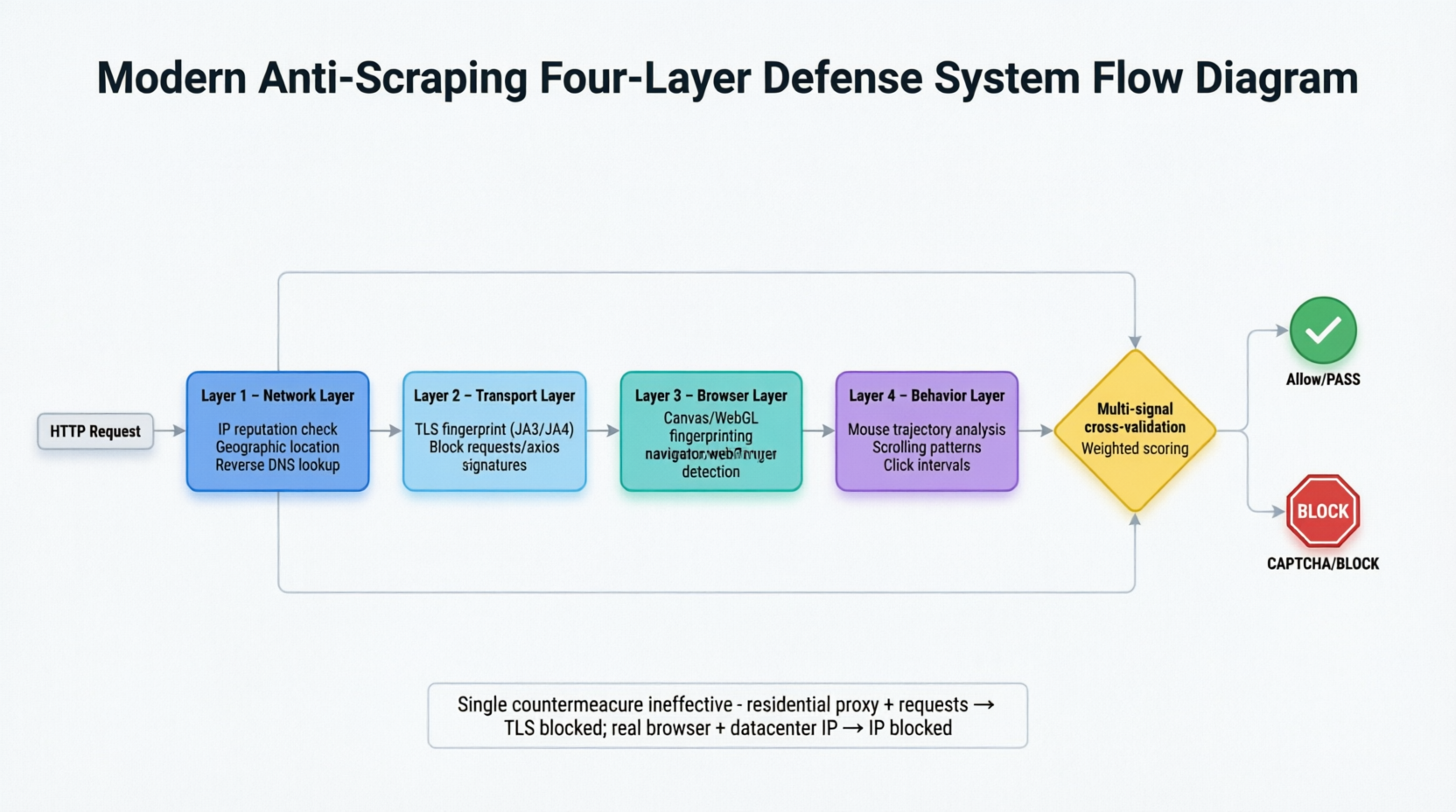
リクエストは4つのフィルタリングレイヤーを順次通過します。ネットワークレイヤーではIPの位置、データセンターに属しているか、逆DNSが欠如しているかなどの静的信号がチェックされます。トランスポートレイヤーではTLSファイントプリントが比較されます。ブラウザレイヤーでは、ヘッドレスモードでのnavigator.webdriverプロパティ、Canvasファイントプリント、WebGLレンダラー情報などの自動化の痕跡がキャプチャされます。行動レイヤーでは、マウスの軌跡、スクロールパターン、クリックインターバルなど、人間の行動特性が難しいと正確にシミュレートされません。4つのレイヤーの信号は相互に検証され、重み付きスコアを形成するため、単一レイヤーの偽装では通過することが困難です。システムが明確な判断ができない場合、最終的な防御手段としてCAPTCHAが発動します。
すべての受動的な検出方法がトラフィックの性質を明確に判断できない場合、システムはCAPTCHAを表示し、これは逆スクレイピングシステムの最終的な防御手段です。現代のCAPTCHAは単なる歪んだ文字認識ではなく、リスクスコアに基づく知的チャレンジシステムです。表3-1は現在利用可能な4つの主要なCAPTCHAシステムを比較しています。
| CAPTCHAシステム | インタラクションフォーム | 判断メカニズム | AIデコード能力/特徴 | クローラーへの脅威 |
|---|---|---|---|---|
| reCAPTCHA v2 | チェックボックスをクリック / イメージ認識 | ユーザーのインタラクション + AIの行動スコアリング | 精度 85%–100% | 高いが破壊可能 |
| reCAPTCHA v3 | 完全に非表示、目に見えるチャレンジなし | バックグラウンド継続的行動スコアリング | 直接的に「破壊」できない、行動シミュレーションに依存 | 非常に高い、非表示スコアリング |
| Cloudflare Turnstile | ブラウザ環境の一貫性チェック | 非対話型検証 | ブラウザの整合性を確認 | 高い、reCAPTCHAの代替 |
| AWS WAF CAPTCHA | リスクベース、設定可能なチャレンジ | AWS統合環境判断 | クラウド環境特有 | 中程度、特定のエコシステム |
CAPTCHAは全体の防御チェーンの最終段階に位置します。トリガーされ、処理されない場合、その後のすべてのコンテンツクリーニングやLLM解析のステージは完全に効果がなくなります。これは、データ取得層が「パイプラインの最初の致命的なボトルネック」と呼ばれる根本的な理由です。反クローリングメカニズムはデータがシステムに流入できるかどうかを決定し、それはターゲットサイトによって深く制御される変数です。AIの意味抽出がデータ処理の効率を大幅に向上させた時代において、取得側での攻防はエンジニアリングの成功の鍵 remains です。
3.2 パズルの完成:現代CAPTCHA突破の技術的アプローチ
4層の反クローリング防御インサイトシステムにおいて、CAPTCHAは自動的に解決するのが最も困難な障壁です。CapSolverを代表とするCAPTCHA認識ソリューションはパイプライン全体で「フューズのような」役割を果たします。これは「反クローリング検出」と「通常アクセス」の間に埋め込まれています。クローラーがreCAPTCHA v2/v3、Cloudflare Turnstile、AWS WAF CAPTCHAなどのチャレンジに遭遇した場合、数秒で認識を行い有効なトークンを返します。図3-2はCapSolverを例として、このタイプのソリューションの介入位置と処理ロジックを示しています:
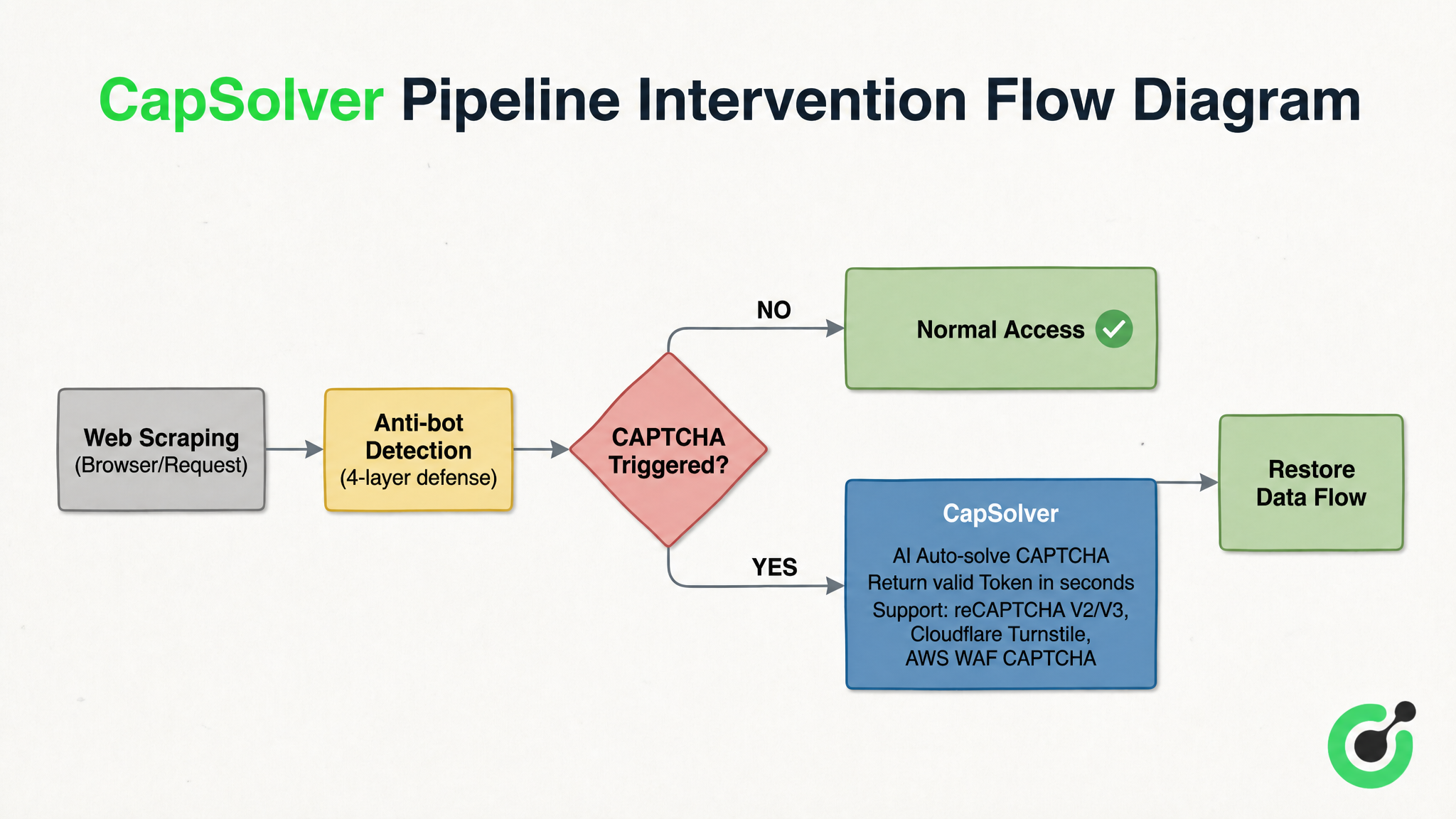
図3-2から、このタイプのソリューションの動作メカニズムが明確です。スクリーピング要求が4層の防御システムによって検出され、CAPTCHAがトリガーされない場合、直接通常アクセスに解放されます。CAPTCHAチャレンジがトリガーされると、認識サービスが即座に介入し、CAPTCHAのタイプとパラメータを送信します。AIが数秒で認識を行い、有効なトークンを返し、データフローがブレイクポイントで再接続されます。これは既存のコンポーネントを置き換えるものではなく、電気システムのフューズのように動作し、異常が発生した瞬間に全体のシステムがクラッシュすることを防ぎます。
CapSolverはこの分野の代表的なソリューションの一つです。2CaptchaやAnti-Captchaなどの類似サービスも同様の機能を提供しており、開発者は遅延要件、サポートされるタイプ、料金モデルに基づいて最も適切なベンダーを選択できます。この埋め込みにより、データ取得層の信頼性モデルが直接変化します。図3-3はCapSolverをケーススタディとして、CAPTCHA認識導入前後のキーポイントの変化を定量化しています:
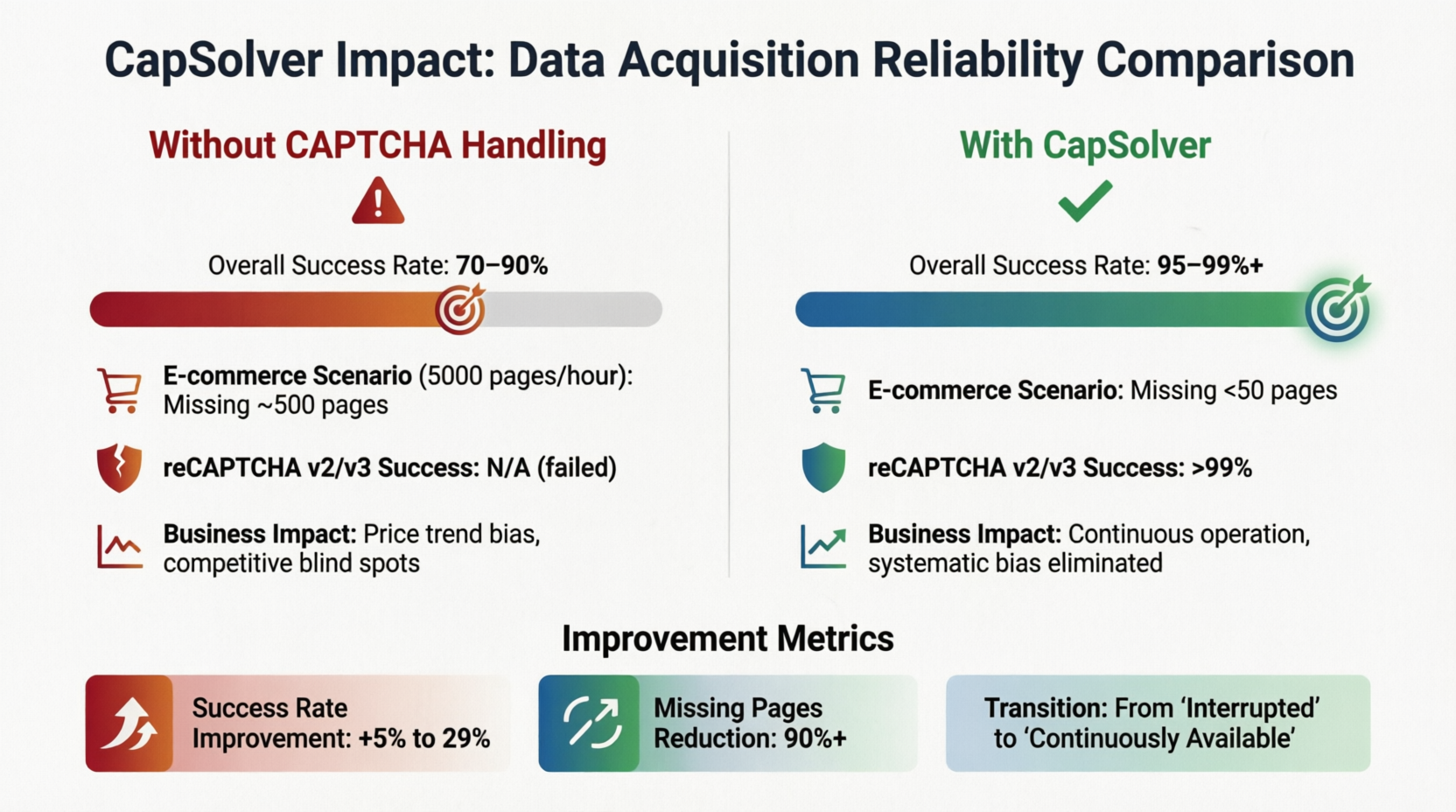
CAPTCHA処理メカニズムがなければ、全体の成功率は70%–90%の間で変動します。ターゲットサイトがCAPTCHAを導入している限り、データフローがブロックされる確率は10%–30%あります。1時間あたり5,000ページの商品ページをスクリーピングする小売価格モニタリングシステムでは、基本的な成功率が90%でも、1時間あたり約500ページのデータが失われるため、価格トレンド分析の方向性のずれや競合戦略のシステム的な盲点を引き起こす可能性があります。しかし、CAPTCHA認識ソリューションを導入すると、成功率は95%–99%にジャンプし、失われるページ数は50以内に減少します。パラメータが正しく設定されている場合、reCAPTCHA v2/v3の認識成功確率は99%を超えます。カードの下部には改善点が要約されています:成功率は5%–29%上昇し、失われるページ数は90%以上減少しました。「継続性はビジネス価値」は大規模なシナリオではスローガンではなく、これらの数字によって確認されたエンジニアリング実践です。
AIベンチマークテストプラットフォームやLLMトレーニングデータ収集シナリオでも同様の課題に直面しています。研究者は継続的に多様なデータを取得する必要があり、このデータをホストするウェブサイトは自動アクセスを防止するためにreCAPTCHAを使用するため、「AI研究チームが研究している技術によって妨げられる」逆説が生じます。CAPTCHA認識サービスはこれらの課題を処理するプログラマティックな方法を提供し、データ収集の継続と完全なベンチマークテスト結果を確保します。
統合レベルでは、このようなソリューションはブラウザオートメーションフレームワーク、プロキシネットワークサービス、低コードオートメーションプラットフォームと協働できます。開発者はCAPTCHAのタイプとパラメータをAPIに提出するだけで、数秒でトークンが返されます。n8nなどのプラットフォームは専用ノードを提供し、ビジネス担当者がコードを書かずにワークフロー内でCAPTCHA認識を直接構成できるようにします。開発者はビジネスロジックとSchema設計に焦点を当て、反クローリング対決は専門ツールに任せることができます。
アーキテクチャの観点から見ると、CAPTCHA認識ソリューションは既存のコンポーネントを置き換えるものではなく、パイプライン全体のエントリーポイントの「可用性保証」の層を提供します。CAPTCHA認識が数秒で自動的に完了できる場合、データ取得は「断続的なブラックアウト」から「継続的なデータ供給」に切り替わり、全体のAIデータ構造抽出チェーンの安定運用の前提条件になります。
3.3 正確性とコスト:エンジニアリング実装の最終的なトレードオフ
AIデータ構造抽出を本番環境に押し進める際、最終的な決定変数は「正確性が十分か?」ではなく「コストを支払えるか?」です。トークン消費はこの問題の中心です。中程度の複雑さを持つ製品ページは、クリーニング後でも8,000~15,000トークンを消費します。現在の主流モデルAPIの料金に基づくと、1回の抽出のコストは$0.001~$0.01です。これはプロトタイプ段階ではほぼ無視できるものですが、抽出規模が1日数百万ページに拡大すると、月間コストは数万ドルに達し、その時点でコスト制御は最適化の項目ではなく、入門要件になります。現在、業界ではコストを削減するための3つの並列的なアプローチがあります。図3-4はそれらの位置付けと全体の解析チェーンにおける協働関係を示しています:
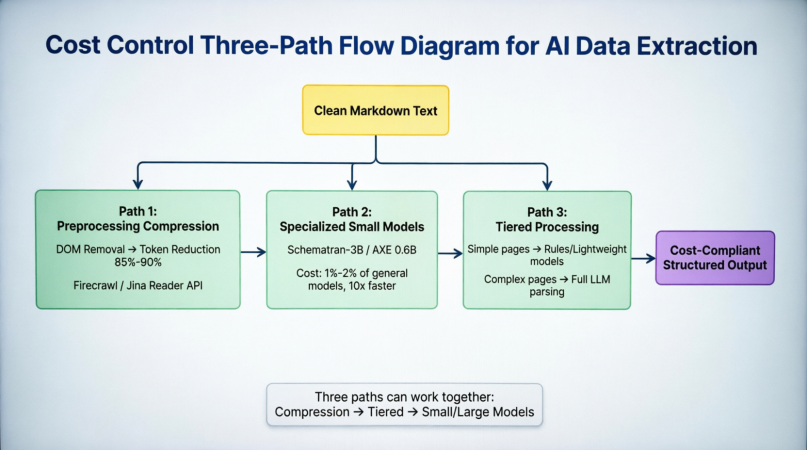
クリーンされたMarkdownが解析ステージに入る前に、パス1はフロントエンドでDOM削除と主要コンテンツ検出を通じてトークンを85%~90%削減します。FirecrawlやJina ReaderはこれをAPIにカプセル化し、開発者が独自のクリーニングパイプラインを構築する必要がなくなります。パス2はモデル層で一般的な大規模モデルをSchematron-3BやAXE 0.6Bなどのタスク固有モデルに置き換えることで、精度を維持しながら推論コストを1%~2%に圧縮し、10倍以上高速化します。パス3はスケジューリング層で構造が単純なページに対してルールや軽量モデルを使用し、複雑なページのみを完全な大規模モデルに渡して解析します。これは、同じサイト内のページが非常に一貫した構造を持つ小売カテゴリモニタリングなどのシナリオで特に効果的で、わずかな異常ページのみが完全なモデルの介入を必要とします。3つのパスは互いに排他的ではなく、協働して重ね合わせることができます。まずトークンを圧縮し、次に複雑さで分類し、最後にタスクに合ったモデルで処理します。図3-5は、3つの戦略のコア原則、トークン削減、代表的なソリューション、コスト削減の規模をさらに定量化し、3つのデータ品質チェックを含んでいます:

前処理圧縮はDOMノイズを削除することで入力量を直接削減し、トークン削減率は85%~90%に達し、コスト削減率は80%~90%になります。専門的な小規模モデルはモデルサイズを縮小することで単一推論のコストを削減し、パラメータ数は数十億から0.6B~3Bの範囲に減少し、推論コストの約98%を削減します。段階的処理は計算リソースの差別的配分を通じて全体の効率を最適化し、コスト削減は単純なページの割合に依存します。これらの3つのアプローチは「送る量を減らす」「計算量を減らす」「賢く計算する」を通じて、入力層、モデル層、スケジューリング層をカバーする完全なコスト削減システムを形成します。
後半は品質保証に移ります。データ品質検査はコスト制御においてしばしば見過ごされがちですが、同じく重要です。下流ビジネスに流入する低品質データの修正コストは、抽出段階でのチェックを行う投資をはるかに上回ります。本番環境では少なくとも3つの自動チェックを導入する必要があります。フィールドの満たし率チェックは、スキーマの必要なフィールドが空でないことを保証し、異常記録を手動レビューのためにマークし、直接破棄するのではなく、異常記録を除外するのではなく、完全性を維持しながらデータの盲点を避けるようにします。数値範囲チェックは価格が負でない、在庫が合理的な範囲内であるなどのビジネスルールを検証し、しきい値を超える入力を拒否します。フォーマットの一貫性チェックは日付、通貨、電話番号などのフィールドを標準化し、正規表現とLLMの内部フォーマット変換機能が補完し合い、変換可能なものは自動的に処理し、変換できないものは手動介入のためにマークします。3つのチェックはコストと品質の動的なバランスを維持し、異常記録を破棄するのではなく、それらを除外することで完全性を保ちながらデータの盲点を回避します。
このバランスの取れた戦略はより大きなスケールでも適用可能です。実際のエンジニアリング実践では、90%の自動抽出精度を追求し、公式な手動レビューのプロセスを組み合わせることが、理論的な100%の精度を追求するよりも商業的に実現可能です。ターゲットデータの保存先の選択は下流の使用方法に依存します。リアルタイムAPIクエリやフロントエンド表示に使用される場合、PostgreSQLやMongoDBが適切です。フルテキスト検索やログ分析に使用される場合、Elasticsearchがより良い選択肢です。LLMトレーニングコーパスとして使用される場合、構造化されたJSONはトレーニングフレームワークに必要な形式に再シリアル化され、オブジェクトストレージに保存する必要があります。目標は「ワンサイズがすべてに適する」保存ソリューションを追求することではなく、データの消費方法とクエリパターンに基づいて最も適切なエンジンにマッチさせることです。この原則は、トークンコストから保存先の選択に至るまで、すべてのエンジニアリング決定に貫くものです。
CapSolverのボーナスコードを取得する
即座に自動化予算を増やす!
CapSolverアカウントにチャージする際にボーナスコード CAP26 を使用すると、毎回チャージに対して 5%のボーナス を受け取れます — 何の制限もありません。
今すぐCapSolverダッシュボードで取得してください
結論
生のHTMLから構造化されたJSONに至るまで、AIデータ抽出の完全なチェーンは5つの連続したステージに要約されます:取得、クリーニング、解析、検証、保存。各ステージは特定の問題を解決し、各ステージの効果は前のステージの成功に依存します。
このチェーンにおいて、データ取得層は「エントリーポイント」の役割を果たし、全体のパイプラインが正常に動作するか、完全に停止するかを決定します。現代の反クローリングシステムの4層の防御インサイトと継続的なアップグレードされたCAPTCHAメカニズムにより、データ取得はチェーン全体で最も制御不能でリスクの高いステージになります。コンテンツクリーニングがHTMLを80%以上圧縮でき、専門的な小規模モデルが数秒で正確な構造化抽出を行うことができ、スキーマ検証が出力フォーマットの適合性を保証する場合、「データが安定して取得できるかどうか」がプロジェクトの成功を決定する主要な問題になります。
これはまさにCapSolverのインフラレベルの価値がAIデータ抽出技術スタックにおいて存在する理由です。これはクリーニング、解析、検証のいずれのステージも置き換えるものではなく、パイプライン全体のエントリーポイントに継続的な可用性保証の層を提供します。CAPTCHA認識が数秒で自動的に完了し、99%以上の成功率を維持できる場合、データ取得は断続的な中断から継続的な出力に切り替わり、その後のすべてのステージの計算リソースとエンジニアリング投資が意味のあるリターンを生み出します。安定したデータ供給に依存するビジネスにとって、パイプラインの継続性自体がビジネス価値であり、この継続性を確保することは、実験から大規模な展開に至るまでAIデータ抽出が克服しなければならない最後のハードルです。
もっと見る
AIJun 26, 2026
CAPTCHA: AIエージェントインフラの欠けている要素
なぜトラフィック検証がAIエージェントインフラストラクチャの欠かせない要素であるかを発見してください。自律型エージェント向けの堅牢なソリューションを統合する方法を学びましょう。
AIJun 26, 2026
CAPTCHA耐性をAIエージェントに組み込む
- AIエージェントは、自動化されたタスク中に継続的な運用を維持するために強力なCAPTCHAの耐性が必要です。 - 構造化されたトラフィック検証戦略を実装することで、リスク管理メカニズムによる混乱を最小限に抑えることができます。 - 信頼性の高いCAPTCHA解決APIを活用することで、複雑な課題の効率的な処理が保証されます。 - 適切なインフラ設計により、コアエージェントロジックとボット保護管理を分離することができます。