







Cara Mengambil Data dari Amazon: Panduan 2026 untuk Ekstraksi Data Etis & Penyelesaian CAPTCHA

Emma Foster
Machine Learning Engineer
10-Apr-2026

TL;Dr:
- Penyedotan data Amazon pada tahun 2026 memerlukan teknik canggih untuk mengatasi langkah anti-bot yang canggih.
- Praktik penyedotan data yang etis, termasuk menghormati
robots.txtdan mengelola laju permintaan, sangat penting. - Proxy dan penggantian user-agent adalah kunci untuk menjaga anonimitas dan menghindari blokir IP.
- Tantangan CAPTCHA, terutama AWS WAF, umum dan dapat diselesaikan secara efektif menggunakan layanan khusus seperti CapSolver.
- Pendekatan langkah demi langkah yang mencakup persiapan lingkungan, integrasi API, penanganan permintaan, dan pemrosesan data memastikan ekstraksi data yang sukses.
- Optimasi kinerja melalui konkurensi dan penyedotan terdistribusi dapat meningkatkan efisiensi secara signifikan.
Pendahuluan
Dalam lingkungan e-commerce yang dinamis, ekstraksi data dari Amazon tetap menjadi tugas penting bagi bisnis dan peneliti. Baik untuk analisis kompetitif, pemantauan harga, penelitian produk, atau identifikasi tren pasar, penyedotan data Amazon memberikan wawasan berharga. Namun, seiring berkembangnya teknologi penyedotan data, mekanisme anti-bot yang digunakan oleh platform utama seperti Amazon juga berkembang. Panduan ini tahun 2026 menawarkan kerangka kerja komprehensif dan praktis untuk menyedot Amazon secara etis dan efisien, dengan fokus pada langkah-langkah praktis, contoh kode, dan solusi untuk tantangan umum, termasuk CAPTCHA AWS yang umum. Untuk perspektif tambahan tentang bypass WAF, pertimbangkan panduan ini panduan penyedotan Amazon dengan bypass WAF. Kami akan membahas alat, teknik, dan praktik terbaik yang diperlukan untuk memastikan upaya ekstraksi data Anda sukses dan berkelanjutan.
Memahami Mekanisme Anti-Penyedotan Amazon
Amazon, seperti banyak platform online besar lainnya, menggunakan kumpulan teknologi anti-penyedotan yang canggih untuk melindungi data dan memastikan penggunaan yang adil. Mekanisme ini dirancang untuk mendeteksi dan mencegah akses otomatis, mulai dari blokir IP dasar hingga tantangan CAPTCHA yang canggih. Memahami pertahanan ini adalah langkah pertama untuk membangun solusi [teknik penyedotan anti-deteksi](https://www.capsolver.com/blog/web scraping/web-scraping-anti-detection-techniques) yang kuat dan tangguh.
Teknik Anti-Penyedotan Umum:
- Blokir IP dan Pembatasan Laju: Permintaan berulang dari satu alamat IP dalam jangka pendek dapat menyebabkan blokir sementara atau permanen. Amazon memantau frekuensi dan pola permintaan untuk mengidentifikasi dan membatasi lalu lintas otomatis.
- Pemeriksaan User-Agent dan Header: Situs web sering memeriksa header HTTP, khususnya string
User-Agent, untuk mengidentifikasi lalu lintas browser yang sah. User-Agent yang tidak standar atau hilang dapat memicu alarm. - Tantangan CAPTCHA: CAPTCHA (Completely Automated Public Turing test to tell Computers and Humans Apart) dirancang untuk membedakan antara pengguna manusia dan bot. Amazon sering menggunakan CAPTCHA AWS WAF, yang melibatkan tantangan berbasis JavaScript kompleks atau tugas pengenalan gambar.
- Jebakan dan Tampalan: Tautan atau elemen tersembunyi di halaman, yang tidak terlihat bagi pengguna manusia tetapi terdeteksi oleh penyedot otomatis, dapat berfungsi sebagai jebakan untuk mengidentifikasi dan memblokir bot.
- Pemuatan Konten Dinamis: Banyak bagian halaman Amazon dimuat secara dinamis menggunakan JavaScript, membuatnya sulit bagi penyedot yang hanya berbasis permintaan HTTP untuk mengakses semua data.
Penyedotan Etis: Panduan Terbaik dan Kepatuhan
Pertimbangan etis dan hukum sangat penting dalam setiap upaya penyedotan data. Mematuhi prinsip ini tidak hanya memastikan kepatuhan tetapi juga berkontribusi pada keberlanjutan operasi penyedotan Anda. Selalu utamakan pengumpulan data yang bertanggung jawab untuk menghindari konsekuensi hukum dan menjaga hubungan positif dengan sumber data.
Panduan Etis Kunci:
- Periksa
robots.txt: Selalu periksa filerobots.txt(misalnya,https://www.amazon.com/robots.txt) untuk memahami bagian mana dari situs yang dilarang untuk crawling. Menghormati petunjuk ini adalah praktik etis dasar. - Hormati Ketentuan Layanan: Kenali Ketentuan Layanan Amazon. Meskipun beberapa ketentuan mungkin melarang penyedotan, memahaminya membantu Anda membuat keputusan yang terinformasi dan mengurangi risiko.
- Pembatasan Laju: Implementasikan jeda antar permintaan untuk menghindari beban berlebihan pada server Amazon. Ini mencegah blokir IP dan mengurangi beban pada situs target. Praktik umum adalah menambahkan jeda acak antara 5 hingga 15 detik.
- Kenali Diri Anda (Secara Bertanggung Jawab): Gunakan string
User-Agentyang deskriptif yang mencakup informasi kontak Anda. Ini memungkinkan administrator situs untuk menghubungi Anda jika mereka memiliki kekhawatiran, membangun transparansi. - Hanya Menyedot Data yang Tersedia Publik: Fokus pada data yang dapat diakses publik dan tidak memerlukan kredensial login. Hindari menyedot informasi pribadi atau sensitif.
Panduan Langkah Demi Langkah untuk Menyedot Amazon pada Tahun 2026
Bagian ini menjelaskan panduan detail dan praktis untuk menyiapkan lingkungan penyedotan Anda, menangani permintaan, dan memproses data, dengan fokus khusus pada integrasi penyelesaian CAPTCHA.
Langkah 1: Persiapan Lingkungan
Sebelum menulis kode apa pun, pastikan lingkungan pengembangan Anda telah disiapkan dengan baik. Python adalah pilihan populer untuk penyedotan web dengan Python karena ekosistem perpustakaannya yang kaya.
Tujuan: Membangun fondasi yang stabil dan efisien untuk proyek penyedotan Anda.
Operasi:
-
Instal Python: Jika belum terinstal, unduh dan pasang Python 3.8+ dari situs web resmi.
-
Buat Lingkungan Virtual: Ini mengisolasi dependensi proyek Anda.
bashpython3 -m venv amazon_scraper_env source amazon_scraper_env/bin/activate # Pada Windows, gunakan `amazon_scraper_env\Scripts\activate` -
Instal Perpustakaan Penting:
requests: Untuk membuat permintaan HTTP.BeautifulSoup4: Untuk menganalisis konten HTML.lxml: Parser HTML yang cepat, sering digunakan bersama BeautifulSoup.selenium(opsional): Untuk rendering konten dinamis, jika diperlukan.webdriver_manager(opsional): Untuk mengelola driver browser untuk Selenium.
bashpip install requests beautifulsoup4 lxml # Jika menggunakan Selenium: # pip install selenium webdriver_manager
Catatan: Perbarui perpustakaan Anda secara berkala untuk memanfaatkan fitur terbaru dan pembaruan keamanan.
Langkah 2: Membuat Permintaan Awal dan Menangani Anti-Penyedotan Dasar
Mulai dengan permintaan dasar, fokus pada penggantian user-agent dan penerapan jeda untuk meniru pola navigasi manusia.
Tujuan: Mengirim permintaan ke Amazon dan mengambil konten HTML sambil meminimalkan risiko blokir segera.
Operasi:
- Ganti User-Agent: Pertahankan daftar string user-agent browser umum dan ganti setiap permintaan. Ini membuat penyedot Anda terlihat sebagai browser berbeda.
- Terapkan Jeda: Tambahkan jeda acak antar permintaan untuk menghindari pembatasan laju.
python
import requests
import time
import random
from bs4 import BeautifulSoup
user_agents = [
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36',
'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 13_1) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/16.1 Safari/605.1.15',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 13_1) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/16.1 Safari/605.1.15',
]
def fetch_amazon_page(url):
headers = {'User-Agent': random.choice(user_agents)}
try:
response = requests.get(url, headers=headers, timeout=10)
response.raise_for_status() # Memicu eksepsi untuk kesalahan HTTP
time.sleep(random.uniform(5, 15)) # Jeda acak
return response.text
except requests.exceptions.RequestException as e:
print(f"Permintaan gagal: {e}")
return None
# Contoh penggunaan:
# product_page_url = "https://www.amazon.com/dp/B08XYZ123"
# html_content = fetch_amazon_page(product_page_url)
# if html_content:
# soup = BeautifulSoup(html_content, 'lxml')
# # Proses objek soupCatatan: Untuk skenario yang lebih canggih, pertimbangkan menggunakan layanan rotasi proxy untuk mengelola kumpulan alamat IP, meningkatkan anonimitas Anda saat melakukan penyedotan Amazon. Untuk wawasan lebih lanjut tentang mengelola proxy, lihat integrasi proxy untuk penyelesaian CAPTCHA. Ini penting untuk operasi skala besar.
Langkah 3: Menangani Tantangan CAPTCHA dengan CapSolver
Amazon sering menerapkan CAPTCHA AWS WAF untuk memblokir permintaan otomatis. Tantangan ini bisa berbasis token (membutuhkan lingkungan browser nyata) atau berbasis klasifikasi gambar. CapSolver menawarkan solusi kuat untuk kedua jenis ini, memungkinkan Anda mengintegrasikan penyelesaian CAPTCHA ke dalam alur kerja penyedotan Amazon Anda.
Tujuan: Menyelesaikan tantangan CAPTCHA AWS WAF secara programatis dan melanjutkan ekstraksi data tanpa gangguan.
Operasi:
CapSolver menyediakan dua tipe tugas utama untuk CAPTCHA AWS WAF:
AntiAwsWafTask: Untuk tantangan berbasis token, sering memerlukan parameter sepertiawsKey,awsIv,awsContext, danawsChallengeJS.AwsWafClassification: Untuk tantangan klasifikasi gambar, di mana Anda menyediakan gambar dan pertanyaan.
CAPTCHA AWS WAF Berbasis Token (Contoh Python)
Contoh ini menunjukkan cara menyelesaikan CAPTCHA AWS WAF berbasis token menggunakan tipe tugas AntiAwsWafTask dari CapSolver. Ini sangat berguna ketika Amazon menampilkan tantangan berbasis JavaScript.
python
import requests
import time
CAPSOLVER_API_KEY = "YOUR_CAPSOLVER_API_KEY" # Ganti dengan kunci API CapSolver Anda
def create_aws_waf_task(website_url, aws_key, aws_iv, aws_context, aws_challenge_js, proxy=None):
payload = {
"clientKey": CAPSOLVER_API_KEY,
"task": {
"type": "AntiAwsWafTask", # Gunakan AntiAwsWafTaskProxyless jika tidak ingin menggunakan proxy Anda sendiri
"websiteURL": website_url,
"awsKey": aws_key,
"awsIv": aws_iv,
"awsContext": aws_context,
"awsChallengeJS": aws_challenge_js
}
}
if proxy:
payload["task"]["proxy"] = proxy # Tambahkan proxy jika disediakan
response = requests.post("https://api.capsolver.com/createTask", json=payload)
response.raise_for_status()
return response.json().get("taskId")
def get_task_result(task_id):
payload = {
"clientKey": CAPSOLVER_API_KEY,
"taskId": task_id
}
while True:
response = requests.post("https://api.capsolver.com/getTaskResult", json=payload)
response.raise_for_status()
result = response.json()
if result.get("status") == "ready":
return result.get("solution")
elif result.get("status") == "failed":
raise Exception(f"Tugas CapSolver gagal: {result.get('errorDescription')}")
time.sleep(3) # Pemeriksaan setiap 3 detik
# Contoh penggunaan (ganti dengan nilai yang sebenarnya dari halaman tantangan Amazon):
# website_url = "https://efw47fpad9.execute-api.us-east-1.amazonaws.com/latest"
# aws_key = "nilai_kunci_dari_halaman_amazon"
# aws_iv = "nilai_iv_dari_halaman_amazon"
# aws_context = "nilai_context_dari_halaman_amazon"
# aws_challenge_js = "url_skrip_tantangan_js"
# proxy_string = "http://pengguna:pass@proxy:port" # Opsional, jika menggunakan AntiAwsWafTask
# try:
# task_id = create_aws_waf_task(website_url, aws_key, aws_iv, aws_context, aws_challenge_js, proxy_string)
# print(f"ID Tugas CapSolver: {task_id}")
# solution = get_task_result(task_id)
# aws_waf_token = solution.get("cookie")
# print(f"Token AWS WAF: {aws_waf_token}")
# # Gunakan token ini dalam permintaan berikutnya sebagai cookie:
# # cookies = {'aws-waf-token': aws_waf_token}
# # response = requests.get(target_url, headers=headers, cookies=cookies)
# except Exception as e:
# print(f"Kesalahan menyelesaikan CAPTCHA: {e}")Catatan: Saat mengintegrasikan CapSolver, pastikan Anda menangkap semua parameter yang diperlukan (awsKey, awsIv, awsContext, awsChallengeJS) dari halaman tantangan Amazon. Nilai-nilai ini biasanya ditemukan dalam sumber HTML halaman tantangan CAPTCHA ketika kode status 405 dikembalikan. Untuk detail lebih lanjut, lihat dokumentasi CapSolver tentang AWS WAF.
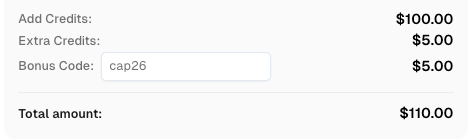
Gunakan kode
CAP26saat mendaftar di CapSolver untuk mendapatkan kredit tambahan!
CAPTCHA AWS WAF Berbasis Klasifikasi Gambar (Contoh Python)
Untuk CAPTCHA berbasis gambar, tipe tugas AwsWafClassification dari CapSolver dapat digunakan. Ini melibatkan pengiriman gambar CAPTCHA dan pertanyaan terkait ke CapSolver untuk pengenalan.
python
import requests
import base64
import time
CAPSOLVER_API_KEY = "YOUR_CAPSOLVER_API_KEY" # Ganti dengan kunci API CapSolver Anda
def solve_aws_waf_classification(image_path, question):
with open(image_path, "rb") as f:
image_base64 = base64.b64encode(f.read()).decode("utf-8")
payload = {
"clientKey": CAPSOLVER_API_KEY,
"task": {
"type": "AwsWafClassification",
"image": image_base64,
"question": question
}
}
response = requests.post("https://api.capsolver.com/createTask", json=payload)
response.raise_for_status()
task_id = response.json().get("taskId")
get_payload = {"clientKey": CAPSOLVER_API_KEY, "taskId": task_id}
while True:
res = requests.post("https://api.capsolver.com/getTaskResult", json=get_payload)
res.raise_for_status()
data = res.json()
if data.get("status") == "ready":
return data.get("solution")
elif data.get("status") == "failed":
raise Exception(f"Tugas klasifikasi CapSolver gagal: {data.get('errorDescription')}")
time.sleep(2)
# Contoh penggunaan:
# Mengasumsikan 'captcha_image.png' adalah file gambar CAPTCHA yang diunduh
# text_pertanyaan = "Pilih semua gambar dengan sepeda" # Pertanyaan yang menyertai gambar
# try:result = solve_aws_waf_classification("captcha_image.png", question_text)
print(f"Indeks yang dipilih: {result}")
# Hasilnya akan menjadi daftar indeks yang sesuai dengan gambar yang dipilih.
# Anda kemudian akan menggunakan indeks ini untuk berinteraksi dengan halaman Amazon.
except Exception as e:
print(f"Kesalahan dalam menyelesaikan CAPTCHA gambar: {e}")
**Catatan:** Metode ini memerlukan Anda untuk terlebih dahulu menangkap gambar CAPTCHA dan pertanyaan terkait dari halaman Amazon. Ini sering melibatkan penggunaan browser tanpa tampilan seperti Selenium untuk merender halaman dan mengambil screenshot dari elemen CAPTCHA. CapSolver mempermudah proses pengenalan, membuat scraping Amazon lebih andal.
### Langkah 4: Ekstraksi dan Pemrosesan Data
Setelah berhasil mengambil konten HTML, langkah berikutnya adalah memproses dan mengekstrak data yang diinginkan. BeautifulSoup adalah perpustakaan yang sangat baik untuk tujuan ini.
**Tujuan:** Untuk secara sistematis mengekstrak titik data spesifik dari struktur HTML.
**Operasi:**
1. **Periksa Struktur HTML:** Gunakan alat pengembang browser untuk memeriksa struktur HTML halaman Amazon dan identifikasi selektor CSS atau ekspresi XPath untuk data yang Anda butuhkan (misalnya, judul produk, harga, ulasan).
2. **Parsing dengan BeautifulSoup:** Muat konten HTML ke dalam objek BeautifulSoup dan gunakan metode (`find`, `find_all`, `select`) untuk menavigasi dan mengekstrak data.
```python
# ... (kode sebelumnya untuk mengambil konten HTML)
def parse_amazon_product_page(html_content):
soup = BeautifulSoup(html_content, 'lxml')
product_data = {}
# Contoh: Ekstrak judul produk
title_element = soup.select_one('#productTitle')
if title_element:
product_data['title'] = title_element.get_text(strip=True)
# Contoh: Ekstrak harga produk
price_element = soup.select_one('.a-price .a-offscreen')
if price_element:
product_data['price'] = price_element.get_text(strip=True)
# Contoh: Ekstrak rating produk
rating_element = soup.select_one('#acrCustomerReviewText')
if rating_element:
product_data['reviews_count'] = rating_element.get_text(strip=True)
# Tambahkan logika ekstraksi lainnya sesuai kebutuhan
return product_data
# Contoh penggunaan:
# html_content = fetch_amazon_page("https://www.amazon.com/dp/B08XYZ123")
# if html_content:
# data = parse_amazon_product_page(html_content)
# print(data)Catatan: Struktur HTML Amazon dapat berubah, jadi secara berkala tinjau dan perbarui selektor Anda. Penanganan kesalahan yang kuat dan validasi penting untuk memastikan kualitas data selama scraping Amazon.
Langkah 5: Penyimpanan dan Manajemen Data
Setelah ekstraksi, simpan data Anda dalam format yang terstruktur untuk analisis lebih lanjut. Format umum termasuk CSV, JSON, atau basis data.
Tujuan: Untuk menyimpan data yang diekstrak dalam bentuk yang terorganisir dan mudah diakses.
Operasi:
- Pilih Format Penyimpanan: Untuk dataset kecil, file CSV atau JSON lebih praktis. Untuk dataset besar dan kompleks, pertimbangkan basis data (misalnya, SQLite, PostgreSQL, MongoDB).
- Implementasikan Logika Penyimpanan: Tulis kode untuk menyimpan data yang diekstrak ke format yang dipilih.
python
import json
import csv
def save_to_json(data, filename):
with open(filename, 'w', encoding='utf-8') as f:
json.dump(data, f, ensure_ascii=False, indent=4)
print(f"Data disimpan ke {filename}")
def save_to_csv(data, filename, fieldnames):
with open(filename, 'w', newline='', encoding='utf-8') as f:
writer = csv.DictWriter(f, fieldnames=fieldnames)
writer.writeheader()
writer.writerows(data)
print(f"Data disimpan ke {filename}")
# Contoh penggunaan:
# all_product_data = [
# {'title': 'Produk A', 'price': '$10.99', 'reviews_count': '1.234 ulasan'},
# {'title': 'Produk B', 'price': '$25.00', 'reviews_count': '567 ulasan'},
# ]
# save_to_json(all_product_data, 'amazon_products.json')
# save_to_csv(all_product_data, 'amazon_products.csv', ['title', 'price', 'reviews_count'])Catatan: Saat menangani volume data besar, pertimbangkan pembaruan inkremental ke penyimpanan Anda untuk menghindari scraping ulang informasi yang sudah ada. Ini mengoptimalkan proses scraping Amazon Anda.
Penyelesaian Masalah Umum Scraping Amazon
Meskipun telah bersiap dengan baik, Anda mungkin menghadapi masalah selama scraping Amazon. Berikut beberapa masalah umum dan solusinya.
Masalah 1: IP Diblokir atau Dibatasi
Deskripsi: Scraper Anda menerima kesalahan HTTP 403 (Dilarang) atau 429 (Terlalu Banyak Permintaan), atau permintaan hanya timeout.
Solusi:
- Gunakan Proksi: Gunakan layanan proksi yang berputar untuk mendistribusikan permintaan ke banyak alamat IP. Ini adalah cara paling efektif untuk menghindari pemblokiran IP selama scraping Amazon. Untuk penjelasan lebih dalam tentang menghindari pemblokiran, baca tentang scraping web tanpa terblokir.
- Tingkatkan Waktu Tunda: Perpanjang durasi
time.sleep()antar permintaan dan tambahkan lebih banyak randomisasi. - Manajemen Sesi: Gunakan
requests.Session()untuk mempertahankan cookie dan header antar permintaan, meniru sesi penjelajahan yang lebih alami.
Masalah 2: CAPTCHA Ditemui
Deskripsi: Amazon menampilkan tantangan CAPTCHA, menghentikan proses scraping Anda.
Solusi:
- Integrasikan CapSolver: Seperti yang ditunjukkan di Langkah 4, gunakan API CapSolver untuk menyelesaikan CAPTCHA AWS WAF secara otomatis. Ini adalah solusi yang andal untuk tantangan kompleks yang ditemui selama scraping Amazon.
- Browser Tanpa Tampilan: Untuk CAPTCHA berbasis JavaScript yang sangat kompleks, Anda mungkin perlu menggunakan browser tanpa tampilan (seperti Selenium dengan Chrome/Firefox) untuk merender halaman, menangkap CAPTCHA, lalu mengirimkannya ke CapSolver.
Masalah 3: Perubahan Struktur HTML
Deskripsi: Logika ekstraksi data Anda rusak karena Amazon telah memperbarui struktur HTML situsnya.
Solusi:
- Pemantauan Berkala: Secara berkala periksa output scraper Anda dan halaman Amazon yang dituju. Atur pemberitahuan untuk format data yang tidak terduga atau bidang yang hilang.
- Selektor Fleksibel: Gunakan selektor CSS atau ekspresi XPath yang lebih umum yang kurang mungkin berubah. Hindari mengandalkan nama kelas yang sangat spesifik atau yang dihasilkan otomatis.
- Penanganan Kesalahan: Implementasikan blok
try-exceptdi sekitar logika parsing untuk menangani elemen yang hilang secara elegan dan mencatat kesalahan untuk tinjauan kemudian hari.
Masalah 4: Konten Dinamis Tidak Dimuat
Deskripsi: Beberapa data yang Anda harapkan untuk diambil tidak hadir dalam respons HTML awal.
Solusi:
- Browser Tanpa Tampilan: Gunakan Selenium atau Playwright untuk merender halaman penuh, termasuk konten yang dimuat via JavaScript. Ini memungkinkan Anda mengakses DOM lengkap selama scraping Amazon.
- Pemantauan API: Periksa permintaan jaringan di alat pengembang browser untuk melihat apakah data dimuat melalui panggilan API internal. Jika ya, Anda mungkin bisa langsung memanggil API tersebut.
Optimasi Kinerja untuk Scraping Amazon Skala Besar
Untuk operasi scraping Amazon skala besar, efisiensi sangat penting. Mengoptimalkan kinerja scraper Anda dapat menghemat waktu dan sumber daya.
1. Koordinasi dan Paralelisme
Alih-alih mengambil halaman secara berurutan, proses halaman yang berbeda secara bersamaan menggunakan threading atau pemrograman asinkron.
- Threading: Gunakan modul
threadingPython untuk tugas I/O-bound (seperti menunggu respons jaringan). - Asyncio: Untuk operasi I/O-bound yang sangat efisien,
asynciodenganaiohttpbisa sangat efektif.
Peringatan: Saat menggunakan koordinasi, lebih hati-hati lagi terhadap batas permintaan Amazon. Distribusikan permintaan dengan hati-hati untuk menghindari membanjiri server dan memicu pemblokiran.
2. Scraping Terdistribusi
Untuk proyek yang sangat besar, pertimbangkan mendistribusikan tugas scraping ke banyak mesin atau instans cloud. Ini bisa dikelola menggunakan alat seperti Celery dengan broker pesan.
3. Penjadwalan Permintaan Cerdas
Prioritaskan permintaan untuk data kritis dan jadwalkan data yang kurang penting pada jam-jam yang tidak sibuk. Implementasikan mekanisme retry yang kuat untuk permintaan yang gagal dengan backoff eksponensial.
4. Cache Data
Simpan data yang sering diakses secara lokal untuk mengurangi jumlah permintaan ke Amazon. Hanya re-scraping data ketika diketahui telah berubah atau setelah interval waktu tertentu.
Ringkasan Perbandingan: Manual vs. Otomatis vs. API Scraping
Memilih pendekatan yang tepat untuk scraping Amazon bergantung pada skala, kompleksitas, dan sumber daya proyek Anda. Berikut adalah perbandingan metode umum, termasuk wawasan dari berbagai layanan API scraper Amazon terbaik:
| Fitur | Scraping Manual (Copy-Paste) | Scraper Otomatis Kustom (Python) | Amazon Product Advertising API (PA-API) | API Scraping Pihak Ketiga |
|---|---|---|---|---|
| Usaha | Tinggi | Sedang hingga Tinggi | Sedang | Rendah |
| Biaya | Gratis (memakan waktu) | Rendah (waktu pengembangan) | Berbeda (berdasarkan penggunaan) | Berbeda (berdasarkan penggunaan) |
| Fleksibilitas | Sangat Tinggi | Tinggi | Terbatas (data yang telah didefinisikan) | Tinggi |
| Kecepatan | Sangat Rendah | Sedang hingga Tinggi | Tinggi | Sangat Tinggi |
| Anti-Scraping | N/A (manusia) | Tinggi (memerlukan pembaruan terus-menerus) | Ditangani oleh Amazon | Ditangani oleh penyedia |
| CAPTCHA | N/A (manusia) | Tinggi (memerlukan integrasi solver) | N/A | Ditangani oleh penyedia |
| Kelegalan/Etika | Risiko Rendah | Risiko Sedang (jika tidak hati-hati) | Risiko Rendah (API resmi) | Risiko Rendah (penyedia menangani kepatuhan) |
| Terbaik Untuk | Tugas kecil, satu kali | Kebutuhan data kustom, kontrol | Data produk resmi, afiliasi | Skala besar, proyek kompleks, kecepatan |
Catatan: Meskipun Amazon Product Advertising API (PA-API) menawarkan cara sah untuk mengakses beberapa data produk, seringkali memiliki keterbatasan pada jenis dan volume data yang tersedia, serta memerlukan kepatuhan terhadap ketentuan layanannya sendiri. Untuk scraping Amazon yang komprehensif, scraper otomatis kustom dengan mekanisme anti-pemblokiran dan penyelesaian CAPTCHA yang kuat, seperti yang disediakan oleh CapSolver, sering kali menawarkan keseimbangan terbaik antara fleksibilitas dan kontrol.
Kesimpulan
Berhasil melakukan scraping Amazon pada 2026 membutuhkan pendekatan strategis dan adaptif. Dari persiapan lingkungan yang cermat dan pertimbangan etis hingga penghindaran bot yang canggih dan pemrosesan data yang efisien, setiap langkah memainkan peran penting. Integrasi alat khusus seperti CapSolver untuk menangani tantangan CAPTCHA AWS WAF yang kompleks tidak lagi opsional, tetapi menjadi keharusan untuk ekstraksi data yang tidak terganggu dan andal. Dengan mematuhi panduan yang dijelaskan dalam panduan ini, Anda dapat membangun solusi scraping Amazon yang tangguh yang memberikan wawasan akurat, tepat waktu, dan bernilai dari platform e-commerce terbesar di dunia. Ingat, praktik scraping yang bertanggung jawab dan etis adalah dasar dari setiap upaya pengumpulan data yang berkelanjutan.
Siap meningkatkan kemampuan scraping Amazon Anda dan mengatasi tantangan CAPTCHA? Jelajahi layanan penyelesaian CAPTCHA lanjutan dari CapSolver hari ini dan sederhanakan alur kerja ekstraksi data Anda. Mulai dengan CapSolver
FAQ
T1: Apakah scraping Amazon legal?
J1: Kelegalan scraping Amazon kompleks dan bergantung pada berbagai faktor, termasuk data yang diambil, tujuan scraping, dan regulasi setempat. Secara umum, scraping data yang tersedia publik sering dianggap legal, tetapi melanggar ketentuan layanan atau scraping data pribadi/orang bisa menyebabkan masalah hukum. Selalu konsultasikan dengan ahli hukum untuk situasi spesifik. Praktik etis, seperti menghormati robots.txt dan batas permintaan, sangat penting.
T2: Bagaimana cara menghindari pemblokiran oleh Amazon?
J2: Untuk menghindari pemblokiran selama scraping Amazon, terapkan kombinasi strategi: gunakan proksi yang berputar, ganti user-agent, tambahkan jeda acak antar permintaan, kelola cookie dan sesi, serta selesaikan CAPTCHA secara efektif dengan layanan seperti CapSolver. Hindari pola permintaan agresif yang meniru perilaku bot.
T3: Apa itu CAPTCHA AWS WAF dan mengapa sulit diselesaikan?
J3: CAPTCHA AWS WAF adalah langkah keamanan yang digunakan oleh Amazon Web Services untuk melindungi situs web dari ancaman otomatis. Sulit diselesaikan karena sering melibatkan tantangan JavaScript kompleks, token yang dienkripsi, atau tugas pengenalan gambar yang dirancang agar mudah diselesaikan manusia tetapi sulit untuk bot. CapSolver spesialis dalam menyelesaikan CAPTCHA lanjutan secara programatis.
T4: Bisakah saya mengambil ulasan produk Amazon?
J4: Ya, mengambil ulasan produk yang tersedia publik adalah kasus penggunaan umum untuk scraping Amazon. Namun, perhatikan volume dan frekuensi permintaan Anda untuk menghindari memicu mekanisme anti-scraping. Pastikan metode Anda sesuai dengan panduan etis dan ketentuan layanan Amazon.
T5: Bagaimana CapSolver membantu scraping Amazon?
J5: CapSolver menyediakan layanan API khusus untuk menyelesaikan berbagai jenis CAPTCHA, termasuk CAPTCHA AWS WAF, yang sering ditemui selama scraping Amazon. Dengan mengintegrasikan CapSolver ke dalam scraper Anda, Anda dapat melewati tantangan ini secara programatis, memastikan aliran data yang tidak terganggu dan meningkatkan keandalan operasi scraping Anda. Pelajari lebih lanjut tentang solusi CapSolver
Pernyataan Kepatuhan: Informasi yang diberikan di blog ini hanya untuk tujuan informasi. CapSolver berkomitmen untuk mematuhi semua hukum dan peraturan yang berlaku. Penggunaan jaringan CapSolver untuk kegiatan ilegal, penipuan, atau penyalahgunaan sangat dilarang dan akan diselidiki. Solusi penyelesaian captcha kami meningkatkan pengalaman pengguna sambil memastikan kepatuhan 100% dalam membantu menyelesaikan kesulitan captcha selama pengambilan data publik. Kami mendorong penggunaan layanan kami secara bertanggung jawab. Untuk informasi lebih lanjut, silakan kunjungi Syarat Layanan dan Kebijakan Privasi.
Lebih lanjut
Bisakah AI Menyelesaikan CAPTCHA? Bagaimana Deteksi dan Menyelesaikan Sebenarnya Bekerja
Jelajahi bagaimana AI mendeteksi dan menyelesaikan tantangan CAPTCHA, dari pengenalan gambar hingga analisis perilaku. Pahami teknologi di balik pemecah CAPTCHA AI dan bagaimana CapSolver membantu alur kerja otomatis. Pelajari tentang pertarungan yang berkembang antara AI dan verifikasi manusia.

Sora Fujimoto
14-Apr-2026

Kesalahan CAPTCHA 600010: Apa Artinya dan Cara Mengatasinya dengan Cepat
Menghadapi Kesalahan CAPTCHA 600010? Pelajari apa arti kesalahan Cloudflare Turnstile ini dan dapatkan solusi langkah demi langkah untuk pengguna dan pengembang, termasuk integrasi CapSolver untuk otomatisasi.

Anh Tuan
14-Apr-2026
Cara Menyelesaikan Tantangan AWS WAF Menggunakan Ekstensi: Panduan Lengkap
Pelajari cara menyelesaikan CAPTCHA AWS WAF dan tantangan secara otomatis dengan menggunakan ekstensi CapSolver. Panduan ini mencakup pengenalan gambar, mode token, dan otomatisasi n8n.
Emma Foster
13-Apr-2026

Cara Mengambil Data dari Amazon: Panduan 2026 untuk Ekstraksi Data Etis & Penyelesaian CAPTCHA
Menguasai scraping Amazon pada 2026 dengan panduan lengkap ini. Pelajari teknik langkah demi langkah, contoh kode, dan cara mengatasi tantangan CAPTCHA AWS dengan menggunakan CapSolver untuk pengambilan data yang efisien dan etis.
Emma Foster
10-Apr-2026
Cara Mengotomatisasi Penyelesaian CAPTCHA AWS WAF: Alat, Integrasi API & Panduan Harga
Pelajari cara otomatisasi penyelesaian CAPTCHA AWS WAF dengan alat yang tepat, langkah integrasi API, dan breakdown biaya lengkap. Bandingkan layanan terbaik dan mulai dengan cepat.

Ethan Collins
10-Apr-2026
API Penyelesaian CAPTCHA Andal untuk reCAPTCHA: Apa yang Harus Dicari
Mencari API penyelesaian CAPTCHA yang dapat dipercaya untuk reCAPTCHA? Bandingkan penyedia terbaik berdasarkan kecepatan, biaya, dan tingkat keberhasilan. Temukan solusi terbaik untuk kebutuhan otomatisasi Anda.

Rajinder Singh
09-Apr-2026