Search API vs Rantai Pasok Pengetahuan: Panduan Infrastruktur Data Kecerdasan Buatan

Emma Foster
Machine Learning Engineer
Ringkasan
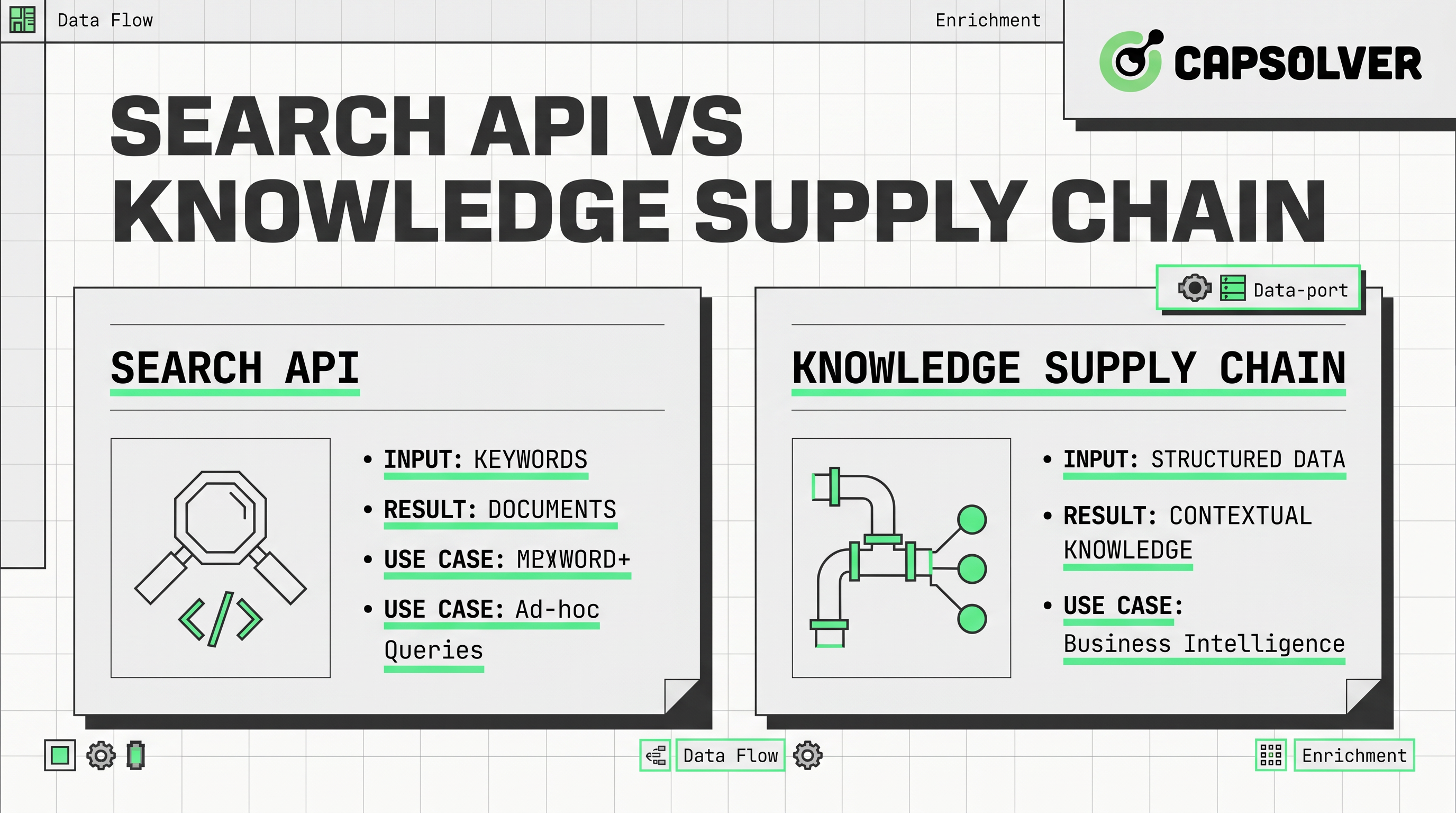
- Alat API pencarian berguna untuk penemuan cepat, tetapi tidak mencakup kebutuhan penuh sistem AI produksi.
- Rantai pasok pengetahuan mencakup penemuan, ekstraksi, validasi, penyimpanan, orchestrasi, dan pemantauan.
- API SERP membantu mengumpulkan hasil pencarian yang diurutkan, sedangkan API scraping web membantu mengumpulkan konten halaman.
- Infrastruktur data web yang kuat bergantung pada kesegaran, kualitas sumber, auditabilitas, dan pengumpulan yang memperhatikan kebijakan.
- Pipa data AI harus menghubungkan pengambilan dengan parsing, peningkatan, tata kelola, dan penggunaan model di hulu.
- Untuk otomatisasi yang disetujui, tim mungkin juga membutuhkan lapisan keandalan ketika langkah verifikasi mengganggu alur pengumpulan.
Pendahuluan
Jawaban singkatnya sederhana. API pencarian adalah antarmuka pengambilan, sedangkan rantai pasok pengetahuan adalah model operasional untuk infrastruktur data AI. Artikel ini ditujukan untuk insinyur AI, pendiri teknologi, tim SEO, dan pembangun platform data yang membutuhkan data web terkini tanpa kehilangan kendali atas kualitas atau kepatuhan. Jika Anda memilih antara antarmuka pencarian, API SERP, dan tumpukan infrastruktur data web yang lebih luas, keputusan yang benar bergantung pada risiko, kesegaran, dan penggunaan di hulu. Nilai intinya adalah kejelasan praktis. Anda akan melihat di mana setiap opsi cocok, di mana ia gagal, dan bagaimana merancang pipa data AI yang lebih andal.
Pengantar API Pencarian dan Rantai Pasok Pengetahuan
Perbedaan utamanya adalah arsitektural. API pencarian biasanya menerima query dan mengembalikan tautan yang diurutkan, cuplikan, atau hasil ringkasan dari indeks. Hal ini membuat alat ini menarik ketika tim membutuhkan jawaban cepat, peningkatan ringan, atau prototipe tahap awal.
Rantai pasok pengetahuan lebih luas secara desain. Ia memperlakukan pengumpulan data untuk AI sebagai alur terus-menerus dari penemuan sumber hingga pengumpulan, validasi, penyimpanan, transformasi, dan pengiriman. Model ini lebih sesuai dengan sistem agen, alat intelijen pasar, dan lapisan pengambilan yang harus mendukung keputusan yang dapat diulang.
Perbedaan ini penting karena sistem AI bertindak berdasarkan apa yang diterimanya. Rangka Kerja Manajemen Risiko AI NIST menjelaskan bahwa AI yang dapat dipercaya bergantung pada praktik desain, pengembangan, penggunaan, dan evaluasi, bukan hanya output model. Dalam praktiknya, artinya lapisan pengambilan adalah bagian dari permukaan risiko.
Alasan lain adalah kebijakan. Google Search Central menyatakan bahwa robots.txt digunakan terutama untuk mengelola lalu lintas crawler dan bukan metode universal untuk menyembunyikan konten. Pengingat ini penting bagi setiap tim yang membangun infrastruktur data web. Kepatuhan dimulai sebelum permintaan pertama.
Cara Kerja API Pencarian dalam Sistem Pengambilan Data
Deskripsi paling sederhana adalah ini. API pencarian berada di lapisan penemuan. Ia mengubah query teks menjadi hasil yang diurutkan yang dapat melayani chatbot, copilot, atau asisten penelitian.
Mayoritas alat pencarian dioptimalkan untuk kecepatan dan kenyamanan pengembang. Biasanya ini berarti data yang telah diindeks, hasil yang disimpan, atau lapisan relevansi yang telah dibangun. Untuk tugas berisiko rendah, ini cukup. Bot dukungan, alat ide SEO, atau agen prototipe sering kali diuntungkan oleh jenis endpoint pengambilan ini karena sistem membutuhkan arah sebelum membutuhkan bukti mendalam.
API SERP lebih sempit. Ia fokus pada halaman hasil mesin pencari dan elemen hasil terkait. Ini bisa berguna untuk pelacakan peringkat, pemantauan query, dan penelitian SEO kompetitif. Namun, API SERP tetap mencerminkan lapisan pencarian, bukan lapisan konten penuh. Jika sistem Anda membutuhkan teks halaman nyata, bidang yang struktur, atau perbandingan historis, biasanya Anda membutuhkan langkah lain.
Ini adalah tempat orang-orang bingung antara penemuan dan pengetahuan. Penemuan memberi tahu Anda di mana mencari. Pengetahuan memerlukan pengambilan, parsing, dan pemeriksaan apa yang sebenarnya ada. Endpoint pencarian membantu bagian pertama. Ia tidak menyelesaikan seluruh pipa data AI.
Apa Itu Rantai Pasok Pengetahuan dalam Arsitektur AI
Cara yang lebih baik untuk mendefinisikannya adalah secara operasional. Rantai pasok pengetahuan adalah sistem yang memindahkan data dari web terbuka ke konteks yang siap untuk model, agen, dan analis.
Konsep rantai pasok muncul dalam tulisan industri terbaru, tetapi banyak artikel berhenti pada metafora. Versi praktis memiliki enam lapisan. Pertama adalah penemuan melalui antarmuka pencarian, API SERP, feed, sitemap, atau sumber yang diketahui. Kedua adalah ekstraksi melalui API scraping web, otomatisasi browser, atau koneksi langsung ke sumber. Ketiga adalah normalisasi, di mana HTML, JSON, PDF, dan metadata diubah menjadi catatan yang konsisten. Keempat adalah verifikasi, yang memeriksa kesegaran, duplikasi, kepemilikan, dan kualitas sumber. Kelima adalah penyimpanan dan indeksasi untuk pengambilan. Keenam adalah orchestrasi, di mana pipa data AI mengirimkan hasil ke sistem RAG, evaluator, atau alat agen.
Model Context Protocol menawarkan petunjuk yang berguna di sini. dokumentasi MCP mendefinisikannya sebagai standar terbuka untuk menghubungkan aplikasi AI dengan sumber data, alat, dan alur kerja. Ia tidak menggantikan lapisan pencarian, tetapi menunjukkan mengapa rantai pasok pengetahuan harus mencakup antarmuka di luar pengambilan.
Secara singkat, API pencarian adalah alat. Rantai pasok pengetahuan adalah sistem.
Perbedaan Kunci Antara API Pencarian dan Rantai Pasok Pengetahuan
Jawaban yang paling jelas ada pada batasan operasional. API pencarian biasanya dioptimalkan untuk pencarian cepat. Rantai pasok pengetahuan dioptimalkan untuk kualitas data di bawah beban kerja nyata.
Ringkasan Perbandingan
| Dimensi | API pencarian | API SERP | Rantai pasok pengetahuan |
|---|---|---|---|
| Tugas utama | Penemuan berbasis query | Pengumpulan hasil SERP | Pengadaan data lengkap untuk AI |
| Output biasanya | Tautan, cuplikan, ringkasan | Elemen SERP yang diurutkan | Konten penuh, metadata, sejarah, validasi |
| Terbaik untuk | Prototipe, asisten, penelitian ringan | Pemantauan SEO, pelacakan hasil | Agen, sistem intelijen, AI produksi |
| Kontrol kesegaran | Terbatas dan bergantung pada penyedia | Sedang di lapisan pencarian | Tinggi ketika dikombinasikan dengan pengumpulan langsung |
| Kedalaman bukti | Rendah hingga sedang | Rendah hingga sedang | Tinggi |
| Kepatuhan | Terbatas | Sedang | Kuat |
| Peran dalam pipa data AI | Langkah pertama | Langkah pertama dengan penekanan SERP | Model operasional multi-langkah |
Kesenjangan kompetitif dalam artikel saat ini adalah panduan praktis. Banyak posting menjelaskan mengapa alat pencarian cepat, atau mengapa rantai pasok pengetahuan terdengar strategis. Lebih sedikit yang menjelaskan di mana satu berakhir dan yang lain dimulai di dalam infrastruktur data web nyata. Batas ini menentukan keandalan sistem.
Perbedaan kedua adalah auditabilitas. Ketika model menjawab dari cuplikan saja, tim sering kali tidak dapat memeriksa jalur transformasi sumber. Ketika rantai pasok pengetahuan menyimpan konten halaman, timestamp, log ekstraksi, dan pemeriksaan kualitas, jawaban yang sama lebih mudah untuk direview dan ditingkatkan.
Perbedaan ketiga adalah biaya kegagalan. Jika API penemuan mengembalikan ringkasan yang usang, aplikasi chat prototipe mungkin masih terasa layak. Jika masalah yang sama memengaruhi intelijen harga atau pemantauan kebijakan, biayanya bisa jauh lebih tinggi.
Kasus Penggunaan dalam Agen AI dan Infrastruktur Data
Kesesuaian paling mudah dilihat melalui kasus penggunaan. API pencarian bekerja baik ketika sistem membutuhkan orientasi cepat. Agen dapat menggunakan lapisan pengambilan ini untuk menemukan URL kandidat, penyebutan terbaru, atau kluster topik sebelum pengambilan yang lebih dalam dimulai.
API SERP bekerja baik ketika tugasnya berfokus pada pencarian. Tim SEO menggunakan API SERP untuk pemantauan peringkat, analisis hasil berbayar dan organik, serta pengujian query regional. Outputnya berguna, tetapi tetap merupakan satu lapisan bukti.
Rantai pasok pengetahuan lebih baik ketika tugasnya operasional. Pemantauan harga, intelijen calon pelanggan, pemantauan kebijakan, peningkatan katalog, penelitian pembelian, dan verifikasi berita semua membutuhkan lebih dari hasil yang diurutkan. Mereka membutuhkan ekstraksi, timestamp, kontrol skema, dan pipa data AI yang andal.
Ini juga adalah tempat alat internal penting. Tim yang membangun agen mungkin menggabungkan kerangka kerja agen AI, alat ekstraksi data terbaik, dan pengumpulan data yang skalabel untuk pelatihan LLM ke dalam satu tumpukan. Komponen-komponen ini lebih mudah dievaluasi ketika Anda memisahkan penemuan, ekstraksi, dan orchestrasi daripada memperlakukan setiap input hulu sebagai kategori alat yang sama.
Implikasi untuk Alat Scraping Web dan Teknik Data Engineering
Pelajaran terbesar adalah bahwa pengambilan saja tidak menghasilkan data yang dapat dipercaya. API scraping web penting karena mengubah tautan menjadi catatan yang dapat digunakan. Lapisan teknik data penting karena konten halaman mentah tidak konsisten, berisik, dan sering kali duplikat.
Itulah sebabnya desain pengumpulan yang patuh penting. Hormati panduan robots, batas kecepatan, kebijakan akses, dan pembatasan kontrak. panduan crawler Google menjelaskan dengan jelas bahwa pengelolaan lalu lintas dan perilaku crawling adalah bagian dari lingkungan operasional web. Infrastruktur data web yang baik harus mengurangi beban server, mendokumentasikan aturan sumber, dan mempertahankan jejak audit.
Dari sudut pandang alat, tumpukan biasanya terlihat seperti ini. API penemuan atau API SERP mengidentifikasi target. API scraping web atau alat browser mengumpulkan konten. Pipa data AI memproses, meningkatkan, dan menyimpan catatan. Alat evaluasi menilai kesegaran dan kepercayaan sumber. Kemudian kerangka kerja agen atau sistem RAG menggunakan hasilnya.
Kepatuhan operasional juga memerlukan catatan realistis. Beberapa alur otomatisasi yang disetujui menghadapi langkah verifikasi yang mengganggu pengumpulan atau pemantauan. Dalam kasus-kasus ini, tim terkadang menambahkan layanan pendukung seperti mengapa otomatisasi web terus gagal pada captcha atau agen AI pemantauan harga untuk menjaga alur kerja yang disetujui tetap stabil. Jika itu bagian dari tumpukan Anda, CapSolver relevan karena menawarkan pola API yang terdokumentasi untuk skenario tersebut.
Cara yang paling aman untuk membahas CapSolver adalah tetap dekat dengan dokumentasi resminya. Contoh di bawah ini mencerminkan format permintaan createTask yang terdokumentasi dari panduan API CapSolver dan hanya boleh digunakan dalam lingkungan otomatisasi yang disetujui.
json
POST https://api.capsolver.com/createTask
Host: api.capsolver.com
Content-Type: application/json
{
"clientKey": "API_KEY_ANDA",
"appId": "APP_ID",
"task": {
"type": "ImageToTextTask",
"body": "BASE64 gambar"
}
}Contoh ini bukan inti dari rantai pasok pengetahuan. Ia adalah komponen keandalan pendukung. Intinya tetap sama. Penemuan, pengumpulan, dan tata kelola harus dirancang bersama.
Tukarkan Kode Bonus CapSolver
Tingkatkan anggaran otomatisasi Anda secara instan!
Gunakan kode bonus CAP26 saat mengisi ulang akun CapSolver Anda untuk mendapatkan tambahan 5% bonus pada setiap pengisian ulang — tanpa batas.
Tukarkan sekarang di Dashboard CapSolver Anda
Kesimpulan
Kesimpulan praktisnya sederhana. API pencarian membantu sistem menemukan informasi, tetapi rantai pasok pengetahuan membantu sistem mempercayai, mengulang, dan menerapkannya. Jika beban kerja Anda eksploratif, lapisan pengambilan ini mungkin cukup. Jika beban kerja Anda memengaruhi produk, pendapatan, atau kepatuhan, Anda membutuhkan infrastruktur data web yang lebih luas dengan ekstraksi, validasi, dan penyimpanan yang terintegrasi.
Untuk sebagian besar tim, desain yang menang adalah hibrid. Gunakan API penemuan atau API SERP untuk penemuan. Gunakan API scraping web untuk pengumpulan konten. Lalu koneksi keduanya ke dalam pipa data AI dengan kebijakan sumber yang jelas, pemantauan, dan ulasan. Itu adalah jalur paling tahan lama untuk pengadaan data untuk AI.
Jika Anda merencanakan langkah berikutnya, audit tumpukan Anda per lapisan. Tanyakan di mana penemuan berakhir, di mana bukti dimulai, dan di mana tata kelola dicatat. Latihan ini biasanya mengungkap apakah Anda membutuhkan antarmuka yang lebih cepat, pipa yang lebih dalam, atau keduanya.
FAQ
Apakah API pencarian sama dengan API SERP?
Tidak. API pencarian adalah antarmuka pengambilan yang luas, sedangkan API SERP fokus pada halaman hasil mesin pencari dan elemen hasil terkait.
Kapan jenis antarmuka pengambilan ini cukup untuk aplikasi AI?
Biasanya cukup untuk prototipe, asisten internal, tugas penelitian berisiko rendah, dan langkah awal penemuan dalam pipa.
Apa yang membuat rantai pasok pengetahuan lebih baik untuk AI produksi?
Rantai pasok pengetahuan menambahkan ekstraksi, normalisasi, validasi, penyimpanan, dan orchestrasi. Lapisan-lapisan ini meningkatkan kesegaran, auditabilitas, dan penggunaan kembali.
Di mana API scraping web cocok dalam model ini?
API scraping web berada setelah penemuan. Ia mengubah URL dan halaman sumber menjadi konten yang struktur yang dapat diproses oleh pipa data AI.
Mengapa menyebut CapSolver dalam artikel tentang infrastruktur data AI?
Karena beberapa alur otomatisasi yang disetujui menghadapi gangguan verifikasi setelah penemuan. Dalam konteks sempit ini, CapSolver dapat mendukung kelanjutan operasional sebagai satu komponen di dalam sistem yang lebih luas dan memperhatikan kebijakan.