Crawlab के साथ CapSolver के एकीकरण: स्वचालित CAPTCHA हल करना वितरित ड्रॉलिंग के लिए

Rajinder Singh
Deep Learning Researcher

स्केल पर वेब क्रॉलर के प्रबंधन के लिए बल्कि बुनियादी ढांचा आवश्यक है। Crawlab एक शक्तिशाली वितरित वेब क्रॉलर प्रबंधन प्लेटफॉर्म है, और CapSolver एक आर्टिफिशियल इंटेलिजेंस पर आधारित CAPTCHA हल करने वाली सेवा है। एक साथ, वे एंटरप्राइज-कक्षा क्रॉलिंग प्रणालियां बनाते हैं जो स्वचालित रूप से CAPTCHA चुनौतियों को पार करती हैं।
इस गाइड में Crawlab स्पाइडर में CapSolver के एकीकरण के लिए पूर्ण, तैयार-कोड उदाहरण प्रदान किए जाते हैं।
आप क्या सीखेंगे
- Selenium के साथ reCAPTCHA v2 हल करें
- Cloudflare Turnstile हल करें
- Scrapy मिडलवेयर एकीकरण
- Node.js/Puppeteer एकीकरण
- स्केल पर CAPTCHA निपटान के शीर्ष अभ्यास
Crawlab क्या है?
Crawlab विभिन्न प्रोग्रामिंग भाषाओं के साथ स्पाइडर के प्रबंधन के लिए डिज़ाइन किया गया एक वितरित वेब क्रॉलर प्रशासन प्लेटफॉर्म है।
मुख्य विशेषताएं
- भाषा-अनाडिस्टिक: Python, Node.js, Go, Java, और PHP के साथ संगतता
- फ्रेमवर्क-लचीलापन: Scrapy, Selenium, Puppeteer, Playwright के साथ काम करता है
- वितरित वास्तुविज्ञान: मास्टर/वर्कर नोड्स के साथ क्षैतिज स्केलिंग
- प्रबंधन यूआई: स्पाइडर प्रबंधन और योजना के लिए वेब इंटरफेस
स्थापना
bash
# Docker Compose का उपयोग करें
git clone https://github.com/crawlab-team/crawlab.git
cd crawlab
docker-compose up -dUI को http://localhost:8080 पर पहुंचें (डिफ़ॉल्ट: admin/admin).
CapSolver क्या है?
CapSolver विभिन्न CAPTCHA प्रकार के लिए तेज और विश्वसनीय समाधान प्रदान करने वाली आर्टिफिशियल इंटेलिजेंस पर आधारित CAPTCHA हल करने वाली सेवा है।
समर्थित CAPTCHA प्रकार
- reCAPTCHA: v2, v3, और एंटरप्राइज
- Cloudflare: Turnstile और चुनौति
- AWS WAF: सुरक्षा बाधा अतिक्रमण
- और अधिक
API कार्य प्रवाह
- CAPTCHA पैरामीटर (प्रकार, siteKey, URL) जमा करें
- कार्य पहचान जांचें
- समाधान के लिए पॉल करें
- टोकन को पृष्ठ में डालें
पूर्वापेक्षा
- Python 3.8+ या Node.js 16+
- CapSolver API की - यहां साइन अप करें
- Chrome/Chromium ब्राउज़र
bash
# Python निर्भरता
pip install selenium requestsSelenium के साथ reCAPTCHA v2 हल करें
reCAPTCHA v2 हल करने के लिए पूर्ण Python स्क्रिप्ट:
python
"""
Crawlab + CapSolver: reCAPTCHA v2 सॉल्वर
Selenium के साथ reCAPTCHA v2 चुनौतियों के लिए पूर्ण स्क्रिप्ट
"""
import os
import time
import json
import requests
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
# कॉन्फ़िगरेशन
CAPSOLVER_API_KEY = os.getenv('CAPSOLVER_API_KEY', 'YOUR_CAPSOLVER_API_KEY')
CAPSOLVER_API = 'https://api.capsolver.com'
class CapsolverClient:
"""reCAPTCHA v2 के लिए CapSolver API क्लाइंट"""
def __init__(self, api_key: str):
self.api_key = api_key
self.session = requests.Session()
def create_task(self, task: dict) -> str:
"""CAPTCHA हल करने के लिए कार्य बनाएं"""
payload = {
"clientKey": self.api_key,
"task": task
}
response = self.session.post(
f"{CAPSOLVER_API}/createTask",
json=payload
)
result = response.json()
if result.get('errorId', 0) != 0:
raise Exception(f"CapSolver त्रुटि: {result.get('errorDescription')}")
return result['taskId']
def get_task_result(self, task_id: str, timeout: int = 120) -> dict:
"""कार्य परिणाम के लिए पॉल करें"""
for _ in range(timeout):
payload = {
"clientKey": self.api_key,
"taskId": task_id
}
response = self.session.post(
f"{CAPSOLVER_API}/getTaskResult",
json=payload
)
result = response.json()
if result.get('status') == 'ready':
return result['solution']
if result.get('status') == 'failed':
raise Exception("CAPTCHA हल नहीं हो सका")
time.sleep(1)
raise Exception("समाधान की प्रतीक्षा में समय सीमा समाप्त हो गई")
def solve_recaptcha_v2(self, website_url: str, site_key: str) -> str:
"""reCAPTCHA v2 हल करें और टोकन लौटाएं"""
task = {
"type": "ReCaptchaV2TaskProxyLess",
"websiteURL": website_url,
"websiteKey": site_key
}
print(f"{website_url} के लिए कार्य बनाया जा रहा है...")
task_id = self.create_task(task)
print(f"कार्य बनाया गया: {task_id}")
print("समाधान की प्रतीक्षा कर रहे हैं...")
solution = self.get_task_result(task_id)
return solution['gRecaptchaResponse']
def get_balance(self) -> float:
"""खाता शेष प्राप्त करें"""
response = self.session.post(
f"{CAPSOLVER_API}/getBalance",
json={"clientKey": self.api_key}
)
return response.json().get('balance', 0)
class RecaptchaV2Crawler:
"""reCAPTCHA v2 समर्थन के साथ Selenium क्रॉलर"""
def __init__(self, headless: bool = True):
self.headless = headless
self.driver = None
self.capsolver = CapsolverClient(CAPSOLVER_API_KEY)
def start(self):
"""ब्राउज़र की शुरुआत करें"""
options = Options()
if self.headless:
options.add_argument("--headless=new")
options.add_argument("--no-sandbox")
options.add_argument("--disable-dev-shm-usage")
options.add_argument("--window-size=1920,1080")
self.driver = webdriver.Chrome(options=options)
print("ब्राउज़र शुरू किया गया")
def stop(self):
"""ब्राउज़र बंद करें"""
if self.driver:
self.driver.quit()
print("ब्राउज़र बंद किया गया")
def detect_recaptcha(self) -> str:
"""reCAPTCHA का पता लगाएं और site key लौटाएं"""
try:
element = self.driver.find_element(By.CLASS_NAME, "g-recaptcha")
return element.get_attribute("data-sitekey")
except:
return None
def inject_token(self, token: str):
"""हल किया गया टोकन पृष्ठ में डालें"""
self.driver.execute_script(f"""
// g-recaptcha-response टेक्सटएरिया सेट करें
var responseField = document.getElementById('g-recaptcha-response');
if (responseField) {{
responseField.style.display = 'block';
responseField.value = '{token}';
}}
// सभी छिपे हुए उत्तर क्षेत्रों को सेट करें
var textareas = document.querySelectorAll('textarea[name="g-recaptcha-response"]');
for (var i = 0; i < textareas.length; i++) {{
textareas[i].value = '{token}';
}}
""")
print("टोकन डाल दिया गया")
def submit_form(self):
"""फॉर्म जमा करें"""
try:
submit = self.driver.find_element(
By.CSS_SELECTOR,
'button[type="submit"], input[type="submit"]'
)
submit.click()
print("फॉर्म जमा किया गया")
except Exception as e:
print(f"फॉर्म जमा नहीं किया जा सका: {e}")
def crawl(self, url: str) -> dict:
"""reCAPTCHA v2 निपटान के साथ URL क्रॉल करें"""
result = {
'url': url,
'success': False,
'captcha_solved': False
}
try:
print(f"जाएं: {url}")
self.driver.get(url)
time.sleep(2)
# reCAPTCHA का पता लगाएं
site_key = self.detect_recaptcha()
if site_key:
print(f"reCAPTCHA v2 पाया गया! site key: {site_key}")
# CAPTCHA हल करें
token = self.capsolver.solve_recaptcha_v2(url, site_key)
print(f"टोकन प्राप्त: {token[:50]}...")
# टोकन डालें
self.inject_token(token)
result['captcha_solved'] = True
# फॉर्म जमा करें
self.submit_form()
time.sleep(2)
result['success'] = True
result['title'] = self.driver.title
except Exception as e:
result['error'] = str(e)
print(f"त्रुटि: {e}")
return result
def main():
"""मुख्य प्रवेश बिंदु"""
# बैलेंस जांचें
client = CapsolverClient(CAPSOLVER_API_KEY)
print(f"CapSolver बैलेंस: ${client.get_balance():.2f}")
# क्रॉलर बनाएं
crawler = RecaptchaV2Crawler(headless=True)
try:
crawler.start()
# लक्ष्य URL क्रॉल करें (अपने लक्ष्य से बदलें)
result = crawler.crawl("https://example.com/protected-page")
print("\n" + "=" * 50)
print("परिणाम:")
print(json.dumps(result, indent=2))
finally:
crawler.stop()
if __name__ == "__main__":
main()Cloudflare Turnstile हल करें
Cloudflare Turnstile हल करने के लिए पूर्ण Python स्क्रिप्ट:
python
"""
Crawlab + CapSolver: Cloudflare Turnstile सॉल्वर
Turnstile चुनौतियों के लिए पूर्ण स्क्रिप्ट
"""
import os
import time
import json
import requests
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
from selenium.common.exceptions import NoSuchElementException
# कॉन्फ़िगरेशन
CAPSOLVER_API_KEY = os.getenv('CAPSOLVER_API_KEY', 'YOUR_CAPSOLVER_API_KEY')
CAPSOLVER_API = 'https://api.capsolver.com'
class TurnstileSolver:
"""Turnstile के लिए CapSolver क्लाइंट"""
def __init__(self, api_key: str):
self.api_key = api_key
self.session = requests.Session()
def solve(self, website_url: str, site_key: str) -> str:
"""Turnstile CAPTCHA हल करें"""
print(f"{website_url} के लिए Turnstile हल कर रहे हैं")
print(f"site key: {site_key}")
# कार्य बनाएं
task_data = {
"clientKey": self.api_key,
"task": {
"type": "AntiTurnstileTaskProxyLess",
"websiteURL": website_url,
"websiteKey": site_key
}
}
response = self.session.post(f"{CAPSOLVER_API}/createTask", json=task_data)
result = response.json()
if result.get('errorId', 0) != 0:
raise Exception(f"CapSolver त्रुटि: {result.get('errorDescription')}")
task_id = result['taskId']
print(f"कार्य बनाया गया: {task_id}")
# परिणाम के लिए पॉल करें
for i in range(120):
result_data = {
"clientKey": self.api_key,
"taskId": task_id
}
response = self.session.post(f"{CAPSOLVER_API}/getTaskResult", json=result_data)
result = response.json()
if result.get('status') == 'ready':
token = result['solution']['token']
print("Turnstile हल कर दिया गया!")
return token
if result.get('status') == 'failed':
raise Exception("Turnstile हल नहीं हो सका")
time.sleep(1)
raise Exception("समाधान की प्रतीक्षा में समय सीमा समाप्त हो गई")
class TurnstileCrawler:
"""Turnstile समर्थन के साथ Selenium क्रॉलर"""
def __init__(self, headless: bool = True):
self.headless = headless
self.driver = None
self.solver = TurnstileSolver(CAPSOLVER_API_KEY)
def start(self):
"""ब्राउज़र की शुरुआत करें"""
options = Options()
if self.headless:
options.add_argument("--headless=new")
options.add_argument("--no-sandbox")
options.add_argument("--disable-dev-shm-usage")
self.driver = webdriver.Chrome(options=options)
def stop(self):
"""ब्राउज़र बंद करें"""
if self.driver:
self.driver.quit()
def detect_turnstile(self) -> str:
"""Turnstile का पता लगाएं और site key लौटाएं"""
try:
turnstile = self.driver.find_element(By.CLASS_NAME, "cf-turnstile")
return turnstile.get_attribute("data-sitekey")
except NoSuchElementException:
return None
def inject_token(self, token: str):
"""Turnstile टोकन डालें"""
self.driver.execute_script(f"""
var token = '{token}';
// cf-turnstile-response क्षेत्र खोजें
var field = document.querySelector('[name="cf-turnstile-response"]');
if (field) {{
field.value = token;
}}
// सभी Turnstile इनपुट खोजें
var inputs = document.querySelectorAll('input[name*="turnstile"]');
for (var i = 0; i < inputs.length; i++) {{
inputs[i].value = token;
}}
""")
print("टोकन डाल दिया!")
def crawl(self, url: str) -> dict:
"""Turnstile निपटान के साथ URL क्रॉल करें"""
result = {
'url': url,
'success': False,
'captcha_solved': False,
'captcha_type': None
}
try:
print(f"जाएं: {url}")
self.driver.get(url)
time.sleep(3)
# Turnstile का पता लगाएं
site_key = self.detect_turnstile()
if site_key:
result['captcha_type'] = 'turnstile'
print(f"Turnstile पाया गया! site key: {site_key}")
# हल करें
token = self.solver.solve(url, site_key)
# डालें
self.inject_token(token)
result['captcha_solved'] = True
time.sleep(2)
result['success'] = True
result['title'] = self.driver.title
except Exception as e:
print(f"त्रुटि: {e}")
result['error'] = str(e)
return result
def main():
"""मुख्य प्रवेश बिंदु"""
crawler = TurnstileCrawler(headless=True)
try:
crawler.start()
# लक्ष्य (अपने लक्ष्य URL से बदलें)
result = crawler.crawl("https://example.com/turnstile-protected")
print("\n" + "=" * 50)
print("परिणाम:")
print(json.dumps(result, indent=2))
finally:
crawler.stop()
if __name__ == "__main__":
main()Scrapy एकीकरण
CapSolver मिडलवेयर के साथ पूर्ण Scrapy स्पाइडर:
python
"""
Crawlab + CapSolver: Scrapy स्पाइडर
CAPTCHA हल करने वाले मिडलवेयर के साथ पूर्ण Scrapy स्पाइडर
"""
import scrapy
import requests
import time
import os
CAPSOLVER_API_KEY = os.getenv('CAPSOLVER_API_KEY', 'YOUR_CAPSOLVER_API_KEY')
CAPSOLVER_API = 'https://api.capsolver.com'
class CapsolverMiddleware:
"""CAPTCHA हल करने के लिए Scrapy मिडलवेयर"""
def __init__(self):
self.api_key = CAPSOLVER_API_KEY
def solve_recaptcha_v2(self, url: str, site_key: str) -> str:
"""reCAPTCHA v2 हल करें"""कार्य बनाएं
response = requests.post(
f"{CAPSOLVER_API}/createTask",
json={
"clientKey": self.api_key,
"task": {
"type": "ReCaptchaV2TaskProxyLess",
"websiteURL": url,
"websiteKey": site_key
}
}
)
task_id = response.json()['taskId']
# परिणाम के लिए पॉल
for _ in range(120):
result = requests.post(
f"{CAPSOLVER_API}/getTaskResult",
json={"clientKey": self.api_key, "taskId": task_id}
).json()
if result.get('status') == 'ready':
return result['solution']['gRecaptchaResponse']
time.sleep(1)
raise Exception("समय सीमा समाप्त")class CaptchaSpider(scrapy.Spider):
"""कैप्चा निपटान के साथ स्पाइडर"""
name = "captcha_spider"
start_urls = ["https://example.com/protected"]
custom_settings = {
'DOWNLOAD_DELAY': 2,
'CONCURRENT_REQUESTS': 1,
}
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
self.capsolver = CapsolverMiddleware()
def parse(self, response):
# reCAPTCHA की जांच करें
site_key = response.css('.g-recaptcha::attr(data-sitekey)').get()
if site_key:
self.logger.info(f"reCAPTCHA पाया गया: {site_key}")
# कैप्चा हल करें
token = self.capsolver.solve_recaptcha_v2(response.url, site_key)
# टोकन के साथ फॉर्म जमा करें
yield scrapy.FormRequest.from_response(
response,
formdata={'g-recaptcha-response': token},
callback=self.after_captcha
)
else:
yield from self.extract_data(response)
def after_captcha(self, response):
"""कैप्चा के बाद पृष्ठ का प्रसंस्करण"""
yield from self.extract_data(response)
def extract_data(self, response):
"""पृष्ठ से डेटा निकालें"""
yield {
'title': response.css('title::text').get(),
'url': response.url,
}Scrapy सेटिंग्स (settings.py)
"""
BOT_NAME = 'captcha_crawler'
SPIDER_MODULES = ['spiders']
Capsolver
CAPSOLVER_API_KEY = 'YOUR_CAPSOLVER_API_KEY'
दर सीमा
DOWNLOAD_DELAY = 2
CONCURRENT_REQUESTS = 1
ROBOTSTXT_OBEY = True
"""
---
## Node.js/Puppeteer एकीकरण
कैप्चा हल करने के लिए पूर्ण Node.js स्क्रिप्ट:
```javascript
/**
* Crawlab + Capsolver: Puppeteer स्पाइडर
* कैप्चा हल करने के लिए पूर्ण Node.js स्क्रिप्ट
*/
const puppeteer = require('puppeteer');
const CAPSOLVER_API_KEY = process.env.CAPSOLVER_API_KEY || 'YOUR_CAPSOLVER_API_KEY';
const CAPSOLVER_API = 'https://api.capsolver.com';
/**
* Capsolver क्लाइंट
*/
class Capsolver {
constructor(apiKey) {
this.apiKey = apiKey;
}
async createTask(task) {
const response = await fetch(`${CAPSOLVER_API}/createTask`, {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({
clientKey: this.apiKey,
task: task
})
});
const result = await response.json();
if (result.errorId !== 0) {
throw new Error(result.errorDescription);
}
return result.taskId;
}
async getTaskResult(taskId, timeout = 120) {
for (let i = 0; i < timeout; i++) {
const response = await fetch(`${CAPSOLVER_API}/getTaskResult`, {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({
clientKey: this.apiKey,
taskId: taskId
})
});
const result = await response.json();
if (result.status === 'ready') {
return result.solution;
}
if (result.status === 'failed') {
throw new Error('कार्य विफल');
}
await new Promise(r => setTimeout(r, 1000));
}
throw new Error('समय सीमा समाप्त');
}
async solveRecaptchaV2(url, siteKey) {
const taskId = await this.createTask({
type: 'ReCaptchaV2TaskProxyLess',
websiteURL: url,
websiteKey: siteKey
});
const solution = await this.getTaskResult(taskId);
return solution.gRecaptchaResponse;
}
async solveTurnstile(url, siteKey) {
const taskId = await this.createTask({
type: 'AntiTurnstileTaskProxyLess',
websiteURL: url,
websiteKey: siteKey
});
const solution = await this.getTaskResult(taskId);
return solution.token;
}
}
/**
* मुख्य ड्रॉलिंग कार्य
*/
async function crawlWithCaptcha(url) {
const capsolver = new Capsolver(CAPSOLVER_API_KEY);
const browser = await puppeteer.launch({
headless: true,
args: ['--no-sandbox', '--disable-setuid-sandbox']
});
const page = await browser.newPage();
try {
console.log(`ड्रॉलिंग: ${url}`);
await page.goto(url, { waitUntil: 'networkidle2' });
// कैप्चा प्रकार की पहचान करें
const captchaInfo = await page.evaluate(() => {
const recaptcha = document.querySelector('.g-recaptcha');
if (recaptcha) {
return {
type: 'recaptcha',
siteKey: recaptcha.dataset.sitekey
};
}
const turnstile = document.querySelector('.cf-turnstile');
if (turnstile) {
return {
type: 'turnstile',
siteKey: turnstile.dataset.sitekey
};
}
return null;
});
if (captchaInfo) {
console.log(`${captchaInfo.type} पाया गया!`);
let token;
if (captchaInfo.type === 'recaptcha') {
token = await capsolver.solveRecaptchaV2(url, captchaInfo.siteKey);
// टोकन डालें
await page.evaluate((t) => {
const field = document.getElementById('g-recaptcha-response');
if (field) field.value = t;
document.querySelectorAll('textarea[name="g-recaptcha-response"]')
.forEach(el => el.value = t);
}, token);
} else if (captchaInfo.type === 'turnstile') {
token = await capsolver.solveTurnstile(url, captchaInfo.siteKey);
// टोकन डालें
await page.evaluate((t) => {
const field = document.querySelector('[name="cf-turnstile-response"]');
if (field) field.value = t;
}, token);
}
console.log('कैप्चा हल कर दिया गया और डाल दिया गया!');
}
// डेटा निकालें
const data = await page.evaluate(() => ({
title: document.title,
url: window.location.href
}));
return data;
} finally {
await browser.close();
}
}
// मुख्य निष्पादन
const targetUrl = process.argv[2] || 'https://example.com';
crawlWithCaptcha(targetUrl)
.then(result => {
console.log('\nपरिणाम:');
console.log(JSON.stringify(result, null, 2));
})
.catch(console.error);शीर्ष व्यवहार
1. पुन: प्रयास के साथ त्रुटि नियंत्रण
python
def solve_with_retry(solver, url, site_key, max_retries=3):
"""कैप्चा हल करें पुन: प्रयास के साथ"""
for attempt in range(max_retries):
try:
return solver.solve(url, site_key)
except Exception as e:
if attempt == max_retries - 1:
raise
print(f"प्रयास {attempt + 1} विफल: {e}")
time.sleep(2 ** attempt) # एक्स्पोनेंशियल बैकऑफ2. लागत प्रबंधन
- हल करने से पहले पता करें: केवल जब कैप्चा उपलब्ध हो
- टोकन कैश करें: reCAPTCHA टोकन लगभग 2 मिनट के लिए वैध होते हैं
- बैलेंस की निगरानी करें: बैच कार्यों से पहले बैलेंस जांचें
3. दर सीमा
python
# Scrapy सेटिंग्स
DOWNLOAD_DELAY = 3
CONCURRENT_REQUESTS_PER_DOMAIN = 14. पर्यावरण चर
bash
export CAPSOLVER_API_KEY="आपका-एपी-कुंजी-यहां"समस्या निवारण
| त्रुटि | कारण | समाधान |
|---|---|---|
ERROR_ZERO_BALANCE |
क्रेडिट नहीं हैं | CapSolver खाता भरें |
ERROR_CAPTCHA_UNSOLVABLE |
अमान्य पैरामीटर | साइट कुंजी निकालने की पुष्टि करें |
TimeoutError |
नेटवर्क समस्याएं | समय सीमा बढ़ाएं, पुन: प्रयास जोड़ें |
WebDriverException |
ब्राउजर क्रैश | --no-sandbox झंडा जोड़ें |
अक्सर पूछे जाने वाले प्रश्न
प्रश्न: कैप्चा टोकन कितने समय तक वैध रहते हैं?
उत्तर: reCAPTCHA टोकन: लगभग 2 मिनट। Turnstile: साइट पर निर्भर करता है।
प्रश्न: औसत हल समय क्या है?
उत्तर: reCAPTCHA v2: 5-15 सेकंड, Turnstile: 1-10 सेकंड।
प्रश्न: क्या मैं अपना स्वयं का प्रॉक्सी उपयोग कर सकता हूं?
उत्तर: हां, "ProxyLess" शब्द बिना वाले कार्य प्रकार उपयोग करें और प्रॉक्सी कॉन्फ़िग दें।
निष्कर्ष
Crawlab के साथ CapSolver के एकीकरण आपके वितरित ड्रॉलिंग बुनियादी ढांचे में कैप्चा निपटान के लिए एक विश्वसनीय तरीका प्रदान करता है। उपरोक्त पूर्ण स्क्रिप्ट को आपके Crawlab स्पाइडर में सीधे कॉपी किया जा सकता है।
शुरू करने के लिए तैयार हैं? CapSolver में पंजीकरण करें और अपने ड्रॉलर्स को बढ़ाएं!
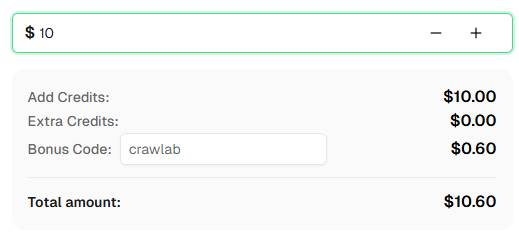
💡 Crawlab एकीकरण उपयोक्ता के लिए विशेष बोनस:
इस एकीकरण के उत्सव के लिए, हम इस ट्यूटोरियल के माध्यम से पंजीकृत CapSolver उपयोक्ताओं के लिए एक विशेष 6% बोनस कोड — Crawlab — प्रदान कर रहे हैं।
बस डैशबोर्ड में भुगतान के समय कोड दर्ज करें ताकि आपको तुरंत अतिरिक्त 6% क्रेडिट प्राप्त हो सके।
13. डॉक्यूमेंटेशन
- 13.1. Crawlab डॉक्यूमेंटेशन
- 13.2. Crawlab GitHub
- 13.3. Capsolver डॉक्यूमेंटेशन
- 13.4. Capsolver API रेफरेंस
और देखें
Web ScrapingApr 22, 2026
रस्ट वेब स्क्रैपिंग आर्किटेक्चर लिए स्केलेबल डेटा निष्कर्षण
Rust में वेब स्क्रैपिंग के स्केलेबल आर्किटेक्चर सीखें, reqwest, scraper, असिंक्रोनस स्क्रैपिंग, हेडलेस ब्राउज़र स्क्रैपिंग, प्रॉक्सी रोटेशन, और संगत CAPTCHA का निपटारा।
Web ScrapingFeb 03, 2026
रॉक्सीब्राउज़र में कैप्चा हल करना कैपसॉल्वर एकीकरण के साथ
CapSolver के साथ RoxyBrowser के एकीकरण करें ताकि ब्राउज़र के कार्यों को स्वचालित किया जा सके और reCAPTCHA, Turnstile और अन्य CAPTCHAs को बायपास किया जा सके।