क्यों AI एजेंट के कार्य CAPTCHA पर फंस जाते हैं और उन्हें कैसे ठीक करें

Rajinder Singh
Deep Learning Researcher
TL;DR
- AI एजेंट कार्य बाधा पर फंस जाते हैं क्योंकि एजेंट एक चुनौती पृष्ठ को सामान्य वेबपेज के रूप में ले लेता है।
- समाधान व्यावहारिक चुनौती निर्धारण, स्थिर ब्राउज़र अवस्था, सीमित पुन: प्रयास और स्पष्ट हस्तांतरण के लिए है।
- CAPTCHA लूप अक्सर अमान्य टोकन, सत्र परिवर्तन, खराब इंतजार ताकत और दोहराए गए असफल उपलब्धि के कारण होते हैं।
- जिम्मेदार स्वचालन को साइट की अनुमतियों, दर सीमाओं, खाता नियमों और डेटा सीमाओं का सम्मान करना चाहिए।
परिचय
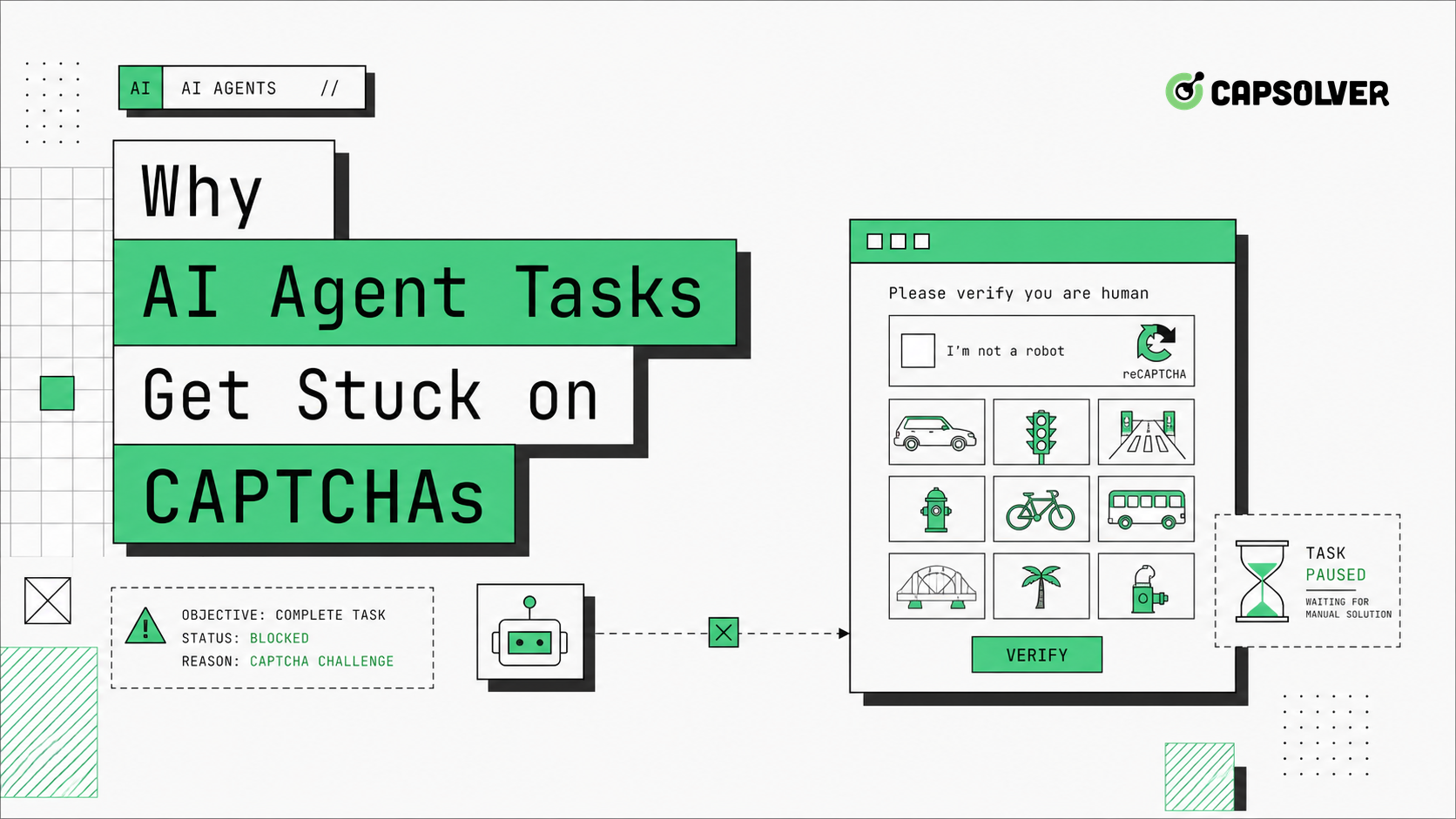
AI एजेंट कार्य तब बाधा पर फंस जाते हैं जब एजेंट के पास चुनौती अवस्था का मॉडल नहीं होता है। यह पृष्ठ को पढ़ता रहता है, एक ही बटन पर क्लिक करता है, अपने आप को रीफ्रेश करता है, या ब्राउज़र टूल को जारी रखने के लिए कहता है। इस व्यवहार के कारण एक लूप बन सकता है और जोखिम संकेत बढ़ सकते हैं। CapSolver आवश्यक CAPTCHA परिणाम के साथ अनुमति प्रक्रिया के लिए उपयोगी है, लेकिन एजेंट को सही निर्धारण, सत्र स्थिरता और रोक की आवश्यकता होती है। सही समाधान CAPTCHA को एजेंट योजना में प्रथम वर्ग की अवस्था के रूप में बनाना है, न कि अप्रत्याशित दृश्य बाधा के रूप में।
एजेंट वास्तविक अवस्था नहीं देख सकता
AI एजेंट कार्य CAPTCHA पर फंस जाते हैं क्योंकि स्क्रीनशॉट और DOM पाठ अक्सर अस्पष्ट होते हैं। एक चुनौती फ्रेम उपयोगी पाठ प्रदान नहीं कर सकता है। reCAPTCHA v3 विफलता केवल पृष्ठभूमि सत्यापन के बाद दिखाई दे सकती है। Cloudflare एक इंतजार पृष्ठ दिखा सकता है जो जावास्क्रिप्ट निष्पादन के बाद बदल जाता है।
आधिकारिक दस्तावेज़ इस अंतर के महत्व को समझाते हैं। गूगल अपने reCAPTCHA प्रदर्शन दस्तावेज़ में स्कोर-आधारित reCAPTCHA v3 का वर्णन करता है, जबकि Cloudflare ब्राउज़र संगतता और चुनौती व्यवहार के लिए अलग-अलग संदर्भ प्रदान करता है। ये अलग-अलग ट्रैफिक सत्यापन प्रवाह हैं, इसलिए एक सामान्य "जारी रखें" नीति विफल रहेगी।
सामान्य लूप कारण
| लूप कारण | जैसा दिखता है | समाधान |
|---|---|---|
| कोई चुनौती डिटेक्टर नहीं | एजेंट CAPTCHA पृष्ठ का सारांश बनाता रहता है | DOM, URL, iframe और स्थिति जांच जोड़ें |
| टोकन बहुत देर से भेजा गया | फॉर्म सबमिट के बाद CAPTCHA फिर से दिखाई देता है | सबमिट के पास हल करें |
| सत्र बदल गया | प्रॉक्सी या ब्राउज़र रीस्टार्ट के बाद टोकन अस्वीकृत कर दिया जाता है | संदर्भ बनाए रखें |
| गलत इंतजार लक्ष्य | पृष्ठ तैयार होने से पहले एजेंट क्लिक करता है | चुनौती के बाद तत्व पर इंतजार करें |
| सीमित पुन: प्रयास नहीं | ब्लॉक अधिक आम हो जाते हैं | रोक की शर्तें जोड़ें |
एजेंट को पहले CAPTCHA क्या हैं का ध्यान रखना चाहिए: ट्रैफिक सत्यापन अवस्थाएं जो सामान्य ब्राउज़िंग के बजाय अलग योजना की आवश्यकता होती है। एक अनुरोध पृष्ठ को Queue-it CAPTCHA पथ की आवश्यकता हो सकती है, जबकि एक विशिष्ट प्रदाता के लिए MTCaptcha कार्यप्रवाह की आवश्यकता हो सकती है। ई-कॉमर्स कार्यों के लिए विशेष सावधानी आवश्यक है क्योंकि ई-कॉमर्स CAPTCHA प्रबंधन भंडार, खरीदारी और खाता नियमों के साथ प्रतिच्छेदन कर सकता है। सार्वजनिक-डेटा एजेंट को पायथन CAPTCHA ब्राउज़िंग गाइड में उपयोग की गई सीमाओं का उपयोग करना चाहिए, विशेष रूप से जब कार्य डेटा एकत्रीकरण में स्पर्श करता है।
CAPTCHA स्थिति मशीन डिज़ाइन करें
AI एजेंट कार्य कम बार CAPTCHA पर फंस जाते हैं जब ब्राउज़र टूल के स्थिति मशीन के बजाय कच्चा पाठ वापस करता है। normal_page, challenge_detected, solving, token_ready, submit_failed, blocked, और needs_human_review जैसे स्थिति का उपयोग करें।
ब्राउज़र कार्यक्रम समय के लिए, एजेंट के लिए एक ही अवधारणा लागू होती है: एक महत्वपूर्ण स्थिति संक्रमण तक प्रतीक्षा करें। एक योजना बनाने वाला पृष्ठ पर कार्य नहीं करना चाहिए जब तक कि ब्राउज़र टूल ने पृष्ठ को सामान्य सामग्री, चुनौती, दर सीमा या कठोर ब्लॉक के रूप में वर्गीकृत नहीं कर दिया है।
CapSolver बोनस कोड के लाभ उठाएं
अपने स्वचालन बजट को तुरंत बढ़ाएं!
CapSolver खाता में अपने खाते को बढ़ाने के दौरान बोनस कोड CAP26 का उपयोग करें ताकि प्रत्येक भरोसे पर 5% बोनस मिले — कोई सीमा नहीं।
अपने CapSolver डैशबोर्ड में अब इसे रीडीम करें

रोक की शर्तें महत्वपूर्ण हैं
AI एजेंट कार्य CAPTCHA पर फंस जाते हैं जब सफलता को बहुत ढीला निर्धारित किया जाता है। "जब तक काम पूरा नहीं हो जाता तब तक जारी रखें" सुरक्षित नहीं है। अधिकतम प्रयास, अधिकतम समय और अंतिम त्रुटि की परिभाषा करें। यदि पृष्ठ कठोर ब्लॉक लौटाता है या वर्कफ़्लो अनुमति नहीं रखता है, तो रोक लें।
संवेदनशील डेटा के लॉग बनाने से बचें। केवल निदान के लिए आवश्यक क्षेत्र रखें: चुनौती प्रकार, URL पैटर्न, पुन: प्रयास संख्या, नेटवर्क रास्ता और उच्च स्तर की त्रुटि। कच्चे टोकन, पासवर्ड या निजी खाता डेटा को स्टोर न करें।
क्यों LLM योजना CAPTCHA लूप को बर्बाद करती है
AI एजेंट कार्य बाधा पर फंस जाते हैं क्योंकि LLM योजक अक्सर कार्य पूरा करने के लिए अनुकूलित करते हैं। यदि निर्देश "लॉग इन करें और रिपोर्ट डाउनलोड करें" है, तो एजेंट प्रत्येक बाधा को अस्थायी यूआई समस्या के रूप में व्याख्या कर सकता है। CAPTCHA अलग है। यह साइट द्वारा डाली गई जोखिम नियंत्रण अवस्था है, और सही कार्रवाई इंतजार करना, अनुमोदित एकीकरण के माध्यम से हल करना, मानव समीक्षा के लिए पूछना या रोक लेना हो सकता है।
इसलिए, ब्राउज़र टूल को प्लानर को असुरक्षित कार्रवाई के लिए अनुमति नहीं देनी चाहिए। "मैं एक चेकबॉक्स देखता हूं" के बजाय, challenge_detected के साथ प्रदाता, विश्वास और अनुमत अगली कार्रवाई लौटाएं। एजेंट अपने आप को नए खाते बनाने, पहचान बदलने या अनुरोध आवृत्ति बढ़ाने का निर्णय नहीं लेना चाहिए। NIST AI जोखिम प्रबंधन ढांचा CAPTCHA मैनुअल नहीं है, लेकिन यह एक उपयोगी नीति संदर्भ है: स्वचालन को मापा, निगरानी करें और सीमित करें।
व्यापक एजेंट कार्य प्रवाह के लिए, सही सवाल केवल एक सॉल्वर के अस्तित्व के बारे में नहीं है, बल्कि यह भी है कि कार्य अनुमत है और क्या ब्राउज़र अवस्था संगत है। AI वेब स्क्रैपिंग और CAPTCHA हल करना कार्य प्रवाह अभी भी क्षेत्र सीमा, पुन: प्रयास सीमा और डेटा सीमा की परिभाषा करे। यदि कार्य सार्वजनिक स्क्रैपिंग है, CAPTCHA के साथ स्क्रैपिंग के 3 तरीके कार्य पुनर्प्राप्ति पथ के लिए जानकारी प्रदान कर सकते हैं, जबकि क्या वेब स्क्रैपिंग है कार्य प्रवाह श्रेणी को स्पष्ट करता है। एक CAPTCHA हल करने वाली सेवा की तुलना करने वाली टीमें विश्वसनीयता, सुसंगतता फिट और एकीकरण स्पष्टता का मूल्यांकन करना चाहिए, न कि केवल हल करने को एक सार्वभौमिक अनुमति परत के रूप में लें।
एक पुनर्प्राप्ति गाइडलाइन जोड़ें
AI एजेंट कार्य CAPTCHA पर कम बार फंस जाते हैं जब प्रत्येक चुनौती के लिए एक पुनर्प्राप्ति गाइडलाइन होती है। गाइडलाइन पांच प्रश्नों का उत्तर देना चाहिए। कौन सा चुनौती प्रकार मौजूद है? कार्य अनुमत है? क्या पर्याप्त चुनौती संदर्भ हल करने के लिए है? क्या ब्राउज़र सत्र स्थिर है? अधिकतम पुन: प्रयास बजट क्या है? यदि कोई उत्तर अज्ञात है, तो एजेंट रुक जाए और निदान लौटाए।
दृश्य चित्र CAPTCHA के लिए, गाइडलाइन सॉल्वर या मानव समीक्षा के लिए मार्गदर्शन कर सकती है। reCAPTCHA v3 के लिए, यह कार्य नाम और टोकन ताजगी की जांच करे। Cloudflare Turnstile के लिए, यह विज्ञापन पैरामीटर और ब्राउज़र अवस्था के बीच संगतता बनाए रखे। कठोर 403 पृष्ठ के लिए, रोक दें। दर सीमा पृष्ठ के लिए, धीमा करें या पुन: योजना बनाएं। इस वर्गीकरण एजेंट को हर सुरक्षा तकनीक के लिए एक ही व्यवहार लागू करने से रोकता है।
ब्राउज़र टूल को अवस्था के बजाय स्क्रीनशॉट के लिए डिज़ाइन करें
स्क्रीनशॉट मानव डीबगिंग के लिए उपयोगी हैं, लेकिन एजेंट के लिए एक कमजोर प्राथमिक इंटरफ़ेस हैं। AI एजेंट कार्य CAPTCHA पर फंस जाते हैं क्योंकि प्लानर छवि देखता है लेकिन नीचे की अवस्था नहीं। एक बेहतर ब्राउज़र टूल एक स्क्रीनशॉट और संरचित संकेत दोनों लौटाता है: URL, शीर्षक, जब उपलब्ध हो, स्थिति कोड, iframe डोमेन, दृश्य प्रदाता स्ट्रिंग, फॉर्म अवस्था और हाल के नेविगेशन घटनाएं।
Playwright के लोकेटर गाइडेंस उपयोगी पैटर्न है क्योंकि यह टूटने वाले निर्देशांक के बजाय महत्वपूर्ण तत्वों का चयन करने के लिए प्रोत्साहित करता है। LangChain के LangGraph प्लेटफॉर्म दस्तावेज़ भी एजेंट प्रणालियों के निर्माण में स्पष्ट कार्य प्रवाह अवस्था के महत्व को दर्शाता है। एक ही डिज़ाइन सिद्धांत यहां लागू होता है: CAPTCHA प्रबंधन को एक अवस्था संक्रमण के रूप में मॉडल करें, न कि एक स्क्रीनशॉट पहेली के रूप में।
एजेंट नीति में सुसंगतता डालें
नीति स्तर निश्चित होना चाहिए। AI एजेंट कार्य निर्दोष प्रवाह में CAPTCHA पर फंस जाते हैं, जैसे कि QA, सार्वजनिक मॉनिटरिंग और आंतरिक प्रशासन स्वचालन। वे विशेष रूप से विशेष प्रवाह में भी दिखाई देते हैं जो आगे नहीं बढ़ना चाहिए। एजेंट को दोनों के लिए नियम होने चाहिए। यह तब रोक लेना चाहिए जब कार्य अनुमति विहीन पहुंच, निजी डेटा, पासवर्ड दुरुपयोग, स्पैम, खरीदारी दुरुपयोग या अनुमति से बाहर कार्रवाई के लिए कहता है।
कार्य संदर्भ में एक छोटी नीति वस्तु जोड़ें: अनुमत डोमेन, अनुमत खाते, दर सीमाएं, डेटा श्रेणियां और उत्कृष्टता पथ। ब्राउज़र टूल फिर से चुनौती के साथ सुरक्षित निर्णय ले सकता है। यदि लक्ष्य डोमेन अनुमत नहीं है, तो हल करने से पहले नीति त्रुटि लौटाएं। यदि प्रवाह अनुमत है लेकिन उच्च जोखिम है, तो एक विफल प्रयास के बाद मानव अनुमोदन की आवश्यकता होती है।
लूप दर को उत्पाद निर्देशक के रूप में मापें
CAPTCHA लूप को विश्वसनीयता निर्देशक के रूप में लें। ट्रैक करें कि कितने कार्य challenge_detected में प्रवेश करते हैं, कितने बरामद होते हैं, कितने नीति के कारण रुक जाते हैं और कितने एक ही चुनौती को दोहराते हैं। उच्च लूप दर कम ब्राउज़र अवस्था, खराब प्रॉक्सी गुणवत्ता, अस्पष्ट एजेंट निर्देश या अनुपलब्ध डिटेक्टर कवरेज के कारण हो सकती है। इन मूल कारणों को ठीक करने से कार्य पूरा करने में सुधार होता है और अनावश्यक ट्रैफिक कम होता है।
सबसे अच्छा AI एजेंट CAPTCHA प्रबंधन बोरिंग है: पहचानें, निर्णय लें, एक बार कार्रवाई करें और ब्लॉक होने पर साफ रूप से रुक जाएं। लक्ष्य एजेंट को अधिक आत्मविश्वास बनाना नहीं है। लक्ष्य एजेंट को अधिक सटीक और जिम्मेदार बनाना है।
प्रॉम्प्ट और टूल विवरण की समीक्षा करें
AI एजेंट कार्य CAPTCHA पर फंस जाते हैं जब प्रॉम्प्ट ब्राउज़र टूल को एक भी वेबसाइट कार्य पूरा कर सकता है जैसा लगता है। टूल विवरण को बदलें ताकि वे सुरक्षित पृष्ठ पर क्या होता है वह बताएं। उदाहरण के लिए, ब्राउज़र टूल सार्वजनिक पृष्ठ ब्राउज़ कर सकता है, अनुमत फॉर्म भर सकता है और चुनौती अवस्था रिपोर्ट कर सकता है। यह ट्रैफिक सत्यापन में पहुंच की गारंटी नहीं दे सकता, नए पहचान बना सकता है या कठोर अस्वीकृति के बाद जारी रख सकता है। स्पष्ट टूल विवरण एजेंट के लिए CAPTCHA को छोटे यूआई तत्व के रूप में लेने की संभावना कम करते हैं।
कार्य प्रॉम्प्ट भी स्वीकृत परिणाम की परिभाषा करना चाहिए। "अनुमत खाता द्वारा इसकी अनुमति होने पर रिपोर्ट डाउनलोड करें" एक सुरक्षित विकल्प है, जबकि "कुछ भी हो, रिपोर्ट डाउनलोड करें" नहीं है। "प्रति पृष्ठ अधिकतम एक अनुरोध के साथ सार्वजनिक मूल्य एकत्र करें" एक सुरक्षित विकल्प है, जबकि "पूरे साइट को स्क्रैप करें" नहीं है। इन छोटे प्रॉम्प्ट अंतर एजेंट के लिए चुनौती मिलने पर अपने प्रतिक्रिया को बनाते हैं। लक्ष्य केवल सफल पूर्णता नहीं है; यह अनुमत सीमा के भीतर सफल पूर्णता है।
जहां वास्तविक रूप से मदद करता है वहां मानव समीक्षा जोड़ें
मानव समीक्षा को एक अस्पष्ट भाग के रूप में नहीं छोड़ें। विशिष्ट निर्णयों के लिए इसका उपयोग करें: प्राधिकरण की पुष्टि करना, नीति की अनुमति होने पर चुनौती पूरा करना, दर सीमा के बाद पुन: प्रयास के लिए मानव अनुमोदन मांगना या यह निर्णय लेना कि कार्य रुक जाए। एजेंट को समीक्षक के पास एक संक्षिप्त पैकेट भेजे: लक्ष्य डोमेन, कार्य उद्देश्य, चुनौती प्रकार, पुन: प्रयास संख्या और अनुमति होने पर सैनिटाइज्ड स्क्रीनशॉट। यह ब्राउज़र टूल रोक नहीं करता है, टोकन या निजी पृष्ठ डेटा।
यह समीक्षा पथ नए डोमेन के लिए विशेष रूप से उपयोगी है। जब टीम को साइट के नियमों और अनुमत स्वचालन पैटर्न के बारे में समझ हो जाती है, तो वर्कफ़्लो को नीति में कोड कर सकते हैं। इसके बाद तक, एक मानव बिंदु एजेंट को दोहराए गए विफलताओं के माध्यम से गलत व्यवहार सीखने से रोकता है।
निष्कर्ष
AI एजेंट कार्य CAPTCHA पर फंस जाते हैं क्योंकि स्वचालन स्टैक में चुनौती जागरूकता की कमी है। निर्धारण, अवस्था संक्रमण, स्थिर सत्र, सीमित पुन: प्रयास और जिम्मेदार रोक शर्तें जोड़ें। अनुमति प्रवाह में जब एक सॉल्वर उपयुक्त है, CapSolver एजेंट के संदर्भ और सुसंगतता के प्रबंधन के साथ CAPTCHA-प्रबंधन चरण प्रदान कर सकता है।
एफक्यूएआई
मेरा AI एजेंट CAPTCHA पृष्ठ को क्यों बार-बार रीफ्रेश करता है?
एजेंट के पास शायद पृष्ठ को अंतिम या विशेष चुनौती अवस्था के रूप में नहीं पहचान है। विशिष्ट चुनौती निर्धारण और पुन: प्रयास सीमा जोड़ें।
क्या एलएलएम अकेले दृश्य CAPTCHA हल कर सकता है?
इसे एक विश्वसनीय या सुसंगत डिफॉल्ट के रूप में नहीं माना जाना चाहिए। जब कार्य अनुमति होती है, तो अनुमोदित प्रक्रिया, मानव समीक्षा या एक विशेष सेवा का उपयोग करें।
CAPTCHA लूप के निदान के लिए कौन से लॉग मदद करते हैं?
लॉग चुनौती प्रकार, URL, पुन: प्रयास संख्या, ब्राउज़र संदर्भ पहचानकर्ता, प्रॉक्सी क्षेत्र और अंतिम त्रुटि। गोपनीयता और निजी डेटा से बचें।
एजेंट कब रुक जाए?
सीमित पुन: प्रयास के बाद, कठोर 403 प्रतिक्रिया, अनुमति न होने, दोहराए गए टोकन अस्वीकृति या किसी भी सुरक्षित डेटा सीमा के बाद रुक जाए।
और देखें
AIJul 31, 2026
ल्लामा इंडेक्स एजेंट्स में कैप्चा कैसे हल करें
LlamaIndex एजेंट्स में CAPTCHA हल करना एम्बेड करें FunctionTool और CapSolver का उपयोग करके वेब डेटा इनपुट पाइपलाइन के लिए।
AIJul 31, 2026
CAPTCHA कैसे हल करें: CapSolver मॉडल संदर्भ प्रोटोकॉल सेवा
कैपसॉल्वर MCP सेवा को क्लॉड डेस्कटॉप, कर्सर और किसी भी MCP क्लाइंट में शून्य-कोड CAPTCHA हल करने के लिए सेट करें।