वेब स्क्रैपिंग सेलीनियम और पायथन के साथ | वेब स्क्रैपिंग के दौरान कैप्चा हल करना

Nikolai Smirnov
Software Development Lead
कल्पना कीजिए कि आप इंटरनेट से आवश्यक डेटा आसानी से प्राप्त कर सकते हैं बिना वेब को हाथ से ब्राउज़ किए या कॉपी-पेस्ट किए। यह वेब स्क्रैपिंग की सुंदरता है। आप डेटा विश्लेषक, बाजार अनुसंधानकर्ता या विकासकर्ता हों या न हों, वेब स्क्रैपिंग आपके लिए स्वचालित डेटा संग्रह की एक पूरी नई दुनिया खोलती है।
इस डेटा-आधारित युग में, जानकारी शक्ति है। हालांकि, सैकड़ों या भले ही हजारों वेब पृष्ठों से जानकारी को हाथ से निकालना न केवल समय लेने वाला है, बल्कि त्रुटि-प्रवण भी है। खुशकिस्मती से, वेब स्क्रैपिंग एक कुशल और सटीक समाधान प्रदान करता है जो आपको इंटरनेट से आवश्यक डेटा के संग्रह की प्रक्रिया को स्वचालित करने की अनुमति देता है, इस प्रकार दक्षता और डेटा गुणवत्ता को बहुत अधिक बढ़ाता है।
सामग्री की सूची
वेब स्क्रैपिंग क्या है?
वेब स्क्रैपिंग वेब पृष्ठों से जानकारी के स्वचालित निकालने की एक तकनीक है जो कार्यक्रम लिखकर किया जाता है। इस तकनीक के बहुत सारे अनुप्रयोग हैं, जैसे डेटा विश्लेषण, बाजार अनुसंधान, प्रतियोगी जानकारी, सामग्री संग्रह आदि। वेब स्क्रैपिंग के साथ, आप एक छोटे समय में बड़ी संख्या में वेब पृष्ठों से डेटा एकत्र कर सकते हैं, बजाय हाथ से ऑपरेशन पर निर्भर करने के।
वेब स्क्रैपिंग की प्रक्रिया आमतौर पर निम्नलिखित चरणों को शामिल करती है:
- HTTP मांग भेजें: लक्षित वेबसाइट पर प्रोग्रामेटिक रूप से मांग भेजें ताकि वेब पृष्ठ के HTML स्रोत को प्राप्त किया जा सके। सामान्य रूप से उपयोग किए जाने वाले उपकरणों में पायथन की requests पुस्तकालय शामिल है जो इसे आसानी से कर सकती है।
- HTML सामग्री का विश्लेषण करें: HTML स्रोत को प्राप्त करने के बाद, आवश्यक डेटा निकालने के लिए इसका विश्लेषण करना आवश्यक है। HTML विश्लेषण पुस्तकालय जैसे BeautifulSoup या lxml का उपयोग किया जा सकता है जो HTML संरचना को संसाधित करता है।
- डेटा निकालें: पार्स किए गए HTML संरचना के आधार पर, विशिष्ट सामग्री की स्थिति निर्धारित करें और निकालें, जैसे लेख का शीर्षक, मूल्य जानकारी, चित्र लिंक आदि। सामान्य विधियां एक्सप्रेशन या CSS सेलेक्टर का उपयोग करना शामिल हैं।
- डेटा संग्रहित करें: निकाले गए डेटा को उपयुक्त संग्रह माध्यम, जैसे डेटाबेस, CSV फ़ाइल या JSON फ़ाइल में संग्रहित करें, जिसके बाद विश्लेषण और प्रसंस्करण के लिए उपयोग किया जा सकता है।
और जिसके साथ सेलेनियम का उपयोग करके उपयोगकर्ता के ब्राउज़र के संचालन का अनुकरण किया जा सकता है, जिससे कुछ एंटी-क्रैलर युक्तियों को पार किया जा सकता है, इस प्रकार वेब स्क्रैपिंग कार्य को अधिक कुशलता से पूरा किया जा सकता है।
CapSolver बोनस कोड के लाभ उठाएं
अपने स्वचालन बजट को तत्काल बढ़ाएं!
CapSolver खाता भरने के दौरान बोनस कोड CAPN का उपयोग करके प्रत्येक भरोसे में 5% बोनस प्राप्त करें - कोई सीमा नहीं।
अपने CapSolver डैशबोर्ड में अब इसे रीडीम करें
.
Selenium के साथ शुरू करें
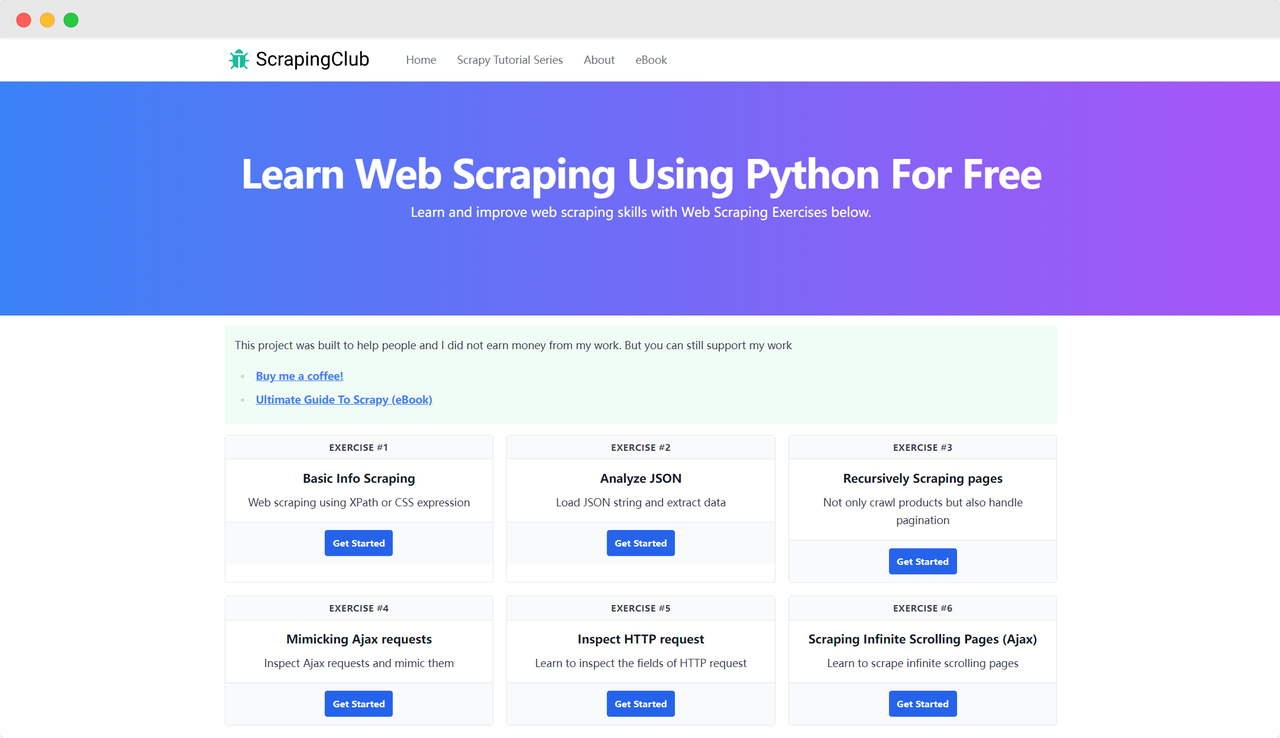
हम एक उदाहरण के रूप में ScrapingClub का उपयोग करेंगे और Selenium के साथ अभ्यास एक पूरा करेंगे।
तैयारी
सबसे पहले, आपको अपने स्थानीय मशीन पर पायथन स्थापित होना आवश्यक है। आप अपने टर्मिनल में निम्न आदेश द्वारा पायथन संस्करण की जांच कर सकते हैं:
bash
python --versionपायथन संस्करण 3 से अधिक होना आवश्यक है। यदि यह स्थापित नहीं है या संस्करण बहुत कम है, तो कृपया पायथन आधिकारिक वेबसाइट से नवीनतम संस्करण डाउनलोड करें। अब, निम्न आदेश का उपयोग करके selenium पुस्तकालय स्थापित करें:
bash
pip install seleniumपुस्तकालय आयात करें
python
from selenium import webdriverएक पृष्ठ तक पहुंचें
Google Chrome के साथ Selenium का उपयोग करके किसी पृष्ठ तक पहुंचना आसान है। जब आप Chrome Options ऑब्जेक्ट के अंतःक्रिया को प्रारंभ करते हैं, तो आप get() विधि का उपयोग करके लक्षित पृष्ठ तक पहुंच सकते हैं:
python
import time
from selenium import webdriver
chrome_options = webdriver.ChromeOptions()
driver = webdriver.Chrome(options=chrome_options)
driver.get('https://scrapingclub.com/')
time.sleep(5)
driver.quit()स्टार्टअप पैरामीटर
Chrome Options में बहुत सारे स्टार्टअप पैरामीटर जोड़े जा सकते हैं जो डेटा प्राप्ति की दक्षता में सुधार करते हैं। आप आधिकारिक वेबसाइट पर पूरी सूची देख सकते हैं: Chromium कमांड लाइन स्विचेस की सूची. नीचे दिए गए तालिका में कुछ सामान्य रूप से उपयोग किए जाने वाले पैरामीटर शामिल हैं:
| पैरामीटर | उद्देश्य |
|---|---|
| --user-agent="" | मांग प्रतिक्रिया में User-Agent सेट करें |
| --window-size=xxx,xxx | ब्राउज़र रिज़ॉल्यूशन सेट करें |
| --start-maximized | अधिकतम रिज़ॉल्यूशन के साथ चलाएं |
| --headless | हेडलेस मोड में चलाएं |
| --incognito | अंधविश्वास मोड में चलाएं |
| --disable-gpu | GPU हार्डवेयर त्वरण अक्षम करें |
उदाहरण: हेडलेस मोड में चलाएं
python
import time
from selenium import webdriver
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--headless')
driver = webdriver.Chrome(options=chrome_options)
driver.get('https://scrapingclub.com/')
time.sleep(5)
driver.quit()पृष्ठ तत्वों की स्थिति ज्ञात करें
डेटा स्क्रैपिंग में आवश्यक चरण डीओएम में संबंधित HTML तत्वों की स्थिति ज्ञात करना है। Selenium पृष्ठ पर तत्वों की स्थिति ज्ञात करने के लिए दो मुख्य विधियां प्रदान करता है:
find_element: मानदंड को पूरा करने वाला एक तत्व खोजें।find_elements: मानदंड को पूरा करने वाले सभी तत्व खोजें।
दोनों विधियां HTML तत्वों की स्थिति ज्ञात करने के आठ अलग-अलग तरीकों का समर्थन करती हैं:
| विधि | अर्थ | HTML उदाहरण | Selenium उदाहरण |
|---|---|---|---|
| By.ID | तत्व ID द्वारा स्थिति ज्ञात करें | <form id="loginForm">...</form> |
driver.find_element(By.ID, 'loginForm') |
| By.NAME | तत्व नाम द्वारा स्थिति ज्ञात करें | <input name="username" type="text" /> |
driver.find_element(By.NAME, 'username') |
| By.XPATH | XPath द्वारा स्थिति ज्ञात करें | <p><code>My code</code></p> |
driver.find_element(By.XPATH, "//p/code") |
| By.LINK_TEXT | लिंक टेक्स्ट द्वारा हाइपरलिंक स्थिति ज्ञात करें | <a href="continue.html">Continue</a> |
driver.find_element(By.LINK_TEXT, 'Continue') |
| By.PARTIAL_LINK_TEXT | आंशिक टेक्स्ट द्वारा हाइपरलिंक स्थिति ज्ञात करें | <a href="continue.html">Continue</a> |
driver.find_element(By.PARTIAL_LINK_TEXT, 'Conti') |
| By.TAG_NAME | टैग नाम द्वारा स्थिति ज्ञात करें | <h1>Welcome</h1> |
driver.find_element(By.TAG_NAME, 'h1') |
| By.CLASS_NAME | वर्ग नाम द्वारा स्थिति ज्ञात करें | <p class="content">Welcome</p> |
driver.find_element(By.CLASS_NAME, 'content') |
| By.CSS_SELECTOR | CSS सेलेक्टर द्वारा स्थिति ज्ञात करें | <p class="content">Welcome</p> |
driver.find_element(By.CSS_SELECTOR, 'p.content') |
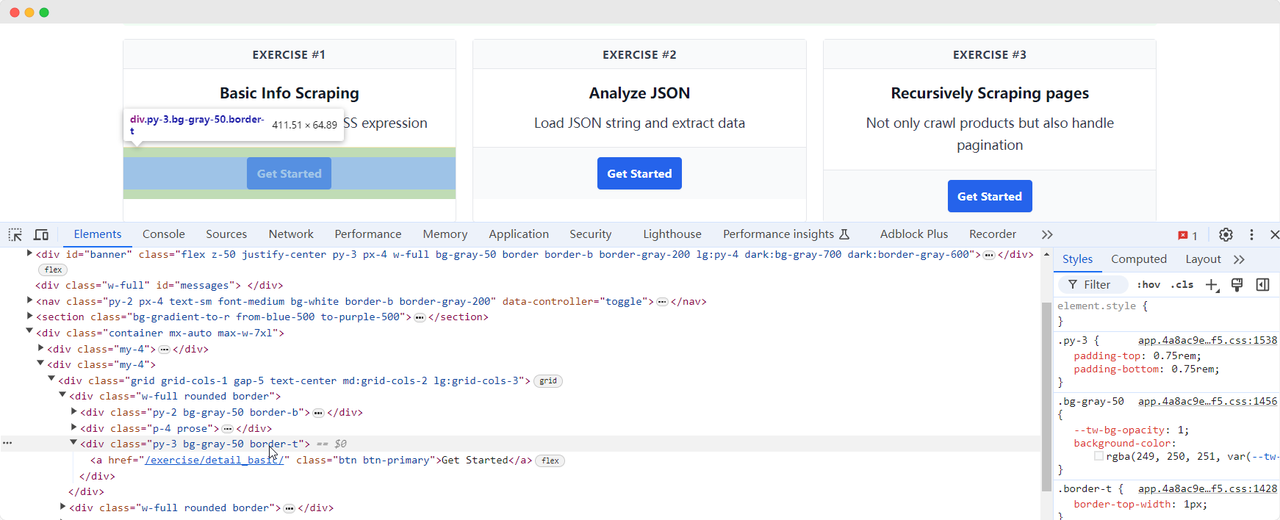
हम ScrapingClub पृष्ठ पर वापस आते हैं और अभ्यास एक के लिए "Get Started" बटन तत्व को खोजने के लिए निम्न कोड लिखते हैं:
python
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
chrome_options = webdriver.ChromeOptions()
driver = webdriver.Chrome(options=chrome_options)
driver.get('https://scrapingclub.com/')
get_started_button = driver.find_element(By.XPATH, "//div[@class='w-full rounded border'][1]/div[3]")
time.sleep(5)
driver.quit()तत्व अंतःक्रिया
जब हम "Get Started" बटन तत्व पाते हैं, तो हम अगले पृष्ठ में प्रवेश करने के लिए बटन पर क्लिक करने की आवश्यकता होती है। इसमें तत्व अंतःक्रिया शामिल है। Selenium कई विधियां प्रदान करता है जो कार्यवाही के अनुकरण करती हैं:
click(): तत्व पर क्लिक करें;clear(): तत्व की सामग्री साफ करें;send_keys(*value: str): कीबोर्ड इनपुट के अनुकरण करें;submit(): एक फॉर्म जमा करें;screenshot(filename): पृष्ठ की एक प्रतिलिपि संग्रहित करें।
अधिक अंतःक्रियाओं के लिए आधिकारिक डॉक्यूमेंटेशन देखें: WebDriver API. हम ScrapingClub अभ्यास कोड को बेहतर बनाने के लिए क्लिक अंतःक्रिया जोड़ते हैं:
python
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
chrome_options = webdriver.ChromeOptions()
driver = webdriver.Chrome(options=chrome_options)
driver.get('https://scrapingclub.com/')
get_started_button = driver.find_element(By.XPATH, "//div[@class='w-full rounded border'][1]/div[3]")
get_started_button.click()
time.sleep(5)
driver.quit()डेटा निकालें
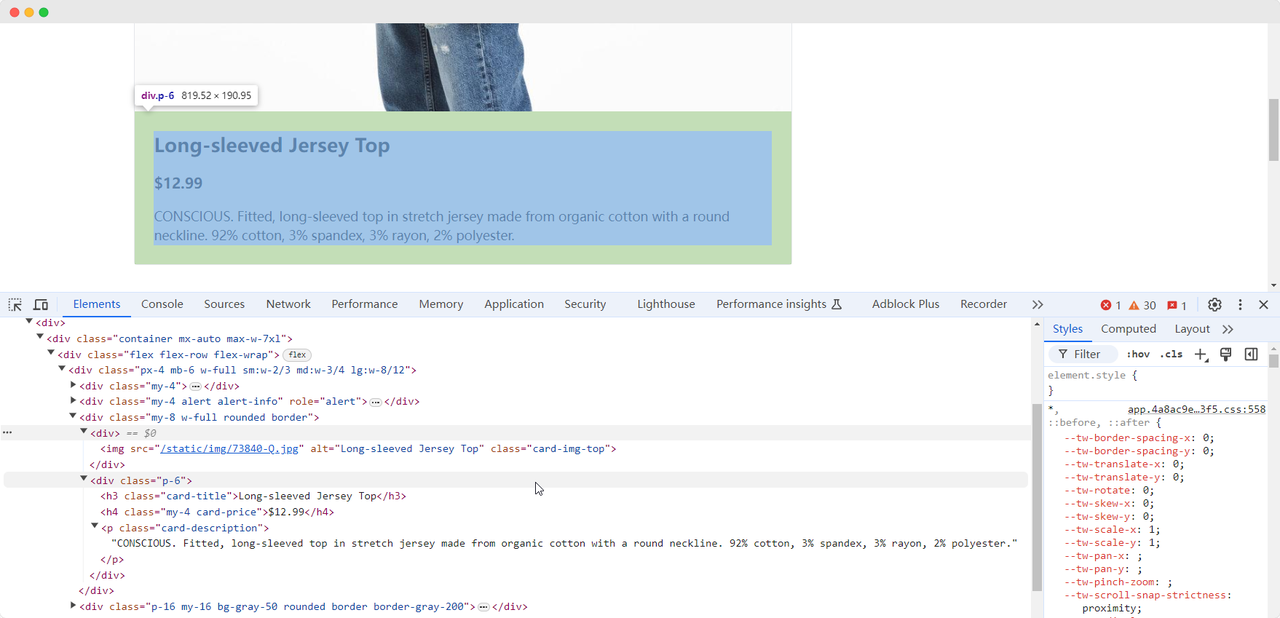
जब हम पहले अभ्यास पृष्ठ पर पहुंचते हैं, तो हम उत्पाद के चित्र, नाम, मूल्य और विवरण की जानकारी एकत्र करने की आवश्यकता होती है। हम विभिन्न विधियों का उपयोग करके इन तत्वों की स्थिति ज्ञात कर सकते हैं और उन्हें निकाल सकते हैं:
python
from selenium import webdriver
from selenium.webdriver.common.by import By
chrome_options = webdriver.ChromeOptions()
driver = webdriver.Chrome(options=chrome_options)
driver.get('https://scrapingclub.com/')
get_started_button = driver.find_element(By.XPATH, "//div[@class='w-full rounded border'][1]/div[3]")
get_started_button.click()
product_name = driver.find_element(By.CLASS_NAME, 'card-title').text
product_image = driver.find_element(By.CSS_SELECTOR, '.card-img-top').get_attribute('src')
product_price = driver.find_element(By.XPATH, '//h4').text
product_description = driver.find_element(By.CSS_SELECTOR, '.card-description').text
print(f'Product name: {product_name}')
print(f'Product image: {product_image}')
print(f'Product price: {product_price}')
print(f'Product description: {product_description}')
driver.quit()कोड निम्न सामग्री का आउटपुट देगा:
Product name: Long-sleeved Jersey Top
Product image: https://scrapingclub.com/static/img/73840-Q.jpg
Product price: $12.99
Product description: CONSCIOUS. Fitted, long-sleeved top in stretch jersey made from organic cotton with a round neckline. 92% cotton, 3% spandex, 3% rayon, 2% polyester.तत्वों के लोड होने के लिए प्रतीक्षा करें
कभी-कभी, नेटवर्क समस्याओं या अन्य कारणों के कारण, Selenium चलाने के बाद तत्व अभी तक लोड नहीं हो सकते हैं, जिसके कारण कुछ डेटा एकत्र करना विफल हो सकता है। इस समस्या को हल करने के लिए, हम एक निश्चित तत्व पूरी तरह से लोड होने तक प्रतीक्षा करने की व्यवस्था कर सकते हैं। यहां एक उदाहरण कोड है:
python
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
chrome_options = webdriver.ChromeOptions()
driver = webdriver.Chrome(options=chrome_options)
driver.get('https://scrapingclub.com/')
get_started_button = driver.find_element(By.XPATH, "//div[@class='w-full rounded border'][1]/div[3]")
get_started_button.click()
# प्रोडक्ट इमेज तत्वों के पूरी तरह से लोड होने के लिए प्रतीक्षा करें
wait = WebDriverWait(driver, 10)
wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '.card-img-top')))
product_name = driver.find_element(By.CLASS_NAME, 'card-title').text
product_image = driver.find_element(By.CSS_SELECTOR, '.card-img-top').get_attribute('src')
product_price = driver.find_element(By.XPATH, '//h4').text
product_description = driver.find_element(By.CSS_SELECTOR, '.card-description').text
print(f'Product name: {product_name}')
print(f'Product image: {product_image}')
print(f'Product price: {product_price}')
print(f'Product description: {product_description}')
driver.quit()एंटी-स्क्रैपिंग सुरक्षाओं से बचें
ScrapingClub अभ्यास आसानी से पूरा किया जा सकता है। हालांकि, वास्तविक डेटा एकत्र करने की स्थिति में, डेटा प्राप्त करना इतना आसान नहीं होता क्योंकि कुछ वेबसाइटें एंटी-स्क्रैपिंग तकनीकों का उपयोग करती हैं जो आपके स्क्रिप्ट को बॉट के रूप में पहचान सकती हैं और संग्रह को ब्लॉक कर सकती हैं। सबसे आम स्थिति CAPTCHA चुनौतियां हैं
इन CAPTCHA चुनौतियों को हल करने के लिए मशीन लर्निंग, रिवर्स इंजीनियरिंग और ब्राउज़र फिंगरप्रिंट विरोधी उपायों में विस्तृत अनुभव की आवश्यकता होती है, जो काफी समय ले सकता है। खुशकिस्मती से, अब आपको इस सभी कार्य को खुद नहीं करना पड़ता। CapSolver आपके लिए एक पूर्ण समाधान प्रदान करता है जो आपको सभी चुनौतियों को आसानी से पार करने में मदद करता है। CapSolver सेलेनियम के साथ डेटा एकत्र करते समय CAPTCHA चुनौतियों को स्वचालित रूप से हल करने वाले ब्राउज़र एक्सटेंशन प्रदान करता है। इसके अलावा, वे CAPTCHA को हल करने और टोकन प्राप्त करने के लिए API विधियां प्रदान करते हैं, जो केवल कुछ सेकंड में पूरा किया जा सकता है। अधिक जानकारी के लिए CapSolver डॉक्यूमेंटेशन देखें।
निष्कर्ष
उत्पाद विवरण के निकालने से लेकर जटिल एंटी-स्क्रैपिंग उपायों के माध्यम से नेविगेट करने तक, Selenium के साथ वेब स्क्रैपिंग एक विशाल क्षेत्र में स्वचालित डेटा संग्रह के द्वार खोलता है। जैसे-जैसे हम वेब के बदलते हुए वातावरण में नेविगेट करते हैं, CapSolver जैसे उपकरण डेटा निकालने में आसानी प्रदान करते हैं, जो अब तक की बाधाओं को पीछे छोड़ देते हैं। इसलिए, चाहे आप डेटा प्रेमी हों या अनुभवी विकासकर्ता हों, इन तकनीकों का उपयोग करके आप दक्षता को बढ़ाते हैं और एक ऐसी दुनिया में पहुंचते हैं जहां डेटा-आधारित अंतर्दृष्टि एक स्क्रैप के दूर है
अक्सर पूछे जाने वाले प्रश्न
1. वेब स्क्रैपिंग का उपयोग किसलिए किया जाता है?
वेब स्क्रैपिंग वेब पृष्ठों से सूचना को स्वचालित रूप से निकालने के लिए उपयोग किया जाता है। यह विकासकर्ता, विश्लेषक और व्यवसायों को हाथ से कॉपी किए बिना बड़ी मात्रा में उत्पाद डेटा, कीमतें, लेख, चित्र, समीक्षाएं आदि ऑनलाइन सूचना एकत्र करने में सक्षम बनाता है, जो काफी अधिक दक्षता और डेटा सटीकता में सुधार करता है।
2. सेलीनियम का उपयोग वेब स्क्रैपिंग के लिए अन्य अनुप्रयोगों जैसे requests या BeautifulSoup के बजाय क्यों करें?
requests और BeautifulSoup स्थैतिक वेब पृष्ठों के लिए अच्छा काम करते हैं, लेकिन बहुत सारे आधुनिक वेबसाइट जावास्क्रिप्ट का उपयोग करके सामग्री लोड करते हैं। सेलीनियम एक वास्तविक ब्राउजर के समान व्यवहार करता है, जिससे आप डायनामिक पृष्ठों, बटनों पर क्लिक करने, स्क्रॉल करने, तत्वों के साथ अंतःक्रिया करने और सरल स्क्रैपिंग विरोधी उपायों को बर्दाश्त कर सकते हैं—जो जटिल परिस्थितियों के लिए आदर्श है।
3. क्या सेलीनियम लॉगिन या उपयोगकर्ता क्रियाकलापों के पीछे वेबसाइटों को छान सकता है?
हां। सेलीनियम बटनों पर क्लिक करने, टेक्स्ट टाइप करने, पृष्ठों को नेविगेट करने और कुकीज या सत्र का प्रबंधन करने जैसे अंतःक्रियाओं को कर सकता है, जो लॉगिन फॉर्म या उपयोगकर्ता प्रवाह के पीछे पृष्ठों के लिए उपयुक्त बनाता है।
4. डेटा स्क्रैपिंग के दौरान CAPTCHA के साथ कैसे निपटें?
CAPTCHA एक सामान्य बॉट विरोधी उपाय है जो सेलीनियम स्क्रिप्ट को रोक सकता है। बजाय इसके कि आप इन्हें हाथ से हल करें, आप CapSolver जैसे समाधानों के साथ एकीकृत कर सकते हैं, जो API या ब्राउजर एक्सटेंशन के माध्यम से स्वचालित रूप से CAPTCHA हल करता है, ताकि स्क्रैपिंग प्रक्रिया अस्थायी रूप से बाधित न हो।
और देखें
The Other CAPTCHANov 15, 2023
कैप्चा कैसे काम करता है?
CAPTCHA के जटिल कार्यक्रमों का अन्वेषण करें: मनुष्य-बॉट अंतर, कृत्रिम बुद्धिमता प्रशिक्षण की भूमिकाएं, reCAPTCHA तकनीक, सुरक्षा और कृत्रिम बुद्धिमता के विकास के मिश्रण को खोलकर दिखाना

The Other CAPTCHAJun 29, 2023
किसी भी कैपचा को कैपचा सॉल्वर सेवा का उपयोग करके हल करें - कैपसॉल्वर
कैपसॉल्वर की खोज करें: एक एआई-आधारित सेवा जो किसी भी कैपचा को आसानी से हल करे, reCAPTCHA से hCaptcha तक, लचीली कीमतों और विश्वसनीय प्रदर्शन के साथ

