C# एक व्यावहारिक प्रोग्रामिंग भाषा है जिसका उपयोग एंटरप्राइज स्तर के परियोजनाओं और एप्लिकेशन में व्यापक रूप से किया जाता है। इसकी जड़ें C परिवार में हैं, जो दक्षता और शक्ति के साथ आती हैं, जो किसी भी डेवलपर के टूलकिट के लिए अमूल्य योगदान है।
इसके व्यापक उपयोग के कारण, C# डेवलपर्स के लिए जटिल समाधान हल करने के लिए एक बहुत बड़ा संसाधन प्रदान करता है, और वेब स्क्रैपिंग इसके अपवाद नहीं है।
इस ट्यूटोरियल में, हम C# और इसके उपयोगकर्ता-मित्र स्क्रैपिंग पुस्तकालय के साथ एक सीधा वेब स्क्रैपर बनाने के लिए आपको चरण-दर-चरण निर्देश देंगे। इसके अलावा, हम एक बुनियादी ट्रिक भी खोलेंगे जो केवल एक लाइन कोड के साथ ब्लॉक होने से बचने में मदद करता है। क्या आप तैयार हैं? चलिए शुरू करते हैं!
सामग्री सूची
वेब स्क्रैपिंग का परिचय
C के बजाय C# क्यों चुनें?
अपने वातावरण की स्थापना
आवश्यकताएं
पुस्तकालय स्थापित करें
Visual Studio में C# वेब स्क्रैपिंग परियोजना बनाएं
C# के साथ मूल वेब स्क्रैपिंग
HTTP मांगें बनाएं
HTML सामग्री का विश्लेषण करें
उन्नत HTML पार्सिंग
स्क्रैप की गई डेटा का निपटान कैसे करें
वेब स्क्रैपिंग में CAPTCHA का निपटान
CAPTCHA सॉल्वर्स के साथ एम्बेड करें
CapSolver के लिए उदाहरण कोड
निष्कर्ष
1. वेब स्क्रैपिंग का परिचय
वेब स्क्रैपिंग वेबसाइटों से जानकारी के स्वचालित निकास की प्रक्रिया है। इसका उपयोग डेटा विश्लेषण, बाजार अनुसंधान और प्रतिस्पर्धी जानकारी के लिए किया जा सकता है। हालांकि, बहुत सारे वेबसाइट ऑटोमेटेड स्क्रैपिंग प्रयासों की पहचान करने और ब्लॉक करने के तरीके लेते हैं, जिसके कारण ब्लॉक होने से बचने के लिए जटिल तकनीकों का उपयोग करना आवश्यक हो जाता है।
C के बजाय C# क्यों चुनें?
वेब स्क्रैपिंग अक्सर वेब तत्वों के साथ अंतःक्रिया, HTTP मांगों के प्रबंधन और डेटा निकास और पार्सिंग के साथ जुड़ा होता है। यद्यपि C एक शक्तिशाली और दक्ष भाषा है, लेकिन वह वेब स्क्रैपिंग को आसान और दक्ष बनाने वाले निर्मित पुस्तकालय और आधुनिक विशेषताओं के बिना होता है। वेब स्क्रैपिंग के लिए C# के चयन के कुछ कारण नीचे दिए गए हैं:
समृद्ध पुस्तकालय: C# के पास HTML पार्सिंग के लिए HtmlAgilityPack और ब्राउज़र ऑटोमेशन के लिए Selenium जैसे विस्तृत पुस्तकालय होते हैं, जो स्क्रैपिंग प्रक्रिया को सरल बनाते हैं।
असिंक्रनस प्रोग्रामिंग: C# के async और await की शब्दावली एक दक्ष असिंक्रनस ऑपरेशन के लिए अनुमति देती है, जो समानांतर रूप से कई वेब मांगों के साथ निपटने के लिए आवश्यक है।
उपयोगकर्ता अनुकूल: C# की वाक्यविन्यास बेहतर और उपयोगकर्ता-मित्र होती है, जो विकास प्रक्रिया को तेज और कम त्रुटि-प्रवण बनाती है।
एकीकरण: C# .NET फ्रेमवर्क के साथ बिना बाधा के एकीकृत होता है, जो विश्वसनीय एप्लिकेशन बनाने के लिए शक्तिशाली टूल और सेवाएं प्रदान करता है।
दर्दनाक कैप्चा को पूरी तरह से हल करने में बार-बार विफलता से जूझ रहे हैं?
Capsolver आर्टिफिशियल इंटेलिजेंस के साथ ऑटोमैटिक कैप्चा समाधान के साथ असाधारण वेब अनब्लॉक तकनीक के साथ खोजें!
शीर्ष कैप्चा समाधान के लिए अपना बोनस कोड लें;
: WEBS। जब आप इसे बदल देते हैं, तो प्रत्येक भरोसे के बाद आपको 5% अतिरिक्त बोनस मिलेगा, असीमित
2. अपने वातावरण की स्थापना
स्क्रैपिंग शुरू करने से पहले, हमें अपने विकास वातावरण की स्थापना करनी होगी। यहां इसके लिए तरीका है:
आवश्यकताएं
Visual Studio: Visual Studio 2022 के मुफ्त Community संस्करण ठीक है।
.NET 6+: 6 से अधिक या बराबर के कोई भी LTS संस्करण ठीक है।
HTML पार्सिंग के लिए HtmlAgilityPack पुस्तकालय
HTTP मांगें बनाने के लिए RestSharp पुस्तकालय
Visual Studio में C# वेब स्क्रैपिंग परियोजना बनाएं
Visual Studio में परियोजना सेट करें
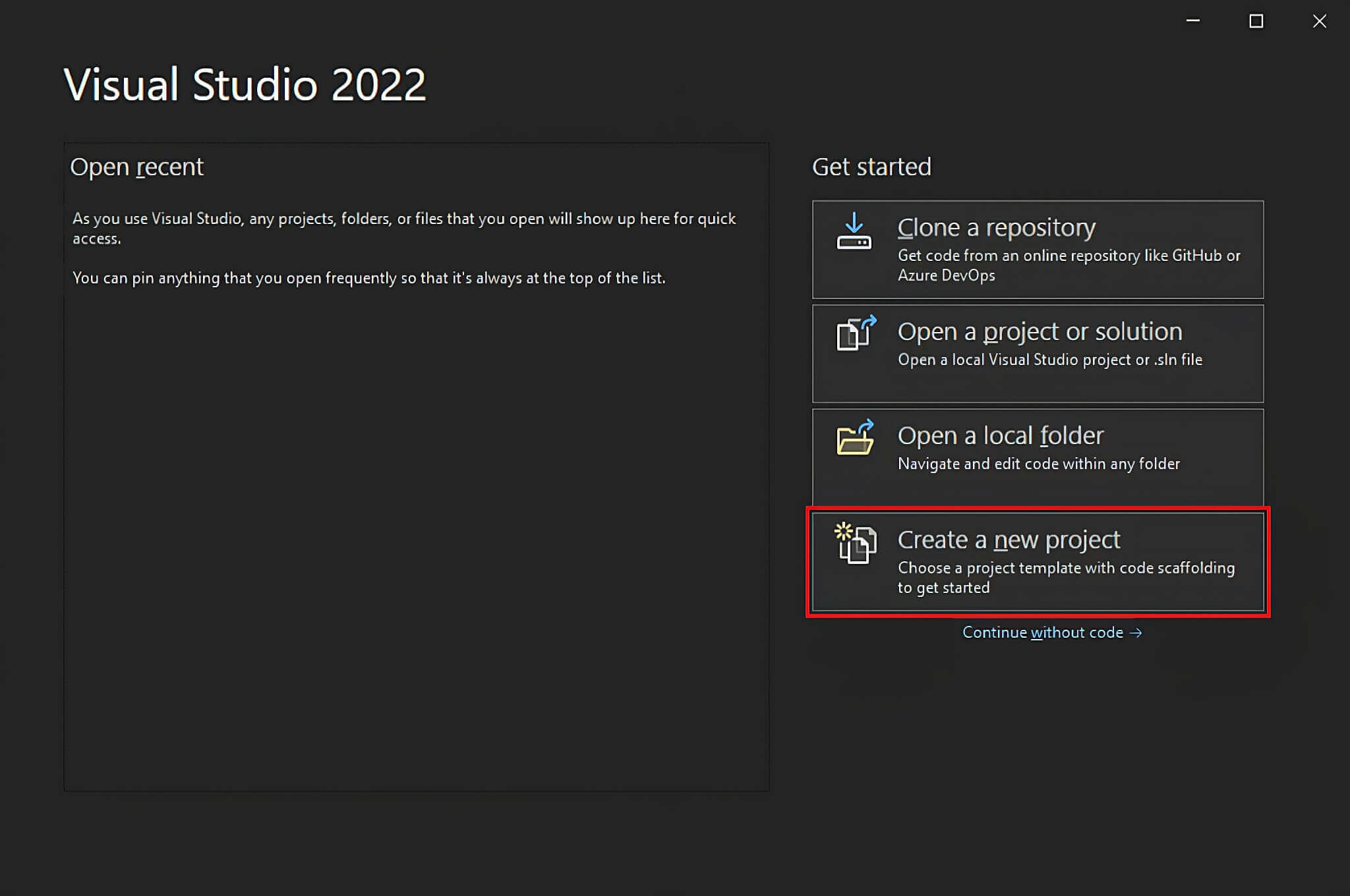
Visual Studio खोलें और "एक नई परियोजना बनाएं" विकल्प पर क्लिक करें।
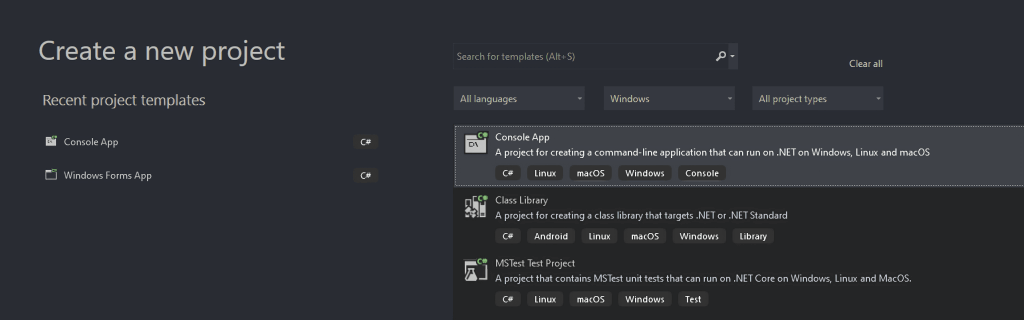
"एक नई परियोजना बनाएं" खिड़की में, एक ड्रॉप-डाउन सूची से "C#" विकल्प चुनें। प्रोग्रामिंग भाषा निर्दिष्ट करने के बाद, "कॉन्सोल एप्लिकेशन" टेम्पलेट चुनें और "अगला" पर क्लिक करें।
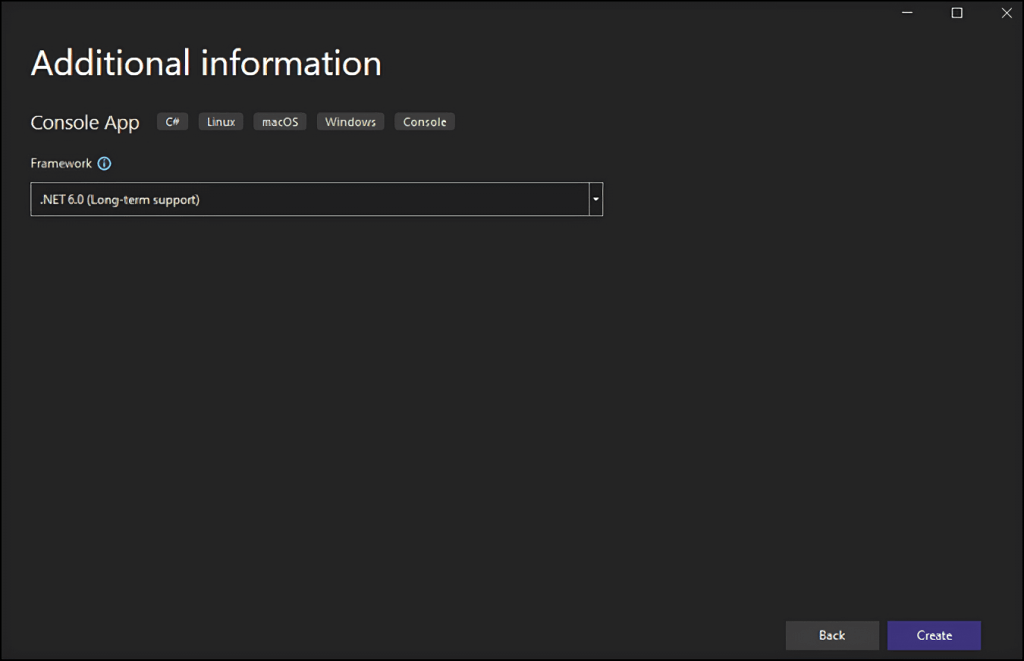
अपनी परियोजना का नाम StaticWebScraping रखें, चयन करें, और .NET संस्करण चुनें। यदि आपने .NET 6.0 स्थापित किया है, तो Visual Studio आपके लिए इसे अपने आप चुन लेगा।
"Create" बटन पर क्लिक करें ताकि आपकी C# वेब स्क्रैपिंग परियोजना शुरू हो जाए। Visual Studio StaticWebScraping फ़ोल्डर बनाएगा जिसमें App.cs फ़ाइल होगी। इस फ़ाइल में आपकी वेब स्क्रैपिंग तकनीक को C# में संग्रहीत करेंगे:
csharpCopy
namespace WebScraping {
public class Program {
public static void Main() {
// स्क्रैपिंग तकनीक...
}
}
}
अब आइए वेब स्क्रैपर कैसे बनाएं, इसके बारे में समझते हैं!
3. C# के साथ मूल वेब स्क्रैपिंग
इस खंड में, हम एक C# एप्लिकेशन बनाएंगे जो एक वेबसाइट पर HTTP मांगें भेजता है, HTML सामग्री लेता है, और इसके बाद इसे जांचकर जानकारी निकालता है।
HTTP मांगें बनाएं
सबसे पहले, हम एक आधारभूत C# एप्लिकेशन बनाएंगे जो वेबसाइट पर HTTP मांगें भेजता है और HTML सामग्री लेता है।
csharpCopy
using System;
using RestSharp;
class Program
{
static void Main()
{
// लक्ष्य URL के साथ एक नई RestClient असाइन करें
var client = new RestClient("https://www.example.com");
// GET विधि के साथ एक नई RestRequest असाइन करें
var request = new RestRequest(Method.GET);
// मांग को निष्पादित करें और प्रतिक्रिया प्राप्त करें
IRestResponse response = client.Execute(request);
// यह जांचें कि मांग सफल रही है या नहीं
if (response.IsSuccessful)
{
// प्रतिक्रिया की HTML सामग्री प्रिंट करें
Console.WriteLine(response.Content);
}
else
{
Console.WriteLine("सामग्री प्राप्त करने में असफल");
}
}
}
HTML सामग्री का विश्लेषण
अब हम HtmlAgilityPack का उपयोग करके HTML सामग्री को पार्स करेंगे और हमें आवश्यक जानकारी निकालेंगे।
csharpCopy
using HtmlAgilityPack;
using System;
using RestSharp;
class Program
{
static void Main()
{
// लक्ष्य URL के साथ एक नई RestClient असाइन करें
var client = new RestClient("https://www.example.com");
// GET विधि के साथ एक नई RestRequest असाइन करें
var request = new RestRequest(Method.GET);
// मांग को निष्पादित करें और प्रतिक्रिया प्राप्त करें
IRestResponse response = client.Execute(request);
// यह जांचें कि मांग सफल रही है या नहीं
if (response.IsSuccessful)
{
// HTML सामग्री को HtmlDocument में लोड करें
var htmlDoc = new HtmlDocument();
htmlDoc.LoadHtml(response.Content);
// निर्दिष्ट XPath अनुरोध के अनुरूप नोड्स का चयन करें
var nodes = htmlDoc.DocumentNode.SelectNodes("//h1");
// चयनित नोड्स के माध्यम से लूप चलाएं और उनका आंतरिक टेक्स्ट प्रिंट करें
foreach (var node in nodes)
{
Console.WriteLine(node.InnerText);
}
}
else
{
Console.WriteLine("सामग्री प्राप्त करने में असफल");
}
}
}
उन्नत HTML पार्सिंग
अब हम एक उदाहरण वेबसाइट से अधिक जटिल डेटा के साथ आगे बढ़ते हैं। मान लीजिए हमें एक ब्लॉग पृष्ठ से लेखों की सूची के शीर्षक और लिंक निकालने की आवश्यकता है।
csharpCopy
using HtmlAgilityPack;
using System;
using RestSharp;
class Program
{
static void Main()
{
// लक्ष्य URL के साथ एक नई RestClient असाइन करें
var client = new RestClient("https://www.example.com/blog");
// GET विधि के साथ एक नई RestRequest असाइन करें
var request = new RestRequest(Method.GET);
// मांग को निष्पादित करें और प्रतिक्रिया प्राप्त करें
IRestResponse response = client.Execute(request);
// यह जांचें कि मांग सफल रही है या नहीं
if (response.IsSuccessful)
{
// HTML सामग्री को HtmlDocument में लोड करें
var htmlDoc = new HtmlDocument();
htmlDoc.LoadHtml(response.Content);
// निर्दिष्ट XPath अनुरोध के अनुरूप नोड्स का चयन करें
var nodes = htmlDoc.DocumentNode.SelectNodes("//div[@class='post']");
// चयनित नोड्स के माध्यम से लूप चलाएं और शीर्षक और लिंक निकालें
foreach (var node in nodes)
{
var titleNode = node.SelectSingleNode(".//h2/a");
var title = titleNode.InnerText;
var link = titleNode.Attributes["href"].Value;
Console.WriteLine("शीर्षक: " + title);
Console.WriteLine("लिंक: " + link);
Console.WriteLine();
}
}
else
{
Console.WriteLine("सामग्री प्राप्त करने में असफल");
}
}
}
इस उदाहरण में, हम एक ब्लॉग पृष्ठ से डेटा निकालते हैं, प्रत्येक लेख के शीर्षक और लिंक निकालते हैं। XPath अनुरोध //div[@class='post'] का उपयोग विशिष्ट पोस्ट नोड्स को खोजने के लिए किया जाता है।
4. स्क्रैप की गई डेटा का निपटान कैसे करें
जब आवश्यकता होती है तब इसे डेटाबेस में संग्रहीत करें ताकि आसानी से पूछताछ की जा सके।
इसे JSON फॉर्मैट में परिवर्तित करें और विभिन्न API के लिए इसका उपयोग करें।
इसे CSV जैसे मानव-पठनीय फॉर्मैट में बदलें, जिसे एक्सेल में खोला जा सकता है।
ये केवल कुछ उदाहरण हैं। महत्वपूर्ण बात यह है कि जब आपके कोड में स्क्रैप की गई डेटा होता है, तो आप इसका उपयोग अपने आवश्यकता के अनुसार कर सकते हैं। आमतौर पर, स्क्रैप की गई डेटा का आपके बाजार, डेटा विश्लेषण या बिक्री टीम के लिए अधिक उपयोगी फॉर्मैट में परिवर्तित किया जाता है।
हालांकि, वेब स्क्रैपिंग के साथ अपने आपको अपने स्वयं के चुनौतियों के साथ जाने के लिए ध्यान रखें।
5. वेब स्क्रैपिंग में CAPTCHA का निपटान
वेब स्क्रैपिंग में सबसे बड़ी चुनौती CAPTCHA के साथ निपटान है, जो बॉट्स के मुकाबले मानव उपयोगकर्ताओं के बीच अंतर बनाने के लिए डिज़ाइन किया गया है। यदि आपको कैप्चा मिलता है, तो आपके स्क्रैपिंग स्क्रिप्ट को आगे बढ़ने के लिए इसे हल करना होगा। विशेष रूप से यदि आप अपने वेब स्क्रैपिंग को बढ़ाना चाहते हैं, CapSolver आपके लिए अपने उच्च सटीकता और तेज हल करने के साथ उपलब्ध है।
CAPTCHA सॉल्वर्स के साथ एम्बेड करें
आपके स्क्रैपिंग स्क्रिप्ट में कई CAPTCHA हल करने वाले सेवा शामिल कर सकते हैं। यहां हम CapSolver सेवा का उपयोग करेंगे। सबसे पहले, आपको CapSolver पर पंजीकरण करना होगा और अपना API कुंजी प्राप्त करना होगा।
चरण 1: CapSolver के लिए पंजीकरण करें
CapSolver के सेवाओं का उपयोग करने से पहले, आपको उपयोगकर्ता पैनल में अपना खाता पंजीकृत करें जाना होगा।
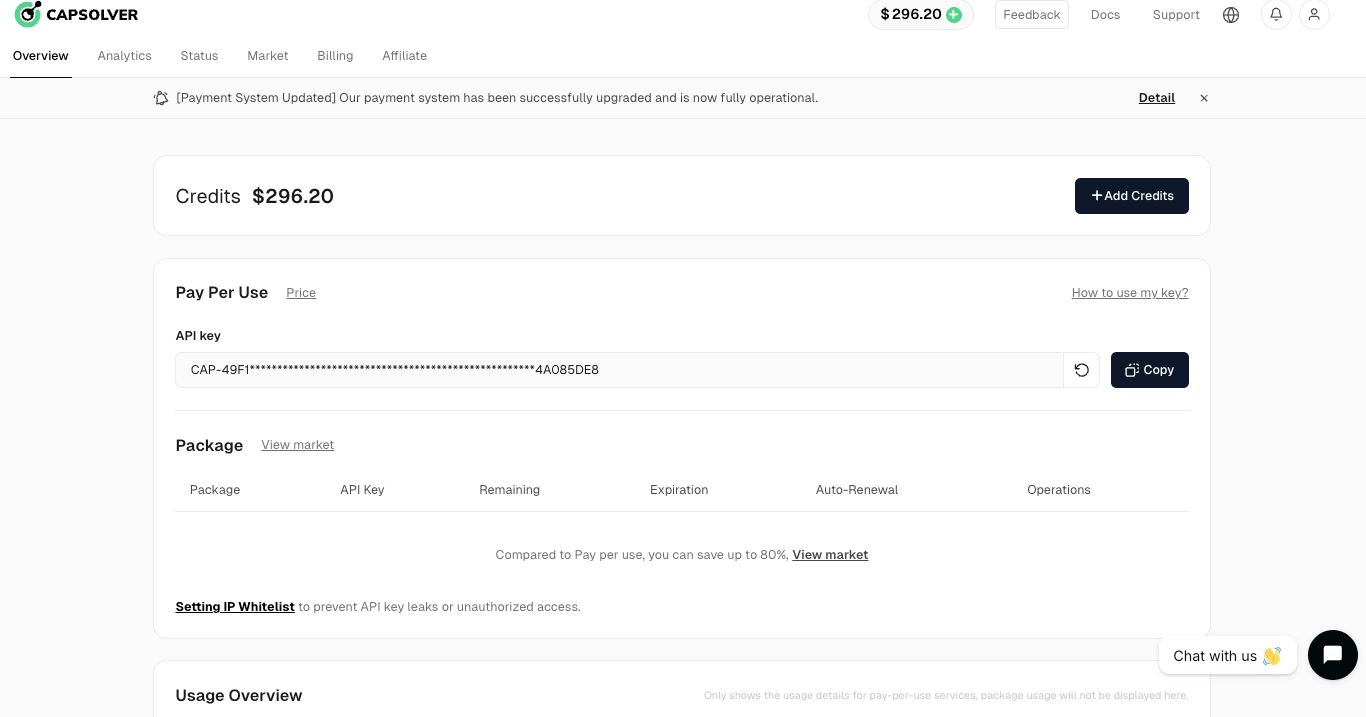
चरण 2: अपना API कुंजी प्राप्त करें
जब आप पंजीकृत हो जाते हैं, तो आप अपना API कुंजी होम पेज पैनल से प्राप्त कर सकते हैं
CapSolver के लिए उदाहरण कोड
आपके वेब स्क्रैपिंग या ऑटोमेशन परियोजना में CapSolver का उपयोग करना आसान है। यहां एक तेज उदाहरण है जो आपके कार्यप्रवाह में CapSolver के एम्बेड करने के तरीके को दर्शाता है:
pythonCopy
# pip install requests
import requests
import time
# TODO: अपना कॉन्फ़िग सेट करें
api_key = "YOUR_API_KEY" # आपका CapSolver के लिए API कुंजी
site_key = "6Le-wvkSAAAAAPBMRTvw0Q4Muexq9bi0DJwx_mJ-" # अपने लक्ष्य साइट के site key
site_url = "" # अपने लक्ष्य साइट के पेज URL
def capsolver():
payload = {
"clientKey": api_key,
"task": {
"type": 'ReCaptchaV2TaskProxyLess',
"websiteKey": site_key,
"websiteURL": site_url
}
}
res = requests.post("https://api.capsolver.com/createTask", json=payload)
resp = res.json()
task_id = resp.get("taskId")
if not task_id:
print("कार्य बनाने में असफल:", res.text)
return
print(f"taskId प्राप्त करें: {task_id} / परिणाम प्राप्त करने के लिए प्रतीक्षा करें...")
while True:
time.sleep(3) # देरी
payload = {"clientKey": api_key, "taskId": task_id}
res = requests.post("https://api.capsolver.com/getTaskResult", json=payload)
resp = res.json()
status = resp.get("status")
if status == "ready":
return resp.get("solution", {}).get('gRecaptchaResponse')
if status == "failed" or resp.get("errorId"):
print("हल करना असफल! प्रतिक्रिया:", res.text)
return
token = capsolver()
print(token)
इस उदाहरण में, capsolver फ़ंक्शन आवश्यक पैरामीटर के साथ CapSolver के API पर मांग भेजता है और कैप्चा समाधान लौटाता है। यह सरल एम्बेड वेब स्क्रैपिंग और ऑटोमेशन कार्यक्रमों में कैप्चा को हल करने के लिए हाथ से काम करने में बचाते हैं।
6. निष्कर्ष
C# में वेब स्क्रैपिंग वेबसाइटों से डेटा निकालने के लिए एक मजबूत ढांचा प्रदान करता है। HtmlAgilityPack और RestSharp जैसे पुस्तकालयों के साथ, और CapSolver जैसे कैप्चा हल करने वाली सेवाओं के साथ, डेवलपर्स वेब पृष्ठों के माध्यम से बिना किसी बाधा के निपट सकते हैं, HTML सामग्री का विश्लेषण कर सकते हैं और चुनौतियों को बिना किसी बाधा के निपट सकते हैं। इस क्षमता न केवल डेटा एकत्र करने की प्रक्रिया को सुव्यवस्थित करती है बल्कि नैतिक स्क्रैपिंग अभ्यासों के साथ सुनिश्चित करती है, जो विविध एप्लिकेशन में वेब स्क्रैपिंग परियोजनाओं के विश्वसनीयता और विस्तार को बढ़ाती है।