Crawl4AI में Cloudflare चुनौती कैसे हल करें और CapSolver एकीकरण के साथ

Rajinder Singh
Deep Learning Researcher
परिचय
क्लाउडफ़्लेर चुनौती एक जटिल बॉट विरोधी तकनीक है जो आमतौर पर ब्राउज़र फिंगरप्रिंटिंग और यूजर-एजेंट प्रमाणीकरण जैसे जटिल चेक के साथ वास्तविक उपयोगकर्ताओं को स्वचालित ट्रैफिक से अलग करने के लिए डिज़ाइन की गई है। इन चुनौतियों को वेब स्क्रैपिंग और डेटा निकालने के प्रयासों में बाधा डाल सकता है, जिससे क्रॉलर लक्षित वेबसाइटों तक पहुंचने में कठिनाई होती है। क्लाउडफ़्लेर चुनौती को पार करने के लिए एक मजबूत और अनुकूलन वाला समाधान आवश्यक है जो वास्तविक ब्राउज़र व्यवहार की नकल कर सके।
इस लेख में Crawl4AI के साथ CapSolver के एपीआई-आधारित एकीकरण विधि के बारे में विस्तृत कोड उदाहरण और स्पष्टीकरण प्रदान करके क्लाउडफ़्लेर चुनौती सुरक्षा को पार करने के लिए एक विस्तृत गाइड प्रदान करता है, जो एक उन्नत वेब क्रॉलर है। हम अपने वेब ऑटोमेशन कार्यकलापों के बिना बाधा के चलाने की गारंटी देने के लिए विस्तृत कोड उदाहरण और स्पष्टीकरण प्रदान करेंगे।
क्लाउडफ़्लेर चुनौती और वेब स्क्रैपिंग के जटिलताओं को समझें
क्लाउडफ़्लेर चुनौती को आम एपीके एपीके की तुलना में अधिक आक्रामक बनाया गया है, जो बॉट की पहचान और ब्लॉक करने के लिए तकनीकों के संयोजन का उपयोग करता है:
- ब्राउज़र फिंगरप्रिंटिंग: ब्राउज़र के अद्वितीय लक्षणों के विश्लेषण के माध्यम से स्वचालन की पहचान करना।
- यूजर-एजेंट प्रमाणीकरण: वास्तविक ब्राउज़र संस्करणों के साथ मेल खाने वाले विशिष्ट और निरंतर यूजर-एजेंट स्ट्रिंग की आवश्यकता होती है।
- जावास्क्रिप्ट निष्पादन: ब्राउज़र क्षमताओं और मानव-जैसे अंतरक्रिया की जांच के लिए पृष्ठभूमि में जटिल जावास्क्रिप्ट निष्पादित करना।
- कुकी प्रबंधन: चुनौती समाधान प्रक्रिया के हिस्से के रूप में विशिष्ट कुकीज़ सेट करना और उनकी पुष्टि करना।
CapSolver के पास AntiCloudflareTask प्रकार है, जो इन जटिल चुनौतियों को सुलझाने के लिए विशेष रूप से डिज़ाइन किया गया है जो आवश्यक टोकन, कुकीज़ और यहां तक कि विशिष्ट यूजर-एजेंट की सिफारिश करता है। जब Crawl4AI के साथ एकीकृत किया जाता है, तो यह आपके क्रॉलर को क्लाउडफ़्लेर-सुरक्षित साइटों के माध्यम से सफलतापूर्वक ब्राउज़ करने की अनुमति देता है।
एकीकरण विधि: Crawl4AI के साथ CapSolver एपीआई एकीकरण
एपीआई एकीकरण विधि क्लाउडफ़्लेर चुनौती के हाथापाई के लिए महत्वपूर्ण है, क्योंकि यह ब्राउज़र कॉन्फ़िगरेशन पर बिना किसी बाधा के नियंत्रण देता है और आवश्यक टोकन और कुकीज़ के निवेश के लिए अनुमति देता है। इस विधि में CapSolver के माध्यम से आवश्यक चुनौती समाधान (टोकन, कुकीज़ और यूजर-एजेंट) प्राप्त करने के बाद Crawl4AI कॉन्फ़िगरेशन को इन पैरामीटर के साथ सेट करना शामिल है।
कैसे काम करता है:
- क्लाउडफ़्लेर चुनौती समाधान प्राप्त करें: क्रॉलर चलाने से पहले, अपने SDK के माध्यम से CapSolver के एपीआई को कॉल करें,
AntiCloudflareTaskप्रकार निर्दिष्ट करें। आपकोwebsiteURL, एकप्रॉक्सी(अगर आवश्यक हो) और एकयूजर-एजेंटकी आवश्यकता होगी जो CapSolver द्वारा समाधान के लिए उपयोग किए जाने वाले ब्राउज़र संस्करण के साथ मेल खाता हो। - Crawl4AI ब्राउज़र कॉन्फ़िगरेशन कॉन्फ़िगर करें: CapSolver के समाधान द्वारा लौटाए गए टोकन, कुकीज़ और एक सुझावित यूजर-एजेंट के उपयोग से Crawl4AI के
BrowserConfigको कॉन्फ़िगर करें। इससे यह सुनिश्चित होता है कि Crawl4AI के ब्राउज़र उपयोगकर्ता के वातावरण की तरह होगा जिसके तहत चुनौती को सुलझाया गया था। - क्रॉलर चलाएं: Crawl4AI फिर विशेष रूप से कॉन्फ़िगर किए गए ब्राउज़र के साथ चलता है, जिसमें आवश्यक कुकीज़ और यूजर-एजेंट शामिल होते हैं, जिससे यह क्लाउडफ़्लेर चुनौती को पार कर सकता है।
- ऑपरेशन जारी रखें: क्लाउडफ़्लेर चुनौती के सफलतापूर्वक पार करने के बाद, Crawl4AI लक्षित वेबसाइट पर डेटा निकालने के कार्यकलापों के साथ आगे बढ़ सकता है।
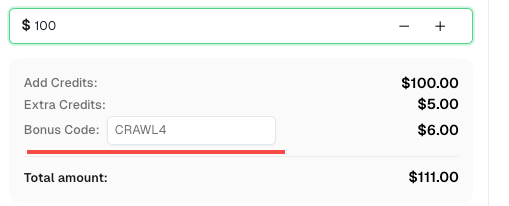
💡 Crawl4AI एकीकरण उपयोगकर्ताओं के लिए अपना विशेष बोनस:
इस एकीकरण के उत्सव के रूप में, हम इस पाठ्यक्रम के माध्यम से पंजीकृत सभी CapSolver उपयोगकर्ताओं के लिए एक विशेष 6% बोनस कोड —CRAWL4प्रदान कर रहे हैं।
बैठक के दौरान बोनस कोड दर्ज करें डैशबोर्ड के लिए तुरंत 6% अतिरिक्त क्रेडिट प्राप्त करें।
उदाहरण कोड: क्लाउडफ़्लेर चुनौती के लिए एपीआई एकीकरण
निम्नलिखित पायथन कोड क्लाउडफ़्लेर चुनौती के समाधान के लिए CapSolver के एपीआई के एकीकरण को दर्शाता है। इस उदाहरण का लक्ष्य क्लाउडफ़्लेर द्वारा सुरक्षित एक समाचार लेख पृष्ठ है।
python
import asyncio
import time
import capsolver
from crawl4ai import *
# TODO: अपना कॉन्फ़िग सेट करें
api_key = "CAP-XXX" # आपका CapSolver के लिए एपी एसी की
site_url = "https://www.tempo.co/hukum/polisi-diduga-salah-tangkap-pelajar-di-magelang-yang-dituduh-perusuh-demo-2070572" # अपने लक्षित साइट के पृष्ठ के लिए URL
captcha_type = "AntiCloudflareTask" # अपने कैप्चा के प्रकार
api_proxy = "http://127.0.0.1:13120"
capsolver.api_key = api_key
user_data_dir = "./crawl4ai_/browser-profile/Default1493"
# या
cdp_url = "ws://localhost:xxxx"
async def main():
print("टोकन सॉल्वर शुरू हो गया")
start_time = time.time()
# कैपसॉल्वर एसडीके के माध्यम से क्लाउडफ़्लेर टोकन प्राप्त करें
solution = capsolver.solve({
"type": captcha_type,
"websiteURL": site_url,
"proxy": api_proxy,
"userAgent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/138.0.0.0 Safari/537.36"
})
token_time = time.time()
print(f"टोकन सॉल्वर: {token_time - start_time:.2f} सेकंड")
# कुकीज़ सेट करें
cookies = solution.get("cookies", [])
if isinstance(cookies, dict):
cookies_array = []
for name, value in cookies.items():
cookies_array.append({
"name": name,
"value": value,
"url": site_url,
})
cookies = cookies_array
elif not isinstance(cookies, list):
cookies = []
token = solution["token"]
print("चुनौती टोकन:", token)
browser_config = BrowserConfig(
verbose=True,
headless=False,
use_persistent_context=True,
user_data_dir=user_data_dir,
# cdp_url=cdp_url,
user_agent=solution["userAgent"],
cookies=cookies,
)
async with AsyncWebCrawler(config=browser_config) as crawler:
result = await crawler.arun(
url=site_url,
cache_mode=CacheMode.BYPASS,
session_id="session_captcha_test"
)
print(result.markdown[:500])
if __name__ == "__main__":
asyncio.run(main())कोड विश्लेषण:
- कैपसॉल्वर एसडीके कॉल:
capsolver.solveविधि यहां केंद्रीय है,AntiCloudflareTaskप्रकार का उपयोग करता है। इसेwebsiteURL,proxyऔर विशिष्टuserAgentकी आवश्यकता होती है। CapSolver चुनौती को समाधान करता है और एकsolutionऑब्जेक्ट लौटाता है जो एकtoken,cookiesऔर चुनौती के समाधान के लिए उपयोग किए गएuserAgentके साथ आता है। - ब्राउज़र कॉन्फ़िगरेशन: Crawl4AI के
BrowserConfigको CapSolver के समाधान से प्राप्त जानकारी के उपयोग से ध्यान से कॉन्फ़िगर किया गया है। इसमें ब्राउज़र के वातावरण को सुनिश्चित करने के लिएuser_agentऔरcookiesशामिल हैं।user_data_dirको एक स्थिर ब्राउज़र प्रोफ़ाइल बनाए रखने के लिए भी निर्दिष्ट किया गया है। - क्रॉलर निष्पादन: Crawl4AI फिर इस ध्यान से कॉन्फ़िगर किए गए
browser_configके साथ अपनेarunविधि के निष्पादन करता है, जिससे यह लक्षित URL तक पहुंच सकता है बिना क्लाउडफ़्लेर चुनौती को फिर से चालू किए बिना।
निष्कर्ष
वेब स्क्रैपिंग में क्लाउडफ़्लेर चुनौती के पार करना एक जटिल कार्य है जिसके लिए जटिल दृष्टिकोण की आवश्यकता होती है। Crawl4AI के साथ CapSolver के एकीकरण एक शक्तिशाली और प्रभावी समाधान प्रदान करता है, जो विकासकर्ताओं को इन उन्नत बॉट-विरोधी सुरक्षाओं के माध्यम से बिना किसी बाधा के ब्राउज़ करने की अनुमति देता है। आवश्यक टोकन, कुकीज़ और यूजर-एजेंट प्राप्त करने के लिए CapSolver के विशेष AntiCloudflareTask का उपयोग करके और फिर Crawl4AI के ब्राउज़र को इन पैरामीटर के साथ कॉन्फ़िगर करके आप अपने वेब स्क्रैपिंग ऑपरेशन की स्थिरता और सफलता सुनिश्चित कर सकते हैं।
Crawl4AI के उन्नत क्रॉलिंग क्षमताओं और CapSolver के विश्वसनीय बॉट-विरोधी तकनीक के बीच यह संयोजन ऑटोमेटेड वेब डेटा निकालने में एक महत्वपूर्ण उन्नति है, जिससे आप क्लाउडफ़्लेर के सुरक्षात्मक उपायों द्वारा बाधित होने के बिना मूल्यवान डेटा एकत्र करने पर ध्यान केंद्रित कर सकते हैं।
अक्सर पूछे जाने वाले प्रश्न (FAQ)
प्रश्न 1: क्लाउडफ़्लेर चुनौती क्या है और इसका उपयोग क्यों किया जाता है?
उत्तर 1: क्लाउडफ़्लेर चुनौती एक उन्नत बॉट विरोधी तकनीक है जो जांचती है कि क्या एक दर्शक वास्तविक मानव है या एक स्वचालित स्क्रिप्ट। यह ब्राउज़र फिंगरप्रिंटिंग, यूजर-एजेंट प्रमाणीकरण और जावास्क्रिप्ट निष्पादन जैसी विभिन्न तकनीकों का उपयोग करता है ताकि वेबसाइटों को बुरे बॉट, DDoS हमलों और अन्य खतरों से सुरक्षित रखा जा सके।
प्रश्न 2: वेब स्क्रैपर्स के लिए क्लाउडफ़्लेर चुनौती क्यों विशेष रूप से कठिन है?
उत्तर 2: क्लाउडफ़्लेर चुनौती वेब स्क्रैपर्स के लिए कठिन है क्योंकि यह साधारण कैप्चा के बजाय ब्राउज़र विशेषताओं का सक्रिय विश्लेषण करता है, स्थिर यूजर-एजेंट स्ट्रिंग की आवश्यकता होती है, जटिल जावास्क्रिप्ट निष्पादित करता है और विशिष्ट कुकीज़ का प्रबंधन करता है। इस जटिल पहचान के कारण इसे वास्तविक मानव अंतरक्रिया की नकल करना विशेष समाधानों के बिना असंभव है।
प्रश्न 3: कैपसॉल्वर क्लाउडफ़्लेर चुनौती के पार करने में कैसे मदद करता है?
उत्तर 3: CapSolver के पास क्लाउडफ़्लेर चुनौती के समाधान के लिए एक विशेष कार्य प्रकार, AntiCloudflareTask है। यह चुनौती को समाधान करता है और एक समाधान लौटाता है जो टोकन, आवश्यक कुकीज़ और एक सुझावित यूजर-एजेंट के साथ आता है। इस जानकारी का उपयोग बाद में Crawl4AI कॉन्फ़िगरेशन के लिए किया जाता है ताकि चुनौती को सफलतापूर्वक पार किया जा सके।
प्रश्न 4: क्लाउडफ़्लेर चुनौती के लिए Crawl4AI और CapSolver के एकीकरण के समय मुख्य विचारों के बारे में क्या होता है?
उत्तर 5: मुख्य विचारों में यह सुनिश्चित करना शामिल है कि Crawl4AI कॉन्फ़िगरेशन में उपयोग किए गए userAgent CapSolver द्वारा प्रदान किए गए यूजर-एजेंट के साथ मेल खाता हो, वापस आए कुकीज़ के सही ढंग से प्रबंधन और इंजेक्शन करना, और अगर आपके स्क्रैपिंग कार्यों की आवश्यकता होती है तो एक प्रॉक्सी प्रदान करना। इन कदमों से यह सुनिश्चित होता है कि Crawl4AI के ब्राउज़र वातावरण चुनौती के समाधान के अवसर में उपस्थित शर्तों के समान होगा।
संदर्भ
और देखें
CloudflareDec 10, 2025
क्लाउडफ़्लेयर चुनौती विरुद्ध टर्नस्टाइल: मुख्य अंतर और उन्हें कैसे पहचानें
क्लाउडफ़्लेयर चैलेंज वर्सेस टर्नस्टाइल के मुख्य अंतर समझें और सफल वेब ऑटोमेशन के लिए उन्हें पहचानना सीखें। विशेषज्ञ सुझाव प्राप्त करें एवं एक सुझाए गए समाधानकर्ता।
CloudflareFeb 04, 2026
वेब स्क्रैपिंग के समय क्लाउडफ़्लेयर सुरक्षा कैसे हल करें
जब वेब स्क्रैपिंग करते हैं तो क्लाउडफ़ेयर सुरक्षा कैसे हल करें। साबित विधियां जैसे कि IP परिवर्तन, TLS फिंगरप्रिंटिंग, और CapSolver की खोज करें।
