चित्र पहचान एआई कैसे काम करता है? | तकनीकी गाइड

Rajinder Singh
Deep Learning Researcher
TL;Dr
- इमेज रिकग्निशन एआई दृश्य पिक्सल को मशीन अनुमान के लिए संख्यात्मक डेटा में बदल देता है।
- कॉन्वोल्यूशनल न्यूरल नेटवर्क (CNNs) एक पैटर्न जैसे कि किनारे और आकृतियां खोजने के लिए उपयोग किए जाने वाले मुख्य आर्किटेक्चर हैं।
- प्रक्रिया में डेटा संग्रह और लेबलिंग से लेकर मॉडल ट्रेनिंग और मूल्यांकन तक एक संरचित पाइपलाइन शामिल है।
- वास्तविक दुनिया के उपयोग में चिकित्सा निदान से लेकर कैपसॉल्वर के विजन इंजन जैसी सुरक्षा प्रणालियों तक शामिल हैं।
- स्थायी एआई विकास के लिए नैतिक डेटा स्रोत और तकनीकी सुसंगतता आवश्यक हैं।
परिचय
इमेज रिकग्निशन एआई दृश्य सूचना को गणितीय ऐरे में बदलकर काम करता है जिसे न्यूरल नेटवर्क विशिष्ट पैटर्न के लिए विश्लेषित करते हैं। इस तकनीक के कारण मशीनें डिजिटल छवियों में वस्तुएं, लोग और कार्यों की अद्भुत गति और सटीकता के साथ पहचान कर सकती हैं। डेवलपर्स और डेटा प्रेमियों के लिए जानना आवश्यक है कि इमेज रिकग्निशन एआई कैसे काम करता है, यह उन्नत कंप्यूटर विजन प्रणालियां बनाने की पहली कदम है।
अंत तक, इमेज रिकग्निशन की प्रभावशीलता ट्रेनिंग डेटा की गुणवत्ता और न्यूरल आर्किटेक्चर की जटिलता पर निर्भर करती है। इस गाइड में दृश्य एआई के तकनीकी स्तरों को समझाया गया है, रॉ पिक्सेल प्रसंस्करण से लेकर जटिल वस्तुओं के अंतिम वर्गीकरण तक। हम देखेंगे कि आधुनिक प्रणालियां गणित का उपयोग कैसे करती हैं ताकि "देखें" और हमारे आसपास के विश्व की व्याख्या कर सकें।
मूलभूत बुनियादी: पिक्सेल और संख्यात्मक डेटा
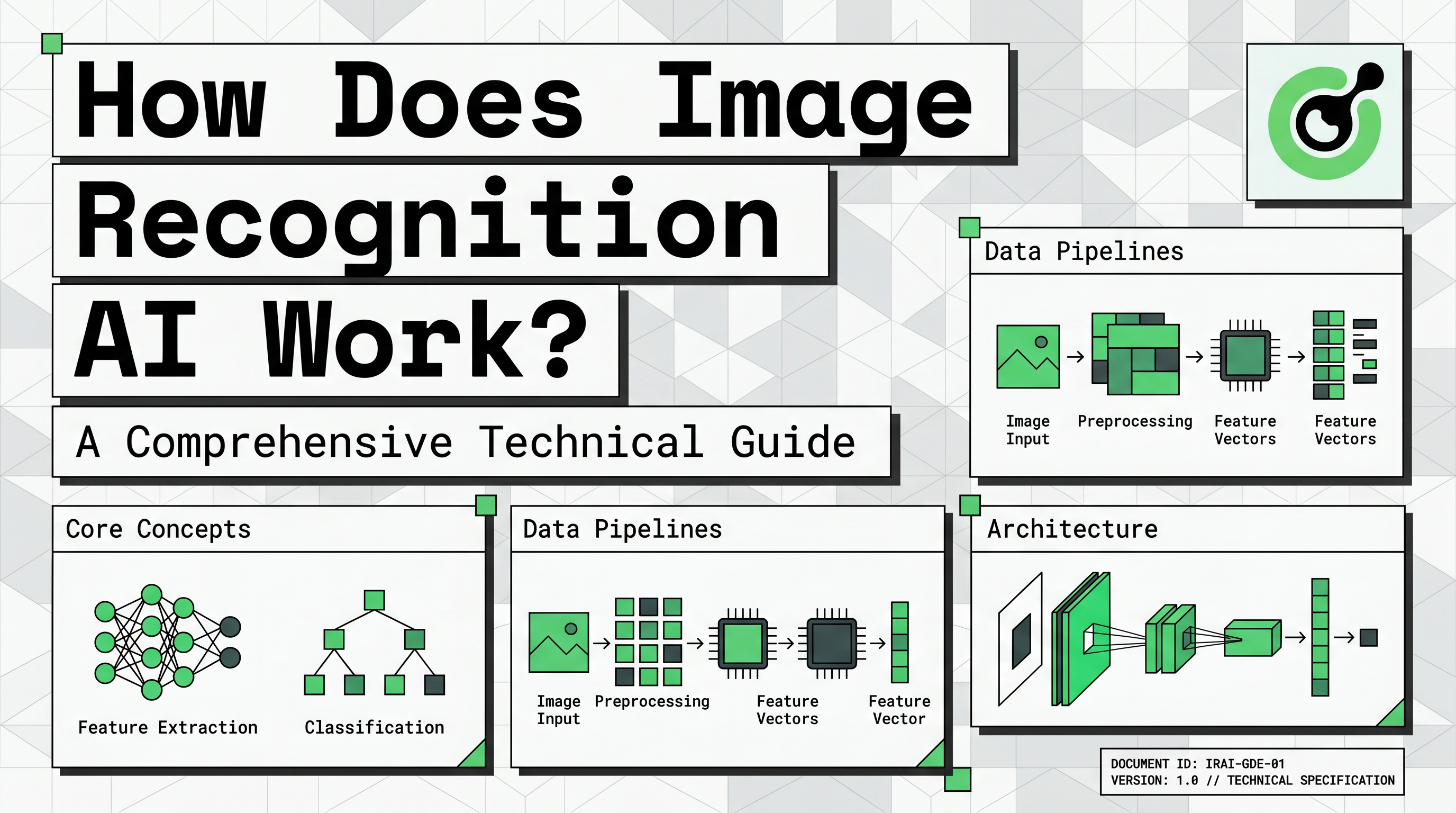
इमेज रिकग्निशन एआई कैसे काम करता है, इसके लिए हमें पहले यह देखना होगा कि कंप्यूटर छवियों को कैसे देखते हैं। एक डिजिटल छवि एक बड़े ग्रिड के रूप में होती है जिसमें छोटे तत्व होते हैं जिन्हें पिक्सेल कहा जाता है। प्रत्येक पिक्सेल में उसकी प्रकाश तीव्रता या रंग स्तर के लिए संख्यात्मक मान होते हैं।
एक सामान्य रंग छवि में, प्रत्येक पिक्सेल तीन मानों द्वारा प्रतिनिधित्व किया जाता है: लाल, हरा और नीला (RGB)। ये मान आमतौर पर 0 से 255 तक होते हैं। एक मशीन एक कार की छवि को एक वाहन के रूप में नहीं, बल्कि एक बड़े नंबर के मैट्रिक्स के रूप में देखती है। यह संख्यात्मक प्रतिनिधित्व एक इमेज रिकग्निशन प्रणाली द्वारा प्रसंस्करण के लिए कच्चा इनपुट है जो अर्थपूर्ण पैटर्न खोजता है।
| घटक | मशीन प्रतिनिधित्व | कार्य |
|---|---|---|
| पिक्सेल | संख्यात्मक मान (0-255) | दृश्य डेटा की मूल इकाई |
| रंग चैनल | RGB मैट्रिक्स | रंग और गहराई की जानकारी प्रदान करता है |
| छवि टेंसर | बहुआयामी ऐरे | एआई इनपुट के लिए पूर्ण डेटा संरचना |
इस परिवर्तन दृश्य इनपुट से मशीन-पठनीय टेंसर तक आवश्यक है। यह एआई को डेटा पर गणितीय संचालन करने की अनुमति देता है ताकि मनुष्य द्वारा अनुभव किए जाने वाले विशिष्ट विशेषताओं की पहचान की जा सके।
दृश्य एआई का इंजन: कॉन्वोल्यूशनल न्यूरल नेटवर्क (CNNs)
आधुनिक दृश्य प्रणालियों के पीछे मुख्य तकनीक कॉन्वोल्यूशनल न्यूरल नेटवर्क (CNN) है। इस आर्किटेक्चर को छवियों जैसे ग्रिड-आधारित डेटा संरचनाओं को प्रसंस्करण के लिए विशेष रूप से डिज़ाइन किया गया है। जब हम इमेज रिकग्निशन एआई कैसे काम करता है, तो CNNs विश्लेषण करने के लिए सबसे महत्वपूर्ण तकनीकी घटक हैं।
एक CNN कई परतों से बना होता है जो विभिन्न कार्य करती हैं। पहली परत कॉन्वोल्यूशनल परत होती है, जो छवि पर फिल्टर लगाकर निम्न-स्तरीय विशेषताएं निकालती है। इन विशेषताओं में सरल तत्व जैसे कि क्षैतिज रेखाएं, ऊर्ध्वाधर किनारे और आधारभूत ऊतक शामिल हैं।
अगले पूलिंग परतें डेटा के आयाम को कम करती हैं जबकि सबसे महत्वपूर्ण जानकारी को बरकरार रखती हैं। इस चरण में प्रणाली अधिक कुशल हो जाती है और अपना ध्यान सबसे महत्वपूर्ण विशेषताओं पर केंद्रित करती है। अंत में, पूर्ण रूप से जुड़ी हुई परतें प्रसंस्कृत जानकारी लेती हैं और अंतिम वर्गीकरण करती हैं। यह वह स्थान है जहां एआई तय करता है कि पहचाने गए विशेषताएं बिल्ली, कार या विशिष्ट प्रकार के पाठ का प्रतिनिधित्व करती हैं।
IBM: इमेज रिकग्निशन क्या है? के अनुसार, ये परतें छवि के एक हिरासत वाले बुनियादी ज्ञान के साथ एक संयुक्त रूप से काम करती हैं। प्रणाली सरल रेखाओं से शुरू होती है और धीरे-धीरे जटिल वस्तुओं तक बढ़ती है। यह हिरासत वाला दृष्टिकोण ही है जो CNNs को विविध दृश्य कार्यों के साथ निपटने में इतना प्रभावी बनाता है।
इमेज रिकग्निशन पाइपलाइन: डेटा से डिप्लॉयमेंट तक
एक सफल प्रणाली बनाने में न्यूरल नेटवर्क के बाहर एक संरचित पाइपलाइन शामिल होती है। पहला चरण डेटा संग्रह है, जहां विकासकर्ता अपने लक्ष्य कार्य के लिए संबंधित हजारों छवियां एकत्र करते हैं। उदाहरण के लिए, चिकित्सा असामान्यताओं की पहचान करने के लिए डिज़ाइन की गई प्रणाली के लिए एक विशाल निदान स्कैन के डेटासेट की आवश्यकता होती है।
डेटा लेबलिंग अगला महत्वपूर्ण चरण है। मानव एनोटेटर्स को सही वर्गीकरण के साथ छवियों को टैग करना होता है या विशिष्ट वस्तुओं के चारों ओर बाउंडिंग बॉक्स बनाना होता है। इस लेबल किए गए डेटा का उपयोग एआई द्वारा ट्रेनिंग चरण में सीखने के लिए किया जाता है। उच्च गुणवत्ता वाले लेबल के बिना, यहां तक कि सबसे अच्छा CNN भी सटीक परिणाम उत्पन्न नहीं कर सकता है।
पूर्व-संसाधन और अनुकूलन भी आवश्यक हैं। इसमें छवियों के आकार को छोटा करना, रंग मानों को सामान्य बनाना और मौजूदा डेटा के विविधता बनाना शामिल है। अनुकूलन मॉडल को अधिक मजबूत बनाता है क्योंकि यह मूल छवियों के घूमे, उलटे या थोड़ा अस्पष्ट संस्करण पर प्रशिक्षण देता है। इससे एआई को विभिन्न वास्तविक दुनिया की स्थितियों में वस्तुओं की पहचान करने में सक्षम बनाया जाता है।
अंत में, मॉडल का मूल्यांकन निर्णायक मापदंडों जैसे सटीकता, याददाश्ता और सटीकता के साथ किया जाता है। इस परीक्षण चरण में तय किया जाता है कि प्रणाली डिप्लॉयमेंट के लिए तैयार है या नहीं। विकासकर्ताओं को यह सुनिश्चित करना आवश्यक है कि एआई नए, अज्ञात डेटा पर विश्वसनीय रूप से काम करती है जब तक कि इसे एक लाइव एप्लिकेशन में एम्बेड नहीं किया जाता।
व्यावहारिक अनुप्रयोग: जटिल दृश्य चुनौतियों को हल करना
इमेज रिकग्निशन का उपयोग कई उद्योगों में अब तक हाथ से किए जाने वाले कार्यों को स्वचालित करने के लिए किया जाता है। स्वास्थ्य देखभाल में, यह रेडियोलॉजिस्ट की मदद करता है कि एक्स-रे में बीमारी के शुरुआती लक्षणों की पहचान करें। रिटेल में, यह स्वचालित चेकआउट प्रणालियों और उपयोगकर्ताओं को फोटो के माध्यम से उत्पाद खोजने में मदद करने वाले दृश्य खोज टूल को संचालित करता है।
एक विशेष अनुप्रयोग इस तकनीक के सुरक्षा और स्वचालन में पाया जाता है। उदाहरण के लिए, CapSolver जटिल दृश्य चुनौतियों जैसे कैप्चा को हल करने के लिए उन्नत इमेज रिकग्निशन का उपयोग करता है। उनका विजन इंजन इमेज रिकग्निशन एआई कैसे काम करता है, इसका एक उत्तम उदाहरण है।
CapSolver Vision Engine का उपयोग करके, डेवलपर्स अत्यधिक सटीकता के साथ दृश्य पहेलियों की पहचान कर सकते हैं। यह वेब स्क्रैपिंग और डेटा निकालने के कार्यों में विशेष रूप से उपयोगी है जहां पारंपरिक स्वचालन ब्लॉक हो सकता है। इन तकनीकों को लागू करने के लिए जाने वाले लोगों के लिए, AI और LLMs के उपयोग के बारे में एक व्यावहारिक गाइड महत्वपूर्ण कार्यान्वयन रणनीतियां प्रदान कर सकता है। नीचे एक अवधारणात्मक उदाहरण दिया गया है जो एक दृश्य पहचान API के साथ अंतर करने के बारे में है:
python
import requests
# एक विजन इंजन का उपयोग करके इमेज रिकग्निशन का उदाहरण
def solve_visual_task(image_path, api_key):
url = "https://api.capsolver.com/createTask"
payload = {
"clientKey": api_key,
"task": {
"type": "ImageToTextTask",
"body": "base64_encoded_image_string"
}
}
response = requests.post(url, json=payload)
return response.json()
# इमेज रिकग्निशन के उपयोग को स्वचालन में दर्शाता हैAI कैप्चा हल करने में कैसे काम करता है के बारे में आधुनिक इमेज रिकग्निशन की तकनीकी परिपक्वता को दर्शाता है। यह दिखाता है कि AI अब मानवों द्वारा हल करने योग्य माने जाने वाले विषयात्मक दृश्य कार्यों का भी निपटारा कर सकता है। यह विकास एक बड़े पैमाने पर ताकत जैसे AI और LLMs कैप्चा वातावरण को बदल रहे हैं के एक हिस्से के रूप में है, जो अधिक जटिल तर्क क्षमताओं के साथ नए समाधान प्रदान करते हैं।
वस्तुनिष्ठ और विषयात्मक कार्यों में दृश्य एआई
सभी इमेज रिकग्निशन कार्य समान जटिलता में नहीं होते हैं। विकासकर्ता आमतौर पर अपनी विषमता और आवश्यक सटीकता के आधार पर कार्यों को वर्गीकृत करते हैं।
| कार्य श्रेणी | विवरण | उदाहरण |
|---|---|---|
| वस्तुनिष्ठ | स्पष्ट मानदंड जिसमें द्विआधारी उत्तर होते हैं | क्या इस छवि में कुत्ता है? |
| विषयात्मक | जटिल व्याख्या की आवश्यकता होती है | क्या यह चिकित्सा स्कैन एक अच्छा या बुरा वृद्धि दिखा रहा है? |
| मात्रात्मक | गिनती या माप के साथ जुड़ा होता है | इस पार्किंग लॉट में कारें कितनी हैं? |
| गुणात्मक | छवि की गुणवत्ता का आकलन | क्या यह ई-कॉमर्स साइट के लिए उपयुक्त उत्पाद छवि पर्याप्त रूप से स्पष्ट है? |
इन श्रेणियों को समझना विकासकर्ताओं के लिए सही मॉडल और ट्रेनिंग रणनीति चुनने में मदद करता है। वस्तुनिष्ठ कार्य आमतौर पर AI के लिए आसान होते हैं, जबकि विषयात्मक कार्य के लिए अधिक विस्तृत डेटा सेट और मानव नियंत्रण की आवश्यकता होती है।
एफक्यूएए (FAQ)
इमेज रिकग्निशन और ऑब्जेक्ट डिटेक्शन में क्या अंतर है?
इमेज रिकग्निशन छवि के प्राथमिक विषय की पहचान करता है, जबकि ऑब्जेक्ट डिटेक्शन एक फ्रेम में कई ऑब्जेक्ट की पहचान और लेबलिंग करता है। ऑब्जेक्ट डिटेक्शन आमतौर पर जटिल होता है क्योंकि इसमें प्रत्येक ऑब्जेक्ट की स्थिति की पहचान करना आवश्यक होता है।
क्यों CNNs इमेज संबंधी कार्यों के लिए पसंदीदा हैं?
CNNs को पसंद किया जाता है क्योंकि वे स्थानीय विशेषताओं के हिरासत वाले ज्ञान को स्वयं शिक्षित कर सकते हैं। वे कॉन्वोल्यूशनल परतों का उपयोग करके सरल पैटर्न जैसे कि किनारे और धीरे-धीरे जटिल वस्तुओं में जुड़े हुए होते हैं। इससे वे दृश्य डेटा के लिए पारंपरिक न्यूरल नेटवर्क की तुलना में अधिक कुशल होते हैं।
एक विश्वसनीय इमेज रिकग्निशन मॉडल के लिए कितना डेटा चाहिए?
डेटा की मात्रा कार्य की जटिलता पर निर्भर करती है। सरल वर्गीकरण के लिए कुछ हजार छवियां पर्याप्त हो सकती हैं। हालांकि, स्वचालित ड्राइविंग जैसे क्षेत्रों में उच्च-सटीकता वाली प्रणालियों के लिए लाखों लेबल छवियां आमतौर पर आवश्यक होती हैं ताकि सुरक्षा और विश्वसनीयता सुनिश्चित की जा सके।
क्या इमेज रिकग्निशन एआई वास्तविक समय में काम कर सकता है?
हां, आधुनिक हार्डवेयर और अनुकूलित न्यूरल आर्किटेक्चर के कारण वास्तविक समय में इमेज रिकग्निशन संभव है। यह चेहरा पहचान सुरक्षा और स्वचालित वाहन नेविगेशन जैसे अनुप्रयोगों के लिए आवश्यक है, जहां निर्णय मिलीसेकंड में लिए जाने चाहिए।
समाप्ति
इमेज रिकग्निशन एआई कैसे काम करता है, इसके लिए न्यूरल आर्किटेक्चर और डेटा प्रबंधन के बारे में गहरा ज्ञान आवश्यक है। शक्तिशाली CNNs और उच्च गुणवत्ता वाले डेटा सेट के संयोजन से विकासकर्ता ऐसी प्रणालियां बना सकते हैं जो दृश्य दुनिया को अद्भुत सटीकता के साथ समझ सकते हैं। इस तकनीक का विकास जारी रहता है, जो ऑटोमेशन और बुद्धिमान निर्णय लेने के नए संभावनाओं को खोलता है।
यदि आप अपने कार्य प्रवाह में उन्नत दृश्य एआई के एकीकरण के लिए खोज रहे हैं, तो CapSolver के साथ आज जांचें। हमारे समाधान आसानी से सबसे चुनौतीपूर्ण इमेज रिकग्निशन कार्यों को हैंडल करने के लिए डिज़ाइन किए गए हैं।
और देखें
aws wafJul 23, 2026
AWS WAF को LangChain में CapSolver के साथ कैसे हल करें
एक अधिकृत AWS WAF LangChain वर्कफ़्लो बनाएं, जिसमें CapSolver टूल्स, प्रतिक्रिया निर्णय, नीति गेट्स, सत्र प्रबंधन, पुनः प्रयास और सत्यापन हों।
AIJul 23, 2026
कैसे हल करें क्लाउडफ़ेयर टर्नस्टाइल लैंगग्राफ एजेंट्स में
एक LangGraph Cloudflare Turnstile सॉल्वर वर्कफ़्लो बनाएं, जिसमें CapSolver, Playwright सेशन हैंडलिंग, नीति गेट्स, पुनर्प्रयास, सत्यापन और समीक्षा शामिल हैं।