AI में डेटा ग्राउंडिंग क्या है? विश्वसनीय बड़े भाषा मॉडल के लिए व्यावहारिक गाइड

Rajinder Singh
Deep Learning Researcher
TL;DR
- डेटा ग्राउंडिंग एआई आउटपुट को विश्वसनीय, वर्तमान और संबंधित सूत्रों से जोड़ता है।
- डेटा ग्राउंडिंग अस्पष्ट उत्तरों को कम करता है क्योंकि इंफेरेंस समय पर संदर्भ जोड़ता है।
- ग्राउंडिंग डेटा में दस्तावेज, डेटाबेस, खोज परिणाम, कैटलॉग, नीतियां और अनुमत रिकॉर्ड शामिल हो सकते हैं।
- RAG डेटा ग्राउंडिंग के लिए एक सामान्य तकनीक है, लेकिन यह पूरी विषय-क्षेत्र नहीं है।
- मजबूत डेटा ग्राउंडिंग के लिए गुणवत्ता जांच, अनुमति, खोज मूल्यांकन, संदर्भ और मॉनिटरिंग की आवश्यकता होती है।
- ऑटोमेशन का उपयोग करने वाली टीमें डेटा कानूनी रूप से एकत्र करें और केवल अनुमोदित वर्कफ़्लो में CAPTCHA चुनौतियों का उपयोग करें।
परिचय
डेटा ग्राउंडिंग एक ऐसी व्यावहारिक प्रथा है जो एआई उत्तरों की सटीकता, वर्तमानता और जांचनीयता बढ़ाती है। यह मॉडल को उत्तर देने से पहले सही संदर्भ प्रदान करता है। यह गाइड एलएलएम के ऊपर एआई टूल बनाने वाली उत्पाद टीमों, एसईओ टीमों, विकासकर्ताओं और ऑटोमेशन टीमों के लिए है। आप एआई में डेटा ग्राउंडिंग के अर्थ, कार्य करने का तरीका, RAG और फिन-ट्यूनिंग से अंतर, और उसे जिम्मेदारी से लागू करने के तरीके सीखेंगे। मूल्य व्यावहारिक है: ग्राउंडेड एआई प्रणालियां स्रोतों को संदर्भित कर सकती हैं, अनुमति का सम्मान कर सकती हैं और जीर्ण उत्तरों को कम कर सकती हैं। जब कानूनी ऑटोमेशन वर्कफ़्लो ट्रैफिक वैलिडेशन या CAPTCHA चुनौतियों के सामने आते हैं, CapSolver संगत परीक्षण प्रक्रियाओं का समर्थन कर सकता है।
डेटा ग्राउंडिंग की परिभाषा
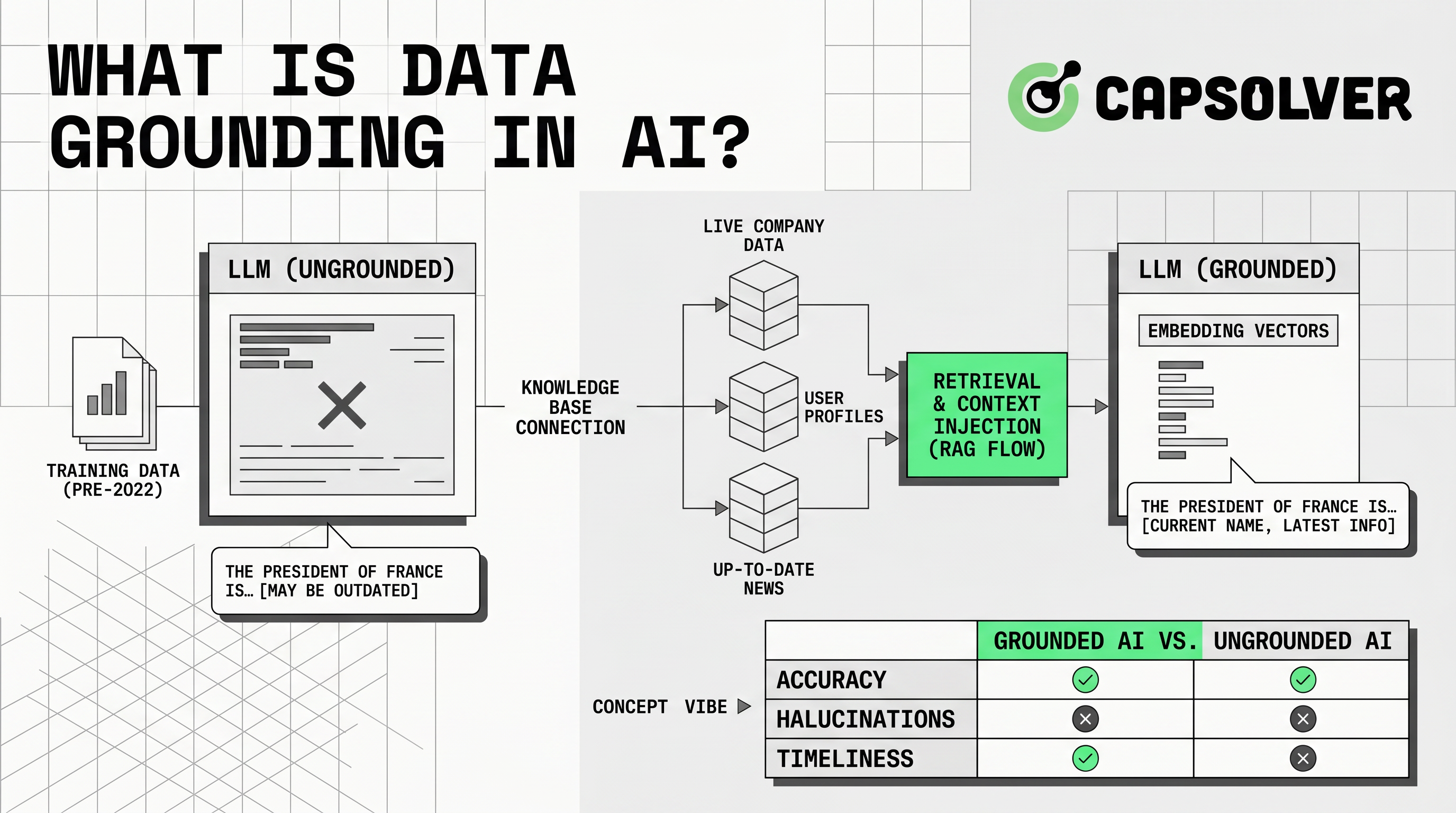
डेटा ग्राउंडिंग का अर्थ है विश्वसनीय बाहरी संदर्भ में एआई उत्तरों को स्थापित करना। जब उपयोगकर्ता कोई प्रश्न पूछता है, तो एप्लिकेशन मॉडल के लिए संबंधित जानकारी प्रदान करता है। माइक्रोसॉफ्ट डेटा ग्राउंडिंग को एक भाषा मॉडल के लिए इंफेरेंस समय पर प्रदान की गई जानकारी के रूप में परिभाषित करता है, जो मूल प्रशिक्षण डेटा में अनुपलब्ध संदर्भ के माध्यम से सटीकता और संबंधितता में सुधार करता है। माइक्रोसॉफ्ट एज़र वेल-आर्किटेड गाइडलाइन्स के माध्यम से।
डेटा ग्राउंडिंग महत्वपूर्ण है क्योंकि एलएलएम भाषा की भविष्यवाणी करते हैं। वे आपकी नवीनतम कीमतें, नीतियां, दस्तावेज, ग्राहक रिकॉर्ड या सार्वजनिक बाजार डेटा के बारे में अनुकूल रूप से नहीं जानते। विश्वसनीय संदर्भ के बिना, एक उत्तर तथ्यों के बिना आत्मविश्वास वाला लग सकता है। डेटा ग्राउंडिंग के साथ, प्रणाली स्रोत सामग्री खोज सकती है, इसे प्रॉम्प्ट में डाल सकती है, और मॉडल से उस सामग्री से उत्तर मांग सकती है।
एआई डेटा ग्राउंडिंग केवल एक प्रॉम्प्ट ट्रिक नहीं है। यह एक डेटा डिज़ाइन पैटर्न है। इसमें स्रोत चयन, साफ करना, इंडेक्सिंग, एक्सेस कंट्रोल, खोज, उत्तर जनरेशन, संदर्भ, मूल्यांकन और मॉनिटरिंग शामिल है।
एआई सटीकता के लिए डेटा ग्राउंडिंग के महत्व
डेटा ग्राउंडिंग मॉडल के उत्तर अंतराल को संकीर्ण करके एआई विश्वसनीयता में सुधार करता है। गूगल क्लाउड एंटरप्राइज ग्राउंडिंग को वेब जानकारी, एंटरप्राइज डेटा, डेटाबेस, एप्लिकेशन और विश्वसनीय स्रोतों से मॉडल को जोड़ने के रूप में वर्णित करता है, जो गूगल क्लाउड एंटरप्राइज ट्रूथ के माध्यम से पूर्णता और सटीकता में सुधार करता है।
यह तेजी से बदलते क्षेत्रों के लिए उपयोगी है। स्टॉक, समर्थन नीतियां, दस्तावेज, मूल्य और घटना शेड्यूल अक्सर बदल जाते हैं। एक मॉडल जो कई महीनों पहले प्रशिक्षित किया गया था, हर अपडेट के बारे में जानकारी नहीं रख सकता। डेटा ग्राउंडिंग एप्लिकेशन को दैनिक रूप से मॉडल के पुनर्प्रशिक्षण के बिना ताजा जानकारी के मार्ग की ओर ले जाता है।
डेटा ग्राउंडिंग टीमों को उत्तरों की व्याख्या करने में भी मदद करता है। संदर्भ, समय-चिह्न और स्रोत क्षेत्र एसीए, सुसंगतता समीक्षा और उपयोगकर्ता विश्वास के लिए समर्थन प्रदान करते हैं।
डेटा ग्राउंडिंग कैसे काम करता है
डेटा ग्राउंडिंग एक खोज और उत्पादन प्रवाह के माध्यम से काम करता है। प्रणाली पहले यह निर्धारित करती है कि कौन से स्रोत विश्वसनीय हैं। फिर वे उन स्रोतों की खोज के लिए तैयार करते हैं। सामान्य स्रोत शामिल हैं: सहायता केंद्र, मैनुअल, एपीआई, SQL डेटाबेस, वेक्टर सूचकांक, उत्पाद फीड और अनुमोदित सार्वजनिक पृष्ठ।
अगला चरण एंट्री है। टीमें दस्तावेज साफ करती हैं, डुप्लिकेट हटाती हैं, मेटाडेटा मानकीकृत करती हैं, सामग्री को टुकड़ों में विभाजित करती हैं और इसे खोज सूचकांक में संग्रहीत करती हैं। सूचकांक कुंजियों के आधार पर खोज, वेक्टर खोज, हाइब्रिड खोज या ग्राफ खोज का उपयोग कर सकता है। माइक्रोसॉफ्ट एआई ग्राउंडिंग डेटा डिज़ाइन के माध्यम से खोज में सुधार, प्रदर्शन और स्रोत-सिस्टम सुरक्षा के लिए बाहरीकरण की सिफारिश करता है।
जब उपयोगकर्ता कोई प्रश्न पूछता है, तो प्रणाली संबंधित रिकॉर्ड खोजती है। यह अनुमति, ताजगी, भाषा, क्षेत्र या उत्पाद लाइन द्वारा फ़िल्टर करता है। फिर वह खोजे गए संदर्भ को मॉडल प्रॉम्प्ट में जोड़ता है। मॉडल उस सामग्री से उत्तर देता है और स्रोत संदर्भ वापस कर सकता है।
डेटा ग्राउंडिंग तब सफल होता है जब खोज सटीक होती है। मजबूत प्रणालियां संबंधितता, विश्वसनीयता, लेटेंसी और स्रोत कवरेज को मापती हैं।
तुलना सारांश
डेटा ग्राउंडिंग कई एआई विधियों के साथ ओवरलैप करता है। नीचे दी गई तालिका व्यावहारिक अंतर दिखाती है।
| विधि | मुख्य उद्देश्य | सबसे अच्छा उपयोग केस | मुख्य सीमा |
|---|---|---|---|
| डेटा ग्राउंडिंग | उत्तरों को विश्वसनीय संदर्भ में स्थापित करें | वर्तमान, स्रोत-समर्थित उत्तर | मजबूत खोज और शासन की आवश्यकता होती है |
| RAG | जनरेशन से पहले दस्तावेज खोजें | ज्ञान-आधारित प्रश्न-उत्तर और समर्थन एजेंट | असंबंधित या अद्यतन संदर्भ खोज सकता है |
| फिन-ट्यूनिंग | उदाहरणों के माध्यम से मॉडल व्यवहार बदलें | शैली, फॉर्मेट या क्षेत्र व्यवहार | बदलते तथ्यों के लिए आदर्श नहीं है |
| प्रॉम्प्ट इंजीनियरिंग | निर्देशों के माध्यम से व्यवहार का मार्गदर्शन करें | छोटे कार्य और उत्तर फॉर्मेटिंग | अकेले कमी के तथ्य प्रदान नहीं कर सकता |
| गार्डरेल्स | नीति और आउटपुट नियंत्रण लागू करें | सुरक्षा, फॉर्मेट और सुसंगतता जांच | विश्वसनीय स्रोत संदर्भ के स्थान पर नहीं हो सकता |
इस तुलना से यह स्पष्ट हो जाता है कि डेटा ग्राउंडिंग RAG से अधिक व्यापक है। RAG एक सामान्य कार्यान्वयन पैटर्न है। डेटा ग्राउंडिंग मॉडल आउटपुट को विश्वसनीय साक्ष्य से जोड़ने के लिए पूरी विषय-क्षेत्र है।
सामान्य डेटा ग्राउंडिंग स्रोत
डेटा ग्राउंडिंग स्रोत की गुणवत्ता से शुरू होता है। टीमें अधिकार, ताजगी, स्वामित्व और अनुमति स्तर द्वारा स्रोतों का रैंक करना चाहिए।
आंतरिक स्रोत अक्सर सबसे अधिक व्यावसायिक मूल्य प्रदान करते हैं। इनमें क्रीम रिकॉर्ड, टिकट, नीतियां, स्टॉक सिस्टम, उत्पाद विशिष्टताएं और ज्ञान बेस शामिल हैं। इनके लिए सख्त एक्सेस कंट्रोल आवश्यक है।
बाहरी स्रोत ताजगी और विस्तार जोड़ते हैं। इनमें आधिकारिक दस्तावेज, सरकारी दिशा-निर्देश, सार्वजनिक डेटासेट, मानक निकाय और विश्वसनीय बाजार डेटा शामिल हैं। NIST कहता है कि इसका AI जोखिम प्रबंधन फ्रेमवर्क संगठनों, व्यक्तियों और समाज के खतरों को प्रबंधित करने में मदद करता है। NIST AI RMF के माध्यम से। ऐसे स्रोत विश्वसनीय AI प्रणालियों के लिए नीतियां लिखते समय उपयोगी होते हैं।
सार्वजनिक वेब डेटा बाजार निगरानी, एसईओ अनुसंधान और प्रतिस्पर्धी विश्लेषण में समर्थन प्रदान कर सकता है। टीमें इसे कानूनी और तार्किक रूप से रखें। वे साइट की शर्तों, दर सीमा, लागू रोबोट्स दिशा-निर्देश और गोपनीयता के कर्तव्यों का सम्मान करें। AI और ऑटोमेशन और ऑटोमेशन वर्कफ़्लो पर CapSolver के संसाधन जिम्मेदार प्रक्रियाओं के लिए उपयोगी शुरुआती बिंदु हैं।
डेटा ग्राउंडिंग के लिए उत्पादन वर्कफ़्लो
डेटा ग्राउंडिंग एक स्पष्ट ऑपरेटिंग मॉडल के साथ सबसे अच्छा काम करता है। पहले, उत्तर सीमा निर्धारित करें। तय करें कि एआई क्या उत्तर दे सकती है, कौन से स्रोत इसका उपयोग कर सकते हैं, और जब इसे अस्वीकार करना या उच्च स्तर पर बढ़ाना होगा।
दूसरा, डेटा तैयार करें। डुप्लिकेट, पुराने रिकॉर्ड, निजी फ़ील्ड और शोर बॉयलरप्लेट हटाएं। मालिक, तारीख, क्षेत्र, उत्पाद, भाषा और अनुमति स्तर जैसे मेटाडेटा जोड़ें। इससे खोज अधिक सटीक हो जाती है।
तीसरा, खोज का डिज़ाइन करें। निर्दिष्ट शब्दों के लिए कुंजी शब्द खोज का उपयोग करें, अर्थपूर्ण समानता के लिए वेक्टर खोज का उपयोग करें और अनुमत रिकॉर्ड के लिए फ़िल्टर का उपयोग करें।
चौथा, कार्यक्षमता का मूल्यांकन करें। वास्तविक प्रश्नों के एक परीक्षण सेट बनाएं। खोज संबंधितता, उत्तर विश्वसनीयता, संदर्भ सटीकता और लेटेंसी के स्कोर। क्षेत्र विशेषज्ञों के साथ किनारे के मामलों की समीक्षा करें। मॉडल आत्मविश्वास पर निर्भर न करें।
पांचवां, ड्रिफ्ट की निगरानी करें। जब दस्तावेज जीर्ण हो जाते हैं, सूचकांक टूट जाते हैं, अनुमति बदल जाती है या उपयोगकर्ता के इरादे बदल जाते हैं, तो डेटा ग्राउंडिंग विफल हो सकती है। महत्वपूर्ण प्रणालियों को स्वचालित ताजगी जांच और मानव समीक्षा मार्ग की आवश्यकता होती है।
सुरक्षा और सुरक्षा पर विचार
डेटा ग्राउंडिंग कानूनी, गोपनीयता और सुरक्षा सीमाओं के सम्मान के साथ होना चाहिए। तकनीकी एक्सेस अनुमति के अर्थ नहीं है। ग्राउंडेड एआई प्रणालियां अनुमति या विश्वसनीय डेटा के बिना निजी, सीमित, संवेदनशील या अनुमति बिना डेटा का उपयोग नहीं करना चाहिए, यदि संगठन के पास एक स्पष्ट कानूनी आधार और उपयोगकर्ता की अनुमति है।
सुरक्षा जोखिम भी महत्वपूर्ण है। OWASP बड़े जोखिमों में प्रॉम्प्ट इंजेक्शन, संवेदनशील जानकारी उजागर, अत्यधिक एजेंसी और अत्यधिक निर्भरता के रूप में बड़े जोखिमों के रूप में उल्लेख करता है। OWASP Top 10 for LLM Applications के माध्यम से। डेटा ग्राउंडिंग अस्पष्ट दावों को कम कर सकता है, लेकिन यदि खोज दुर्भावनापूर्ण सामग्री या सुरक्षित रिकॉर्ड के खुले करती है, तो यह जोखिम पैदा कर सकता है।
टीमें अनुमति-जागरूक खोज का उपयोग करें। अनुमति बिना टेक्स्ट को साफ करें, संवेदनशील रिकॉर्ड के बजाय स्रोत आईडी को लॉग करें और वर्गीकरण द्वारा डेटा को अलग करें।
ऑटोमेशन टीमों को अतिरिक्त सावधानी की आवश्यकता होती है। वेब डेटा संग्रह केवल अनुमति दिए गए सार्वजनिक डेटा, तार्किक अनुरोध दर और दस्तावेजीकृत व्यावसायिक उद्देश्यों पर केंद्रित होना चाहिए। जब अनुमोदित QA, समीक्षा या डेटा वर्कफ़्लो में CAPTCHA चुनौतियां दिखाई देती हैं, तो टीमें इन्हें ट्रैफिक वैलिडेशन के हिस्से के रूप में विचार करें। सार्वजनिक वेब डेटा संग्रह पर CapSolver के लेख और CAPTCHA चुनौतियों पर उनका गाइड ऑपरेशनल संदर्भ समझने में मदद कर सकता है।
जिम्मेदार AI वर्कफ़्लो में CapSolver कहां फिट होता है
CapSolver तब संबंधित है जब डेटा ग्राउंडिंग कानूनी ऑटोमेशन वर्कफ़्लो पर निर्भर करता है। कुछ टीमें मूल्य निगरानी, एसईओ जांच, विज्ञापन सत्यापन, QA परीक्षण या अनुसंधान के लिए सार्वजनिक डेटा एकत्र करती हैं। इन वर्कफ़्लो में सामान्य ब्राउजिंग या परीक्षण के दौरान CAPTCHA चुनौतियां हो सकती हैं।
CapSolver ऑटोमेशन पर्यावरण के लिए डिज़ाइन किए गए सेवा के माध्यम से टीमों की मदद कर सकता है। सिफारिश छोटी और सुरक्षा-पहल है। केवल तभी इसका उपयोग करें जब आपके पास अनुमति हो, लागू नियमों का सम्मान करें और सीमित या संवेदनशील डेटा के बिना। टीमें CapSolver उत्पाद की समीक्षा कर सकती हैं ताकि समर्थित परिदृश्यों को समझें और उन्हें अनुमोदित वर्कफ़्लो से मेल खाएं।
CapSolver बोनस कोड जमा करें
अपने ऑटोमेशन बजट को तत्काल बढ़ाएं!
CapSolver खाता भरते समय बोनस कोड CAP26 का उपयोग करके प्रत्येक भरोसे पर 5% का अतिरिक्त बोनस प्राप्त करें — कोई सीमा नहीं।
अपने CapSolver डैशबोर्ड में अब जमा करें
डेटा ग्राउंडिंग और CAPTCHA प्रबंधन को आसानी से मिलाना नहीं चाहिए। ग्राउंडिंग लेयर यह तय करता है कि एआई कौन सा साक्ष्य उपयोग कर सकता है। ऑटोमेशन लेयर अनुमोदित नियमों के तहत डेटा एकत्र करता है या जांचता है। इन लेयर को अलग रखने से ऑडिट आसान हो जाते हैं और ऑपरेशनल जोखिम कम हो जाते हैं।
ग्राउंडेड AI प्रणालियों के लिए व्यावहारिक मापदंड
डेटा ग्राउंडिंग के लिए मापनीय गुणवत्ता मानकों की आवश्यकता होती है। खोज संबंधितता यह पूछता है कि वापस आए संदर्भ प्रश्न का उत्तर देता है। एक कम स्कोर अर्थ देता है कि मॉडल कमजोर साक्ष्य के साथ काम कर रहा है।
उत्तर विश्वसनीयता यह पूछता है कि क्या उत्तर वापस आए स्रोतों में रहता है। यह महत्वपूर्ण है क्योंकि चिकने उत्तर अस्पष्ट विवरण जोड़ सकते हैं।
संदर्भ सटीकता जांचती है कि क्या प्रत्येक संदर्भ उस वाक्य के बाद समर्थन करता है। ताजगी दस्तावेज की उम्र, सूचकांक अपडेट समय और स्रोत अपडेट आवृत्ति की ट्रैकिंग करती है। अस्वीकृति गुणवत्ता जांचती है कि प्रणाली जब साक्ष्य गायब होता है तो क्या कहती है।
निष्कर्ष और सीटीए
डेटा ग्राउंडिंग एआई प्रणालियों को विश्वसनीय बनाने के लिए एक अत्यधिक व्यावहारिक तरीका है। यह उत्तरों को विश्वसनीय संदर्भ से जोड़ता है, ताजगी में सुधार करता है, संदर्भ का समर्थन करता है और टीमों को जोखिम प्रबंधित करने में मदद करता है। RAG आमतौर पर समाधान के हिस्सा होता है, लेकिन उत्पादन-ग्रेड डेटा ग्राउंडिंग के लिए साफ डेटा, मजबूत अनुमति, मूल्यांकन, मॉनिटरिंग और जिम्मेदार ऑटोमेशन अभ्यास की आवश्यकता होती है।
अगर आपके एआई वर्कफ़्लो सार्वजनिक डेटा निगरानी, ब्राउज़र ऑटोमेशन, QA परीक्षण या अनुसंधान पर निर्भर करते हैं, तो डेटा पाइपलाइन को ध्यान से योजना बनाएं। स्रोत पहुंच कानूनी रूप से रखें। संवेदनशील डेटा सुरक्षित रखें। महत्वपूर्ण निर्णयों के लिए उत्पादन की समीक्षा करें। अनुमोदित वर्कफ़्लो में CAPTCHA चुनौतियों का सामना करने वाले टीमें, CapSolver के लिए एक संगत ऑटोमेशन स्टैक के रूप में मूल्यांकन करने पर विचार करें।
एफक्यूए
एआई में डेटा ग्राउंडिंग क्या है?
डेटा ग्राउंडिंग एआई उत्तरों को विश्वसनीय संदर्भ से जोड़ने की प्रक्रिया है। संदर्भ दस्तावेज, डेटाबेस, एपीआई, खोज सूचकांक या अनुमोदित सार्वजनिक स्रोतों से आ सकता है। यह मॉडल को प्रशिक्षण डेटा के बजाय साक्ष्य से उत्तर देने में मदद करता है।
क्या डेटा ग्राउंडिंग RAG के समान है?
नहीं। RAG डेटा ग्राउंडिंग के एक सामान्य तरीका है। डेटा ग्राउंडिंग व्यापक है। इसमें स्रोत शासन, सूचकांक, अनुमति, खोज मूल्यांकन, संदर्भ, मॉनिटरिंग और उत्प्रेरण नियम शामिल हैं।
डेटा ग्राउंडिंग अस्पष्ट एआई उत्तरों को क्यों कम करता है?
डेटा ग्राउंडिंग अस्पष्ट उत्तरों को कम करता है क्योंकि यह इंफेरेंस समय पर मॉडल के लिए संबंधित साक्ष्य प्रदान करता है। मॉडल वर्तमान संदर्भ के बजाय सांख्यिकीय पैटर्न से अंतर भरे बिना उत्तर दे सकता है।
LLM के लिए ग्राउंडिंग डेटा के लिए कौन सा डेटा उपयोग किया जाना चाहिए?
सटीक, अनुमति, वर्तमान और संबंधित डेटा का उपयोग करें। अच्छे उदाहरण में आधिकारिक दस्तावेज, उत्पाद रिकॉर्ड, समर्थन नीतियां, ज्ञान बेस, सार्वजनिक डेटासेट और अनुमोदित व्यावसायिक डेटाबेस शामिल हैं। अनुमति बिना निजी या सीमित डेटा से बचें।
टीमें डेटा ग्राउंडिंग कैसे जिम्मेदारी से लागू कर सकती हैं?
टीमें स्रोत नियमों को परिभाषित करें, एक्सेस कंट्रोल लागू करें, खोज गुणवत्ता की निगरानी करें और उच्च प्रभाव वाले उत्पादन की समीक्षा करें। ऑटोमेशन टीमें कानूनी रूप से डेटा एकत्र करें, साइट नियमों का सम्मान करें और केवल अनुमोदित वर्कफ़्लो में CAPTCHA संबंधी सेवाओं का उपयोग करें।
और देखें
Web ScrapingJul 22, 2026
तकनीकी एसईओ रिग्रेशन निगरानी: स्वचालन पाइपलाइन
तकनीकी एसईओ रिग्रेशन निगरानी के साथ संस्करणबद्ध आधाररेखा, अर्थपूर्ण अंतर, सत्यापित चेतावनी और वैकल्पिक अधिकृत CAPTCHA पुनर्प्राप्ति चरण।
CloudflareJul 22, 2026
MCP कैप्चा सॉल्वर: क्लाउडफ़्लेयर टर्नस्टाइल एंटीग्रेशन मार्गदर्शिका
एक नीति-गेटेड MCP Cloudflare Turnstile वर्कफ़्लो बनाएं, CapSolver के साथ, सीमित पुनः प्रयास, रेडैक्टेड लॉग्स, सत्र जांच, और परिणाम मान्यता।